分层Teams
- 分层Agent
- 创建tool
- 研究团队工具
- 文档编写团队工具
- 通用能力
- 定义Agent团队
- 研究团队
- 文档编写团队
- 添加图层
分层Agent
在前面的示例(Agent管理)中,我们引入了单个管理节点的概念,用于在不同工作节点之间路由工作。
但是,如果单个worker的工作变得过于复杂怎么办?如果worker数量过多怎么办?
对于某些应用程序,如果工作按层次分布,系统可能会更有效。
您可以通过组合不同的子图并创建顶级管理和中级管理来实现此目的。
为此,让我们构建一个简单的研究助手!该图表将如下所示:
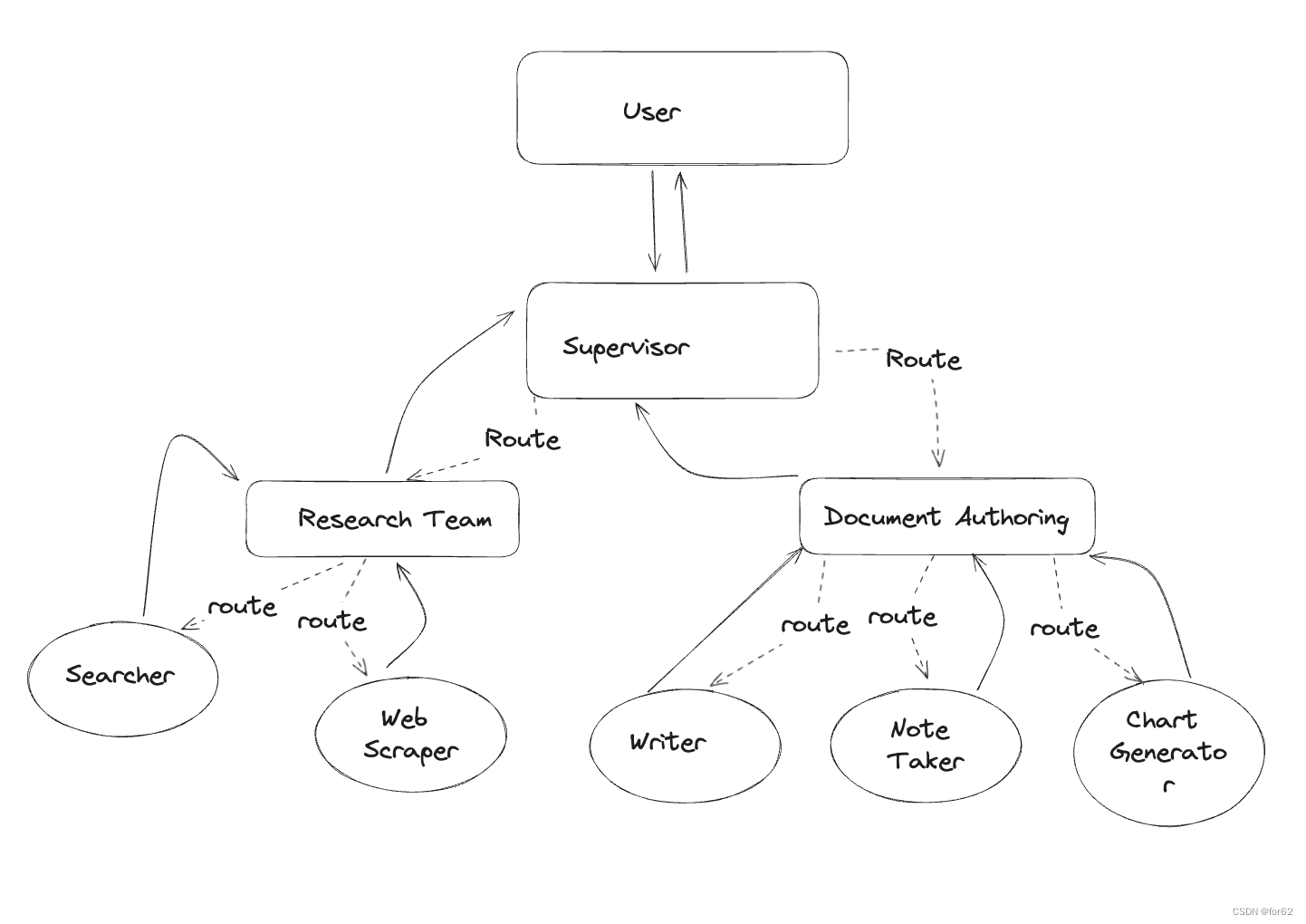
本笔记的灵感来自于 Wu 等人的论文《AutoGen:通过多代理对话启用下一代 LLM 应用程序》。等人。在本笔记的其余部分中,您将:
- 定义Agent访问网络和写入文件的工具
- 定义一些实用程序来帮助创建图形和代理
- 创建并定义每个团队(网络研究+文档写作)
- 将所有内容组合在一起。
创建tool
每个团队将由一名或多名Agent组成,每个Agent拥有一种或多种工具。下面定义了不同团队要使用的所有工具。
研究团队工具
研究团队可以使用搜索引擎和 URL 抓取工具在网络上查找信息。请随意添加以下附加功能以提高团队性能!
from typing import Annotated, List
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain_core.tools import tool
tavily_tool = TavilySearchResults(max_results=5)
@tool
def scrape_webpages(urls: List[str]) -> str:
"""Use requests and bs4 to scrape the provided web pages for detailed information."""
loader = WebBaseLoader(urls)
docs = loader.load()
return "\n\n".join(
[
f'\n{doc.page_content}\n'
for doc in docs
]
)
文档编写团队工具
接下来,我们将提供一些工具供文档编写团队使用。我们在下面定义了一些基本的文件访问工具。
请注意,这使Agent可以访问您的文件系统,这可能是不安全的。我们还没有针对性能优化工具描述。
from pathlib import Path
from tempfile import TemporaryDirectory
from typing import Dict, Optional, Annotated, List
from langchain_core.tools import tool
from langchain_experimental.utilities import PythonREPL
from typing_extensions import TypedDict
_TEMP_DIRECTORY = TemporaryDirectory()
WORKING_DIRECTORY = Path(_TEMP_DIRECTORY.name)
@tool
def create_outline(
