Hadoop3.X版本,在2017年左右就有了第一个alpha版本,但是那个时候刚出来,所以没有人使用,到2018年3.0.0版本作为第一个3,X正式发布,截止当前本文书写时间,3.X版本已经发展到了3.4,在Hadoop的顶层设计上最大的区别就是在2.X的时候,高可用机制只允许一个在工作中,一个在备用,但是3.X的hadoop允许最多存在五套高可用节点。当然,官方推荐最多三套,自带的MR计算框架也由原来的纯磁盘运算加入了内存运算的设计。
在给大家介绍3.X如何搭建集群之前,要先给大家说一些理论上的东西,当你要把Hadoop运行在商业硬件上。可以选择普通硬件供应商生产的标准化的、广泛有效的硬件来构建集群,无需使用特定供应商生产的昂贵、专有的硬件设备。但要注意商业硬件并不等同于低端硬件。低端机器常常使用便宜的零部件,其故障率远高于更贵一些,但仍是商业级别的机器。当管理几十台、上百台,甚至几千台机器时,选择便宜的零部件并不划算,因为更高的故障率推高了维护成本。也不推荐使用大型的数据库级别的机器,因为这类机器的性价比太低了。
在国内,很多互联网小作坊,可能会考虑使用少数几台数据库级别的机器来构建一个集群,使其性能达到一个中等规模的商业机器集群。然而,这会埋下很大的一个坑洞,当大比例的集群由于硬件故障无法使用,或者硬件规格过时后,会对整个集群产生更大的负面影响。
这里举例说明,在2010 年年中,运行Hadoop的datanode和tasktracker的典型机器具有以下规格:
处理器,两个四核2~2.5 GHz CPU
内存,16~24 GB ECC RAM (使用ECC内存能够有效减少Hadoop的效验错误)
存储器,4x1TB SATA 硬盘
网络,千兆以太网
在实际实施中,尽管各个集群采用的硬件规格肯定有所不同,但是Hadoop一般使用多核 CPU和多磁盘,以充分利用硬件的强大功能。
Hadoop本身尽管建议采用RAID作为 namenode的存储器以保护元数据,但是!不推荐直接使用RAID作为datanode的存储设备,因为它不会给HDFS带来其他益处。HDFS所提供的节点间数据复制技术已可满足数据备份需求,无需使用RAID的冗余机制。
此外,尽管RAID条带化技术(RAID0)被广泛用于提升性能,但是其速度仍然比用在HDFS 里的JBOD(Just a Bunch Of Disks)技术慢。JBOD可以在所有磁盘之间循环调度HDFS数据块。而RAID0的读写操作受限于磁盘阵列中最慢盘片的速度,而JBOD的磁盘操作均独立,因而平均读写速度高于最慢盘片的读写速度。需要强调的是,各个磁盘的性能在实际使用中总存在相当大的差异,即使对于相同型号的磁盘。雅虎集群曾经有过一个评测报告(http://markmail.org/message/xmzc45zi25htr7ry)表明,在一个测试(Gridmix)中,JBOD 比RAID0快10%,在另一测试(HDFS写吞吐量)中,JBOD 比 RAID 0 快 30%。最后,若JBOD配置的某一磁盘出现故障,HDFS可以忽略该磁盘,继续工作。而 RAID 的某一盘片故障会导致整个磁盘阵列不可用,进而使相应节点失效。
Hadoop 的主体由Java语言写成,能够在任意一个安装了JVM的平台上运行。但由于仍有部分代码(例如控制脚本)需在Unix环境下执行,因而Hadoop 并不适宜以最终产品的形态运行在非Unix平台上。
至于一个 Hadoop 集群到底应该有多大?这个问题并无确切答案。但是,Hadoop的魅力在于用户可以在初始阶段构建一个小集群(大约10个节点),并随存储与计算需求增长持续扩充。从某种意义上讲,更恰当的问题是:你的集群需要增长得多快?通过以下一个关于存储的例子可以体会更深。
假如数据每周增长1TB。如果采用三路HDFS复制技术(就是数据块的备份数+本身),则每周需要增加3 TB 存储能力。再加上一些中间文件和日志文件(约占30%),基本上相当于每周添设一台机器(2010年的典型机器)。当然在实际上,一般不会每周去购买一台新机器并将其加入集群。类似这样的粗略计算意义在于了解集群的规模:既,在本例中,保存两年数据大致需要100台机器。
而对于一个小集群(几十个节点)而言,在一台master机器上同时运行 namenode 和jobtracker(这个组件是yarn的前身,但是很多外语文献任然会使用这个名称),通常没问题,但需确保至少一份namenode的元数据被另存在远程文件系统中。随着HDFS中的集群和文件数不断增长, namenode 需要使用更多内存,在这种情况下namenode和jobtracker,最好分别放在不同机器中。辅助 namenode可以和namenode一起运行在同一台机器之中,但是同样由于内存使用的原因(辅助namenode 和主namenode的内存需求相同),二者最好运行在独立的硬件之上,对于大规模集群来说,更是如此。
这里和大家说一个有意思的点,在早期,人们通常这样认为,集群应该配备的是32位机器,以避免大指针引起的存储开销。Sun公司的Java 6 update 14的特色之一“压缩的普通对象指针”显著降低了这类开销,因而说白了现在在64位硬件上运行 Hadoop是会降低它的性能的。
