目录
引言
1. CMake的安装
2. CMake的原理
3. CMake入门
3.1 CMakeLists.txt与注释
3.2 版本指定与工程描述
3.3 生成可执行程序
3.4 定义变量与指定输出路径
3.5 指定C++标准
3.6 搜索文件
3.7 包含头文件
4. CMake进阶
4.1 生成动静态库
4.2 链接动静态库
4.3 日志
4.4 变量操作
4.5 定义宏
5. CMake精通
5.1 CMake的嵌套
5.2 条件判断
5.3 循环
结语
引言
CMake是一个跨平台的项目构筑工具。当项目规模庞大,依赖关系错综复杂时,编写 makefile 的工作量较大,解决依赖关系时也容易出错。同时makefileakefile 非常依赖于当前的编译平台,无法跨平台使用。而CMake以其出色的灵活性和强大的功能,成为了解决问题的理想选择。
本文笔者将详细介绍CMake的用法,帮助你高效地管理项目构建过程。
1. CMake的安装
在这里我们主要介绍Linux与Windows下的安装。
Linux下的安装
在Centos上,我们可以使用以下命令:
sudo yum install cmake在Ubuntu或Debian上,我们可以使用以下命令:
sudo apt install cmake安装完成后我们可以在终端下输入:
cmake -version如果安装成功会显示cmake的版本。

Windows下的安装
打开浏览器,访问CMake的官方网站下载页面:CMake Download。
下滑选择你要安装的版本,然后点击链接。
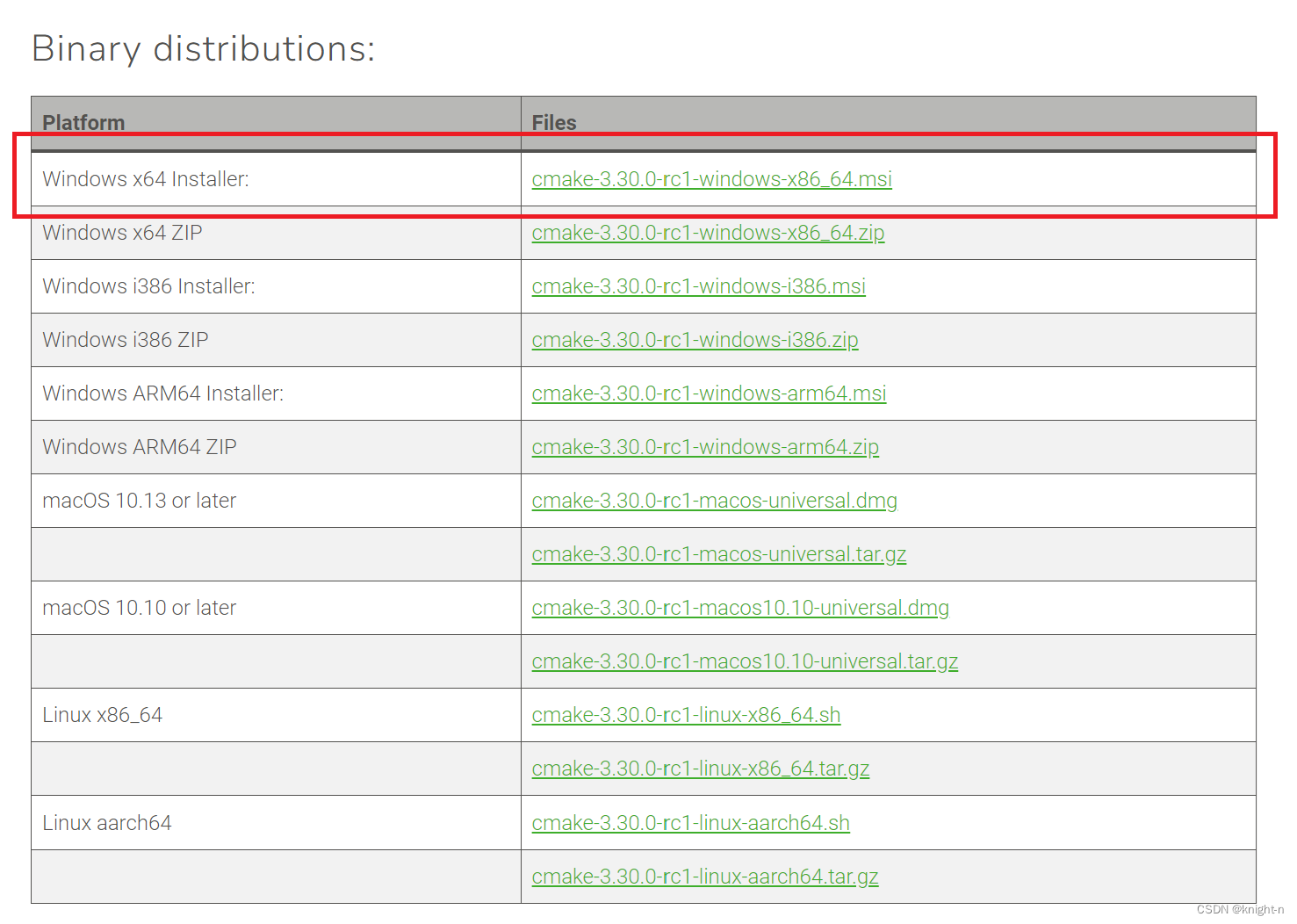
这里推荐选择第一个,注意如果选择的是zip格式需要手动解压并设置环境变量。
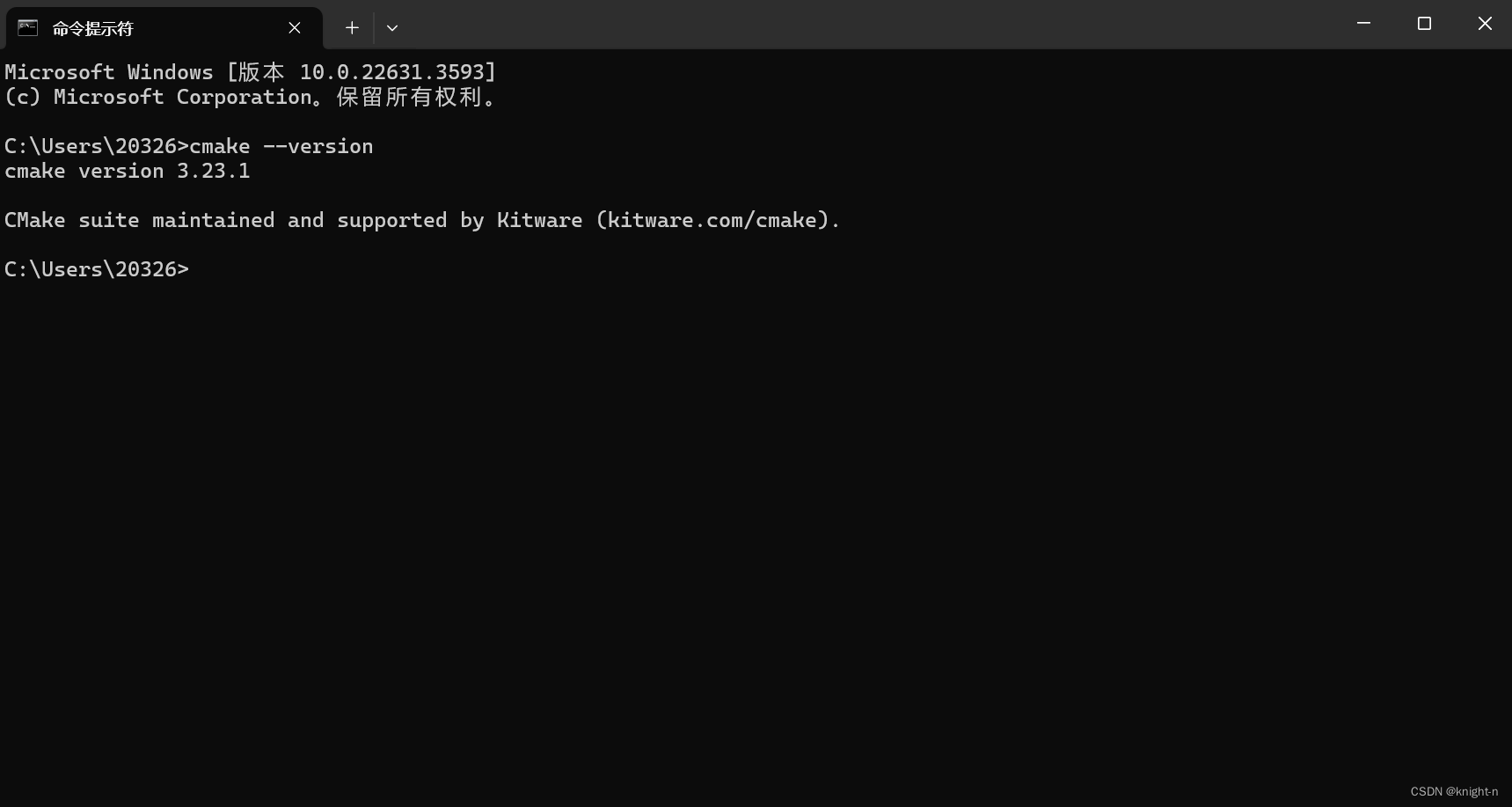
下载后按指引安装即可。 打开命令窗口,输入cmake --version验证CMake 是否已正确安装
2. CMake的原理
CMake并不直接编译源代码,它根据开发者在CMakeLists.txt文件指定的编译流程,生成适用于不同平台和编译器的本地化构建文件。
在Linux上是makefile文件,在Windows是Visual Studio解决方案文件(.sln)和项目文件(.vcxproj或.vcxproj.filters)。生成的这些文件也不编译源代码,他们用来描述工程的组织架构,帮助编译器编译。流程如下图:
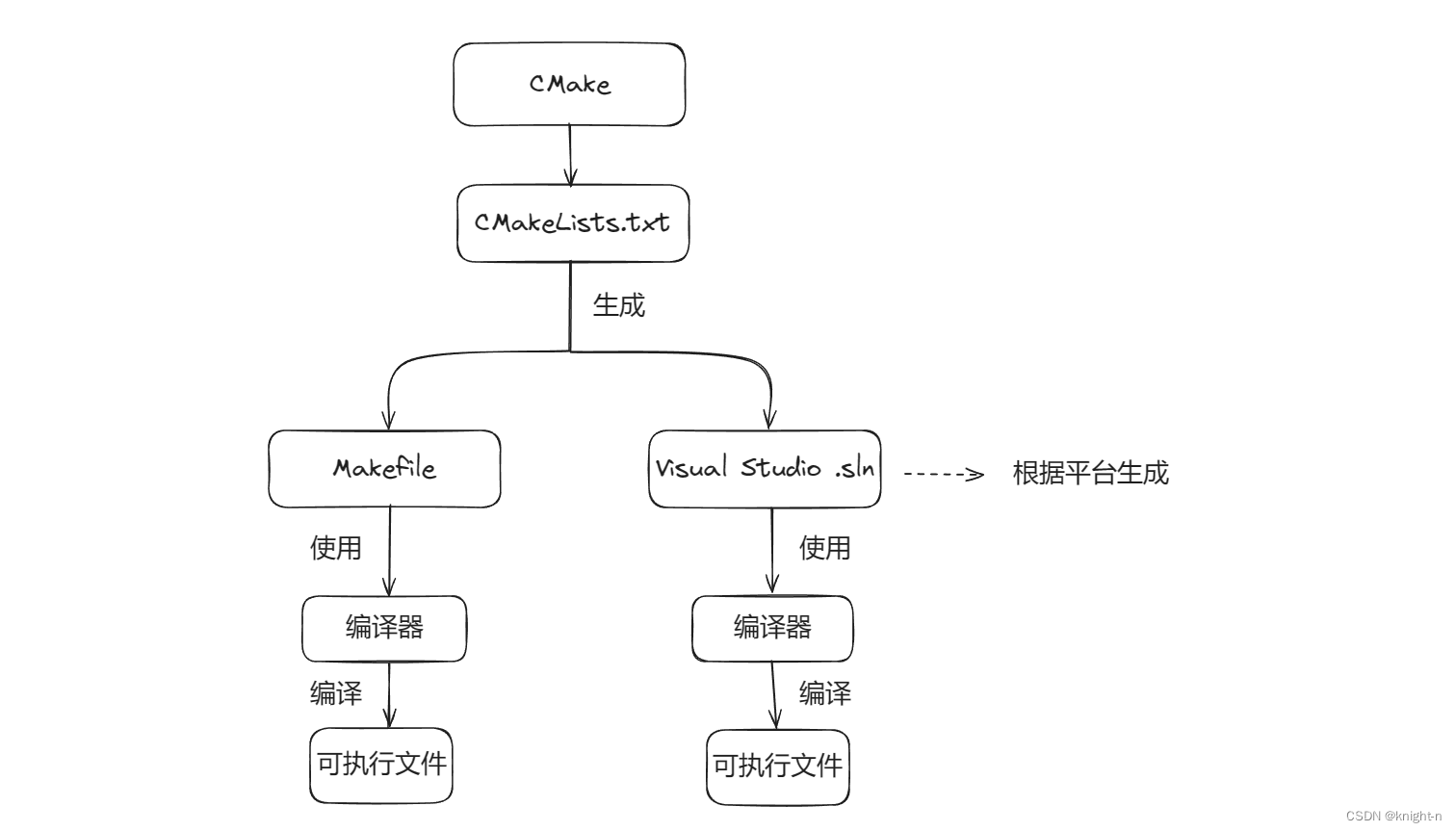
简而言之,CMake之所以可以跨平台,是因为其在不同平台可以生成相应的构筑文件。
同时它还能够检测系统环境并设置相应的编译器标志和库路径,进一步简化跨平台开发。支持条件逻辑,允许开发者根据不同的平台或编译器选项定制构建过程。
3. CMake入门
演示文件介绍
演示目录下共有六个文件: head.h add.cpp div.cpp sub.cpp mul.cpp main.cpp。
add.cpp div.cpp sub.cpp mul.cpp分别定义了加减乘除函数。
//add.cpp
#include "head.h"
int myadd(int x,int y)
{
return x+y;
}//sub.cpp
#include "head.h"
int mysub(int x,int y)
{
return x-y;
}//mul.cpp
#include "head.h"
int mymul(int x,int y)
{
return x*y;
}//div.cpp
#include "head.h"
int mydiv(int x,int y)
{
return x/y;
}head.h声明了这些函数 。
#pragma once
int myadd(int x,int y);
int mydiv(int x,int y);
int mymul(int x,int y);
int mysub(int x,int y);
main.cpp调用了这些函数。
#include<iostream>
#include"head.h"
int main()
{
int x=6,y=3;
std::cout << x << "+" << "y" << "=" << myadd(x,y) << std::endl;
std::cout << x << "-" << "y" << "=" << mysub(x,y) << std::endl;
