day8
笔记来源于:黑马程序员python教程,8天python从入门到精通,学python看这套就够了
目录
- day8
- 58、数据容器(序列)的切片
- 序列的常用操作——切片
- 59、序列的切片课后练习
- 60、集合的定义和操作
- 集合的定义
- 集合的操作
- 添加新元素
- 移除元素
- 从集合中随机取出元素
- 清空集合
- 取出2个集合的差集
- 消除2个集合的差集
- 2个集合合并
- 查看集合的元素数量
- 集合的常用操作——for循环遍历
- 集合的常用功能总结
- 集合的特点
- 61、集合的课后练习
- 62、字典的定义
- 字典数据的获取
- 字典的嵌套
- 嵌套字典的内容获取
- 字典的注意事项
- 63、字典的常用操作
- 新增元素
- 更新元素
- 删除元素
- 清空字典
- 获取全部的key
- 遍历字典
- 计算字典内的全部元素(键值对)数量
- 字典的常用操作总结
- 字典的特点
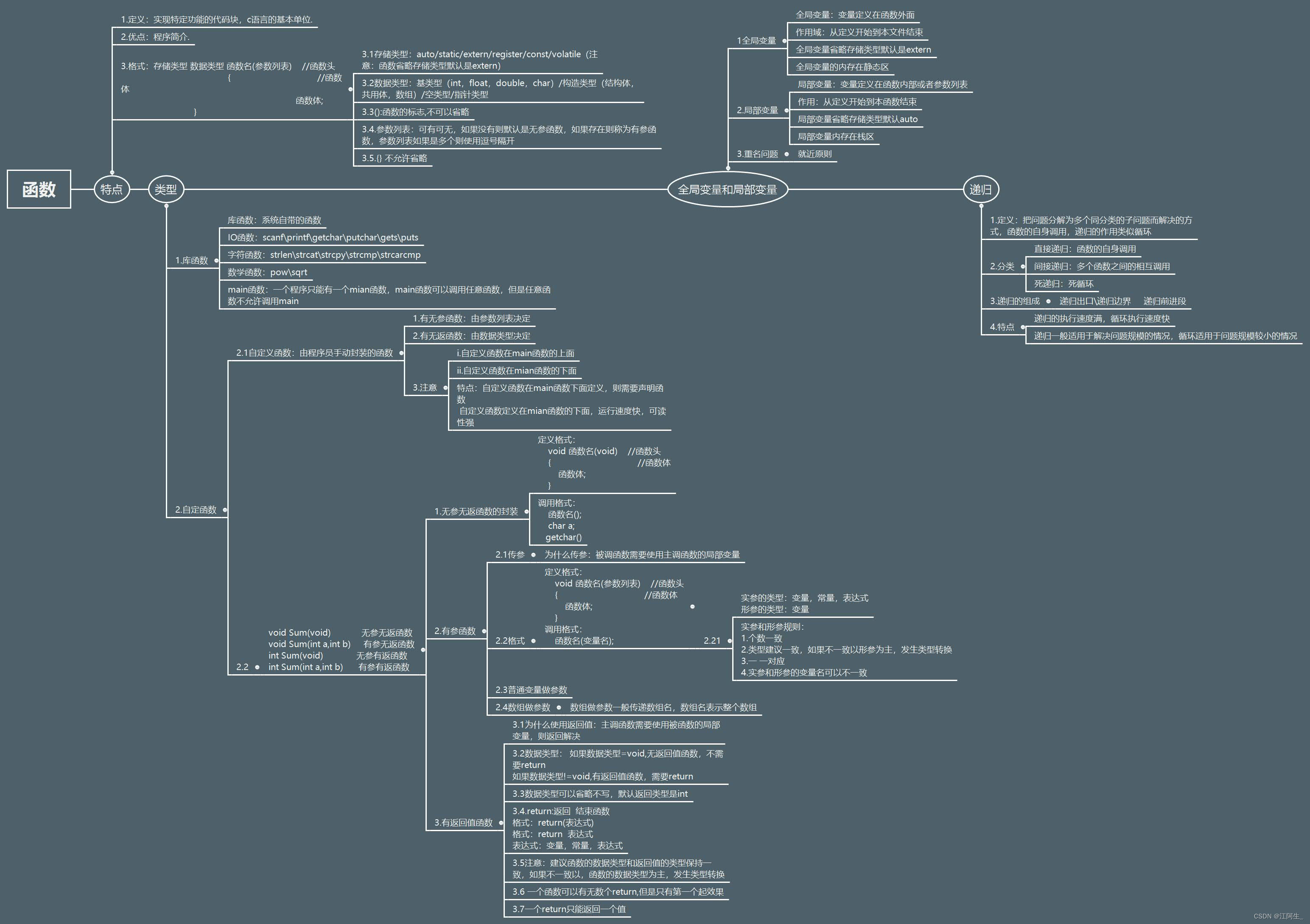
58、数据容器(序列)的切片
序列是指:内容连续、有序,可使用下标索引的一类数据容器。列表、元组、字符串,均可以可以视为序列。


序列的常用操作——切片
序列支持切片,即:列表、元组、字符串,均支持进行切片操作
切片:从一个序列中,取出一个子序列
语法:序列[起始下标:结束下标:步长]
表示从序列中,从指定位置开始,依次取出元素,到指定位置结束,得到一个新序列:
- 起始下标表示从何处开始,可以留空,留空视作从头开始
- 结束下标(不含)表示何处结束,可以留空,留空视作截取到结尾
- 步长表示,依次取元素的间隔
- 步长 1 表示,一个个取元素;
- 步长 2 表示,每次跳过 1 个元素取;
- 步长 N 表示,每次跳过 N-1 个元素取;
- 步长为负数表示,反向取(注意,起始下标和结束下标也要反向标记)
注意,此操作不会影响序列本身,而是会得到一个新的序列(列表、元组、字符串)
示例:
"""
演示对序列进行切片操作
"""
# 对 list 进行切片,从 1 开始, 4 结束,步长为 1
my_list = [0, 1, 2, 3, 4, 5, 6]
result1 = my_list[1:4] # 步长默认是1,所以可以省略不写
print(f"结果1:{result1}")
# 对 tuple 进行切片,从头开始,到最后结束,步长为 1
my_tuple = (0, 1, 2, 3, 4, 5, 6)
result2 = my_tuple[:] # 起始和结束不写表示从头到尾,步长为 1 可以省略
print(f"结果2:{result2}")
# 对 str 进行切片,从头开始,到最后结束,步长为 2
my_str = "01234567"
result3 = my_str[::2]
print(f"结果3:{result3}")
# 对 str 进行切片,从头开始,到最后结束,步长为 2
my_str = "01234567"
result4 = my_str[::-1] # 等同于将序列反转了
print(f"结果4:{result4}")
# 对列表进行 my_list = [0, 1, 2, 3, 4, 5, 6] 切片,从 3 开始,到 1 结束,步长 -1
my_list = [0, 1, 2, 3, 4, 5, 6]
result5 = my_list[3:1:-1]
print(f"结果5:{result5}")
# 对元组进行切片,从头开始,到尾结束,步长 -2
my_tuple = (0, 1, 2, 3, 4, 5, 6)
result6 = my_tuple[::-2]
print(f"结果6:{result6}")
59、序列的切片课后练习

# 方法1
mystr1 = "万过薪月,员序程马黑来,nohtyP学"
mystr2 = mystr1[::-1]
print(mystr2)
mystr3 = mystr2.split(",")
print(mystr3)
mystr4 = mystr3[1]