points: Annotated[List[str], "List of main points or sections."],
file_name: Annotated[str, "File path to save the outline."],
) -> Annotated[str, "Path of the saved outline file."]:
"""Create and save an outline."""
with (WORKING_DIRECTORY / file_name).open("w") as file:
for i, point in enumerate(points):
file.write(f"{i + 1}. {point}\n")
return f"大纲保存到 {file_name}"
@tool
def read_document(
file_name: Annotated[str, "File path to save the document."],
start: Annotated[Optional[int], "The start line. Default is 0"] = None,
end: Annotated[Optional[int], "The end line. Default is None"] = None,
) -> str:
"""Read the specified document."""
with (WORKING_DIRECTORY / file_name).open("r") as file:
lines = file.readlines()
if start is not None:
start = 0
return "\n".join(lines[start:end])
@tool
def write_document(
content: Annotated[str, "Text content to be written into the document."],
file_name: Annotated[str, "File path to save the document."],
) -> Annotated[str, "Path of the saved document file."]:
"""Create and save a text document."""
with (WORKING_DIRECTORY / file_name).open("w") as file:
file.write(content)
return f"文档保存到 {file_name}"
@tool
def edit_document(
file_name: Annotated[str, "Path of the document to be edited."],
inserts: Annotated[
Dict[int, str],
"Dictionary where key is the line number (1-indexed) and value is the text to be inserted at that line.",
],
) -> Annotated[str, "Path of the edited document file."]:
"""Edit a document by inserting text at specific line numbers."""