std::cout << x << "*" << "y" << "=" << mymul(x,y) << std::endl;
std::cout << x << "/" << "y" << "=" << mydiv(x,y) << std::endl;
return 0;
}当使用gcc编译文件我们可以使用以下命令:
g++ -std=c++11 -o program *.cpp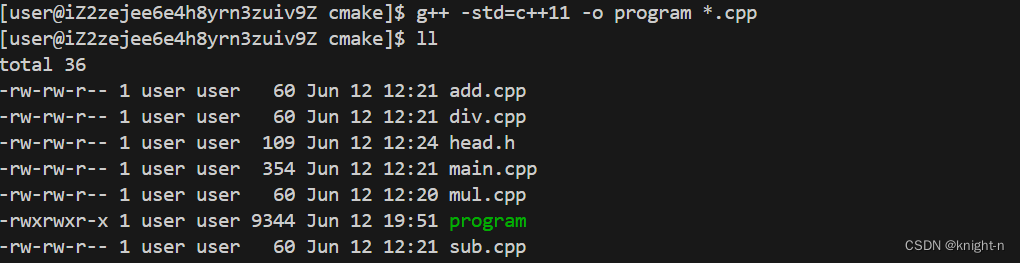
可以看到源文件成功编译,代码成功运行。
 下面我们演示如何使用CMake编译。
下面我们演示如何使用CMake编译。
3.1 CMakeLists.txt与注释
首先我们需要创建一个CMakeLists.txt,注意文件名严格区分大小写。创建成功后我们在文件中编写命令。这是CMake的基石。
行注释
在CMake中我们使用 # 进行行注释。效果类似C/C++中的 // 。
#这是一行注释段注释
当我们要进行段注释时我们使用 #[[ ]] ,效果类似C/C++中的 /* */ 。
#[[这是一段注释
这是一段注释
这是一段注释
这是一段注释]]3.2 版本指定与工程描述
版本指定
在CMake的版本更新中会更新新的命令,这些命令在低版本并不兼容,所以需要通过cmake_minimum_required 指定需要的最低版本。这并不是必须的,但如果不加可能会有警告。
示例:
#语法
cmake_minimum_required(VERSION [版本号])
#示例
cmake_minimum_required(VERSION 3.0)工程描述
我们可以使用 project 定义工程名称,工程的版本、工程描述、web主页地址、支持的语言(默认情况支持所有语言),如果不需要这些都是可以忽略的,只需要指定出工程名字即可。
- 定义项目名称: project(<PROJECT_NAME>) 这是最基本的用法,只需要指定项目名称。
- 版本信息: VERSION <major>[.<minor>[.<patch>[.<tweak>]]] 可以指定项目的版本号。
- 项目描述: DESCRIPTION "<description>" 可以为项目添加描述。
- Web主页地址: HOMEPAGE_URL "<url>" 可以指定项目的主页URL。
- 支持的语言: LANGUAGES <lang> [<lang>...] 可以指定项目支持的编程语言。如果不指定,默认情况下CMake支持多种语言,如C和C++。
- 忽略可选参数:如果不需要设置版本、描述、主页或特定语言,可以忽略这些参数,只指定项目名称
示例:
#语法
project(<PROJECT-NAME>
[VERSION <major>[.<minor>[.<patch>[.<tweak>]]]]
[DESCRIPTION <project-description-string>]
[HOMEPAGE_URL <url-string>]
[LANGUAGES <language-name>...])
#示例
#定义项目名称,版本,描述,主页URL,以及支持的语言
project(
MyProject
VERSION 1.0.0
DESCRIPTION "这是一个示例项目"
HOMEPAGE_URL "http://www.example.com"
LANGUAGES CXX
)现在我们在CMakeLists.txt中指定版本信息与工程描述。
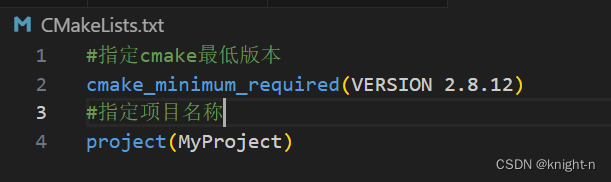
3.3 生成可执行程序
我们已经指定了版本信息与工程描述。现在我们需要使用 add_executable 定义工程生成的可执行程序。
//语法
add_executable(可执行程序名 源文件名称)
//示例
add_executable(program main.cpp add.cpp sub.cpp mul.cpp div.cpp)现在我们继续完善CMakeLists.txt
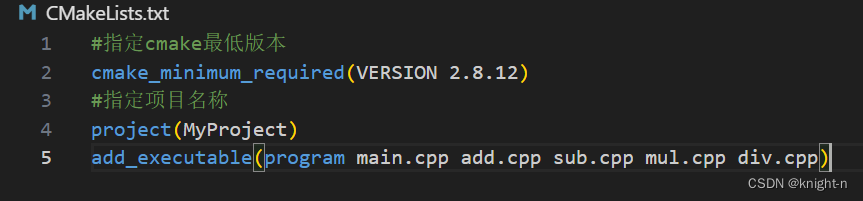
一个基本的 CMakeLists.txt 完成了。
我们使用cmake命令构筑项目。
#语法
cmake CMakeLists.txt文件所在路径
#示例
cmake .
输入cmake . 命令 ,可以看到当前目录生成了许多文件。
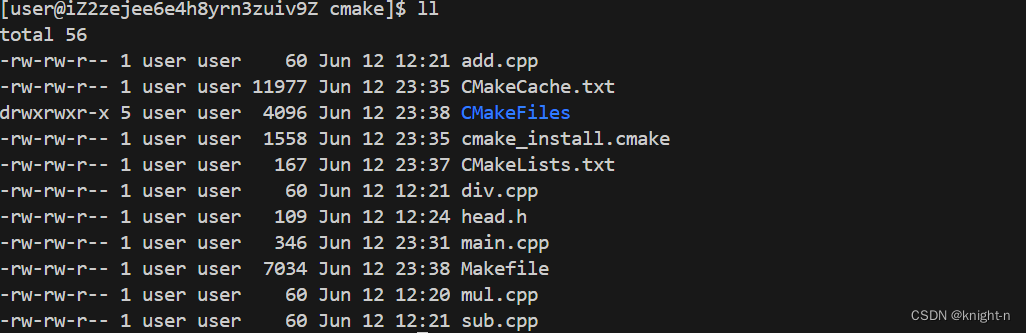