print(mystr4)
result = mystr4[1::1]
print(result)
# 方法2:
mystr1 = "万过薪月,员序程马黑来,nohtyP学"
result2 = mystr1.split(",")[1].replace("来","")[::-1]
print(result2)
60、集合的定义和操作
集合的定义
通过特性来分析:
- 列表可修改、支持重复元素且有序
- 元组、字符串不可修改、支持重复元素且有序
局限就在于:它们都支持重复元素。
如果场景需要对内容做去重处理,列表、元组、字符串就不方便了。
而集合,最主要的特点就是:不支持元素的重复(自带去重功能)、并且内容无序
基本语法格式:

示例:
# 定义集合
my_set = {"传智教育", "黑马程序员", "itheima","传智教育", "黑马程序员", "itheima","传智教育", "黑马程序员", "itheima"}
my_set_empty = set() # 定义空集合
print(f"my_set的内容是:{my_set},类型是:{type(my_set)}")
print(f"my_set_empty的内容是:{my_set_empty},类型是:{type(my_set_empty)}")
# 结果
my_set的内容是:{'传智教育', 'itheima', '黑马程序员'},类型是:<class 'set'>
my_set_empty的内容是:set(),类型是:<class 'set'>
和列表、元组、字符串等定义基本相同:
- 列表使用:[]
- 元组使用:()
- 字符串使用:“”
- 集合使用:{}
集合的操作
因为集合是无序的,所以集合不支持:下标索引访问
添加新元素
语法:集合.add(元素)。将指定元素,添加到集合内
结果:集合本身被修改,添加了新元素
示例:
# 添加新元素
my_set = {"传智教育", "黑马程序员", "itheima"}
my_set.add("Python")
my_set.add("传智教育")
print(f"my_set添加元素后结果是:{my_set}")
# 结果
my_set添加元素后结果是:{'传智教育', 'itheima', 'Python', '黑马程序员'}
tips:注意到添加已有元素,并不会重复出现在集合里
移除元素
语法:集合.remove(元素),将指定元素,从集合内移除
结果:集合本身被修改,移除了元素
示例:
# 移除元素
my_set = {"传智教育", "黑马程序员", "itheima"}
my_set.remove("黑马程序员")
print(f"my_set移除元素后结果是:{my_set}")
# 结果
my_set移除元素后结果是:{'传智教育', 'itheima'}
从集合中随机取出元素
语法:集合.pop(),功能,从集合中随机取出一个元素
结果:会得到一个元素的结果。同时集合本身被修改,元素被移除
示例:
# 随机取一个元素
my_set = {"传智教育", "黑马程序员", "itheima"}
element = my_set.pop()
print(f"集合被取出元素是:{element},取出元素后:{my_set}")
# 结果
集合被取出元素是:传智教育,取出元素后:{'itheima', '黑马程序员'}
清空集合
语法:集合.clear(),功能,清空集合
结果:集合本身被清空
示例:
# 清空集合
my_set = {"传智教育", "黑马程序员", "itheima"}
my_set.clear()
print(f"集合被清空啦,结果是:{my_set}")
# 结果
集合被清空啦,结果是:set()
取出2个集合的差集
语法:集合1.difference(集合2),功能:取出集合1和集合2的差集(集合1有而集合2没有的)
结果:得到一个新集合,集合1和集合2不变
# 取 2 个集合的差集
set1 = {1, 2, 3}
set2 = {1, 5, 6}
set3 = set1.difference(set2)
