一、在K8s中扩缩容分为两种:
●Node层面:对K8s物理节点扩容和缩容,根据业务规模实现物理节点自动扩缩容
●Pod层面:我们一般会使用Deployment中的Replicas参数,设置多个副本集来保证服务的高可用,但是这是一个固定的值,比如我们设置10个副本,就会启10个pod同时Running来提供服务。如果这个服务平时流量很少的时候,也是10个Pod同时在Running,而流量突然暴增时,又可能出现10个Pod不够用的情况,针对这种情况就要使用扩容和缩容
自动扩容和缩容:VPA、KPA、HPA
KPA(Knative Pod Autoscaler)
基于请求数对Pod自动扩缩容,KPA的主要限制在于它不支持基于CPU的自动扩缩容
●根据并发请求数实现自动扩缩容
●设置扩缩容边界实现自动扩缩容
扩缩容边界是指应用程序提供服务的最小和最大Pod数量。通过设置应用程序服务的最小和最大Pod数量实现自动扩缩容。
VPA
Kubernetes VPA(Vertical Pod Autoscaler)垂直Pod自动扩缩容,VPA会基于Pod的资源使用情况自动为集群设置资源占用的限制,从而让集群将Pod调度到足够资源的最佳节点上。VPA也会保持最初容器定义中资源Request和Limit的占比。
它会根据容器资源使用率自动设置Pod的CPU和内存的Request,从而允许在节点上进行适当的调度,以便为每个Pod提供适当的可用的节点。它既可以缩小过度请求资源的容器,也可以根据其使用情况随时提升资源不足的容量。
HPA
HPA(Horizontal Pod Autoscaling)Pod 水平自动伸缩,Kubernetes 有一个 HPA 的资源,HPA 可以根据 CPU 利用率自动伸缩一个 Replication Controller、Deployment 或者Replica Set 中的 Pod 数量。
(1)HPA 基于 Master 上的 kube-controller-manager 服务启动参数 horizontal-pod-autoscaler-sync-period 定义的时长(默认为30秒),周期性的检测 Pod 的 CPU 使用率。
(2)HPA 与之前的 RC、Deployment 一样,也属于一种 Kubernetes 资源对象。通过追踪分析 RC 控制的所有目标 Pod 的负载变化情况,来确定是否需要针对性地调整目标Pod的副本数,这是HPA的实现原理。
(3)metrics-server 也需要部署到集群中, 它可以通过 resource metrics API 对外提供度量数据。
HPA 是kubernetes 中实现自动扩缩容Pod 副本数量的机制
它允许集群中的工作负载根据实际的负载情况自动调整pod的数量,以此来优化资源的使用和提高服务的响应能力
核心概念
●水平扩展(Horizontal Scaling):增加Pod的数量来分摊负载,与垂直扩展(增加单个Pod的资源)相对。
●Pod副本(Pod Replicas):运行应用程序的容器实例,通常是在Deployment或ReplicaSet等控制器下管理的。
●指标(Metrics):用于触发HPA扩缩容的度量值,如CPU使用率、内存使用量、自定义的应用程序指标等
HPA 的配置关键参数
