我们向您介绍在音频理解、生成和对话方面表现出色的开源音频基础模型–Kimi-Audio。该资源库托管了 Kimi-Audio-7B-Instruct 的模型检查点。

Kimi-Audio 被设计为通用的音频基础模型,能够在单一的统一框架内处理各种音频处理任务。主要功能包括:
- 通用功能:可处理各种任务,如语音识别 (ASR)、音频问题解答 (AQA)、音频字幕 (AAC)、语音情感识别 (SER)、声音事件/场景分类 (SEC/ASC)、文本到语音 (TTS)、语音转换 (VC) 和端到端语音对话。
- 最先进的性能:在众多音频基准测试中取得了 SOTA 级结果(参见我们的技术报告)。
- 大规模预训练:在超过 1300 万小时的各种音频数据(语音、音乐、声音)和文本数据上进行预训练。
- 新颖的架构:采用混合音频输入(连续声音+离散语义标记)和 LLM 内核,并行头用于文本和音频标记生成。
- 高效推理:采用基于流匹配的分块流式解码器,可生成低延迟音频。
https://github.com/MoonshotAI/Kimi-Audio
架构概述
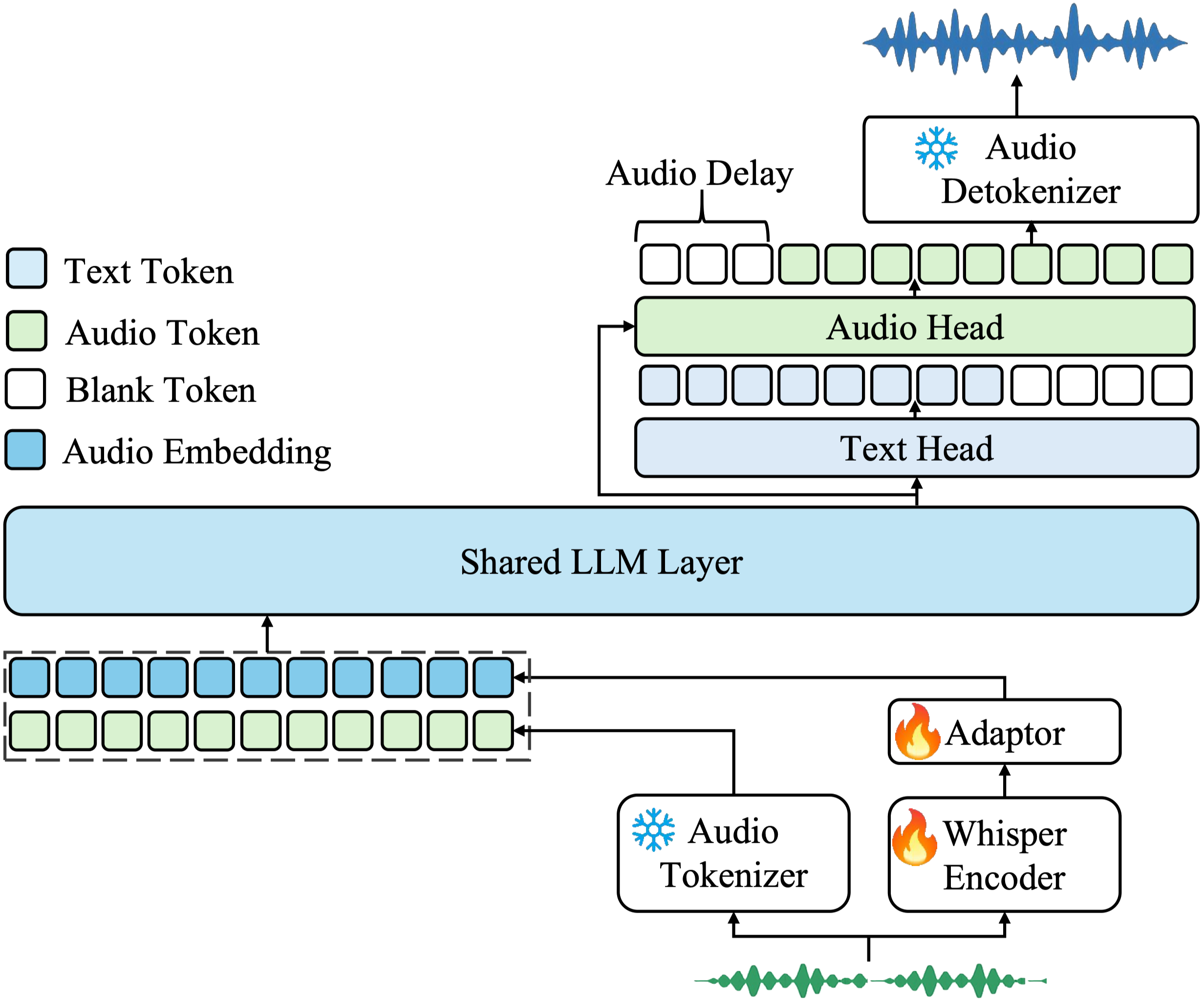
Kimi-Audio consists of three main components:
- Audio Tokenizer: 将输入音频转换为:
使用向量量化的离散语义标记(12.5Hz)。
从 Whisper 编码器获得的连续声学特征(降采样至 12.5Hz)。 - Audio LLM: 基于转换器的模型(从 Qwen 2.5 7B 等预先训练好的文本 LLM 初始化),具有处理多模态输入的共享层,然后是并行头,用于自回归生成文本标记和离散音频语义标记。
- Audio Detokenizer: 使用流匹配模型和声码器(BigVGAN)将预测的离散语义音频标记转换成高保真波形,支持采用前瞻机制的分块流,以降低延迟。
评估
Kimi-Audio在广泛的音频基准测试中实现了最先进的(SOTA)性能。
以下是总体表现:
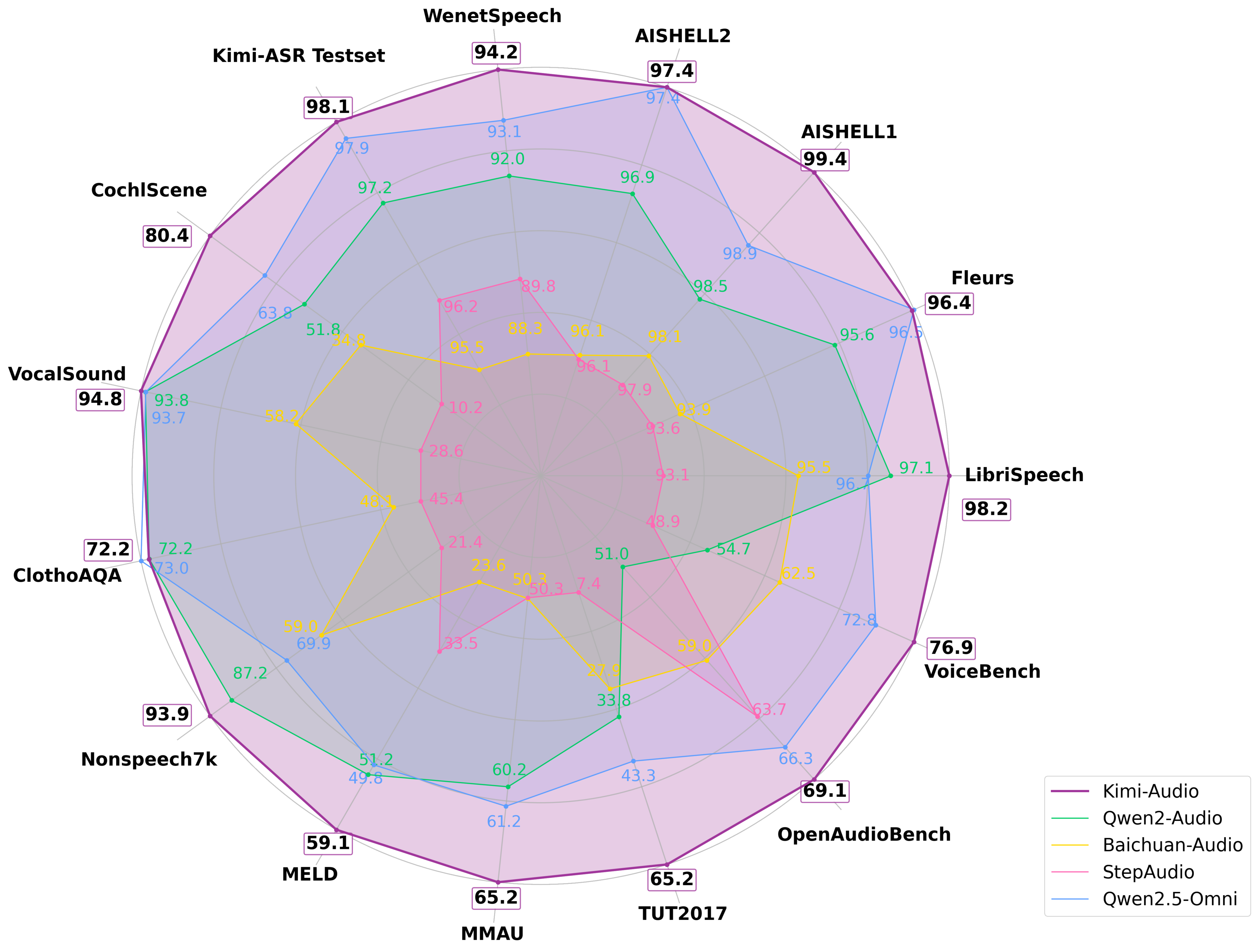
Automatic Speech Recognition (ASR)
| Datasets | Model | Performance (WER↓) |
|---|---|---|
| LibriSpeech test-clean | test-other | Qwen2-Audio-base | 1.74 | 4.04 |
| Baichuan-base | 3.02 | 6.04 | |
| Step-Audio-chat | 3.19 | 10.67 | |
| Qwen2.5-Omni | 2.37 | 4.21 | |
| Kimi-Audio | 1.28 | 2.42 | |
