欢迎来到 Papicatch的博客
文章目录
🍉决策树算法介绍
🍈原理
🍈核心思想包括
🍍递归分割
🍍选择标准
🍍剪枝
🍈解题过程
🍍数据准备
🍍选择最佳分割特征
🍍分割数据集
🍍递归构建子树
🍍剪枝处理
🍈时间复杂度和空间复杂度
🍍时间复杂度
🍍空间复杂度
🍈优缺点
🍍优点
🍍缺点
🍉示例
🍈案例分析1
🍍加载数据集
🍍划分训练集和测试集
🍍构建决策树模型
🍍预测
🍍评估模型
🍍可视化决策树
🍈案例分析2
🍍详细解释
🍉总结
🍉决策树算法介绍
决策树算法是一种常见的机器学习算法,广泛应用于分类和回归问题中。它通过将数据集分割成更小的子集,并在这些子集上递归地构建树形结构,从而实现对数据的预测和分类。本文将介绍决策树算法的原理、核心思想、解题过程、时间复杂度和空间复杂度,以及其优点和缺点,并提供一个案例实现。
🍈原理
决策树的基本思想是将数据集逐步划分为不同的子集,使得每个子集中的数据更加同质化。具体来说,决策树通过选择特征及其对应的阈值来分割数据,选择的标准通常是信息增益或基尼指数等度量标准。树的每个节点表示一个特征,每条边代表该特征的一个取值或取值范围,叶子节点则表示分类结果或回归值。
🍈核心思想包括
🍍递归分割
从根节点开始,选择一个最佳特征进行分割,继续对分割后的子集进行分割,直到满足停止条件。
🍍选择标准
常用的选择标准有信息增益、信息增益率和基尼指数。信息增益用于ID3算法,信息增益率用于C4.5算法,而基尼指数用于CART算法。
🍍剪枝
为防止过拟合,决策树算法通常会进行剪枝,分为预剪枝和后剪枝。
🍈解题过程
决策树的构建过程可以概括为以下步骤:
🍍数据准备
收集并整理数据。
🍍选择最佳分割特征
根据某种标准(如信息增益、基尼指数等),选择一个特征进行分割。
🍍分割数据集
根据选择的特征将数据集分割成子集。
🍍递归构建子树
对每个子集,重复步骤2和步骤3,直到满足停止条件(如所有样本属于同一类别,或特征用尽)。
🍍剪枝处理
对生成的树进行剪枝,以提高模型的泛化能力。
🍈时间复杂度和空间复杂度
🍍时间复杂度
决策树的构建时间复杂度取决于数据集的大小和特征数量。构建过程中需要对每个特征进行排序,复杂度为 O(nlogn),因此总的时间复杂度为O(mnlogn),其中 m 为特征数量, n 为样本数量。
🍍空间复杂度
存储决策树的空间复杂度取决于树的深度和节点数量。最坏情况下,空间复杂度为O(nlogn)。
🍈优缺点
🍍优点
- 易于理解和解释:决策树的模型直观易懂,决策过程类似于人类的思考过程。
- 无需数据预处理:决策树不需要特征缩放或归一化,能处理缺失数据。
- 能够处理多种数据类型:既可以处理数值型特征,也可以处理分类型特征。
🍍缺点
- 容易过拟合:决策树如果不进行剪枝,容易对训练数据过拟合,泛化能力差。
- 对噪声敏感:对数据中的噪声较为敏感,可能导致模型性能下降。
- 偏倚问题:不同分割标准可能导致不同的树结构,对数据中的一些重要特征选择不敏感。
🍉示例
🍈案例分析1
以下是使用Python的scikit-learn库实现决策树分类的示例:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score🍍加载数据集
iris = load_iris()
X = iris.data
y = iris.target🍍划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)🍍构建决策树模型
clf = DecisionTreeClassifier(criterion='gini', max_depth=3, random_state=42)
clf.fit(X_train, y_train)🍍预测
y_pred = clf.predict(X_test)🍍评估模型
accuracy = accuracy_score(y_test, y_pred)
print(f'模型准确率: {accuracy:.2f}')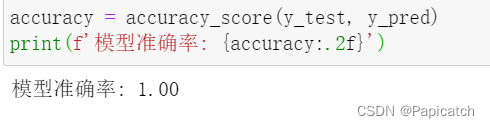
🍍可视化决策树
from sklearn.tree import plot_tree
import matplotlib.pyplot as plt
plt.figure(figsize=(12,8))
plot_tree(clf, filled=True, feature_names=iris.feature_names, class_names=iris.target_names)
plt.show()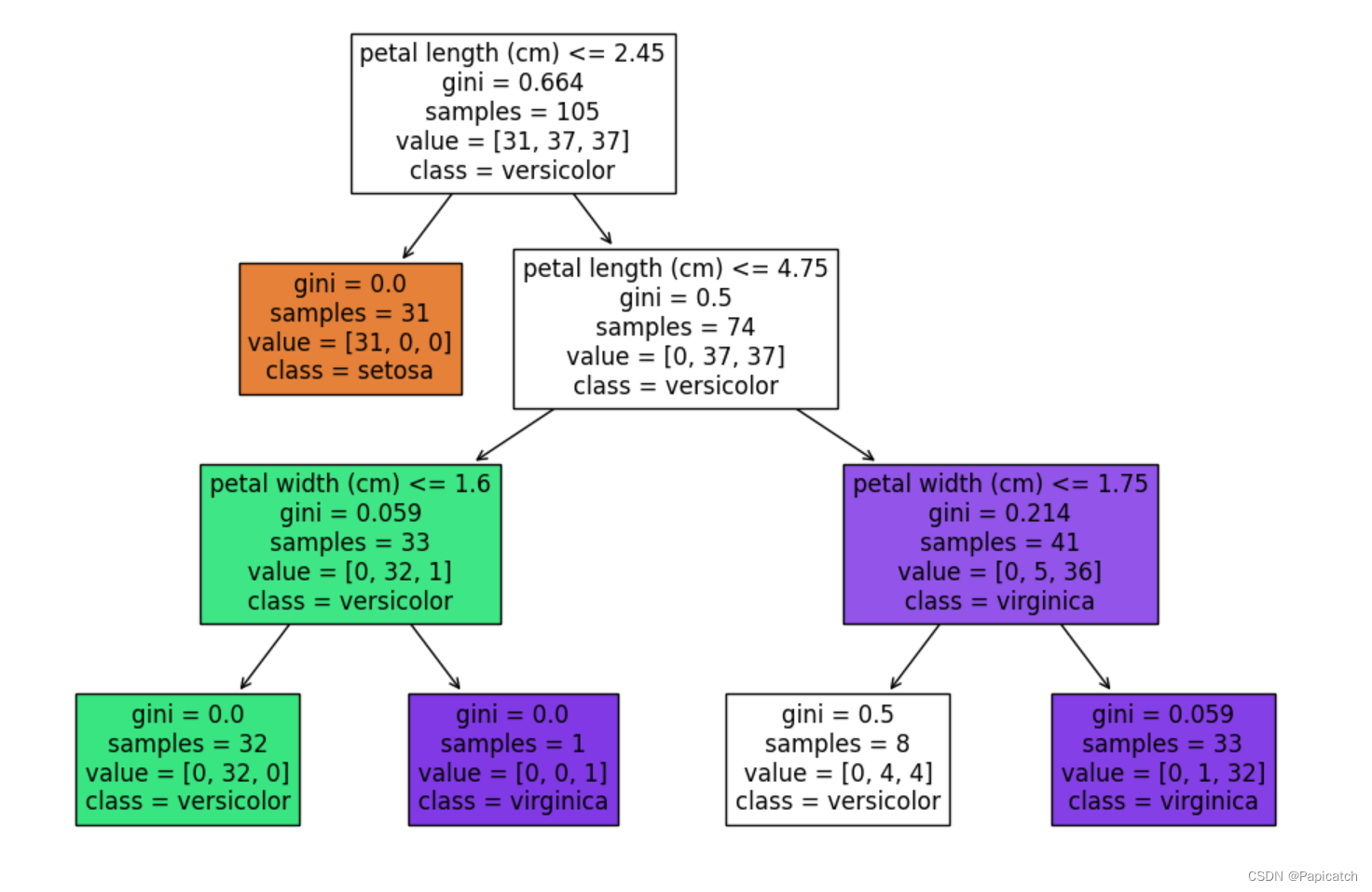