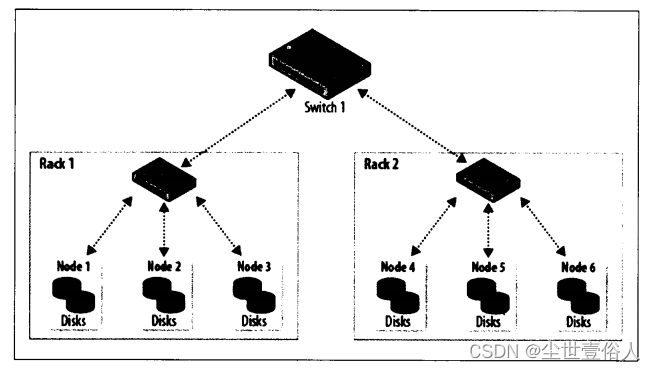
在网络策略上,Hadoop 集群架构通常包含两级网络拓扑,如上图所示。一般来说,各机架装配30~40个服务器,共享一个1GB的交换机(该图中各机架只画了3个服务器),各机架的交换机又通过上行链路与一个核心交换机或路由器(通常为1GB或更高)互联。该架构的突出特点是同一机架内部的节点之间的总带宽要远高于不同机架上的节点间的带宽。
在机架选择上,为了达到Hadoop的最佳性能,配置Hadoop系统以让其了解网络拓扑状况就极为关键。如果集群只包含一个机架,就无需做什么,因为这是默认配置。但是对于多机架的集群来说,描述清楚节点-机架间的映射关系就很有必要。这样的话,当Hadoop将MapReduce任务分配到各个节点时,会倾向于执行机架内的数据传输(拥有更多带宽),而非跨机架数据传输。HDFS将能够更加智能地放置复本(replica),以取得性能和弹性的平衡。
诸如节点和机架等的网络位置以树的形式来表示,从而能够体现出各个位置之间的网络“距离”。namenode使用网络位置来确定在哪里放置块的复本,MapReduce的调度器根据网络位置来查找最近的复本,将它作为map任务的输入。
在上面的网络拓扑图中,机架拓扑由两个网络位置来描述,即/switchl/rack1和/switchl/rack2。由于该集群只有一个顶层路由器,这两个位置可以简写为/rack1 和/rack2。
Hadoop 配置需要通过一个Java接口DNSToSwitchMapping来指定节点地址和网络位置之间的映射关系。该接口定义如下:
public interface DNSToSwitchMapping {
public List<String> resolve(List<String> names);
}
resolve()函数的输入参数names 描述IP地址列表,返回相应的网络位置字符串列表。topology.node.switch.mapping.impl配置属性实现了 DNSToSwitchMapping接口,namenode和jobtracker均采用它来解析工作节点的网络位置。
在上例的网络拓扑中,可将node1、node2 和node3映射到/rack1,将 node4、node5 和node6 映射到/rack2 中。
但是,大多数安装并不需要额外实现新的接口,只需使用默认的 ScriptBasedMapping实现即可,它运行用户定义的脚本来描述映射关系。脚本的存放路径由属性topology.script.file.name控制。脚本接受一系列输入参数,描述带映射的主机名称或IP地址,再将相应的网络位置以空格分开,输出到标准输出。可以参考Hadoop wiki的一个例子,网址为http://wiki.apache.org/hadoop/topology_rack_awareness_scripts。如果没有指定脚本位置,默认情况下会将所有节点映射到单个网络位置,即/default-rack。
开始正式安装
注意:安装所需的服务器SSH免密互信等环境准备,这里就不演示了,有需要,去我主页找原生大数据集群搭建二里面看。
第一步:本次操作的版本是3.3.6,上传Hadoop安装包解压即可,这里有一个坑要注意,按照试错经验以及官网的一些资料,发现默认情况下3.x的hadoop是不允许root用户启动的,但是如果你用更改用户的方式搭建3.x就会发现在启动的时候,无论你关闭SELinux安全模块也好,还是用sudo也好,都无法越过Linux的线程优先级拦截,所以我们需要搭建的时候通过在配置文件里面追加新配置的方式,替换掉默认的用户启动限制。
cd /opt
tar -zxvf hadoop-3.3.6.tar.gz
第二步:进入配置文件所在的路径${HADOOP_HOME}/etc/hadoop,修改所有*-env.sh中存在的JAVA_HOEM值
第三步:打开hadoop-env.sh文件修改如下配置项,指定root用户为运行这些组件的用户,注意除了HDFS_NAMENODE_USER使原本就有的配置,其他的都是直接追加就行。
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_ZKFC_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
第四步:修改配置文件core-site.xml
<configuration>
<!--
集群的 namenode组 访问地址在这里指定!注意我说的组是主、备的统称,该值必须和hdfs-site.xml文件中的组名配置一致,
这里之所以强调就是防止大家两个文件写的不一样,大家使用自己的配置就可以,不是必须为hdp
-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hdp</value>
</property>
<!-- hadoop的运行时的临时数据的本地存放目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-3.3.6/hdpData/tmp</value>
</property>