| Fleurs zh | en | Qwen2-Audio-base | 3.63 | 5.20 |
| Baichuan-base | 4.15 | 8.07 | |
| Step-Audio-chat | 4.26 | 8.56 | |
| Qwen2.5-Omni | 2.92 | 4.17 | |
| Kimi-Audio | 2.69 | 4.44 | |
| AISHELL-1 | Qwen2-Audio-base | 1.52 |
| Baichuan-base | 1.93 | |
| Step-Audio-chat | 2.14 | |
| Qwen2.5-Omni | 1.13 | |
| Kimi-Audio | 0.60 | |
| AISHELL-2 ios | Qwen2-Audio-base | 3.08 |
| Baichuan-base | 3.87 | |
| Step-Audio-chat | 3.89 | |
| Qwen2.5-Omni | 2.56 | |
| Kimi-Audio | 2.56 | |
| WenetSpeech test-meeting | test-net | Qwen2-Audio-base | 8.40 | 7.64 |
| Baichuan-base | 13.28 | 10.13 | |
| Step-Audio-chat | 10.83 | 9.47 | |
| Qwen2.5-Omni | 7.71 | 6.04 | |
| Kimi-Audio | 6.28 | 5.37 | |
| Kimi-ASR Internal Testset subset1 | subset2 | Qwen2-Audio-base | 2.31 | 3.24 |
| Baichuan-base | 3.41 | 5.60 | |
| Step-Audio-chat | 2.82 | 4.74 | |
| Qwen2.5-Omni | 1.53 | 2.68 | |
| Kimi-Audio | 1.42 | 2.44 |
Audio Understanding
| Datasets | Model | Performance↑ |
|---|---|---|
| MMAU music | sound | speech | Qwen2-Audio-base | 58.98 | 69.07 | 52.55 |
| Baichuan-chat | 49.10 | 59.46 | 42.47 | |
| GLM-4-Voice | 38.92 | 43.54 | 32.43 | |
| Step-Audio-chat | 49.40 | 53.75 | 47.75 | |
| Qwen2.5-Omni | 62.16 | 67.57 | 53.92 | |