对应的目录下生成了makefile文件,此时执行make命令便可到可执行文件。
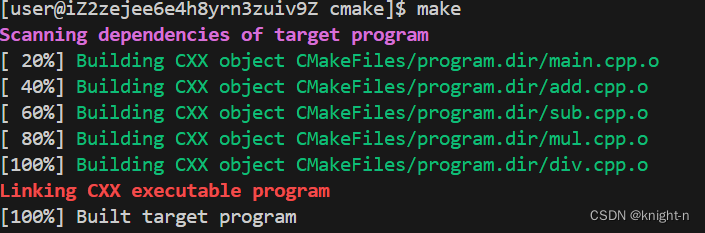
可以看到编译成功,我们执行程序。

程序执行成功。在上面的过程中我们发现执行cmake后会生成一堆文件,使得目录十分杂乱。我们可以单独创建一个目录,在该目录下执行cmake .. ,文件会创建在此目录,更加整洁。
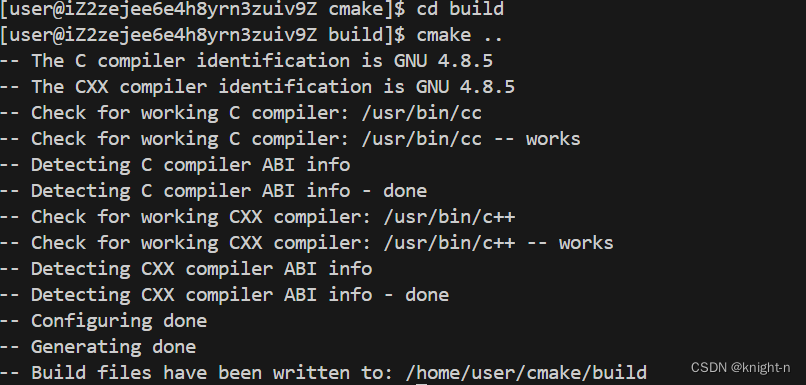
需要注意的是此时只能在 build 目录下执行,生产的可执行文件也在 build 目录。
3.4 定义变量与指定输出路径
在上面的过程中,我们使用了五个源文件。如果这些源文件需要反复使用,我们每次都需要将他们的名称写出来,这是非常低效的。cmake为我们提供了 set 指令来定义变量与设置宏。
#语法
set(VARIABLE_NAME value [CACHE_TYPE [CACHE_VARIABLE]])- VARIABLE_NAME:变量的名称。
- value:为变量赋予的值。
- CACHE_TYPE(可选):指定缓存变量的类型,如 FILEPATH、PATH、STRING、BOOL 等。
- CACHE_VARIABLE(可选):如果指定,变量将被存储在 CMake 缓存中,而不是只限于当前的 CMakeLists.txt 文件。
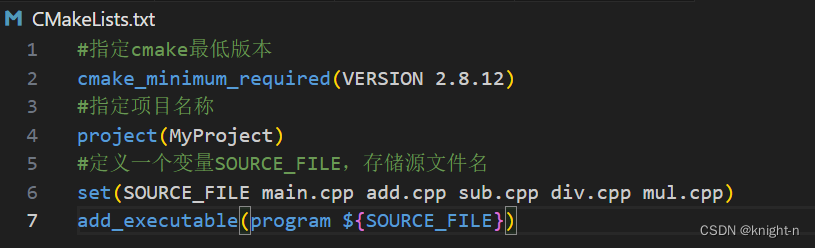
后两项我们暂时不做讨论。现在我们可以将要使用的源文件名存储在变量里
#定义一个变量SOURCE_FILE,存储源文件名
set(SOURCE_FILE main.cpp add.cpp sub.cpp div.cpp mul.cpp)如果要取变量中的值语法格式为:
${变量名}现在我们修改CMakeLists.txt,使用变量存储文件名。
编译并运行程序。
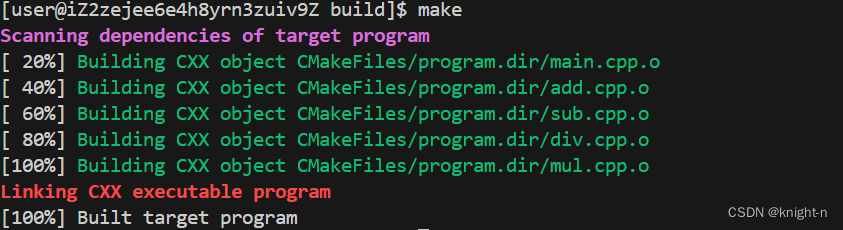
可以看到程序成功运行。
上面我们提到可以单独创建一个目录,在该目录下执行cmake .. 这样的操作使目录更加整洁,但这样可执行文件就会生成在build目录下,能不能指定可执行文件输出路径呢?CMake为我们提供了一个宏 EXECUTABLE_OUTPUT_PATH 我们可以通过设置这个宏指定输出路径。这里的输出路径支持相对路径与绝对路径。我们可以使用 set 命令设置宏。
#定义一个变量存储路径,输出路径为上一级的bin目录
set(OUTPATH ../bin)
#设置宏
set(EXECUTABLE_OUTPUT_PATH ${OUTPATH})注意:如果输出路径中的子目录不存在,会自动生成。
现在我们修改CMakeLists.txt,指定输出路径。
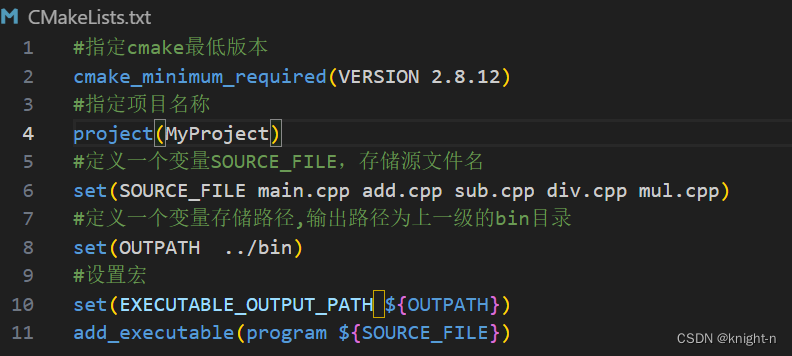
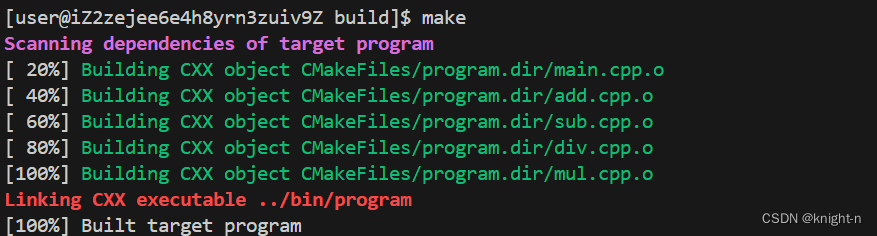
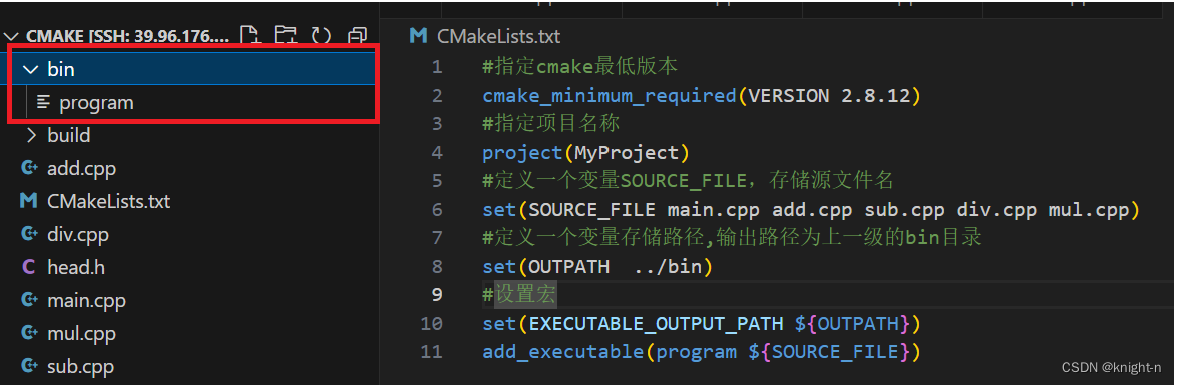 可以看到成功创建了目录 bin 并生成了可执行程序。
可以看到成功创建了目录 bin 并生成了可执行程序。
3.5 指定C++标准
在这里我们再额外介绍一个宏 CMAKE_CXX_STANDARD 。这个宏用来指定C++标准。在CMake中想要指定C++标准有两种方式:通过set命令指定,在执行cmake指令时指定。
我们在main.cpp中添加一行代码
auto x=6;auto关键字在 C++11 引入,下面我们分别演示用通过set命令指定C++11和在执行cmake指令时指定。
通过set命令指定C++11
我们需要通过set命令设置 CMAKE_CXX_STANDARD 的值,示例如下
set(CMAKE_CXX_STANDARD 11)同样修改CMakeLists.txt后运行。
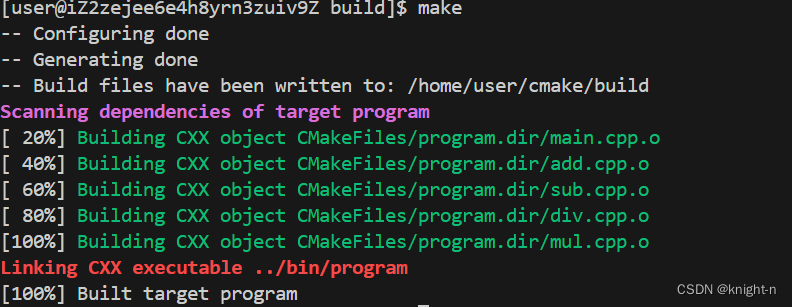
文件成功编译。
执行cmake指令时指定
我们注释掉CMakeLists.txt中指定CMAKE_CXX_STANDARD的命令。在执行cmake指令时设置CMAKE_CXX_STANDARD的值。注意 CMAKE_CXX_STANDARD 需要的最低版本为3.1。这里并没有更改最低版本

我们使用cmake命令
cmake .. -DCMAKE_CXX_STANDARD=11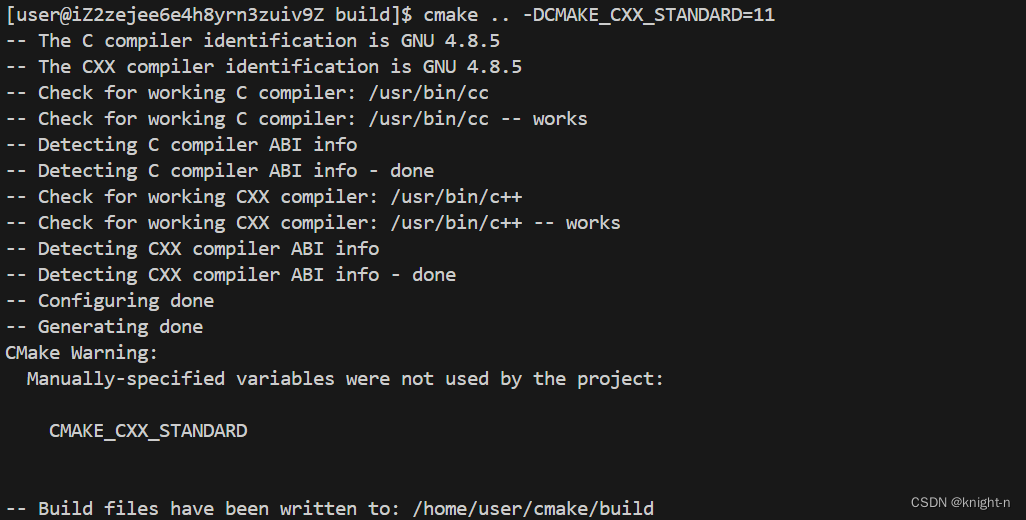