●ScaleTargetRef:指定 HPA 将要作用的资源对象,如 Deployment、Replica Set 或 RC 的名称。
●MinReplicas:最小副本数,即使在负载很低时也不会低于这个数量。
●MaxReplicas:最大副本数,即使在负载很高时也不会超过这个数量。
●Metrics:定义用于触发伸缩的度量标准和目标值。例如,可以设置 CPU 的利用率目标,当实际利用率超过这个目标值时,HPA 会增加副本数量;当利用率低于目标值时,HPA 会减少副本数量
二、部署 metrics-server
●metrics-server:是kubernetes集群资源使用情况的聚合器,收集数据给kubernetes集群内使用,如kubectl、hpa、scheduler等。
//在所有 Node 节点上传 metrics-server.tar 镜像包到 /opt 目录
cd /opt/
docker load -i metrics-server.tar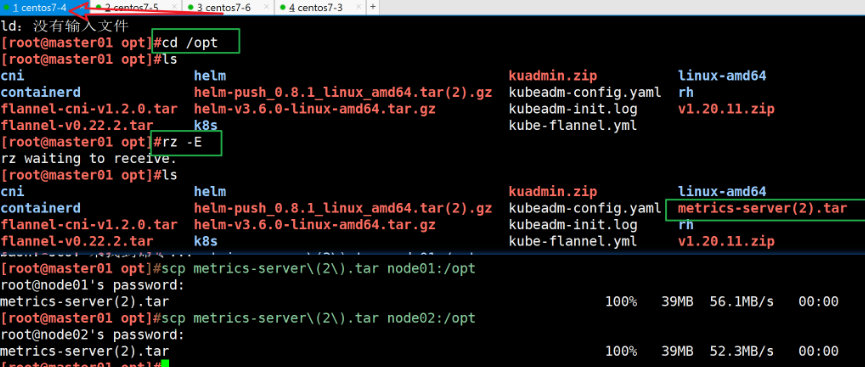

设置 Helm 仓库和下载 Metrics Server 的 Helm Chart
#创建一个目录 /opt/metrics 用于存放 metrics-server 的配置文件
mkdir /opt/metrics
cd /opt/metrics
#移除旧的 Helm 仓库(没有的话不用移)
helm repo remove stable#添加新的 Helm 仓库,可以选择使用官方源或镜像源,建议使用官方
helm repo add stable https://charts.helm.sh/stable
#或
helm repo add stable http://mirror.azure.cn/kubernetes/charts#更新Helm 仓库
helm repo update
#从 Helm 仓库拉取 metrics-server chart
helm pull stable/metrics-server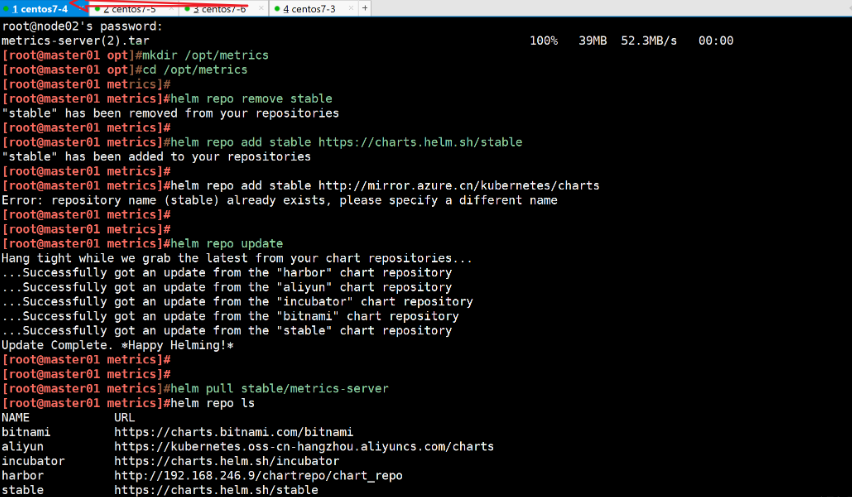
配置Metrics-Server
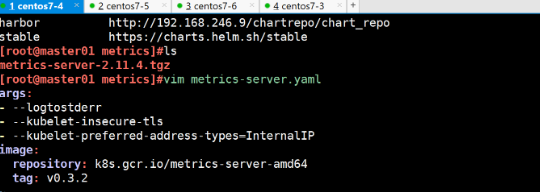
vim metrics-server.yaml
args:
- --logtostderr
- --kubelet-insecure-tls
- --kubelet-preferred-address-types=InternalIP
image:
repository: k8s.gcr.io/metrics-server-amd64
tag: v0.3.2-------------------------------------------------- # 在 Metrics Server 的容器启动参数中添加了以下选项: args: - --logtostderr # 将日志输出到标准错误输出(stderr),这对于容器环境中的日志收集很常见。 - --kubelet-insecure-tls # 允许 Metrics Server 以不安全的方式与 kubelet 通信,忽略 TLS 证书验证。这在测试或非生产环境中可能用到,但生产环境应避免。 - --kubelet-preferred-address-types=InternalIP # 指定 Metrics Server 优先使用节点的 InternalIP 地址来与 kubelet 通讯,这有助于在具有多个网络接口的节点上正确路由。 # 镜像信息设置: image: repository: k8s.gcr.io/metrics-server-amd64 # 使用了 Kubernetes 官方仓库中的 Metrics Server 镜像,适用于 amd64 架构。 tag: v0.3.2 # 指定了镜像的标签为 v0.3.2,代表使用的 Metrics Server 版本。 --------------------------------------------------
使用 helm install 安装 metrics-server
helm install metrics-server stable/metrics-server -n kube-system -f metrics-server.yaml
kubectl get pods -n kube-system | grep metrics-server
#需要多等一会儿
kubectl top node
kubectl top pods --all-namespaces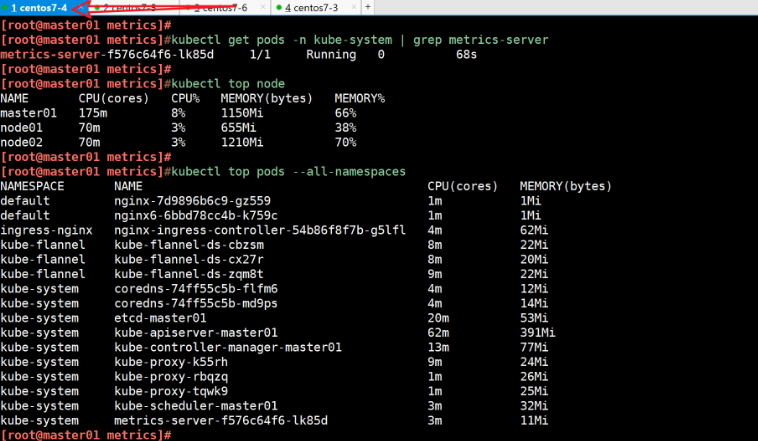
通过这些步骤,确保 metrics-server 成功部署在 Kubernetes 集群中,并且可以提供集群资源使用情况的聚合信息,这对于 Kubernetes 集群的运维和自动扩缩容策略的实施非常关键。
部署 HPA
//在所有节点上传 hpa-example.tar 镜像文件到 /opt 目录
hpa-example.tar 是谷歌基于 PHP 语言开发的用于测试 HPA 的镜像,其中包含了一些可以运行 CPU 密集计算任务的代码。
cd /opt
docker load -i hpa-example.tar
docker images | grep hpa-example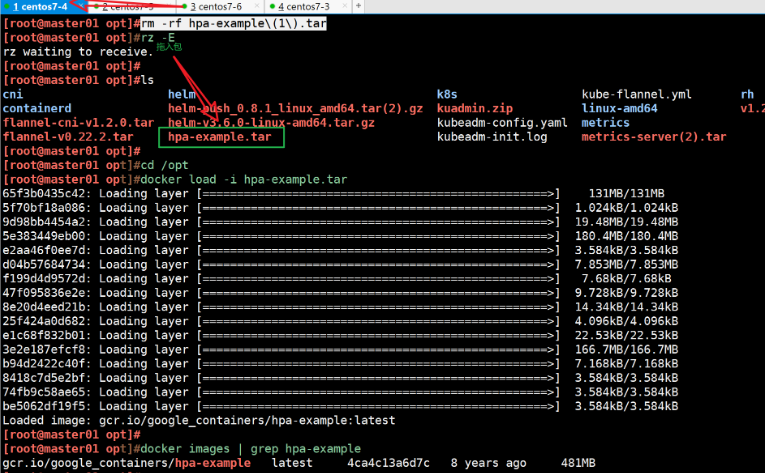

//创建用于测试的 Pod 资源,并设置请求资源为 cpu=200m
vim hpa-pod.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
run: php-apache
name: php-apache
spec:
replicas: 1
selector:
matchLabels:
run: php-apache
template:
metadata:
labels:
run: php-apache
spec:
containers:
- image: gcr.io/google_containers/hpa-example
name: php-apache
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
resources:
requests:
cpu: 200m
---
apiVersion: v1
kind: Service
metadata:
name: php-apache