<!-- 配置HDFS网页登录使用的静态用户:Root,你如果不设置这个那么你就需要把hdfs的所有文件全选改为777不然操作不了-->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- ZooKeeper集群的地址和端口。注意,数量一定是奇数,且不少于三个节点-->
<property>
<name>ha.zookeeper.quorum</name>
<value>hdp4:2181,hdp5:2181,hdp6:2181</value>
</property>
<!--修改core-site.xml中的ipc参数,防止出现连接journalnode服务ConnectException,默认10s-->
<property>
<name>ipc.client.connect.max.retries</name>
<value>100</value>
</property>
<property>
<name>ipc.client.connect.retry.interval</name>
<value>10000</value>
</property>
</configuration>
第五步:修改配置文件hdfs-site.xml,配置的时候注意3.x允许最多存在5个namenode,但是官方建议3个位最佳,可以节省很多不必要的网络IO
<configuration>
<!--指定hdfs的nameservice服务组名字,再次声明hdp只是一个名字啊,不是hdp这个节点,大家觉得别扭可以改成别的,但一定要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>hdp</value>
</property>
<!-- 这个配置时用来标识hdp下面有主、备共三个NameNode,并且为他们标识名字,我配置的分别是nn1,nn2,nn3 -->
<property>
<name>dfs.ha.namenodes.hdp</name>
<value>nn1,nn2,nn3</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.hdp.nn1</name>
<value>hdp4:8020</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.hdp.nn1</name>
<value>hdp4:9870</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.hdp.nn2</name>
<value>hdp5:8020</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.hdp.nn2</name>
<value>hdp5:9870</value>
</property>
<!-- nn3的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.hdp.nn3</name>
<value>hdp6:8020</value>
</property>
<!-- nn3的http通信地址 -->
<property>
<name>dfs.namenode.http-address.hdp.nn3</name>
<value>hdp6:9870</value>
</property>
<!-- 指定NameNode的edits元数据在JournalNode上的存放位置,这个配置本质上的目的就是在zk上使用一个zk节点,保存namenode同步数据-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hdp4:8485;hdp5:8485;hdp6:8485/hdp</value>
</property>
<!-- 指定JournalNode数据在本地磁盘存放日志数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/hadoop-3.3.6/hdpData/journaldata</value>
</property>
<!-- 开启NameNode死亡自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 指定该集群出故障时,哪个实现类负责执行故障切换 -->
<property>