可以看到同样编译成功。
3.6 搜索文件
在我们的示例文件中只有五个源文件,如果有大量源文件,那么需要一个一个罗列出来十分繁琐。cmake中同样提供了搜索文件的命令 aux_source_directory 与 file 命令。
aux_source_directory
aux_source_directory 命令可以查找某个路径下的所有源文件,语法:
aux_source_directory(<directory> <variable>)- <directory>: 要搜索源文件的目录的路径。这可以是相对路径或绝对路径。
- <variable>: 用于存储找到的源文件列表的变量名。
示例使用:
#搜索上一级目录的源文件
aux_source_directory(.. SOURCE_FILE)现在我们修改CMakeLists.txt并执行cmake命令。
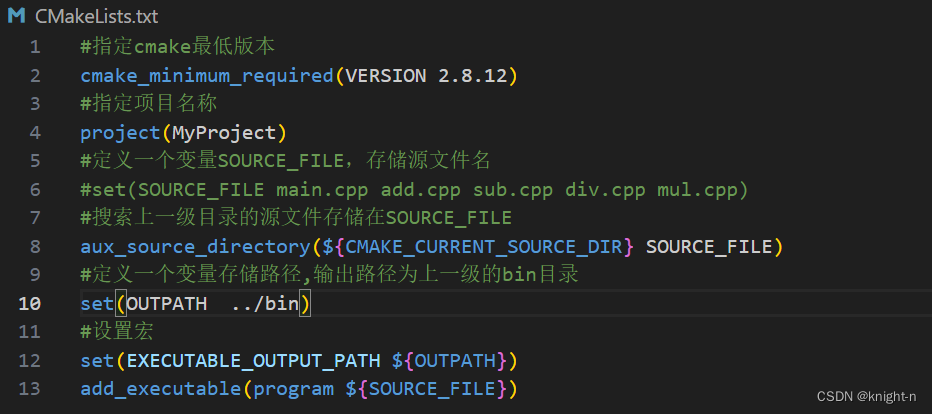
CMAKE_CURRENT_SOURCE_DIR 是 CMake 中的一个预定义变量,它指向当前正在处理的 CMakeLists.txt 文件所在的目录。注意:如果使用相对路径,相对路径是相对于CMakeLists.txt 文件所在的目录,而非执行cmake命令的目录。
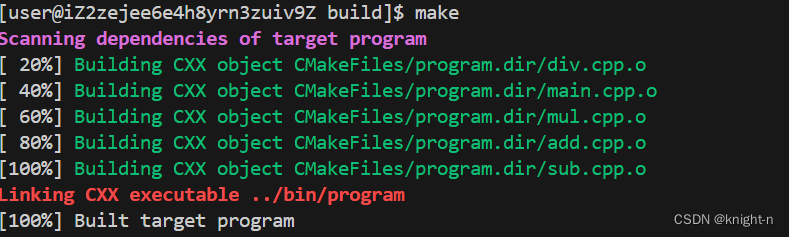
可以看到成功编译。
file
file 命令用于对文件和目录进行操作,包括检查文件属性、读取和写入文件内容、复制文件、删除文件等。在这里我们只介绍一种用法搜索文件。语法:
file(<GLOB/GLOB_RECURSE> <VARIABLE> <PATH>)- <GLOB/GLOB_RECURSE>选择非递归搜索(GLOB)还是递归搜索(GLOB_RECURSE),递归搜索会搜索路径下的所有目录。
- <VARIABLE>存储搜索结果的变量。
- <PATH>搜索的路径与搜索的文件名。
file使用相对路径时同样相对于CMakeLists.txt 文件所在的目录,而非执行cmake命令的目录。 示例:
#搜索CMakeLists.txt路径下所有源文件并存储在SOURCE_FILE
file(GLOB SOURCE_FILE ./*.cpp)修改CMakeLists.txt,同样可以成功编译。
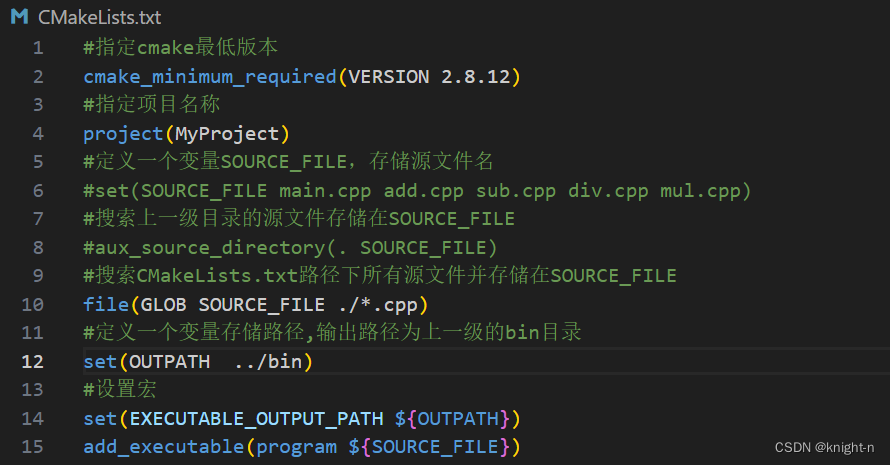
3.7 包含头文件
现在我们将工程结构调整为下面的结构(文件搜索路径同步调整):
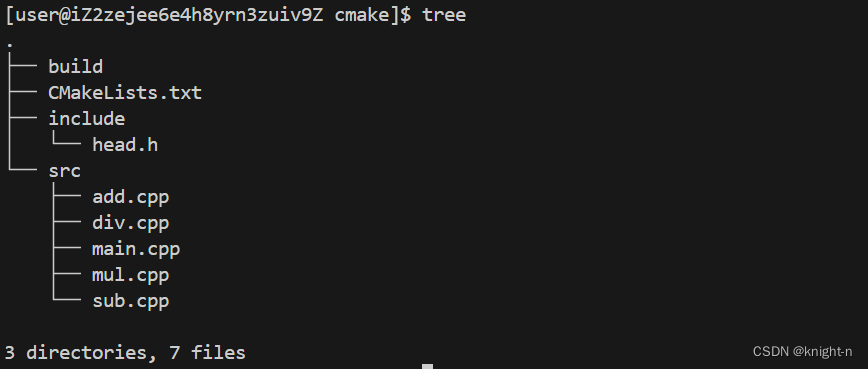
我们执行cmake命令。
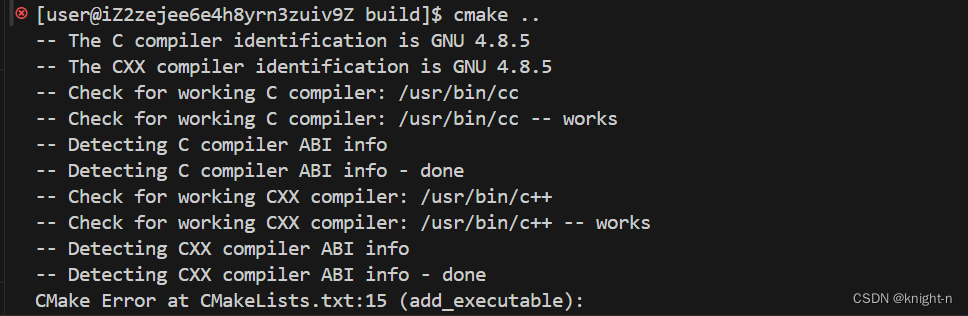
发现执行失败,这是为什么?我们的源文件都包含了head.h头文件。
#include"head.h"
当我们使用 " " 方式包含头文件时默认从当前源文件所在路径搜索。如果当前目录下没有找到,编译器会搜索项目中指定的其他包含目录(通过编译器的-I选项或在IDE中设置的包含路径来指定的)。如果以上目录都没有找到,编译器会搜索系统的标准库包含目录。
在我们调整了工程结构后头文件与源文件不在同一目录,我们又没有指定头文件搜素路径。所以找不到头文件。我们可以使用include_directories 指定头文件搜索路径。
#语法
include_directories([headpath])
#示例
include_directories(${CMAKE_CURRENT_SOURCE_DIR}/include)现在我们在 CMakeLists.txt 加入头文件搜索路径。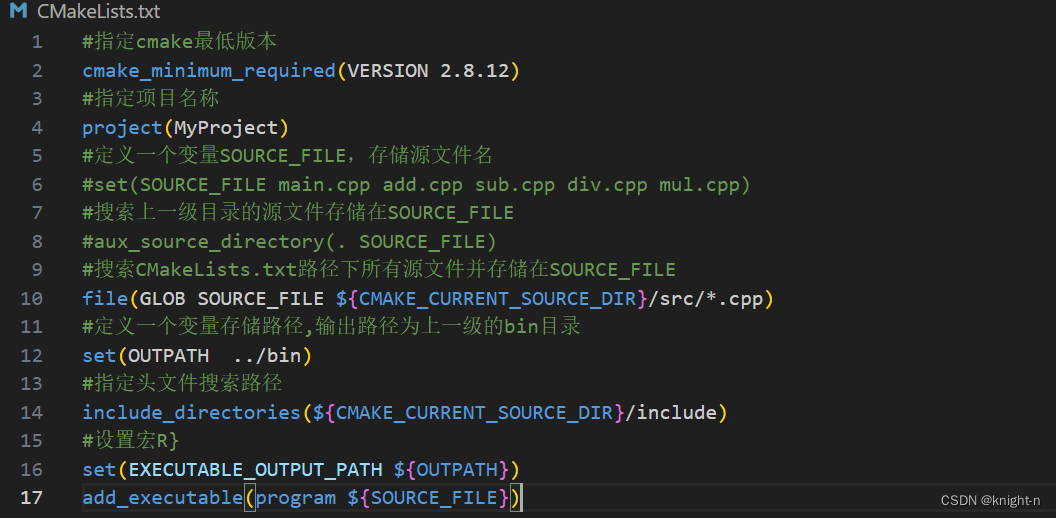
再次执行cmake与make命令。
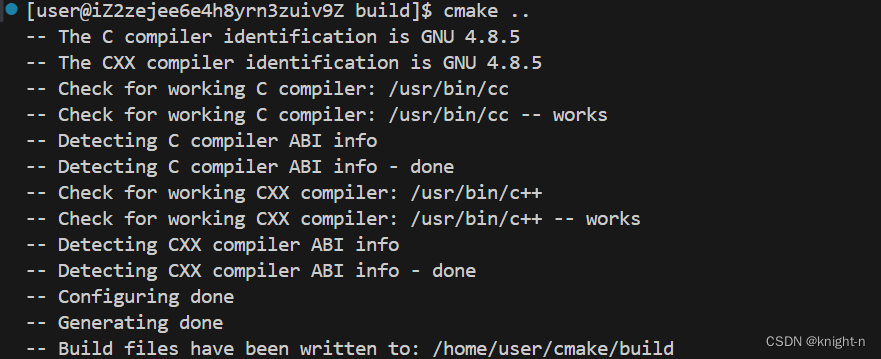
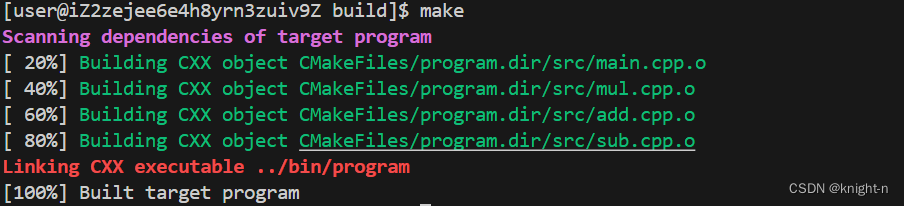
程序编译成功。
4. CMake进阶
现在我们来学习使用cmake制作动态库与静态库,对动静态库不熟悉的读者可以阅读我的往期博客——动态库与静态库。
4.1 生成动静态库
生成静态库
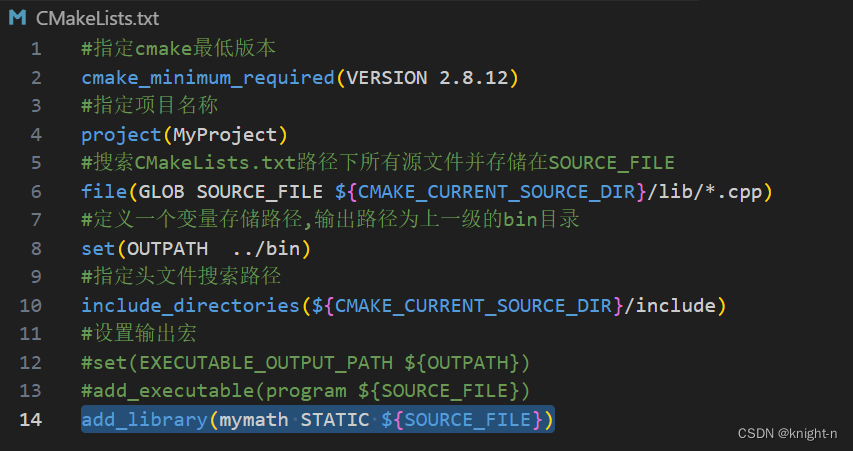
生成静态库需要用到命令 add_library 语法:
#语法
add_library([库名称] SHARED/STATIC [源文件1] [源文件2] ...)