with (WORKING_DIRECTORY / file_name).open("r") as file:
lines = file.readlines()
sorted_inserts = sorted(inserts.items())
for line_number, text in sorted_inserts:
if 1 <= line_number <= len(lines) + 1:
lines.insert(line_number - 1, text + "\n")
else:
return f"错误: 行号{Line_number}超出范围。"
with (WORKING_DIRECTORY / file_name).open("w") as file:
file.writelines(lines)
return f"文档编辑并保存到 {file_name}"
# Warning: This executes code locally, which can be unsafe when not sandboxed
repl = PythonREPL()
@tool
def python_repl(
code: Annotated[str, "The python code to execute to generate your chart."],
):
"""Use this to execute python code. If you want to see the output of a value,
you should print it out with `print(...)`. This is visible to the user."""
try:
result = repl.run(code)
except BaseException as e:
return f"执行失败,错误: {repr(e)}"
return f"执行成功:\n```python\n{code}\n```\nStdout: {result}"
通用能力
当我们想要执行以下操作时,我们将创建一些实用函数以使其更加简洁:
- 创建一个worker agent
- 为子图创建一个管理者
这些将为我们简化最后的图形组合代码,以便更容易看到发生了什么。
from typing import List, Optional
from langchain.agents import AgentExecutor, create_openai_functions_agent
from langchain.output_parsers.openai_functions import JsonOutputFunctionsParser
from langchain_core.messages import HumanMessage
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_openai import ChatOpenAI
from langgraph.graph import END, StateGraph
def create_agent(
llm: ChatOpenAI,
tools: list,
system_prompt: str,
) -> str:
"""创建一个函数调用代理并将其添加到图中。"""
system_prompt += "\n根据自己的专业,使用可用的工具自主工作。"
"不要询问说明。"
"您的其他团队成员(以及其他团队)将根据自己的专长与你合作。"
"你被选中是有原因的!你是以下团队成员之一: {team_members}。"
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
system_prompt,
),
MessagesPlaceholder(variable_name="messages"),
MessagesPlaceholder(variable_name="agent_scratchpad"),
]
)
agent = create_openai_functions_agent(llm, tools, prompt)
executor = AgentExecutor(agent=agent, tools=tools)
return executor
def agent_node(state, agent, name):
result = agent.invoke(state)
return {"messages": [HumanMessage(content=result["output"], name=name)]}
# 创建团队管理
def create_team_supervisor(llm: ChatOpenAI, system_prompt, members) -> str:
"""An LLM-based router."""
options = ["FINISH"] + members
function_def = {
"name": "route",
"description": "选择下一个角色。",
"parameters": {
"title": "routeSchema",
"type": "object",
"properties": {
"next": {
"title": "Next",
"anyOf": [
{"enum": options},
],
},
},
"required": ["next"],
},
}
prompt = ChatPromptTemplate.from_messages(
[
("system", system_prompt),
MessagesPlaceholder(variable_name="messages"),
(
"system",
"鉴于上述对话,下一步谁应该采取行动?"
"还是应该结束?选择其中一个:: {options}",
),
]
).partial(options=str(options), team_members=", ".join(members))
return (
prompt
| llm.bind_functions(functions=[function_def], function_call="route")
| JsonOutputFunctionsParser()
)
定义Agent团队
现在我们可以开始定义我们的分层团队了。 “选择你的玩家!”