<name>dfs.client.failover.proxy.provider.hdp1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用sshfence隔离机制时需要ssh免登陆,因此需要指定公钥路径,大家集群中ssh之后的公钥文件在哪里就指定那里,一般在用户主目录下的 .ssh文件夹里面-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 配置sshfence隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<!-- namenode与datanode存储多路径配置,且更改datanode磁盘写入规则,但是注意默认情况下数据时写进hdfs的所以如果你想和我一样写在本地磁盘里面就要加上file:///前缀,第一个斜杠是 URI 方案的结尾,第二个斜杠是文件路径的根目录,第三个斜杠是文件路径的开始 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///opt/hadoop-3.3.6/hdpData/dfs/data,file:///opt/hadoop-3.3.6/hdpData/dfs/data1</value>
</property>
<property>
<name>dfs.datanode.fsdataset.volume.choosing.policy</name>
<value>org.apache.hadoop.hdfs.server.datanode.fsdataset.AvailableSpaceVolumeChoosingPolicy</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///opt/hadoop-3.3.6/hdpData/dfs/name,file:///opt/hadoop-3.3.6/hdpData/dfs/name1</value>
</property>
<!--副本数量,默认3个-->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
第六步:修改配置文件mapred-site.xml
<configuration>
<!-- 指定mr框架为yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 历史服务器的外部服务端口 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hdp5:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hdp5:19888</value>
</property>
<!--MapReduce应用程序管理器的暂存目录,是一个hdfs路径-->
<property>
<name>yarn.app.mapreduce.am.staging-dir</name>
<value>/hisdata/staging</value>
</property>
<!--MR JobHistory Server管理的已完成的日志的存放位置,是一个hdfs路径-->
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/hisdata/done</value>
</property>
<!-- MapReduce作业产生的中间完成日志存放位置,是一个hdfs路径 -->
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/hisdata/done_intermediate</value>
</property>
<!--以下的配置值就是把你的HOME路径配上去,因为不配置的话运行MapReduce会提示检查-->
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/opt/hadoop-3.3.6</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/opt/hadoop-3.3.6</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/opt/hadoop-3.3.6</value>
</property>
</configuration>
第七步:修改yarn-site.xml配置文件
<configuration>
<!-- 开启RM高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!-- 指定RM的名字,对应主备namenode -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hdp5</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hdp6</value>
</property>
<!-- 指定zk集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hdp4:2181,hdp5:2181,hdp6:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 阻止磁盘检查 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!--配置外部端口-->
<!-- yarn对applicationmaster服务的端口 -->