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
run: php-apachekubectl apply -f hpa-pod.yaml
kubectl get pods
通过这些步骤,可以在 Kubernetes 集群中部署一个应用程序,并使用 HPA 根据实际负载自动调整 Pod 副本数,从而实现应用程序的自动扩缩容
三、配置和使用 HPA
创建 HPA 控制器
//使用 kubectl autoscale 命令创建 HPA 控制器,设置 cpu 负载阈值为请求资源的 50%,指定最少负载节点数量为 1 个,最大负载节点数量为 10 个
kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=10监控 HPA 状态
//需要等一会儿,才能获取到指标信息 TARGETS
kubectl get hpa
kubectl top pods查看 HPA 的状态,包括当前的 CPU 负载百分比、最小和最大 Pod 数量以及当前的 Pod 副本数

压力测试

创建一个测试客户端容器
kubectl run -it load-generator --image=busybox /bin/sh增加负载
# while true; do wget -q -O- http://php-apache.default.svc.cluster.local; done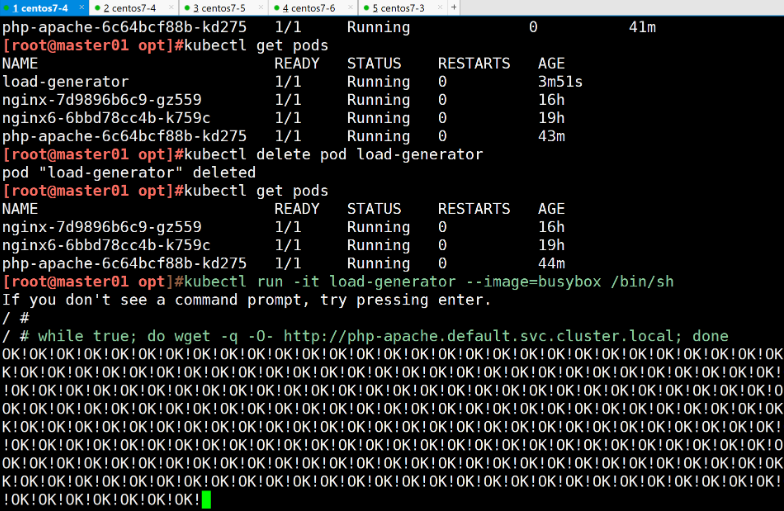
打开一个新的窗口,查看负载节点数目
kubectl get hpa -w#以上可以看到经过压测,负载节点数量最大上升到 10 个,并且 cpu 负载也随之下降。
#观察 HPA 控制器的响应,可以看到随着 CPU 负载的增加,Pod 的副本数从 1 个增加到最大限制的 10 个
如果 cpu 性能较好导致负载节点上升不到 10 个,可再创建一个测试客户端同时测试:

//如果 cpu 性能较好导致负载节点上升不到 10 个,可再创建一个测试客户端同时测试:
kubectl run -i --tty load-generator1 --image=busybox /bin/sh
# while true; do wget -q -O- http://php-apache.default.svc.cluster.local; done//查看 Pod 状态,也发现已经创建了 10 个 Pod 资源
kubectl get pods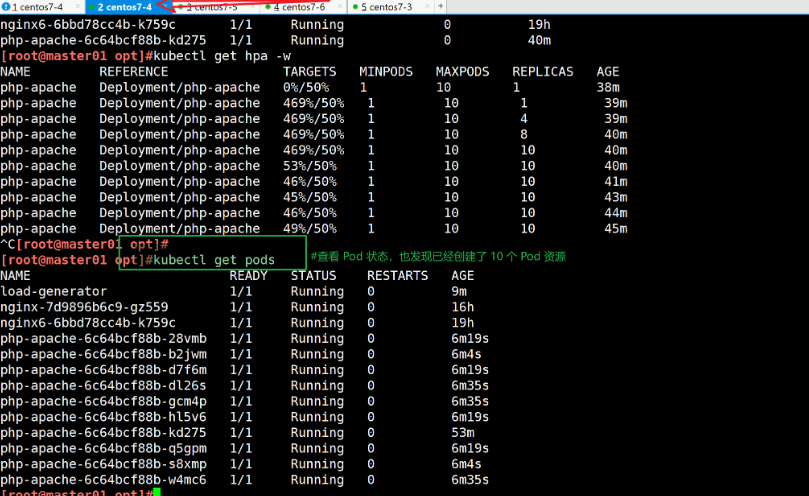
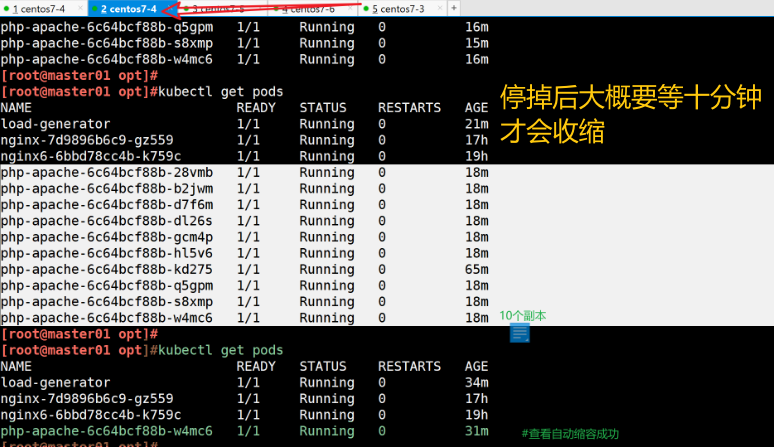
#HPA 扩容的时候,负载节点数量上升速度会比较快;但回收的时候,负载节点数量下降速度会比较慢。
原因是防止在业务高峰期时因为网络波动等原因的场景下,如果回收策略比较积极的话,K8S集群可能会认为访问流量变小而快速收缩负载节点数量,而仅剩的负载节点又承受不了高负载的压力导致崩溃,从而影响业务。

四、资源限制 - Pod
Kubernetes对资源的限制实际上是通过cgroup来控制的,cgroup是容器的一组用来控制内核如何运行进程的相关属性集合。针对内存、CPU 和各种设备都有对应的 cgroup。