研究团队
研究团队将有一个搜索代理和一个网络抓取“research_agent”作为两个工作节点。让我们创建这些以及团队主管。
import functools
import operator
from typing import TypedDict, Annotated, List
from langchain_core.messages import BaseMessage
from langchain_openai.chat_models import ChatOpenAI
from common.common import API_KEY, PROXY_URL
from researchteam_tool1 import scrape_webpages, tavily_tool
from utilities3 import create_team_supervisor, create_agent, agent_node
# ResearchTeam graph state
class ResearchTeamState(TypedDict):
# A message is added after each team member finishes
messages: Annotated[List[BaseMessage], operator.add]
# The team members are tracked so they are aware of
# the others' skill-sets
team_members: List[str]
# Used to route work. The supervisor calls a function
# that will update this every time it makes a decision
next: str
llm = ChatOpenAI(model_name="gpt-4o", api_key=API_KEY, base_url=PROXY_URL)
search_agent = create_agent(
llm,
[tavily_tool],
"你是一名研究助理,可以使用tavily搜索引擎搜索最新信息。",
)
search_node = functools.partial(agent_node, agent=search_agent, name="Search")
research_agent = create_agent(
llm,
[scrape_webpages],
"你是一名研究助理,可以使用scrape_webpages功能抓取指定的URL以获取更详细的信息。",
)
research_node = functools.partial(agent_node, agent=research_agent, name="WebScraper")
supervisor_agent = create_team_supervisor(
llm,
"您是一名主管,负责管理以下worker之间的对话:Search、WebScraper。"
"给定以下用户请求,请与该工作人员一起响应以执行下一步操作。"
"每个工作人员将执行一项任务,并以其结果和状态进行响应。"
"完成后,以FINISH进行响应。",
["Search", "WebScraper"],
)
现在我们已经创建了必要的组件,定义它们的交互就很容易了。将节点添加到团队图中,并定义边,这确定了转换标准。
import functools
import operator
from typing import TypedDict, Annotated, List
from langchain_core.messages import BaseMessage, HumanMessage
from langchain_openai.chat_models import ChatOpenAI
from langgraph.constants import END
from langgraph.graph import StateGraph
from common.common import API_KEY, PROXY_URL, show_img
from researchteam_tool1 import scrape_webpages, tavily_tool
from utilities3 import create_team_supervisor, create_agent, agent_node
# ResearchTeam graph state
class ResearchTeamState(TypedDict):
# A message is added after each team member finishes
messages: Annotated[List[BaseMessage], operator.add]
# The team members are tracked so they are aware of
# the others' skill-sets
team_members: List[str]
# Used to route work. The supervisor calls a function
# that will update this every time it makes a decision
next: str