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>hdp5:8030</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>hdp6:8030</value>
</property>
<!-- yarn对nodemanager服务的地址 -->
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm1</name>
<value>hdp5:8031</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2</name>
<value>hdp6:8031</value>
</property>
<!--yarn对客户端服务的端口 -->
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>hdp5:8032</value>
</property>
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>hdp6:8032</value>
</property>
<!-- yarn对管理员服务的地址 -->
<property>
<name>yarn.resourcemanager.admin.address.rm1</name>
<value>hdp5:8033</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm2</name>
<value>hdp6:8033</value>
</property>
<!-- yarn web UI服务的地址 -->
<property>
<name>yarn.resourcemanager.web.address.rm1</name>
<value>hdp5:8088</value>
</property>
<property>
<name>yarn.resourcemanager.web.address.rm2</name>
<value>hdp6:8088</value>
</property>
<!--开启Continer日志聚合,否则无法在web页面查看mr的日志-->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!--把yarn的日志存放在历史服务器上的一个路径-->
<property>
<name>yarn.log.server.url</name>
<value>http://hdp5:19888/jobhistory/logs</value>
</property>
<!-- 以下三项配置是修改hadoop对历史MR任务的保存态度,使得重启后yarn-ui的历史MR记录不会丢失 -->
<property>
<!-- 开启作业保留 -->
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<!-- 指定保存与加载历史任务的类,总计三个可选项,但高可用集群必须使用ZK -->
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<property>
<!-- yarn重启后等待历史任务被加载的时间 -->
<name>yarn.resourcemanager.work-preserving-recovery.scheduling-wait-ms</name>
<value>10000</value>
</property>
<!-- 下面这两个配置是计算任务运行时资源队列允许每个Continer容器占用内存资源的大/小最值,全局配置不需要区分ResourceManager实例 -->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>1024</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>8192</value>
</property>
<!-- 下面这两个配置是计算任务运行时资源队列允许每个Continer容器占用虚拟核数资源的大/小最值,全局配置不需要区分ResourceManager实例 -->
<property>
<name>yarn.scheduler.minimum-allocation-vcores</name>
<value>1</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-vcores</name>
<value>3</value>
</property>
<!-- 下面这两个配置在当前节点如果是datanode时生效规定当前节点可用总内存和可用总核数,全局配置不需要区分ResourceManager实例 -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>32768</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>4</value>