print(f"取出差集后的结果是:{set3}")
print(f"取出差集后,原有的set1的内容是:{set1}")
print(f"取出差集后,原有的set3的内容是:{set2}")
# 结果
取出差集后的结果是:{2, 3}
取出差集后,原有的set1的内容是:{1, 2, 3}
取出差集后,原有的set3的内容是:{1, 5, 6}
消除2个集合的差集
语法:集合1.difference_update(集合2)
功能:对比集合1和集合2,在集合1内,删除和集合2相同的元素。
结果:集合1被修改,集合2不变
# 消除 2 个集合的差集
set1 = {1, 2, 3}
set2 = {1, 5, 6}
set1.difference_update(set2)
print(f"消除差集后,集合1结果:{set1}")
print(f"消除差集后,集合2结果:{set2}")
# 结果
消除差集后,集合1结果:{2, 3}
消除差集后,集合2结果:{1, 5, 6}
2个集合合并
语法:集合1.union(集合2)
功能:将集合1和集合2组合成新集合
结果:得到新集合,集合1和集合2不变
# 2 个集合合并为 1 个
set1 = {1, 2, 3}
set2 = {1, 5, 6}
set3 = set1.union(set2)
print(f"2集合合并结果:{set3}")
print(f"合并后集合1:{set1}")
print(f"合并后集合2:{set2}")
# 结果
2集合合并结果:{1, 2, 3, 5, 6}
合并后集合1:{1, 2, 3}
合并后集合2:{1, 5, 6}
查看集合的元素数量
语法:len(集合)
功能:统计集合内有多少元素
结果:得到一个整数结果
# 统计集合元素数量 len()
set1 = {1, 2, 3, 4, 5, 1, 2, 3, 4, 5}
num = len(set1)
print(f"集合内的元素数量有:{num}个")
# 结果
集合内的元素数量有:5个
集合的常用操作——for循环遍历
tips:集合不支持下标索引,所以也就不支持使用 while 循环。
# 集合的遍历
# 集合不支持下标索引,不能用 while 循环
# 可以用 for 循环
set1 = {1, 2, 3, 4, 5}
for element in set1:
print(f"集合的元素有:{element}")
集合的常用功能总结
| 编号 | 操作 | 说明 |
|---|---|---|
| 1 | 集合.add(元素) | 集合内添加一个元素 |
| 2 | 集合.remove(元素) | 移除集合内指定的元素 |
| 3 | 集合.pop() | 从集合中随机取出一个元素 |
| 4 | 集合.clear() | 将集合清空 |
| 5 | 集合1.difference(集合2) | 得到一个新集合,内含2个集合的差集 原有的2个集合内容不变 |
| 6 | 集合1.difference_update(集合2) | 在集合1中,删除集合2中存在的元素 集合1被修改,集合2不变 |
| 7 | 集合1.union(集合2) | 得到1个新集合,内含2个集合的全部元素 原有的2个集合内容不变 |
| 8 | len(集合) | 得到一个整数,记录了集合的元素数量 |
集合的特点
- 可以容纳多个数据;
- 可以容纳不同类型的数据(混装);
- 数据是无序存储的(不支持下标索引);
- 不允许重复数据存在;
- 可以修改(增加或删除元素等);
- 支持for循环。
61、集合的课后练习

示例:
my_list = ['黑马程序员', '传智播客', '黑马程序员', '传智播客', 'itheima', 'itcast', 'itheima', 'itcast', 'best']
my_set = set()
for element in my_list:
my_set.add(element)
print(f"存入集合后,集合结果为:{my_set}")
62、字典的定义
字典可以实现用 key 取出 Value 的操作