#示例生成一个名为libmymath.a的静态库
add_library(mymath STATIC add.cpp sub.cpp mul.cpp div.cpp) 在Linux中,静态库名字分为三部分:lib+库名+.a,命令需要指出的是中间部分,另外两部分在生成库文件时会自动补全。命令的第二个选项代表生成的是静态库(STATIC)还是动态库(SHARED)。
现在我们调整一下工程结构(CMakeLists.txt 同步调整 )。
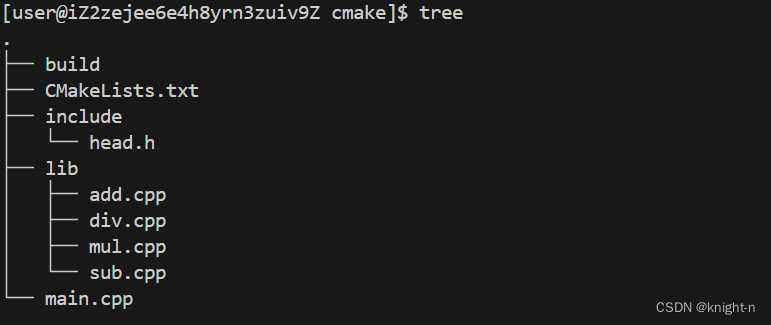
在 CMakeLists.txt 中我们删除add_executable,添加add_library生成静态库。
我们执行cmake命令
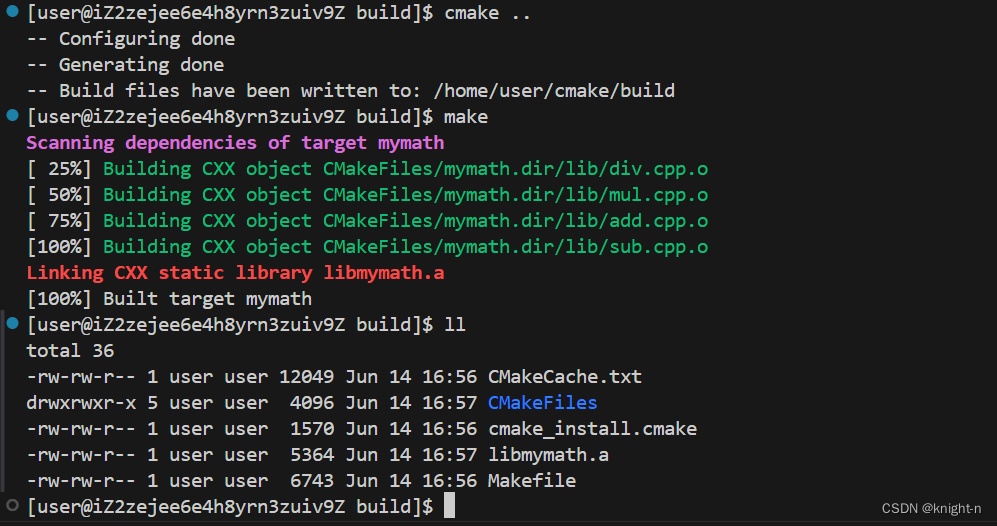
可以看到build 目录下成功生成了静态库文件 libmymath.a 。
生成动态库
生成静态库需要用到命令 add_library 只需将第二个参数由STATIC改为SHARED。我们修改CMakeLists.txt。与静态库相同命令只需要指出名字中间部分

执行cmake命令并编译。
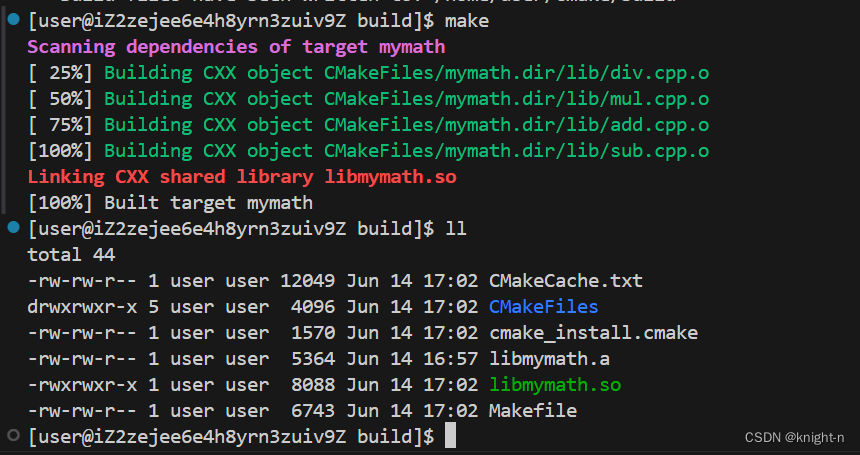
可以看到build 目录下成功生成了动态库文件 libmymath.so 。
指定库文件的输出路径
指定库文件的输出路径有两种方法:设置 EXECUTABLE_OUTPUT_PATH 指定输出路径,设置 LIBRARY_OUTPUT_PATH 指定输出路径。
使用 EXECUTABLE_OUTPUT_PATH 指定输出路径只对动态库有效,因为Linux下生成的动态库默认是有执行权限的,而静态库没有。
我们在这只演示通过 LIBRARY_OUTPUT_PATH 指定输出路径。
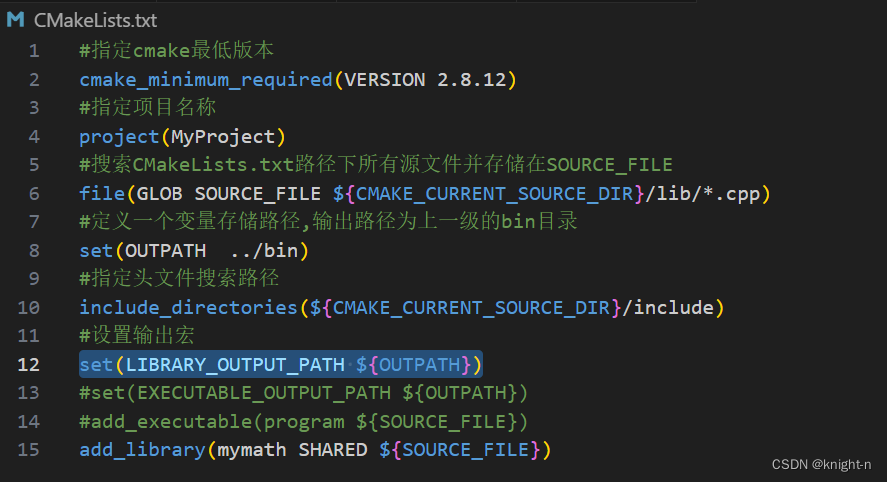
我们执行cmake并编译。
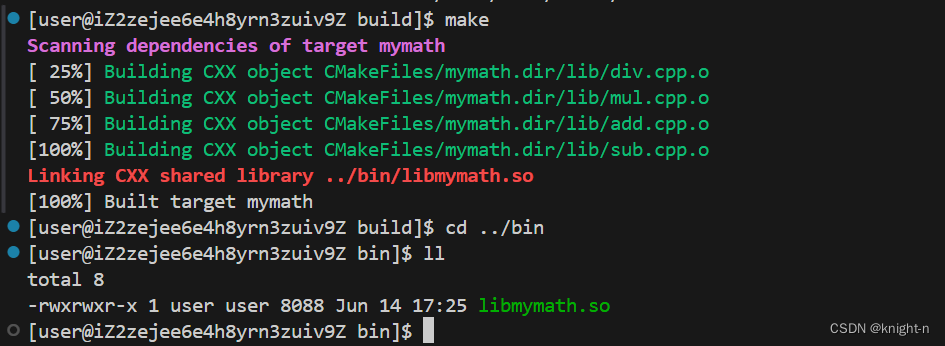
可以看到库文件被成功生成到指定的目录下。
4.2 链接动静态库
cmake 链接库的命令为target_link_libraries 。target_link_libraries 可以链接动态库与静态库。
target_link_libraries(<target> <PRIVATE|PUBLIC|INTERFACE> <item>...)- <target>:要链接库的目标名称,可以是可执行文件或库。
- <PRIVATE|PUBLIC|INTERFACE>:指定链接库的可见性:PRIVATE:链接库仅对当前目标有效,不会传递给依赖该目标的其他目标。 PUBLIC:链接库对当前目标及其依赖者都有效,链接属性会传递给依赖该目标的其他目标。 INTERFACE:指定仅对依赖该目标的其他目标可见的接口链接库,不包括其实现细节。
- <item>...:一个或多个库的名称或目标名称,可以是库文件的路径、目标名称,或者是使用 find_package 或 find_library 找到的库名称。
关于可见性问题可能不太好理解,我们举例说明。现在有以下CMake命令
# 库A依赖B和C
target_link_libraries(A PUBLIC B PUBLIC C)
# 动态库D链接库A
target_link_libraries(D PUBLIC A)在这个例子中:
- A链接了B和C,并且使用了PUBLIC关键字,所以任何链接到A的库(包括D)也会链接B和C。
- 由于D链接了A,并且同样使用了PUBLIC关键字,D的任何依赖者也将链接A、B和C。
如果将PUBLIC更改为PRIVATE或INTERFACE,链接行为将相应改变:
- 使用PRIVATE,D将链接A,但D的依赖者不会链接A、B或C。
- 使用INTERFACE,D将不会链接A的实际实现,但D的依赖者将能够使用A定义的接口。
如果target_link_libraries 。target_link_libraries 链接的是第三方库,需要用 link_directories 指定库所在的路径。
link_directories(<libpath>)现在我们调整工程结构如下。
我们链接lib中的 libmymath.so 。向 CMakeLists.txt 中添加以下命令:
link_directories(${CMAKE_CURRENT_SOURCE_DIR}/lib)
target_link_libraries(program libmymath.so)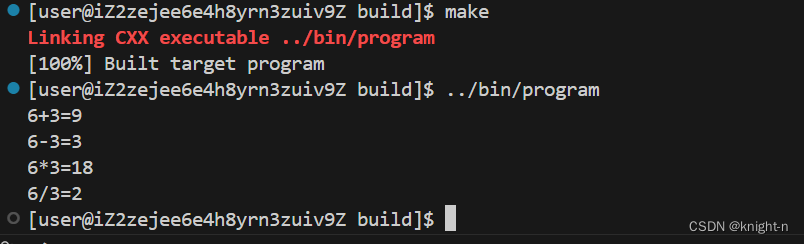
我们执行cmake命令并编译
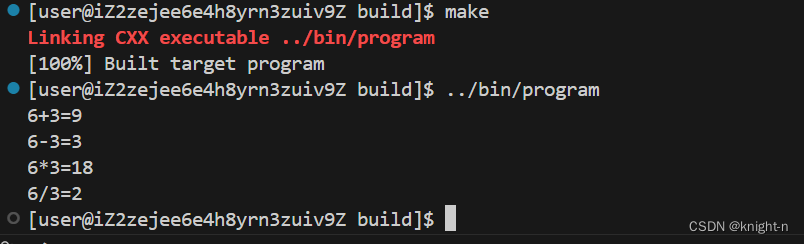
可以看到程序成功运行。需要注意的是 target_link_libraries 。target_link_libraries 命令需要写在生成目标文件之后。
4.3 日志
