文章目录
- 概述
- BPE
- 构建词表
- 词元化
- 代码实现
- WordPiece
- Unigram
- 估算概率(E)
- 删除词元(M)
- 参考资料
概述
接上回,子词词元化(Subwords tokenization)是平衡字符级别和词级别的一种方法,也是目前用得最多的方法。
子词词元化的目标有2个:
● 常见词不应该切分为更小的单元
● 罕见词应该被分解为有意义的子词
BPE
BPE(Byte-Pair Encoding)最早用于数据压缩[3],后面由论文[4]将其应用于切词。模型词表通过统计出现频次最高的词或子词而构成,可以达到子词词元化的2个目标。BPE分为两步:
● 构建词表:根据预料构建词表,可理解为训练。
● 词元化:对文本利用上述词表进行词元化,可理解为推理。
字节级(Byte-level)BPE 通过将字节视为合并的基本符号,用来改善多语言语料库(例如包含非ASCII字符的文本)的分词质量。GPT-2、BART 和 LLaMA 等大语言模型都采用了这种分词方法
构建词表
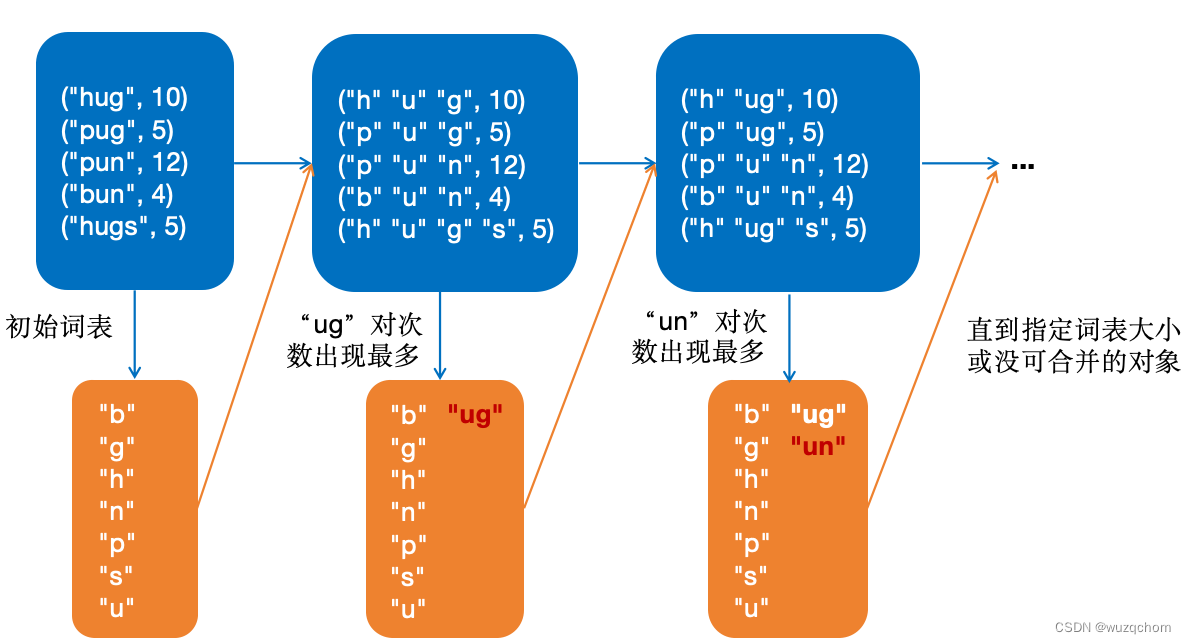
最初,BPE按照所有单词的字符表作为初始词表,将每个单词切分成字符序列,然后每次迭代选取出现次数最多的字符对加入词表,直到没有可合并的字符或者词表到预设的大小为止。
这里具体构建过程以Huggingface上的例子说明,假设单词和出现的频次如下:
("hug", 10), ("pug", 5), ("pun", 12), ("bun", 4), ("hugs", 5)
BPE构建词表过程如下图所示:
词元化
该过程可以理解为推理,应用上面的词表将新文本进行词元化。
代码实现
对Huggingface上的代码稍加整理、并增加了一些注释:
from collections import defaultdict
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("gpt2")
corpus = [
"This is the Hugging Face Course.",
"This chapter is about tokenization.",
"This section shows several tokenizer algorithms.",
"Hopefully, you will be able to understand how they are trained and generate tokens.",
]
def stat_word_freqs():
"""统计语料中的词频"""
word_freqs = defaultdict(int)
for text in corpus:
words_with_offsets = tokenizer.backend_tokenizer.pre_tokenizer.pre_tokenize_str(text)
new_words = [word for word, offset in words_with_offsets]
for word in new_words:
word_freqs[word] += 1
return word_freqs
def stat_alphabet(word_freqs):
"""获取所有的字符"""
alphabet = []
for word in word_freqs.keys():
for letter in word:
if letter not in alphabet:
alphabet.append(letter)
alphabet.sort()
return alphabet
def compute_pair_freqs(splits, word_freqs):
"""统计每一个对出现的频次"""
pair_freqs = defaultdict(int)
for word, freq in word_freqs.items():
split = splits[word]
if len(split) == 1:
continue
for i in range(len(split) - 1):
pair = (split[i], split[i + 1])
pair_freqs[pair] += freq