字典数据的获取
字典同集合一样,不可以使用下标索引;
但是字典可以通过 Key值 来取得对应的 Value
# 定义字典
my_dict1 = {"王力宏" : 99, "周杰伦" : 88, "林俊杰" : 77}
# 定义空的字典
my_dict2 = {} # 集合不能使用 my_set = {}, 只能使用 my_set = set()
my_dict3 = dict()
print(f"字典1的内容是:{my_dict1},类型:{type(my_dict1)}")
print(f"字典2的内容是:{my_dict2},类型:{type(my_dict2)}")
print(f"字典3的内容是:{my_dict3},类型:{type(my_dict3)}")
# 定义重复 key 的字典
my_dict1 = {"王力宏" : 99, "王力宏" : 88, "林俊杰" : 77}
print(f"重复 key 的字典的内容是:{my_dict1}")
# 从字典中基于 Key 获取 Value
my_dict1 = {"王力宏" : 99, "周杰伦" : 88, "林俊杰" : 77}
score = my_dict1["王力宏"]
print(f"王力宏的考试分数是:{score}")
score = my_dict1["周杰伦"]
print(f"周杰伦的考试分数是:{score}")
# 结果
字典1的内容是:{'王力宏': 99, '周杰伦': 88, '林俊杰': 77},类型:<class 'dict'>
字典2的内容是:{},类型:<class 'dict'>
字典3的内容是:{},类型:<class 'dict'>
重复 key 的字典的内容是:{'王力宏': 88, '林俊杰': 77}
王力宏的考试分数是:99
周杰伦的考试分数是:88
tips:定义重复的 key,后出现的 key 所对应的 value 会覆盖掉前者的 value
字典的嵌套

示例:
# 定义嵌套字典
stu_score_dict = {
"wanglihonh" : {
"yuwen" : 77,
"shuxue" : 66,
"yingyu" : 33
},
"zhoujielun" : {
"yuwen" : 88,
"shuxue" : 86,
"yingyu" : 55
},
"linjunjie" : {
"yuwen" : 99,
"shuxue" : 96,
"yingyu" : 66
}
}
print(f"学生的考试信息是:{stu_score_dict}")
# 结果
学生的考试信息是:{'wanglihonh': {'yuwen': 77, 'shuxue': 66, 'yingyu': 33}, 'zhoujielun': {'yuwen': 88, 'shuxue': 86, 'yingyu': 55}, 'linjunjie': {'yuwen': 99, 'shuxue': 96, 'yingyu': 66}}
嵌套字典的内容获取
# 从嵌套字典中获取信息
# 看一下周杰伦的语文信息
score = stu_score_dict["zhoujielun"]["yuwen"]
print(f"zhoujielun的yuwen考试分数是:{score}")
score = stu_score_dict["linjunjie"]["yingyu"]
print(f"linjunjie的yingyu考试分数是:{score}")
字典的注意事项
- 键值对的Key和Value可以是任意类型(Key不可为字典);
- 字典内Key不允许重复,重复添加等同于覆盖原有数据;
- 字典不可用下标索引,而是通过Key检索Value。
63、字典的常用操作
新增元素
语法:字典[Key] = Value,结果:字典被修改,新增了元素
my_dict = {"王力宏" : 99, "周杰伦" : 88, "林俊杰" : 77}
# 新增元素
my_dict["张信哲"] = 66
print(f"字典经过新增元素后,结果:{my_dict}")