</property>
<!-- 配置虚拟内存额外使用比例 -->
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>1.5</value>
</property>
<!-- datanode是否检查内存超出 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>true</value>
</property>
<!-- 指定yarn的任务队列类型为容器 -->
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
</configuration>
第八步:按照自己的需要修改CapacityScheduler调度器配置文件capacity-scheduler.xml
<configuration>
<property>
<name>yarn.scheduler.capacity.maximum-applications</name>
<value>10000</value>
<description>
整个集群正在运行的以及等待中的任务的最大数
</description>
</property>
<property>
<name>yarn.scheduler.capacity.maximum-am-resource-percent</name>
<value>0.1</value>
<description>
整个集群中有多少资源可以可以用来运行applicationmaster
该配置主要用来限制正在运行的任务数量,防止集群过载
当前是整个集群的全局配置,如果你有需要可以使用
yarn.scheduler.capacity.<queue-path>.maximum-am-resource-percent
来规定某一个队列的
</description>
</property>
<property>
<name>yarn.scheduler.capacity.resource-calculator</name>
<value>org.apache.hadoop.yarn.util.resource.DominantResourceCalculator</value>
<description>
使用的资源计算类
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>default</value>
<description>
有多少个一级队列用英文逗号隔开
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.capacity</name>
<value>100</value>
<description>该队列占总队列(root)的多少资源,是个百分比的值</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.user-limit-factor</name>
<value>1</value>
<description>
不同用户向该队列提交时最多使用多少资源,例如1或0,5
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.maximum-capacity</name>
<value>100</value>
<description>
该队列自身资源最大的可使用资源占比,是一个百分比值,意味着该队列
已使用的资源到达该值后,即使有空闲资源也不会再给其他任务使用
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.state</name>
<value>RUNNING</value>
<description>
该队列的状态RUNNING(可使用) or STOPPED(暂停使用).
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.acl_submit_applications</name>
<value>*</value>
<description>
谁可以向该队里及其子队列提交任务,默认*,既全部用户
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.acl_administer_queue</name>
<value>*</value>
<description>
谁可以管理该队里及其子队列任务,比如做kill操作等,默认*,既全部用户
</description>
</property>
<property>
<name>yarn.scheduler.capacity.node-locality-delay</name>
<value>40</value>
<description>
控制 YARN 调度器在放弃节点本地性(node locality)
并考虑机架本地性(rack locality)或其他非本地性资源之前
应该等待的调度机会数量
</description>