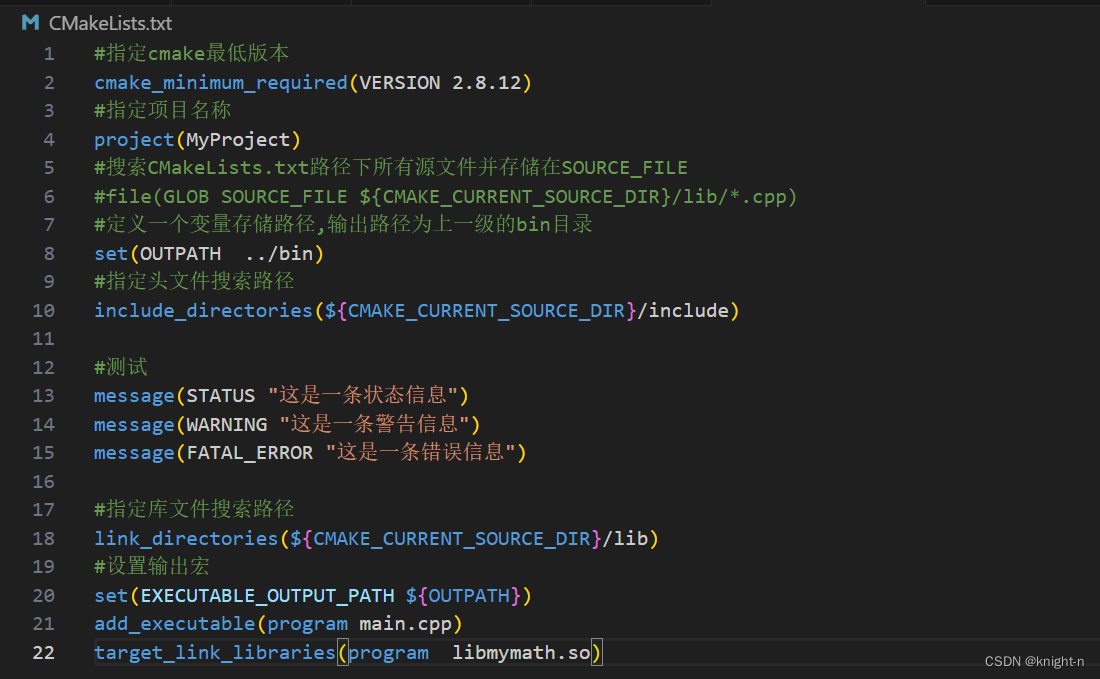
在CMake中,我们可以使用message命令记录日志或输出信息到控制台。这个命令允许输出不同级别的信息,包括普通消息、警告和错误。
message([STATUS|WARNING|AUTHOR_WARNING|FATAL_ERROR|SEND_ERROR] "message")- STATUS:显示状态消息,通常不是很重要。
- WARNING:显示警告消息,编译过程会继续执行。
- AUTHOR_WARNING:显示作者警告消息,用于开发过程中,编译过程会继续执行。
- FATAL_ERROR:显示错误消息,终止所有处理过程。
- SEND_ERROR:显示错误消息,但继续执行,会跳过生成步骤。
CMake的命令行工具会在stdout上显示STATUS消息,在stderr上显示其他所有消息。
我们简单测试一下。
执行cmake命令
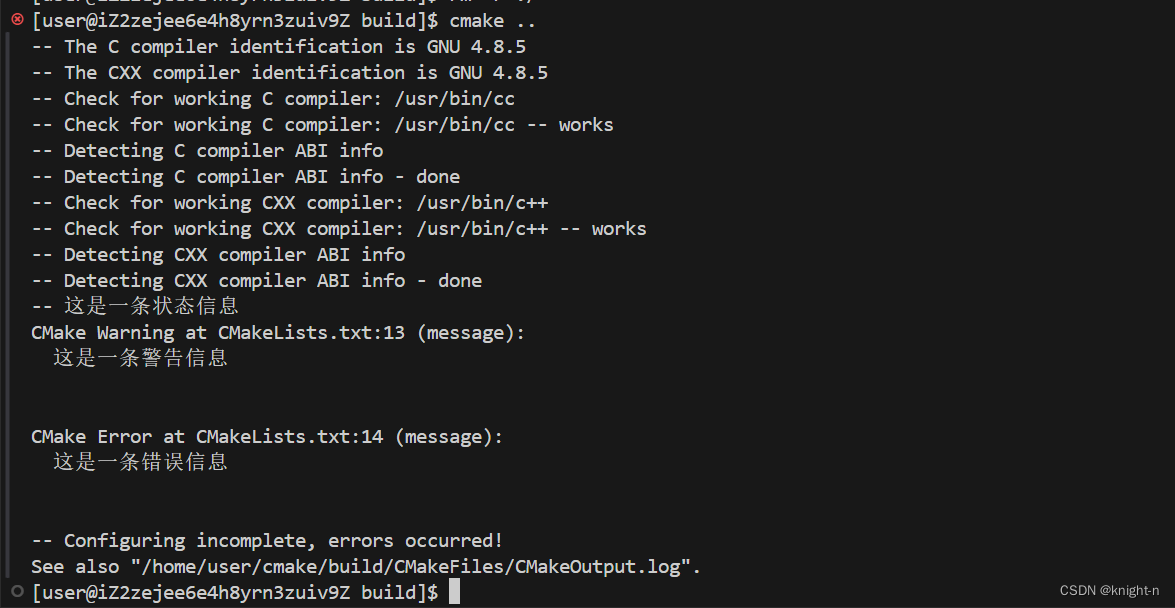
可以看到信息正常输出,在输出错误信息后编译终止。
4.4 变量操作
在在CMake中,所有的变量都为字符串类型,变量操作实际上也是字符串操作。CMake提供了多种命令来操作这些字符串变量。
拼结变量
拼接字符串可以通过 list 命令与 set 命令进行。
#使用set进行拼接
set(变量名1 ${变量名1} ${变量名2} ...)
#示例使用
set(variables1 ${variables1} ${variables2})我们简单演示一下,并使用 message 输出。
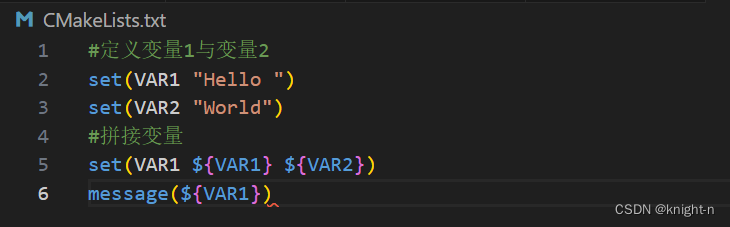
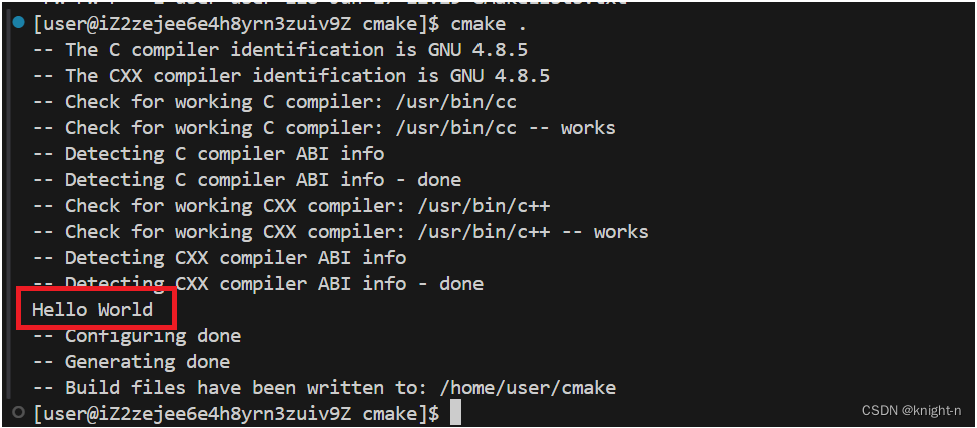
可以看到成功输出。
使用 list 命令拼接变量
#语法
list(APPEND 变量名1 ${变量名2} ...)
#示例使用
list(APPEND variables1 ${variables2})我们简单演示一下 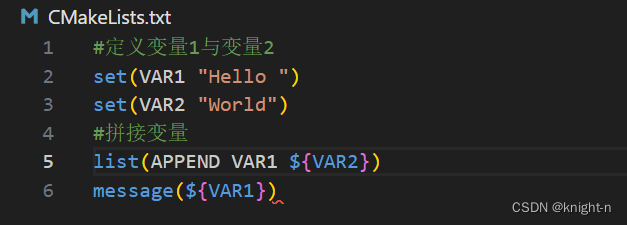
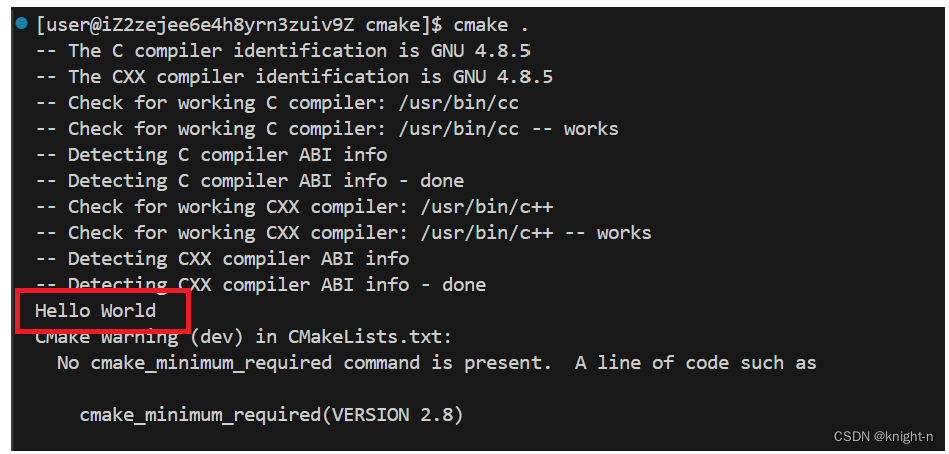
移除字符串
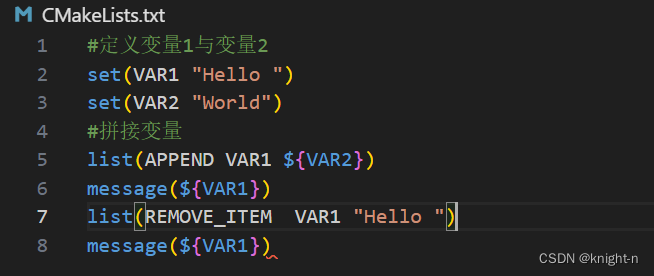
有时候我们需要从变量中移除字串这时候我们可以也使用 list
#语法
list(REMOVE_ITEM 变量名 要移除的子串)
#示例
list(REMOVE_ITEM VAR "Hello ")我们简单演示一下
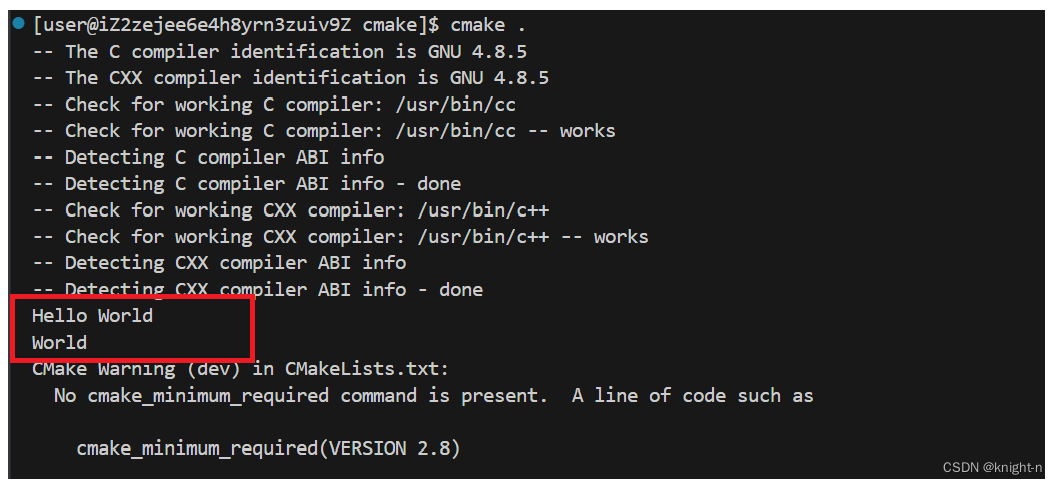
list 命令还有许多用法我们这里不再一 一演示。
创建和初始化列表:
set(MY_LIST item1 item2 item3)追加元素(
list(APPEND ...)):
list(APPEND MY_LIST "new_item1" "new_item2")插入元素(
list(INSERT ...)):
list(INSERT MY_LIST 1 "item1.5") # 在位置1插入元素移除元素(
list(REMOVE_ITEM ...)):
list(REMOVE_ITEM MY_LIST "item2")移除指定索引的元素(
list(REMOVE_AT ...)):
list(REMOVE_AT MY_LIST 1) # 移除索引为1的元素获取列表长度(
list(LENGTH ...)):
list(LENGTH MY_LIST LENGTH_OF_LIST)获取特定索引的元素(
list(GET ...)):
list(GET MY_LIST 0 FIRST_ITEM)设置特定索引的元素:
list(SET MY_LIST 1 "new_item2") # 设置索引为1的元素连接列表元素为字符串(
list(JOIN ...)):
list(JOIN MY_LIST ", " JOINED_STRING)分割字符串为列表(
string(REPLACE ...)与list(APPEND ...)结合使用):
string(REPLACE "," ";" MY_LIST "${SOME_STRING}")查找元素(
list(FIND ...)):
list(FIND MY_LIST "item1" INDEX)反转列表(
list(REVERSE ...)):
list(REVERSE MY_LIST)排序列表(
list(SORT ...)):
list(SORT MY_LIST) # 默认升序排序复制列表(
list(COPY ...)):
list(COPY MY_LIST COPY_OF_MY_LIST)清除列表(
list(CLEAR ...)):
list(CLEAR MY_LIST)
4.5 定义宏
在CMake中,宏主要分为两种:CMake脚本中的宏和C++源代码中通过CMake定义的条件编译宏。
条件编译宏