| Kimi-Audio | 61.68 | 73.27 | 60.66 | |
| ClothoAQA test | dev | Qwen2-Audio-base | 71.73 | 72.63 |
| Baichuan-chat | 48.02 | 48.16 | |
| Step-Audio-chat | 45.84 | 44.98 | |
| Qwen2.5-Omni | 72.86 | 73.12 | |
| Kimi-Audio | 71.24 | 73.18 | |
| VocalSound | Qwen2-Audio-base | 93.82 |
| Baichuan-base | 58.17 | |
| Step-Audio-chat | 28.58 | |
| Qwen2.5-Omni | 93.73 | |
| Kimi-Audio | 94.85 | |
| Nonspeech7k | Qwen2-Audio-base | 87.17 |
| Baichuan-chat | 59.03 | |
| Step-Audio-chat | 21.38 | |
| Qwen2.5-Omni | 69.89 | |
| Kimi-Audio | 93.93 | |
| MELD | Qwen2-Audio-base | 51.23 |
| Baichuan-chat | 23.59 | |
| Step-Audio-chat | 33.54 | |
| Qwen2.5-Omni | 49.83 | |
| Kimi-Audio | 59.13 | |
| TUT2017 | Qwen2-Audio-base | 33.83 |
| Baichuan-base | 27.9 | |
| Step-Audio-chat | 7.41 | |
| Qwen2.5-Omni | 43.27 | |
| Kimi-Audio | 65.25 | |
| CochlScene test | dev | Qwen2-Audio-base | 52.69 | 50.96 |
| Baichuan-base | 34.93 | 34.56 | |
| Step-Audio-chat | 10.06 | 10.42 | |
| Qwen2.5-Omni | 63.82 | 63.82 | |
| Kimi-Audio | 79.84 | 80.99 |
Audio-to-Text Chat
| Datasets | Model | Performance↑ |
|---|---|---|
| OpenAudioBench AlpacaEval | Llama Questions | Reasoning QA | TriviaQA | Web Questions | Qwen2-Audio-chat | 57.19 | 69.67 | 42.77 | 40.30 | 45.20 |