默认情况下,Pod 运行没有 CPU 和内存的限额。这意味着系统中的任何 Pod 将能够像执行该 Pod 所在的节点一样, 消耗足够多的 CPU 和内存。
一般会针对某些应用的 pod 资源进行资源限制,这个资源限制是通过 resources 的 requests 和 limits 来实现。requests 为创建 Pod 时初始要分配的资源,limits 为 Pod 最高请求的资源值。
cgroup 的作用
●控制组: cgroup(Control Groups)是 Linux 内核的一个特性,它允许对系统资源进行分组管理和限制。
●资源隔离: cgroup 通过为每个组设置资源配额和限制,实现了对 CPU、内存、I/O 等资源的隔离和控制。
Pod 资源限制
●requests: 指定 Pod 运行所需的最小资源量。Kubernetes 调度器会考虑这些请求来决定在哪个节点上调度 Pod。如果节点无法满足 Pod 的资源请求,Pod 将不会被调度到该节点。
●limits: 指定 Pod 可以使用的最大资源量。如果 Pod 尝试使用超过其限制的资源,系统将通过 cgroup 强制限制资源使用,可能会导致 Pod 被杀死或重启
示例:
spec:
containers:
- image: xxxx
imagePullPolicy: IfNotPresent
name: auth
ports:
- containerPort: 8080
protocol: TCP
resources:
limits:
cpu: "2" # 限制 CPU 使用量为 2 个单位(可以是核心数或毫核)
memory: 1Gi # 限制内存使用量为 1Gi(Gibibytes)
requests:
cpu: 250m # 请求 CPU 使用量为 250 毫核
memory: 250Mi # 请求内存使用量为 250Mi(Mebibytes)在这个配置中,auth 容器请求了 250 毫核的 CPU 和 250Mi 的内存,同时设置了 2 个单位的 CPU 和 1Gi 内存的限制。这意味着 Kubernetes 会确保 auth 容器至少有 250 毫核的 CPU 和 250Mi 的内存可用,但如果资源充足,它可以使用更多,但不会超过 2 个单位的 CPU 和 1Gi 的内存
资源限制 - 命名空间
1.计算资源配额
在 Kubernetes 中使用 ResourceQuota 和 LimitRange 资源类型来对命名空间级别的资源使用进行限制和管理
apiVersion: v1
kind: ResourceQuota #使用 ResourceQuota 资源类型
metadata:
name: compute-resources
namespace: spark-cluster #指定命令空间
spec:
hard:
pods: "20" #设置 Pod 数量最大值
requests.cpu: "2"
requests.memory: 1Gi
limits.cpu: "4"
limits.memory: 2Gi2.配置对象数量配额限制
apiVersion: v1
kind: ResourceQuota
metadata:
name: object-counts
namespace: spark-cluster
spec:
hard:
configmaps: "10"
persistentvolumeclaims: "4" #设置 pvc 数量最大值
replicationcontrollers: "20" #设置 rc 数量最大值
secrets: "10"
services: "10"
services.loadbalancers: "2"ResourceQuota 被命名为 object-counts,它限制了 spark-cluster 命名空间中的配置对象数量:
configmaps、persistentvolumeclaims、replicationcontrollers、secrets、services:这些项限制了各种类型配置对象的数量。
services.loadbalancers:特别限制了使用负载均衡器类型的服务数量
#如果Pod没有设置requests和limits,则会使用当前命名空间的最大资源;如果命名空间也没设置,则会使用集群的最大资源。
K8S 会根据 limits 限制 Pod 使用资源,当内存超过 limits 时 cgruops 会触发 OOM。
这里就需要创建 LimitRange 资源来设置 Pod 或其中的 Container 能够使用资源的最大默认值
apiVersion: v1
kind: LimitRange #使用 LimitRange 资源类型
metadata:
name: mem-limit-range
namespace: test #可以给指定的 namespace 增加一个资源限制
spec:
limits:
- default: #default 即 limit 的值
memory: 512Mi
cpu: 500m
defaultRequest: #defaultRequest 即 request 的值
memory: 256Mi
cpu: 100m
type: Container #类型支持 Container、Pod、PVC
LimitRange 示例中,mem-limit-range 为 test 命名空间中的所有容器设置了默认的内存和 CPU 限制:
default:设置了默认的资源限制值。
defaultRequest:设置了默认的资源请求值。
type:指定了这些限制适用于的类型,可以是 Container、Pod 或 PersistentVolumeClaim (PVC)通过这些资源限制,Kubernetes 管理员可以精细地控制集群资源的使用,避免资源浪费,并确保集群的稳定性和效率
总结
HPA
●HPA 是 控制器管理pod资源的副本数量 实现自动伸缩
●原理:追踪可控制器管理的pod负载情况,来根据设置的阈值来动态调整pod副本的数量
●metrics-server 收集k8s中的node、pod 等资源的使用情况,kubectl top node/pod
●kubectl autoscale 控制器 --cpuprecent=60 --min=最小值 --max=最大值
kubectl 资源限制
●resource.requests/limits 限制pod中容器的资源量
●resourceQuota 资源类型对命名空间的资源对象或者资源量 进行配额的限制
●limitRanger 资源类型设置命名空间中 pod(容器默认的)资源限制limit requests