本文章是针对论文《2017-CVPR-DenseNet-Densely-Connected Convolutional Networks》中实验的复现,使用了几乎相同的超参数
目录
一、论文中的实验
1.准确率
2.参数效率
3.不同网络结构之间的比较
二、超参数:
三、复现的实验结果:
1.DenseNet201 epoch=40:
2.DenseNet121 epoch=40:
3.ResNet18 epoch=40:
三、结论
1.准确率
2.参数效率
一、论文中的实验
在源论文中,作者使用CIFAR10,CIFAR100和SVHN三个数据集上使用了一些包括DenseNet-BC(以下统称DenseNet)和ReNet的网络进行测试,最终的错误率如下:
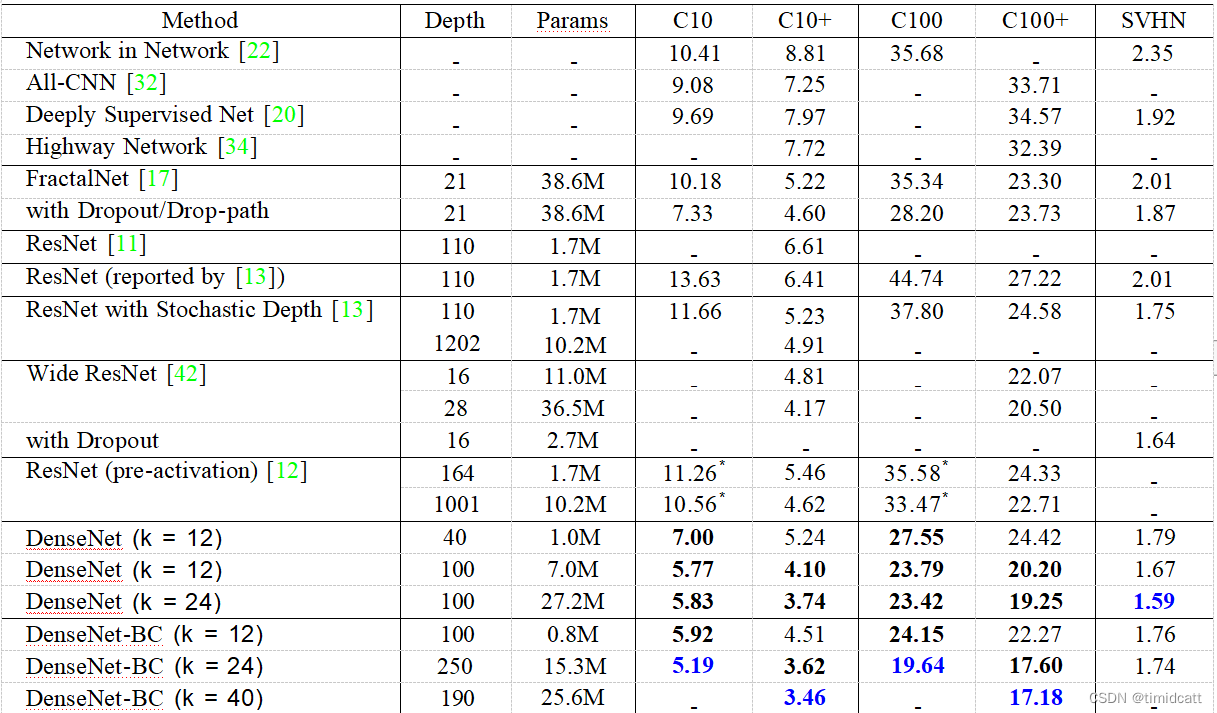
1.准确率
在没有数据增强的情况下,DenseNet的准确率显著超过了其他网络,在有数据增强的情况下,也有微弱优势
2.参数效率
在参数数量相等的情况下,DenseNet优更低的错误率,在达到相同错误率时,DenseNEt只用了1/3的参数