进行程序测试的时候,我们可以在代码中添加宏定义,通过宏来控制这些代码是否生效:
#include<iostream>
int main()
{
#ifdef DEBUG
std::cout<< "DEBUG" << std::endl;
#endif
#ifndef DEBUG
std::cout<< "NDEBUG" << std::endl;
#endif
return 0;
}我们可以在CMake脚本中定义条件编译宏 。命令为 add_definitions 。
#定义宏
add_definitions(-D宏名称)
#定义宏并赋值
add_definitions(-DDEBUG=1)我们修改 CMakeLists.txt 并简单测试
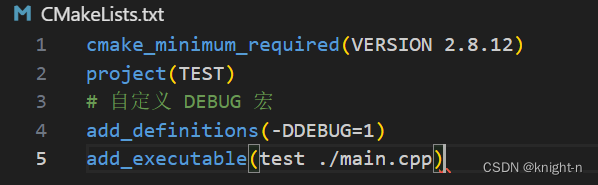
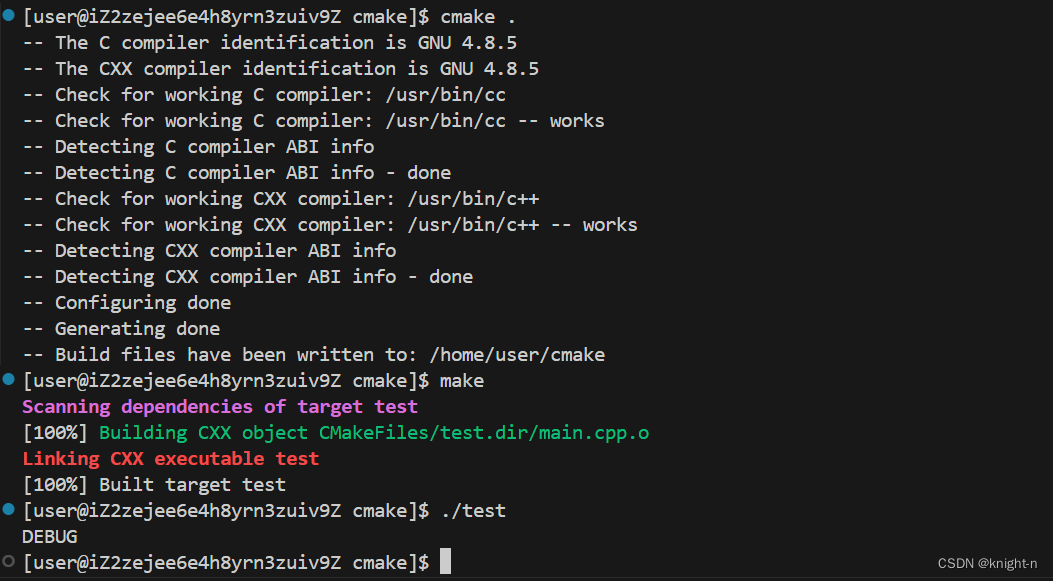
可以看到成功定义了DEBUG。
CMake中的宏
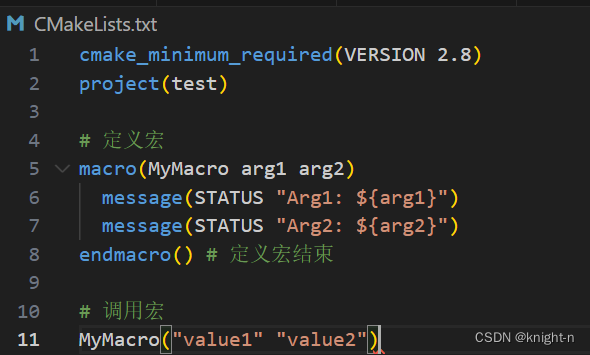
CMake中的宏是一系列可以被多次调用的CMake命令,可以接收参数,类似于函数。用于封装重复使用的构建逻辑。我们可以使用 macro 和 endmacro 命令定义宏。宏在定义它们的CMake文件中全局可见。
macro(MyMacro arg1 arg2) #定义宏
message(STATUS "Arg1: ${arg1}")
message(STATUS "Arg2: ${arg2}")
endmacro() #定义宏结束
# 调用宏
MyMacro(value1 value2)简单演示一下

5. CMake精通
到这里相信你已经掌握了CMake的基础用法,下面让我们进一步学习CMake的使用。
5.1 CMake的嵌套
当我们的项目很大时,项目中会有很多的源码目录,如果只使用一个CMakeLists.txt,会比较复杂,我们可以给每个源码目录都添加一个CMakeLists.txt文件,这样每个文件都不会太复杂,而且更灵活,更容易维护。
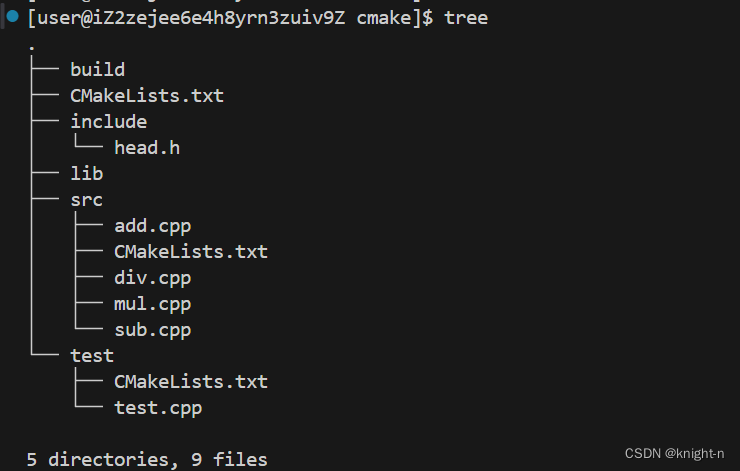
在这个工程中我们有五个目录,我们在 build 目录下执行CMake命令。在src下我们生成一个动态库,在test目录下我们链接动态库生成一个可执行文件。
嵌套的CMake是一个树状结构,最顶层的 CMakeLists.txt 是根节点,其次是子节点。我们需要使用 add_subdirectory() 命令在结点间建立父子关系。
add_subdirectory(source_dir [binary_dir] [EXCLUDE_FROM_ALL])- source_dir:要添加的子目录的路径,相对于当前 CMakeLists.txt 文件的路径。
- binary_dir(可选):构建输出的目录,如果未指定,CMake 会使用 source_dir 作为构建目录。
- EXCLUDE_FROM_ALL(可选):如果指定,该子目录的构建目标不会包含在 all 目标中,即默认情况下不会在调用 make 时构建。
后两项我们通常用不到可以忽略,在建立关系后,父节点的变量可以被子节点继承,执行cmake命令时,也会一起处理。
下面我们来编写根目录的 CMakeLists.txt ,这里只需要定义一下工程名称,最低版本,建立父子关系,定义一些变量即可。
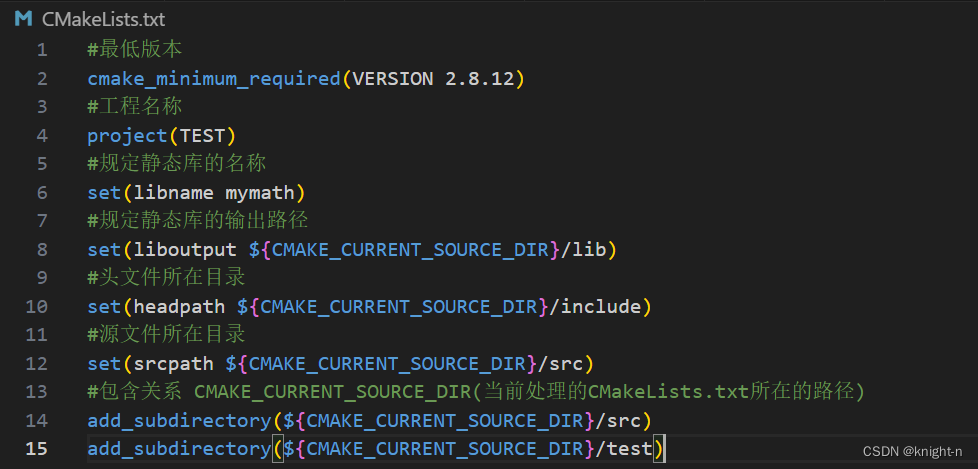
下面我们编写 src 下的 CMakeLists.txt,在这部分我们需要生成一个动态库并输出到lib目录下。
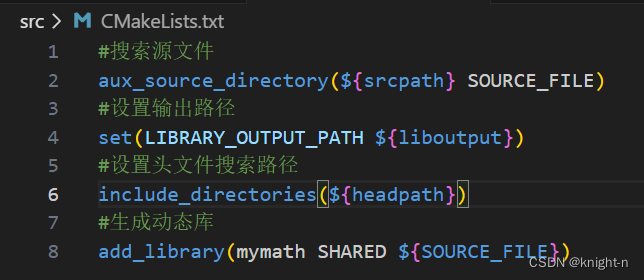
在 test 下的 CMakeLists.txt ,我们需要链接动态库生成可执行文件。
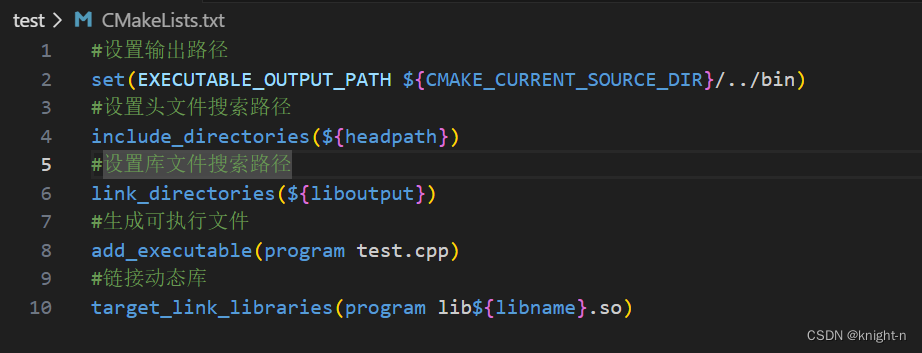
现在我们完成了准备工作,我们在build目录下执行cmake命令。
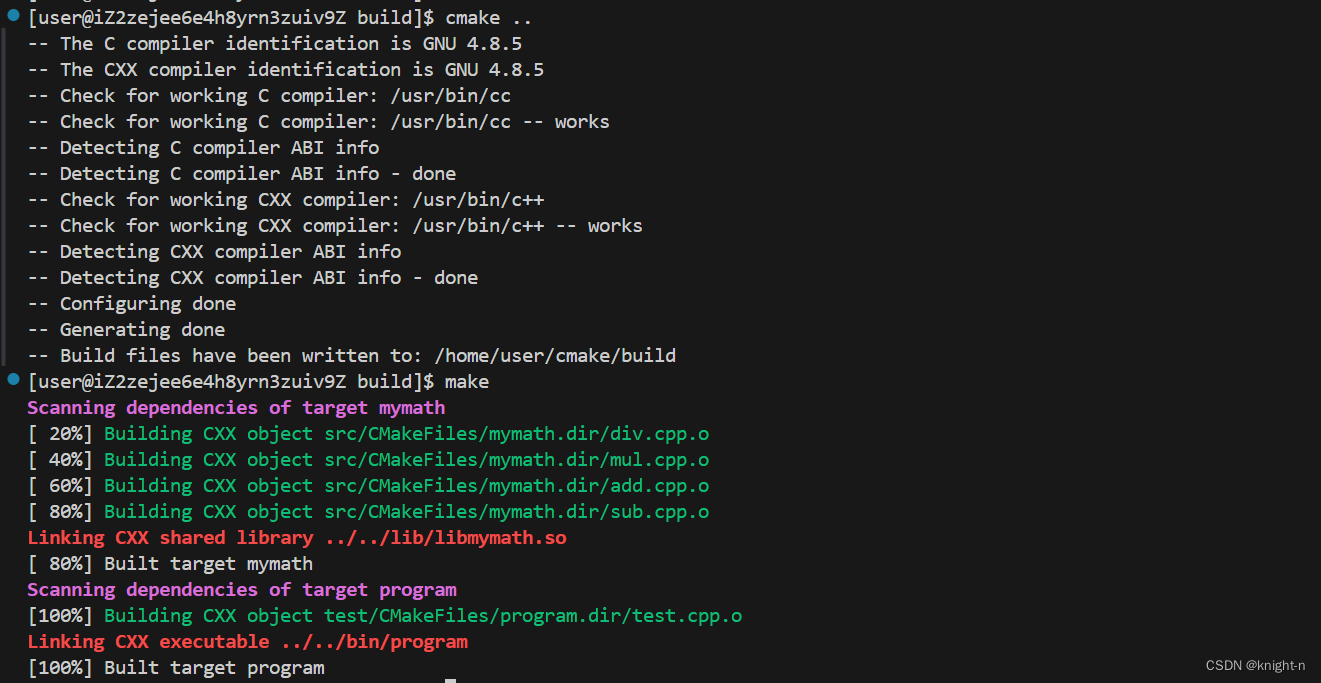

可以看到程序成功运行。
5.2 条件判断
cmake下的条件判断与C语言基本类似。不同的是cmake需要使用endif() 结束 if 语句块
if(条件1)
# 条件为真时执行的命令
elseif(条件2)
# 条件为真时执行的命令
else()
# 没有条件为真时执行的命令
endif()条件主要包括以下种类:
- 变量:检查变量是否存在或其值是否符合特定条件。
- 平台:根据操作系统、编译器等平台特性进行判断。
- 文件和目录:检查文件或目录是否存在。
- 逻辑运算:使用逻辑运算符来组合多个条件。
变量
变量的判断有以下关键字:DEFINED、EXISTS、IS_DIRECTORY
DEFINED:DEFINED 用于检查变量是否已经被定义。它不检查变量的值,只检查变量是否存在。
if(DEFINED MY_VARIABLE)
message(STATUS "MY_VARIABLE is defined.")