以上代码展示了如何使用决策树对Iris数据集进行分类,包括数据加载、模型训练、预测和评估,以及决策树的可视化。通过这种方式,我们可以直观地理解决策树的决策过程和模型性能。
🍈案例分析2
下面是一个更复杂的案例,实现了在一个金融数据集上的决策树分类模型,并进行了模型的性能评估和剪枝处理。
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.metrics import accuracy_score, classification_report
import matplotlib.pyplot as plt
# 加载数据集
data = pd.read_csv('financial_data.csv') # 假设数据集名为financial_data.csv
X = data.drop('target', axis=1)
y = data['target']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 构建决策树模型
clf = DecisionTreeClassifier(criterion='gini', max_depth=5, random_state=42)
clf.fit(X_train, y_train)
# 预测
y_pred = clf.predict(X_test)
# 评估模型
accuracy = accuracy_score(y_test, y_pred)
report = classification_report(y_test, y_pred)
print(f'模型准确率: {accuracy:.2f}')
print('分类报告:')
print(report)
# 可视化决策树
plt.figure(figsize=(20,12))
plot_tree(clf, filled=True, feature_names=X.columns, class_names=['Class 0', 'Class 1'])
plt.show()
# 剪枝处理
path = clf.cost_complexity_pruning_path(X_train, y_train)
ccp_alphas = path.ccp_alphas
clfs = []
for ccp_alpha in ccp_alphas:
clf = DecisionTreeClassifier(random_state=42, ccp_alpha=ccp_alpha)
clf.fit(X_train, y_train)
clfs.append(clf)
# 评估剪枝后的模型
train_scores = [accuracy_score(y_train, clf.predict(X_train)) for clf in clfs]
test_scores = [accuracy_score(y_test, clf.predict(X_test)) for clf in clfs]
plt.figure(figsize=(10,6))
plt.plot(ccp_alphas, train_scores, marker='o', label='Train', drawstyle="steps-post")
plt.plot(ccp_alphas, test_scores, marker='o', label='Test', drawstyle="steps-post")
plt.xlabel('Effective Alpha')
plt.ylabel('Accuracy')
plt.legend()
plt.title('Accuracy vs Alpha for Training and Testing Sets')
plt.show()
🍍详细解释
- 数据加载与预处理:加载金融数据集,并进行特征和目标变量的分离。
- 数据集划分:将数据集划分为训练集和测试集。
- 模型构建与训练:使用
DecisionTreeClassifier构建决策树模型,并进行训练。- 预测与评估:对测试集进行预测,并评估模型的准确率和分类报告。
- 模型可视化:可视化决策树,展示树的结构。
- 剪枝处理:通过计算成本复杂度剪枝路径,评估不同剪枝强度下模型的性能,并绘制准确率随剪枝参数变化的图。
🍉总结
总之,决策树算法在数据科学和机器学习中具有重要地位,理解其原理和实现方法对解决实际问题具有重要意义。
希望这些能对刚学习算法的同学们提供些帮助哦!!!