return pair_freqs
def pick_best_pais(pair_freqs):
best_pair = ""
max_freq = None
# 找到出现频次最多的对
for pair, freq in pair_freqs.items():
if max_freq is None or max_freq < freq:
best_pair = pair
max_freq = freq
return best_pair, max_freq
def merge_pair(a, b, splits, word_freqs):
for word in word_freqs:
split = splits[word]
if len(split) == 1:
continue
i = 0
while i < len(split) - 1:
if split[i] == a and split[i + 1] == b:
split = split[:i] + [a + b] + split[i + 2 :]
else:
i += 1
splits[word] = split
return splits
def make_vacab(vocab, merges, splits, word_freqs, vocab_size=20):
"""制作词表"""
while len(vocab) < vocab_size:
pair_freqs = compute_pair_freqs(splits, word_freqs)
best_pair, _ = pick_best_pais(pair_freqs)
splits = merge_pair(*best_pair, splits, word_freqs)
merges[best_pair] = best_pair[0] + best_pair[1]
vocab.append(best_pair[0] + best_pair[1])
def tokenize(text, merges):
"""对文本进行词元切分"""
pre_tokenize_result = tokenizer._tokenizer.pre_tokenizer.pre_tokenize_str(text)
pre_tokenized_text = [word for word, offset in pre_tokenize_result]
splits = [[l for l in word] for word in pre_tokenized_text]
for pair, merge in merges.items():
for idx, split in enumerate(splits):
i = 0
# 如果可以合并,则尽可能长
while i < len(split) - 1:
if split[i] == pair[0] and split[i + 1] == pair[1]:
split = split[:i] + [merge] + split[i + 2 :]
else:
i += 1
splits[idx] = split
return sum(splits, [])
def main():
# 1. 统计词频
word_freqs = stat_word_freqs()
print('word_freqs=', word_freqs)
# 2. 统计字符表
alphabet = stat_alphabet(word_freqs)
vocab = ["<|endoftext|>"] + alphabet.copy()
splits = {word: [c for c in word] for word in word_freqs.keys()}
print('splits=', splits)
print('alphabet=', alphabet)
merges = {}
# 3. 根据语料制作词表
make_vacab(vocab, merges, splits, word_freqs)
print('merges=', merges)
print('vocab=', vocab)
# 应用词元化
res = tokenize("This is not a token.", merges)