llm = ChatOpenAI(model_name="gpt-4o", api_key=API_KEY, base_url=PROXY_URL)
search_agent = create_agent(
llm,
[tavily_tool],
"你是一名研究助理,可以使用tavily搜索引擎搜索最新信息。",
)
search_node = functools.partial(agent_node, agent=search_agent, name="Search")
research_agent = create_agent(
llm,
[scrape_webpages],
"你是一名研究助理,可以使用scrape_webpages功能抓取指定的URL以获取更详细的信息。",
)
research_node = functools.partial(agent_node, agent=research_agent, name="WebScraper")
supervisor_agent = create_team_supervisor(
llm,
"您是一名主管,负责管理以下worker之间的对话:Search、WebScraper。"
"给定以下用户请求,请与该工作人员一起响应以执行下一步操作。"
"每个工作人员将执行一项任务,并以其结果和状态进行响应。"
"完成后,以FINISH进行响应。",
["Search", "WebScraper"],
)
research_graph = StateGraph(ResearchTeamState)
research_graph.add_node("Search", search_node)
research_graph.add_node("WebScraper", research_node)
research_graph.add_node("supervisor", supervisor_agent)
# Define the control flow
research_graph.add_edge("Search", "supervisor")
research_graph.add_edge("WebScraper", "supervisor")
research_graph.add_conditional_edges(
"supervisor",
lambda x: x["next"],
{"Search": "Search", "WebScraper": "WebScraper", "FINISH": END},
)
research_graph.set_entry_point("supervisor")
chain = research_graph.compile()
# The following functions interoperate between the top level graph state
# and the state of the research sub-graph
# this makes it so that the states of each graph don't get intermixed
def enter_chain(message: str):
results = {
"messages": [HumanMessage(content=message)],
}
return results
research_chain = enter_chain | chain
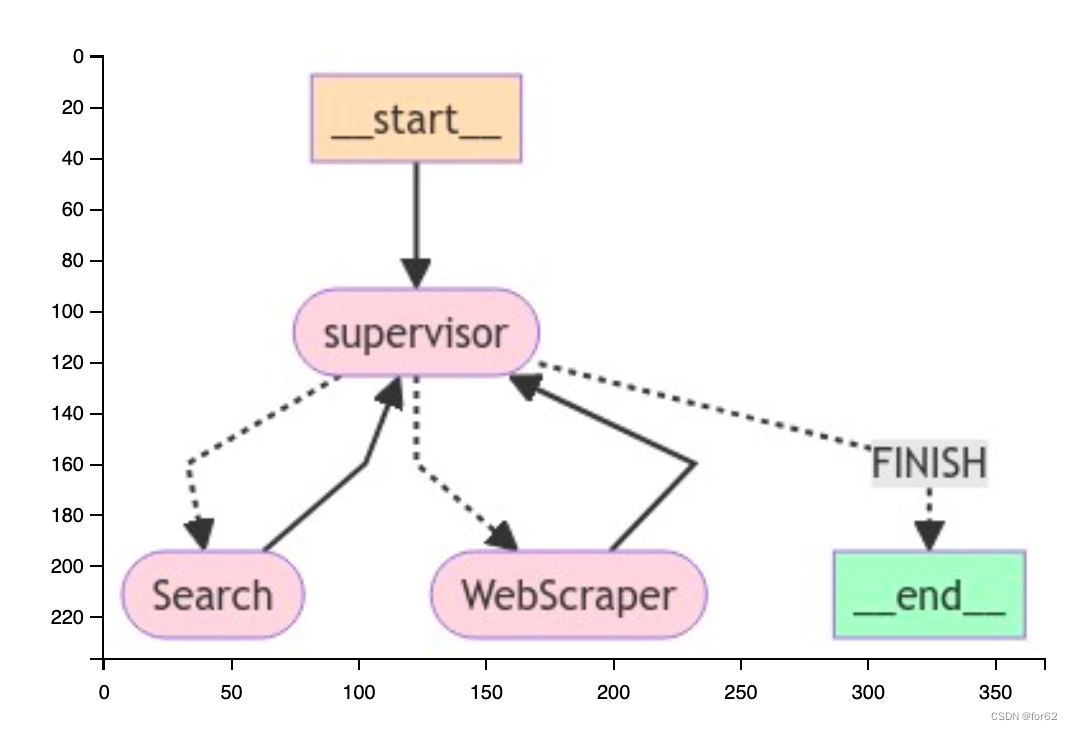
文档编写团队
使用类似的方法创建下面的文档编写团队。这次,我们将为每个代理提供不同的文件写入工具的访问权限。
请注意,我们在这里向Agent授予文件系统访问权限,这在任何情况下并不安全。
import functools
import operator
from pathlib import Path
from typing import TypedDict, Annotated, List
from langchain_core.messages import BaseMessage, HumanMessage
from langchain_openai import ChatOpenAI
from langgraph.constants import END
from langgraph.graph import StateGraph
from common.common import API_KEY, PROXY_URL, show_img
from doc_writing_team_tool2 import WORKING_DIRECTORY, write_document, edit_document, read_document, create_outline, \
python_repl
from utilities3 import create_agent, agent_node, create_team_supervisor
# Document writing team graph state
class DocWritingState(TypedDict):
# This tracks the team's conversation internally
messages: Annotated[List[BaseMessage], operator.add]