| Baichuan-chat | 59.65 | 74.33 | 46.73 | 55.40 | 58.70 | |
| GLM-4-Voice | 57.89 | 76.00 | 47.43 | 51.80 | 55.40 | |
| StepAudio-chat | 56.53 | 72.33 | 60.00 | 56.80 | 73.00 | |
| Qwen2.5-Omni | 72.76 | 75.33 | 63.76 | 57.06 | 62.80 | |
| Kimi-Audio | 75.73 | 79.33 | 58.02 | 62.10 | 70.20 | |
| VoiceBench AlpacaEval | CommonEval | SD-QA | MMSU | Qwen2-Audio-chat | 3.69 | 3.40 | 35.35 | 35.43 |
| Baichuan-chat | 4.00 | 3.39 | 49.64 | 48.80 | |
| GLM-4-Voice | 4.06 | 3.48 | 43.31 | 40.11 | |
| StepAudio-chat | 3.99 | 2.99 | 46.84 | 28.72 | |
| Qwen2.5-Omni | 4.33 | 3.84 | 57.41 | 56.38 | |
| Kimi-Audio | 4.46 | 3.97 | 63.12 | 62.17 | |
| VoiceBench OpenBookQA | IFEval | AdvBench | Avg | Qwen2-Audio-chat | 49.01 | 22.57 | 98.85 | 54.72 |
| Baichuan-chat | 63.30 | 41.32 | 86.73 | 62.51 | |
| GLM-4-Voice | 52.97 | 24.91 | 88.08 | 57.17 | |
| StepAudio-chat | 31.87 | 29.19 | 65.77 | 48.86 | |
| Qwen2.5-Omni | 79.12 | 53.88 | 99.62 | 72.83 | |
| Kimi-Audio | 83.52 | 61.10 | 100.00 | 76.93 |
Speech Conversation
| Model | Ability | |||||
|---|---|---|---|---|---|---|
| Speed Control | Accent Control | Emotion Control | Empathy | Style Control | Avg | |