</property>
<property>
<name>yarn.scheduler.capacity.queue-mappings</name>
<value></value>
<description>
一般不使用,它是指当你需要更加细致的用户队列映射时使用
语法如下:[u or g]:[name]:[queue_name][,next_mapping]
比如:u:user1:queueA,g:group1:queueB,u:user2:queueC
用户 user1 会被映射到 queueA 队列。
组 group1 中的所有用户会被映射到 queueB 队列。
用户 user2 会被映射到 queueC 队列
</description>
</property>
<property>
<name>yarn.scheduler.capacity.queue-mappings-override.enable</name>
<value>false</value>
<description>
这个配置是用来决定你是否允许用户或者应用程序通过动态配置
来覆盖你已经设置好的队列配置,通常保持false,主要是防止用户
之间访问不应该访问的运行资源
</description>
</property>
</configuration>
如果在未来你该更改capacity-scheduler.xml文件中的配置,更改完一定不要直接重启集群,要运行一下yarn rmadmin -refreshQueues命令才可以
第九步:修改workers配置文件,这个就是datanode节点,2.x版本叫做slaves,3.x改名了
hdp4
hdp5
hdp6
第十步:使用scp命令把hadoop包发送到其他节点上
第十一步:开始格式化。
1、首先你要确保你的Zookeeper时启动好的,这一步不需要受用户的影响,你自己的zookeeper该怎么启动就怎么启动就行,然后就是确保你的环境变量配置好了。
export JAVA_HOME=/opt/jdk1.8.0_333
export HADOOP_HOME=/opt/hadoop-3.3.6
export ZOOKEEPER_HOME=/opt/zookeeper-3.7.2
export PATH=$PATH:${JAVA_HOME}/bin
export PATH=$PATH:${HADOOP_HOME}/bin
export PATH=$PATH:${HADOOP_HOME}/sbin
export PATH=$PATH:${ZOOKEEPER_HOME}/bin
export HADOOP_CONF_DIR=/opt/hadoop-3.3.6/etc/hadoop
2、在所有的datanode节点上手动启动journalnode进程
${HADOOP_HOME}/sbin/hadoop-daemon.sh start journalnode
或者
${HADOOP_HOME}/bin/hdfs --daemon start journalnode
运行之后jsp检查,查看是否有journalnode进程
3、在你准备的主节点上格式化namenode
${HADOOP_HOME}/bin/hdfs namenode -format
4、在主namenode上运行命令,启动它,注意这一点和2.x不一样,2.x这时候可以运行start-dfs.sh直接启动hdfs,但是3.x不行,如果你运行了start-dfs.sh你会发现在操作journalnode会触发优先级拦截
${HADOOP_HOME}/bin/hdfs --daemon start namenode
5、在其他两个备用namenode节点运行命令同步主namenode数据
${HADOOP_HOME}/bin/hdfs namenode -bootstrapStandby
命令会在Found nn*卡一会不要着急
6、格式化zkfc,在主namenode上运行一次就可以
${HADOOP_HOME}/bin/hdfs zkfc -formatZK
7、启动hdfs和yarn
${HADOOP_HOME}/sbin/start-dfs.sh
${HADOOP_HOME}/sbin/start-yarn.sh
第一次启动hdfs的时候可能会在namendoe的一个文件上卡一下资源优先级,但是不要慌后面不报错正常启动完成就行,要注意的是后续启动hdfs不需要单独启动namenode了,会随着启动,但是active节点激活可能有些慢,而且随着你集群的namenode越多,这个时间越长。
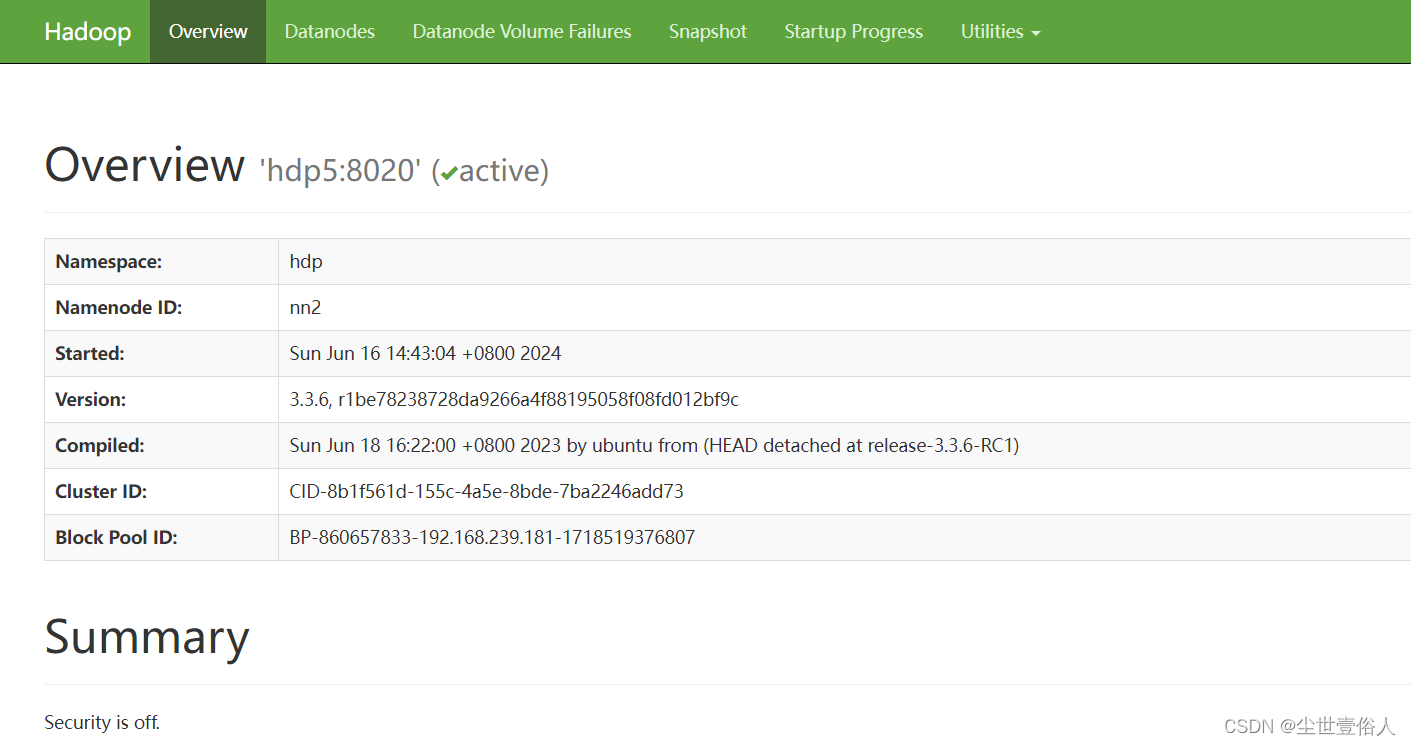
8、访问三个namenode的9870端口,查看namenode的状态
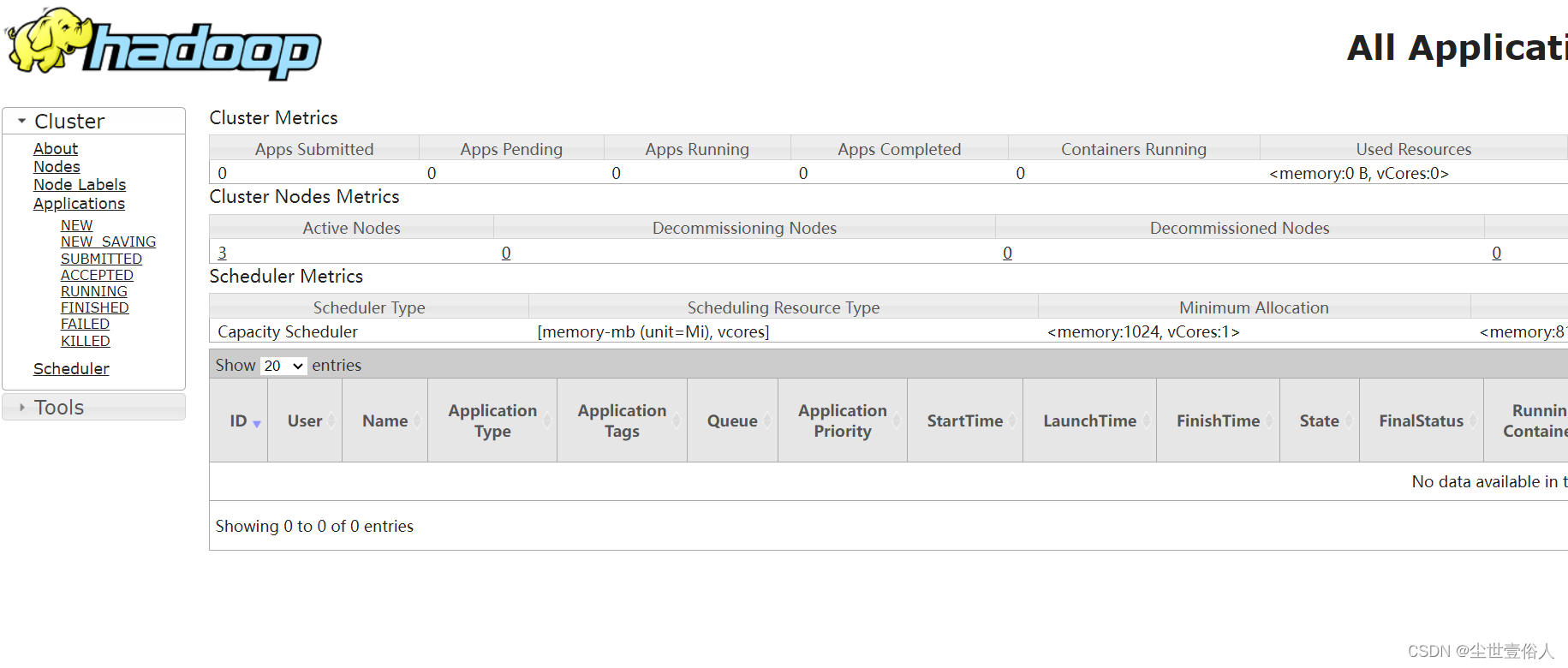
访问yarn节点的8088端口可以打开yarn的ui
跑一个自带的MR测试任务运行
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output
最后你可以写一个shell脚本放在主namenode节点上来启动hadoop