endif()EXISTS: EXISTS 用于检查文件或目录是否存在。接受一个路径作为参数,并返回一个布尔值。
if(EXISTS "${CMAKE_SOURCE_DIR}/somefile.txt")
message(STATUS "The file somefile.txt exists.")
endif()IS_DIRECTORY: IS_DIRECTORY 用于检查给定的路径是否是一个目录。如果路径是一个存在的目录,返回布尔值。
if(IS_DIRECTORY "${CMAKE_SOURCE_DIR}/somedir")
message(STATUS "The path somedir is a directory.")
endif()逻辑运算
CMake 支持AND, OR, NOT 逻辑运算符来进行更复杂的条件判断。
- AND(同C语言 && ):逻辑与。两个条件都必须为真,整个表达式才为真。
- OR(同C语言 || ):逻辑或。两个条件中至少有一个为真,整个表达式就为真。
- NOT(同C语言 ! ):逻辑非。反转条件的真假。
平台
平台判断包括检查操作系统、编译器、架构,我们这里主要介绍操作系统判断。
CMake 提供了一些预定义的变量来标识操作系统类型,例如 WIN32, UNIX, 和 APPLE。
if(WIN32)
message(STATUS "Windows") //Windows
elseif(UNIX)
message(STATUS "Unix") //Linux
elseif(APPLE)
message(STATUS "macOS") //苹果
endif()比较
条件判断必不可少涉及到比较。我们这里介绍数值比较与字符串比较。
数值比较:
-
LESS <: 检查左侧是否小于右侧。
-
GREATER >: 检查左侧是否大于右侧。
-
EQUAL ==: 检查两侧是否数值相等。
-
NOTEQUAL !=: 检查两侧是否数值不相等。
字符串比较:
- STRLESS: 字符串是否字典序较小。
- STRGREATER: 字符串是否字典序较大。
- STREQUAL: 字符串是否相等。
- NOT STREQUAL: 字符串是否不相等。
# 定义变量
set(a 10)
set(b 20)
# 数值比较
if(a LESS b)
message("a<b")
endif()
if(a EQUAL 10)
message("a=10")
endif()
# 字符串比较
if(a STREQUAL "10")
message("a = '10'")
endif()
算术运算
同样在循环与条件判断中算数运算必不可少,cmake为我们提供 math 命令用于执行算术运算。
加法:
set(counter 1) math(EXPR counter "${counter} + 1") # counter 现在是 2减法:
set(counter 5) math(EXPR counter "${counter} - 2") # counter 现在是 3乘法:
set(counter 3) math(EXPR counter "${counter} * 2") # counter 现在是 6除法:
set(counter 20) math(EXPR counter "${counter} / 4") # counter 现在是 5模运算:
set(counter 7) math(EXPR counter "${counter} % 3") # counter 现在是 1使用变量:
set(a 10)
set(b 3)
math(EXPR result "${a} * ${b}") # result 是 305.3 循环
CMake中的循环分为两种,foreach 循环和 while 循环。
foreach 循环
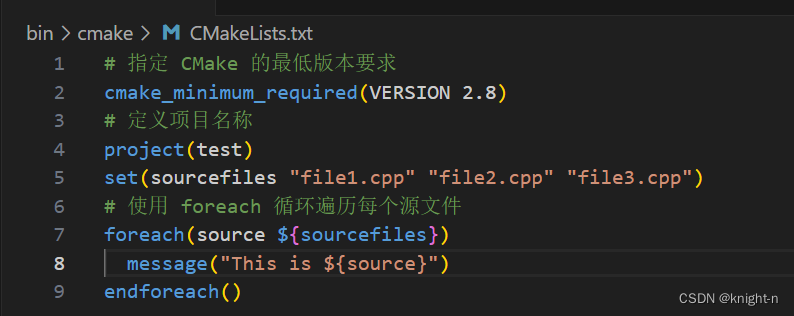
foreach循环的基本语法如下:
foreach(<variable> IN <list>)
# 命令
endforeach()- <variable>:这是循环变量,每次迭代都会赋予它列表中的一个元素。
- <list>:这是要遍历的元素列表,可以是列表、数组或任何可迭代的对象。
示例使用
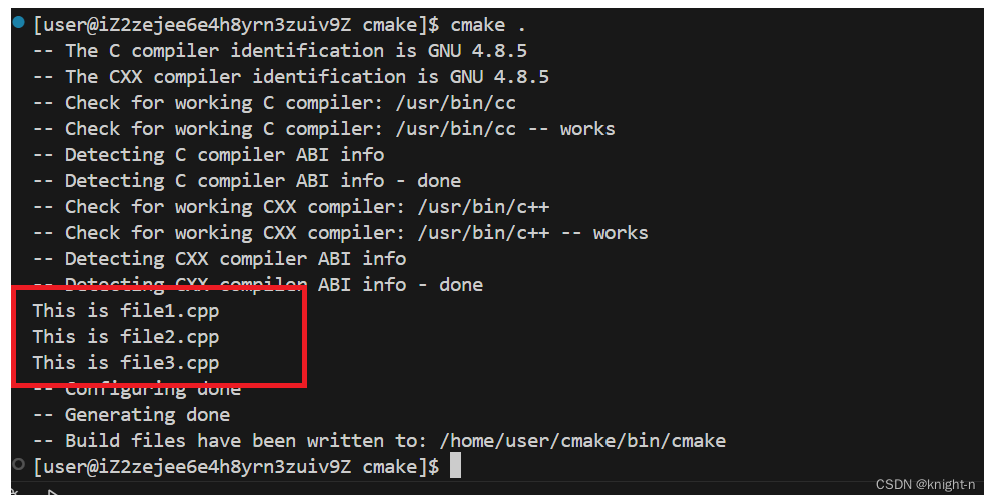
while循环
while循环比较简单,只需要指定出循环结束的条件。
while(<condition>)
# 命令序列
endwhile()这里的 <condition> 是一个布尔表达式,每次循环迭代开始时都会进行判断。只要条件为真,循环就会继续执行。一旦条件为假,循环就会终止。
示例使用

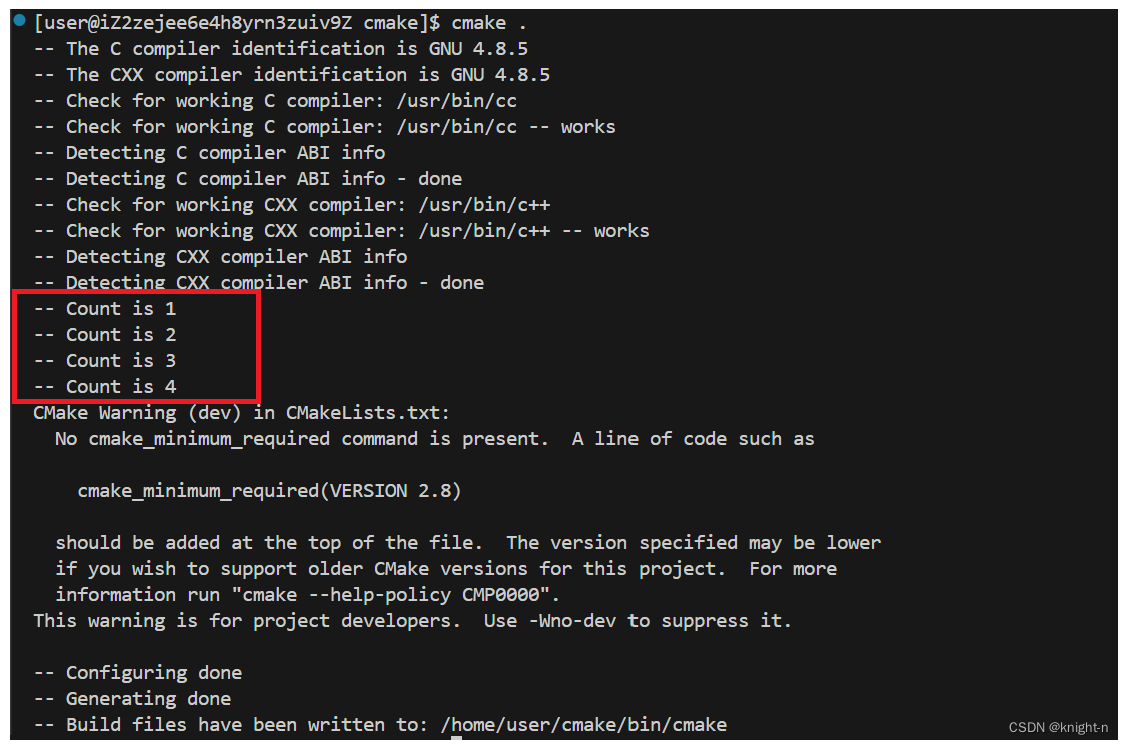
结语
到这里我们已经完成了CMake的学习。笔者能力有限,如有错漏之处,欢迎指正。同时很多命令语法只是讲了基础用法,如果有读者想要深入研究可以参考CMake的官方文档。制作不易,求点赞关注。