3.运算复杂度

要达到同样的错误率,DenseNet进行的浮点运算次数更少
4.不同网络结构之间的比较
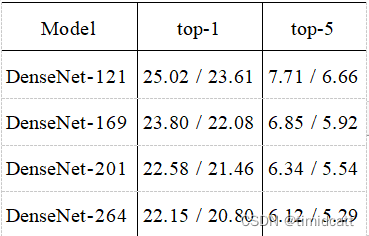
网络层数越多,错误率越低
二、超参数:
#使用镜像加裁剪的数据增强,以及使用通道均值和标准差对数据进行归一化
transform_train = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomCrop(32, padding=4),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
])
#使用通道均值和标准差对数据进行归一化
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
])#载入训练集50000张图片,batchsize=64
trainset = tv.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform_train)
trainloader = t.utils.data.DataLoader(trainset, batch_size=64,
shuffle=True, num_workers=0)
#载入测试集10000张图片
testset = tv.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform_test)
testloader = t.utils.data.DataLoader(testset, batch_size=64,shuffle=False, num_workers=0)
#使用GPU训练
MyDevice = t.device("cuda:0" if t.cuda.is_available() else "cpu")# 权重初始化(本论文中直接引用的另一篇论文的权重初始化,这里也是直接拿过来用)
def weights_init(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
nn.init.kaiming_normal_(m.weight)
elif classname.find('BatchNorm') != -1:
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
net.apply(weights_init)
net=net.to(MyDevice)#交叉熵损失函数
criterion = nn.CrossEntropyLoss()
#使用SGD优化,初始学习率为0.1,使用权重衰减为0.0001和0.9的Nesterov动量
optimizer = optim.SGD(net.parameters(), lr=0.1, momentum=0.9, weight_decay=1e-4)
#在训练周期为总周期的50%和75%时,学习率降低10倍
scheduler = MultiStepLR(optimizer, milestones=[20,30], gamma=0.1)三、复现的实验结果:
论文中给出了DenseNet的四中结构,我们首先分别使用121和201使用同样的超参数进行了测试:
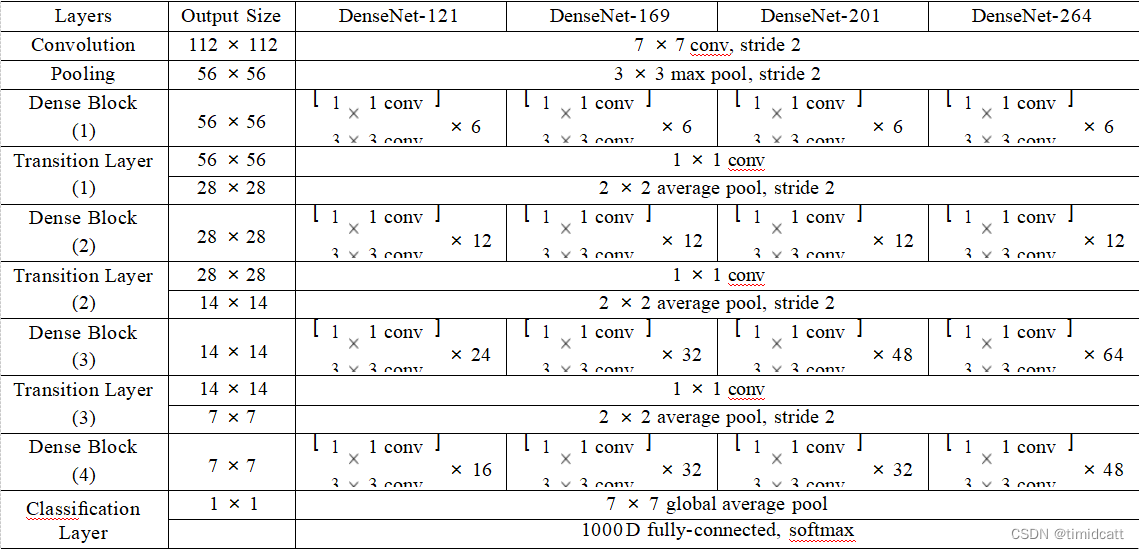
1.DenseNet201 epoch=40:
#直接使用pytorch提供的网络
net = models.densenet121(pretrained=False,num_classes=10).to(MyDevice)
![]()