#!/bin/bash
#该脚本用来启动所有服务,通过参数决定
#集群地址
cluster = (hdp4 hdp5 hdp6)
case $1 in
"zk_start"){
#启动zookeeper
echo `date` > /opt/start_ap_log/zk_start.log
for i in cluster
do
echo "-----------正在启动$i的zookeeper---------"
echo "$i--zookeeper:" >> /opt/start_ap_log/zk_start.log
ssh $i "source /etc/profile && /opt/zookeeper-3.4.10/bin/zkServer.sh start" >> /opt/start_ap_log/zk_start.log
done
};;
"zk_stop"){
#关闭zookeeper
echo `date` > /opt/start_ap_log/zk_stop.log
for i in cluster
do
echo "-----------正在关闭$i的zookeeper---------"
echo "$i--zookeeper:" >> /opt/start_ap_log/zk_stop.log
ssh $i "source /etc/profile && /opt/zookeeper-3.4.10/bin/zkServer.sh stop" >> /opt/start_ap_log/zk_stop.log
done
};;
"hdp_start"){
#开启hadoop
echo `date` > /opt/start_ap_log/hdp_start.log
echo "----------------开始启动namenode-hdfs----------------"
/opt/hadoop-3.3.6/sbin/start-dfs.sh >> /opt/start_ap_log/hdp_start.log
echo `date` > /opt/start_ap_log/yarn_start.log
echo "----------------开始启动yarn----------------"
echo "yarn节点----------------------" >> /opt/start_ap_log/yarn_start.log
ssh hdp5 "source /etc/profile && /opt/hadoop-3.3.6/sbin/start-yarn.sh" >> /opt/start_ap_log/yarn_start.log
echo "----------------开始启动his----------------"
echo `date` > /opt/start_ap_log/his_start.log
ssh hdp5 "source /etc/profile && /opt/hadoop-3.3.6/sbin/mr-jobhistory-daemon.sh start historyserver" >> /opt/start_ap_log/his_start.log
};;
"hdp_stop"){
#关闭hadoop
echo "----------------开始关闭his----------------"
echo `date` > /opt/start_ap_log/his_stop.log
ssh hdp5 "source /etc/profile && /opt/hadoop-3.3.6/sbin/mr-jobhistory-daemon.sh stop historyserver" >> /opt/start_ap_log/his_stop.log
echo `date` > /opt/start_ap_log/yarn_stop.log
echo "----------------开始关闭yarn----------------"
echo "yarn节点----------------------" >> /opt/start_ap_log/yarn_stop.log
ssh hdp5 "source /etc/profile && /opt/hadoop-3.3.6/sbin/stop-yarn.sh" >> /opt/start_ap_log/yarn_stop.log
echo "----------------关闭namenode-hdfs------------"
echo `date` > /opt/start_ap_log/hdp_stop.log
/opt/hadoop-3.3.6/sbin/stop-dfs.sh >> /opt/start_ap_log/hdp_stop.log
};;
esac







![[论文精读]Line Graph Neural Networks for Link Prediction](https://img-blog.csdnimg.cn/direct/4b8272eef3d940ae9017a714f856381e.png)