# This provides each worker with context on the others' skill sets
team_members: str
# This is how the supervisor tells langgraph who to work next
next: str
# This tracks the shared directory state
current_files: str
# This will be run before each worker agent begins work
# It makes it so they are more aware of the current state
# of the working directory.
def prelude(state):
written_files = []
if not WORKING_DIRECTORY.exists():
WORKING_DIRECTORY.mkdir()
try:
written_files = [
f.relative_to(WORKING_DIRECTORY) for f in WORKING_DIRECTORY.rglob("*")
]
except Exception:
pass
if not written_files:
return {**state, "current_files": "没有文件被写"}
return {
**state,
"current_files": "\n以下是您的团队已写入目录的文件:\n"
+ "\n".join([f" - {f}" for f in written_files]),
}
llm = ChatOpenAI(model_name="gpt-4o", api_key=API_KEY, base_url=PROXY_URL)
doc_writer_agent = create_agent(
llm,
[write_document, edit_document, read_document],
"你是一个写文档研究的专家。\n"
# The {current_files} value is populated automatically by the graph state
"以下是当前在您目录中的文件:\n{current_files}",
)
# Injects current directory working state before each call
context_aware_doc_writer_agent = prelude | doc_writer_agent
doc_writing_node = functools.partial(
agent_node, agent=context_aware_doc_writer_agent, name="DocWriter"
)
note_taking_agent = create_agent(
llm,
[create_outline, read_document],
"你是一名专业的高级研究员,负责撰写论文提纲并做笔记,以撰写一篇完美的论文。{current_files}",
)
context_aware_note_taking_agent = prelude | note_taking_agent
note_taking_node = functools.partial(
agent_node, agent=context_aware_note_taking_agent, name="NoteTaker"
)
chart_generating_agent = create_agent(
llm,
[read_document, python_repl],
"你是一名数据专家,负责为研究项目生成图表。"
"{current_files}",
)
context_aware_chart_generating_agent = prelude | chart_generating_agent
chart_generating_node = functools.partial(
agent_node, agent=context_aware_note_taking_agent, name="ChartGenerator"
)
doc_writing_supervisor = create_team_supervisor(
llm,
"你是一名主管,负责管理以下worker之间的对话: {team_members}。"
"给定以下用户请求,请与工作人员一起响应以执行下一步操作。"
"每个工作人员将执行一项任务,并以其结果和状态作出响应。"
"完成后,回复FINISH。",
["DocWriter", "NoteTaker", "ChartGenerator"],
)
# Create the graph here:
# Note that we have unrolled the loop for the sake of this doc
authoring_graph = StateGraph(DocWritingState)
authoring_graph.add_node("DocWriter", doc_writing_node)
authoring_graph.add_node("NoteTaker", note_taking_node)
authoring_graph.add_node("ChartGenerator", chart_generating_node)
authoring_graph.add_node("supervisor", doc_writing_supervisor)
# Add the edges that always occur
authoring_graph.add_edge("DocWriter", "supervisor")
authoring_graph.add_edge("NoteTaker", "supervisor")
authoring_graph.add_edge("ChartGenerator", "supervisor")
# Add the edges where routing applies
authoring_graph.add_conditional_edges(
"supervisor",
lambda x: x["next"],
{
"DocWriter": "DocWriter",
"NoteTaker": "NoteTaker",
"ChartGenerator": "ChartGenerator",
"FINISH": END,
},
)
authoring_graph.set_entry_point("supervisor")