2.DenseNet121 epoch=40:
#直接使用pytorch提供的网络
net = models.densenet121(pretrained=False,num_classes=10).to(MyDevice)
![]()

可以很明显的看出201相比121的优势很明显
对于ResNet,我们同样使用了最简单ResNet18和较复杂的ResNet101:
3.ResNet18 epoch=40:
net = models.resnet18(pretrained=False,num_classes=10).to(MyDevice)![]()
4.ResNet101 epoch=40:
net = models.resnet101(pretrained=False,num_classes=10).to(MyDevice)![]()

准确率极低,可能是过拟合导致的
三、结论
1.准确率
复现的实验准确率与论文中的实验准确率存在差距,原因可能是仍有部分超参数不同,论文中有一些超参数时直接引用的其他论文,没有给出具体参数,比如“We adopt a standard data aug-mentation scheme (mirroring/shifting) that is widely used for these two datasets[11, 13, 17, 22, 28, 20, 32, 34]”,我们没有时间和能力去读额外的论文,所以采用了便于实现的镜像+裁剪来进行数据增强。在权重初始化和定义优化函数时也遇到了类似的问题,所以实验并不是100%复现
在复现的实现中,ResNet18和DenseNet201的准确率几乎一样,与论文中使用数据增强时的结果类似
2.参数效率
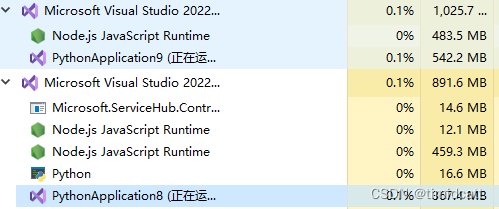
DenseNet的参数效率确实比DenseNet,可以从运行时的程序内存占用大概看出来(PythonApplication9在运行ResNet18,PythonApplication8在运行DenseNet201)
3.过拟合
从上面ResNet101的结果可以看出,在使用相同超参数的情况下,ResNet很早就出现了损失下降二准确率没有提高的过拟合迹象,即使学习率改变也没有改善,而DenseNet没有出现这种情况
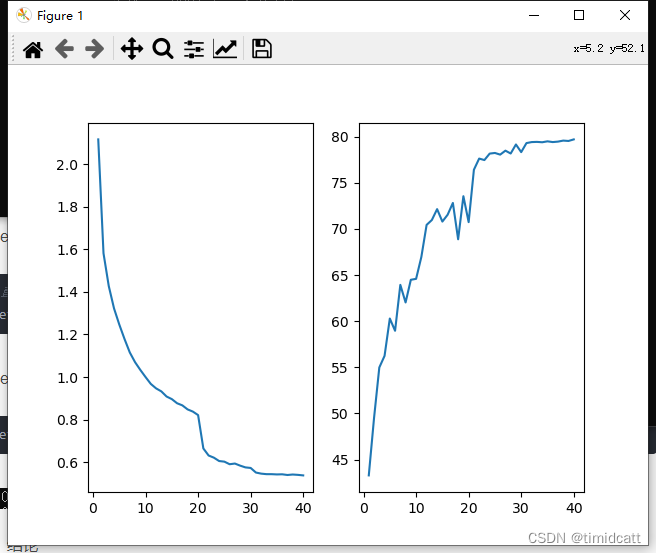
4.运算复杂度
在进行epoch=300的复现实验时,两个网络是同时开始在同一设备上运行的,在任意相同时刻时,DenseNet达到的准确率都要更高,可以印证论文中的说法

如图:左边是DenseNet201,右边是ResNet8




![[论文精读]Line Graph Neural Networks for Link Prediction](https://img-blog.csdnimg.cn/direct/4b8272eef3d940ae9017a714f856381e.png)



![[Linux] UDP协议介绍:UDP协议格式、端口号在网络协议栈那一层工作...](https://img-blog.csdnimg.cn/img_convert/89f8d427a90f84f4b1646b96963cbd91.webp?x-oss-process=image/format,png)