| GPT-4o | 4.21 | 3.65 | 4.05 | 3.87 | 4.54 | 4.06 |
| Step-Audio-chat | 3.25 | 2.87 | 3.33 | 3.05 | 4.14 | 3.33 |
| GLM-4-Voice | 3.83 | 3.51 | 3.77 | 3.07 | 4.04 | 3.65 |
| GPT-4o-mini | 3.15 | 2.71 | 4.24 | 3.16 | 4.01 | 3.45 |
| Kimi-Audio | 4.30 | 3.45 | 4.27 | 3.39 | 4.09 | 3.90 |
快速上手
部署环境
git clone https://github.com/MoonshotAI/Kimi-Audio
cd Kimi-Audio
git submodule update --init --recursive
pip install -r requirements.txt
推理代码
import soundfile as sf
# Assuming the KimiAudio class is available after installation
from kimia_infer.api.kimia import KimiAudio
import torch # Ensure torch is imported if needed for device placement
# --- 1. Load Model ---
# Load the model from Hugging Face Hub
# Make sure you are logged in (`huggingface-cli login`) if the repo is private.
model_id = "moonshotai/Kimi-Audio-7B-Instruct" # Or "Kimi/Kimi-Audio-7B"
device = "cuda" if torch.cuda.is_available() else "cpu" # Example device placement
# Note: The KimiAudio class might handle model loading differently.
# You might need to pass the model_id directly or download checkpoints manually
# and provide the local path as shown in the original readme_kimia.md.
# Please refer to the main Kimi-Audio repository for precise loading instructions.
# Example assuming KimiAudio takes the HF ID or a local path:
try:
model = KimiAudio(model_path=model_id, load_detokenizer=True) # May need device argument
model.to(device) # Example device placement
except Exception as e:
print(f"Automatic loading from HF Hub might require specific setup.")
print(f"Refer to Kimi-Audio docs. Trying local path example (update path!). Error: {e}")
# Fallback example:
# model_path = "/path/to/your/downloaded/kimia-hf-ckpt" # IMPORTANT: Update this path if loading locally
# model = KimiAudio(model_path=model_path, load_detokenizer=True)
# model.to(device) # Example device placement
# --- 2. Define Sampling Parameters ---
sampling_params = {
"audio_temperature": 0.8,
"audio_top_k": 10,
"text_temperature": 0.0,
"text_top_k": 5,
"audio_repetition_penalty": 1.0,
"audio_repetition_window_size": 64,
"text_repetition_penalty": 1.0,
"text_repetition_window_size": 16,
}
# --- 3. Example 1: Audio-to-Text (ASR) ---
# TODO: Provide actual example audio files or URLs accessible to users
# E.g., download sample files first or use URLs
# wget https://path/to/your/asr_example.wav -O asr_example.wav
# wget https://path/to/your/qa_example.wav -O qa_example.wav
asr_audio_path = "./test_audios/asr_example.wav" # IMPORTANT: Make sure this file exists
qa_audio_path = "./test_audios/qa_example.wav" # IMPORTANT: Make sure this file exists
messages_asr = [
{"role": "user", "message_type": "text", "content": "Please transcribe the following audio:"},
{"role": "user", "message_type": "audio", "content": asr_audio_path}
]
# Generate only text output
# Note: Ensure the model object and generate method accept device placement if needed
_, text_output = model.generate(messages_asr, **sampling_params, output_type="text")
print(">>> ASR Output Text: ", text_output)
# Expected output: "这并不是告别,这是一个篇章的结束,也是新篇章的开始。" (Example)
# --- 4. Example 2: Audio-to-Audio/Text Conversation ---
messages_conversation = [
{"role": "user", "message_type": "audio", "content": qa_audio_path}
]
# Generate both audio and text output
wav_output, text_output = model.generate(messages_conversation, **sampling_params, output_type="both")
# Save the generated audio
output_audio_path = "output_audio.wav"
# Ensure wav_output is on CPU and flattened before saving
sf.write(output_audio_path, wav_output.detach().cpu().view(-1).numpy(), 24000) # Assuming 24kHz output
print(f">>> Conversational Output Audio saved to: {output_audio_path}")
print(">>> Conversational Output Text: ", text_output)
# Expected output: "A." (Example)
print("Kimi-Audio inference examples complete.")