# 输出:['This', 'Ġis', 'Ġ', 'n', 'o', 't', 'Ġa', 'Ġtoken', '.']
print(res)
if __name__ == '__main__':
main()
WordPiece
BERT中使用的WordPiece方法进行词元化,其思想和BPE类似。主要有以下不同点:
- 使用
##代表非开始字符,如“word”按照字符切分为:w ##o ##r ##d - 在合并字符对的时候,BPE使用的是出现最多的对,而“WordPiece”选择依据如下所示:
s c o r e = # p a i r # f i r s t _ e l e m e n t × # s e c o n d _ e l e m e n t score=\frac{\#pair}{\#first\_element \times \#second\_element} score=#first_element×#second_element#pair
使用BPE中的例子,切分后的语料如下所示:
按照上述计算方式,应该合并“##g”和“##s”。("h" "##u" "##g", 10), ("p" "##u" "##g", 5), ("p" "##u" "##n", 12), ("b" "##u" "##n", 4), ("h" "##u" "##g" "##s", 5)- BPE选中的“ug”对得分为: s c o r e u g = 25 36 × 25 = 1 36 score_{ug}=\frac{25}{36 \times 25}=\frac{1}{36} scoreug=36×2525=361
- “gs”对得分为: s c o r e g s = 5 20 × 5 = 1 20 score_{gs}=\frac{5}{20 \times 5}=\frac{1}{20} scoregs=20×55=201
Unigram
T5、XLNet等模型使用Unigram词元化方法。Unigram的思想和前两种词元化方法截然不同,最刚开始尽可能找到所有的子词,然后不断地删除,直到达到设定的词表大小为止。
Unigram方法本质上是一个基于词袋的统计语言模型。
使用之前的例子:
("hug", 10), ("pug", 5), ("pun", 12), ("bun", 4), ("hugs", 5)
我们可以通过子串的方式得到最原始的词表:
["h", "u", "g", "hu", "ug", "p", "pu", "n", "un", "b", "bu", "s", "hug", "gs", "ugs"]
然后通过不断地迭代删除词元,直到达到设定的词表大小为止。采用期望最大化(EM)算法进行迭代。
估算概率(E)
该步骤找到最佳的切分方式,即需要计算每一种可能切分的概率,选取概率最大的切分。概率计算方式为每个次元概率相乘,如对于“pug”,其中一种切分方式的概率计算如下:
p
(
“
p
"
,
“
u
"
,
“
g
"
)
=
p
(
“
p
"
)
×
p
(
“
u
"
)
×
p
(
“
g
"
)
=
5
210
×
36
210
×
20
210
=
0.000389
p(“p", “u", “g")=p(“p")\times p(“u") \times p(“g")=\frac{5}{210} \times \frac{36}{210} \times \frac{20}{210}=0.000389
p(“p",“u",“g")=p(“p")×p(“u")×p(“g")=2105×21036×21020=0.000389
同理,可以计算出其它2种切分的概率:
["p", "u", "g"]: 0.000389
["p", "ug"]: 0.0022676
["pu", "g"]: 0.0022676
从以上选取概率最大的切分方式,如果一样泽随机选。在实际使用中,所有可能切分方式可以使用维特比算法得到。
删除词元(M)
即一次计算每一个词元的损失,然后删除损失最小的词元。我们使用-logP计算得到语料中每个词的词元切分及得分:
"hug": ["hug"] (score 0.071428)
"pug": ["pu", "g"] (score 0.007710)
"pun": ["pu", "n"] (score 0.006168)
"bun": ["bu", "n"] (score 0.001451)
"hugs": ["hug", "s"] (score 0.001701)
假设删除“hug”,相关词得分变化:
"hug": ["hu", "g"] (score 0.006802)
"hugs": ["hu", "gs"] (score 0.001701)
可以计算出该词元删除后增加的损失为:
- 10 * (-log(0.071428)) + 10 * (-log(0.006802)) = 23.5
同理可以计算出在这次的迭代中应该删除词元pu,使其总体损失最小。
不断迭代E-M,直到词表到设定大小为止。
参考资料
- Huggingface NLP course
- 大规模语言模型:从理论到实践 – 张奇、桂韬、郑锐、黄萱菁
- A New Algorithm for Data Compression
- Neural Machine Translation of Rare Words with Subword Units








![[C++] 从零实现一个ping服务](https://img-blog.csdnimg.cn/img_convert/7b0d6ba5dcce6ce6b2e732fdffde6496.gif#pic_center)