chain = authoring_graph.compile()
# The following functions interoperate between the top level graph state
# and the state of the research sub-graph
# this makes it so that the states of each graph don't get intermixed
def enter_chain(message: str, members: List[str]):
results = {
"messages": [HumanMessage(content=message)],
"team_members": ", ".join(members),
}
return results
# We reuse the enter/exit functions to wrap the graph
authoring_chain = (
functools.partial(enter_chain, members=authoring_graph.nodes)
| authoring_graph.compile()
)
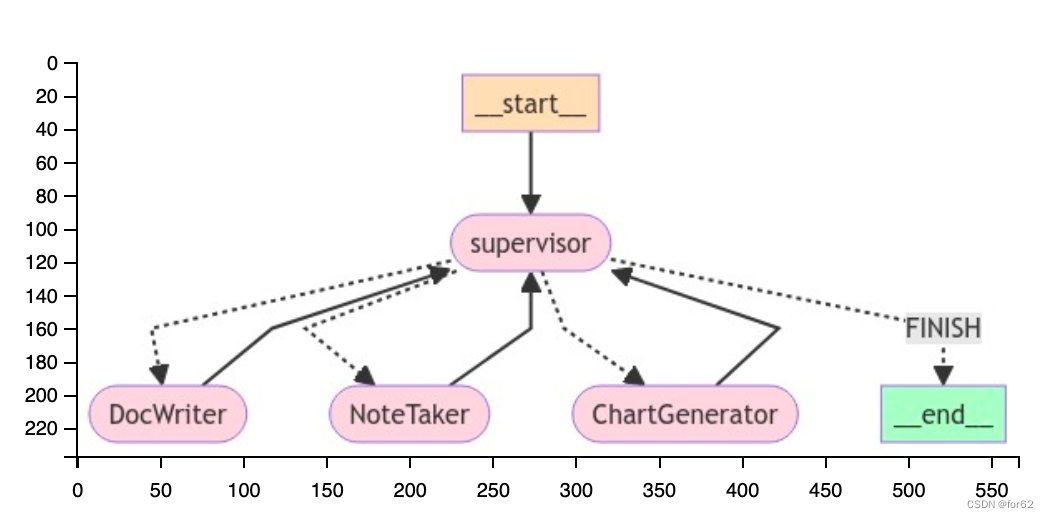
添加图层
在这个设计中,我们正在执行自上而下的规划政策。我们已经创建了两个图表,但我们必须决定如何在两个图表之间分配工作。
我们将创建第三个图来编排前两个图,并添加一些连接器来定义如何在不同图之间共享此顶级状态。
import operator
from typing import TypedDict, Annotated, List
from langchain_core.messages import BaseMessage
from langchain_openai.chat_models import ChatOpenAI
from langgraph.constants import END
from langgraph.graph import StateGraph
from common.common import API_KEY, PROXY_URL, show_img
from research_team_agent4 import research_chain
from doc_writing_team_agent5 import authoring_chain
llm = ChatOpenAI(model_name="gpt-4o", api_key=API_KEY, base_url=PROXY_URL)
from utilities3 import create_team_supervisor
supervisor_node = create_team_supervisor(
llm,
"你是一名主管,负责管理以下团队之间的对话: {team_members}。"
"给定以下用户请求,与工作人员一起响应以执行下一步操作。"
"每个工作人员都将执行一项任务,并以其结果和状态作出响应。"
"完成后,回复FINISH。",
["ResearchTeam", "PaperWritingTeam"],
)
# Top-level graph state
class State(TypedDict):
messages: Annotated[List[BaseMessage], operator.add]
next: str
def get_last_message(state: State) -> str:
return state["messages"][-1].content
def join_graph(response: dict):
return {"messages": [response["messages"][-1]]}
# Define the graph.
super_graph = StateGraph(State)
# First add the nodes, which will do the work
super_graph.add_node("ResearchTeam", get_last_message | research_chain | join_graph)
super_graph.add_node(
"PaperWritingTeam", get_last_message | authoring_chain | join_graph
)
super_graph.add_node("supervisor", supervisor_node)
# Define the graph connections, which controls how the logic
# propagates through the program
super_graph.add_edge("ResearchTeam", "supervisor")
super_graph.add_edge("PaperWritingTeam", "supervisor")
super_graph.add_conditional_edges(
"supervisor",
lambda x: x["next"],
{
"PaperWritingTeam": "PaperWritingTeam",
"ResearchTeam": "ResearchTeam",
"FINISH": END,
},
)
super_graph.set_entry_point("supervisor")
super_graph = super_graph.compile()



![vivado在implementation时出现错误[Place 30-494] The design is empty的一个可能原因和解决方法](https://img-blog.csdnimg.cn/direct/eb9b9db5f43d4aadaa91333535501409.png)


![【2024最新华为OD-C/D卷试题汇总】[支持在线评测] K小姐和A先生的聚餐计划(200分) - 三语言AC题解(Python/Java/Cpp)](https://img-blog.csdnimg.cn/direct/40c8e976ca794190b81c45d81d26dfb9.png)
![[自动驾驶 SoC]-4 特斯拉FSD](https://img-blog.csdnimg.cn/direct/8fb72c8a1c3844d3bde9eea558cc5815.png)





![[环境配置]vscode通过ssh连接autodl进行项目开发](https://img-blog.csdnimg.cn/img_convert/c5e1dbc898e3463aac03e89c1f82a5f1.png)