# 结果
字典经过新增元素后,结果:{'王力宏': 99, '周杰伦': 88, '林俊杰': 77, '张信哲': 66}
更新元素
语法:字典[Key] = Value,结果:字典被修改,元素被更新
tips:字典Key不可以重复,所以对已存在的Key执行上述操作,就是更新Value值
# 更新元素
my_dict["周杰伦"] = 33
print(f"字典经过更新元素后,结果:{my_dict}")
# 结果
字典经过更新元素后,结果:{'王力宏': 99, '周杰伦': 33, '林俊杰': 77, '张信哲': 66}
删除元素
语法:字典.pop(Key),结果:获得指定Key的Value,同时字典被修改,指定Key的数据被删除
# 删除元素
score = my_dict.pop("周杰伦")
print(f"字典经过删除元素后,结果:{my_dict},周杰伦的考试分数为:{score}")
# 结果
字典经过删除元素后,结果:{'王力宏': 99, '林俊杰': 77, '张信哲': 66},周杰伦的考试分数为:33
清空字典
语法:字典.clear(),结果:字典被修改,元素被清空
# 清空元素
my_dict.clear()
print(f"字典被清空了,内容是:{my_dict}")
# 结果
字典被清空了,内容是:{}
获取全部的key
语法:字典.keys(),结果:得到字典中的全部Key
# 获取全部的 key
my_dict = {"王力宏" : 99, "周杰伦" : 88, "林俊杰" : 77}
keys = my_dict.keys()
print(f"字典的全部keys是:{keys}")
# 结果
字典的全部keys是:dict_keys(['王力宏', '周杰伦', '林俊杰'])
遍历字典
语法:for key in 字典.keys()
tips:字典不支持下标索引,所以同样不可以用 while 循环遍历
# 遍历字典
# 方式1:通过获取到全部的 key 来完成遍历
for key in keys:
print(f"字典的key是:{key}")
print(f"字典的value是:{my_dict[key]}")
# 方式2:直接对字典进行 for 循环,每一次循环都是直接得到 key
for key in my_dict:
print(f"字典的key是:{key}")
print(f"字典的value是:{my_dict[key]}")
# 结果
字典的key是:王力宏
字典的value是:99
字典的key是:周杰伦
字典的value是:88
字典的key是:林俊杰
字典的value是:77
字典的key是:王力宏
字典的value是:99
字典的key是:周杰伦
字典的value是:88
字典的key是:林俊杰
字典的value是:77
计算字典内的全部元素(键值对)数量
语法:len(字典)
结果:得到一个整数,表示字典内元素(键值对)的数量
# 统计字典内的元素的数量
num = len(my_dict)
print(f"字典中的元素数量有:{num}个")
# 结果
字典中的元素数量有:3个
字典的常用操作总结
| 编号 | 操作 | 说明 |
|---|---|---|
| 1 | 字典[Key] | 获取指定Key对应的Value值 |
| 2 | 字典[Key] = Value | 添加或更新键值对 |
| 3 | 字典.pop(Key) | 取出Key对应的Value并在字典内删除此Key的键值对 |
| 4 | 字典.clear() | 清空字典 |
| 5 | 字典.keys() | 获取字典的全部Key,可用于for循环遍历字典 |
| 6 | len(字典) | 计算字典内的元素数量 |
字典的特点
- 可以容纳多个数据
- 可以容纳不同类型的数据
- 每一份数据是 KeyValue 键值对
- 可以通过 Key 获取到 Value,Key不可重复(重复会覆盖)
- 不支持下标索引
- 可以修改(增加或删除更新元素等)
- 支持for循环,不支持while循环