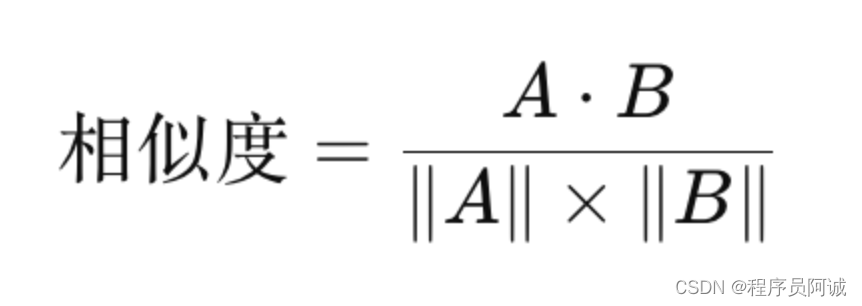桂电人工智能学院大数据实验,使用 Docker 搭建 hadoop 集群
第一步
安装 Docker, Windows 上可以使用 Docker Desktop
下载地址:https://www.docker.com/products/docker-desktop/
安装过程自行谷歌
安装好的标志:打开终端

运行docker ps,显示下面内容即安装成功

第二步
创建一个文件夹,名字随意,在文件夹下面新建docker-compose.yml
这是什么?
docker-compose.yml 是一个用来定义和管理多容器 Docker 应用的配置文件。通过 docker-compose.yml 文件,你可以定义多个服务(容器),以及它们之间的关系、依赖和配置。这个文件使用 YAML(YAML Ain’t Markup Language)格式编写,非常易读。
编写 docker-compose.yml
version: "3"
networks:
hadoop-net:
driver: bridge
services:
# Namenode服务:HDFS的主节点,管理文件系统命名空间,控制客户端对文件的访问,维护所有文件和目录的元数据。
namenode:
image: apache/hadoop:3
hostname: namenode
command: ["hdfs", "namenode"]
user: "root:root"
ports:
- 19000:9000 # HDFS Namenode服务端口
- 9870:9870 # Namenode Web UI端口
- 8020:8020 # HDFS Namenode RPC端口
volumes:
- namenode:/tmp/hadoop-root/dfs
env_file:
- ./config.env
privileged: true
environment:
ENSURE_NAMENODE_DIR: "/tmp/hadoop-root/dfs/name" # 确保Namenode目录存在
networks:
- hadoop-net
# Datanode服务:HDFS的工作节点,存储实际的数据块,处理客户端的读写请求,根据Namenode的指示执行数据块的创建、删除和复制操作。
datanode:
image: apache/hadoop:3
hostname: datanode
command: ["hdfs", "datanode"]
user: "root:root"
env_file:
- ./config.env
privileged: true
volumes:
- datanode:/tmp/hadoop-root/dfs # 存储数据块的路径
networks:
- hadoop-net
# Datanode2服务:另一个Datanode实例,用于增加集群的存储容量和数据冗余。
datanode2:
image: apache/hadoop:3
hostname: datanode2
command: ["hdfs", "datanode"]
user: "root:root"
env_file:
- ./config.env
privileged: true
volumes:
- datanode2:/tmp/hadoop-root/dfs # 存储数据块的路径
networks:
- hadoop-net
# Datanode3服务:又一个Datanode实例,用于进一步增加集群的存储容量和数据冗余。
datanode3:
image: apache/hadoop:3
hostname: datanode3
command: ["hdfs", "datanode"]
user: "root:root"
env_file:
- ./config.env
privileged: true
volumes:
- datanode3:/tmp/hadoop-root/dfs # 存储数据块的路径
networks:
- hadoop-net
# ResourceManager服务:YARN中的主节点,负责资源的管理和分配,调度作业在集群中运行。
resourcemanager:
image: apache/hadoop:3
hostname: resourcemanager
command: ["yarn", "resourcemanager"]
user: "root:root"
ports:
- 8088:8088 # ResourceManager Web UI端口
- 8030:8030 # ResourceManager RPC端口
- 8031:8031 # ResourceManager端口
- 8032:8032 # ResourceManager端口
- 8033:8033 # ResourceManager端口
env_file:
- ./config.env
volumes:
- ./test.sh:/opt/test.sh # 挂载测试脚本
networks:
- hadoop-net
# NodeManager服务:YARN中的工作节点,负责单个节点上的资源管理和任务执行。
nodemanager:
image: apache/hadoop:3
command: ["yarn", "nodemanager"]
user: "root:root"
env_file:
- ./config.env
ports:
- 8042:8042 # NodeManager Web UI端口
networks:
- hadoop-net
# 用于在宿主机设置 socks5 代理以使用容器内 hadoop-net 网络,不然使用 hadoop 的 webui 不能上传文件
socks5:
image: serjs/go-socks5-proxy
container_name: socks5
ports:
- 10802:1080
restart: always
networks:
- hadoop-net
# Jupyter服务:用于在Jupyter Notebook中进行PySpark实验。
jupyter:
image: jupyter/pyspark-notebook
user: root
restart: always
volumes:
- ./notebooks:/home/jupyternb
environment:
- NB_USER=jupyternb
- NB_UID=1000
- NB_GID=100
- CHOWN_HOME=yes
- JUPYTER_TOKEN=123456
command: start.sh jupyter notebook --NotebookApp.token=${JUPYTER_TOKEN}
working_dir: /home/jupyternb
ports:
- '8888:8888'
networks:
- hadoop-net
volumes:
namenode:
datanode:
datanode2:
datanode3:
还需要编写一个 hadoop 配置文件 config.env
# CORE-SITE.XML配置
# 设置默认的文件系统名称为HDFS,并指定namenode
CORE-SITE.XML_fs.default.name=hdfs://namenode
CORE-SITE.XML_fs.defaultFS=hdfs://namenode
# 设置静态用户为root
CORE-SITE.XML_hadoop.http.staticuser.user=root
# 指定Hadoop临时目录
CORE-SITE.XML_hadoop.tmp.dir=/tmp/hadoop-root
# HDFS-SITE.XML配置
# 设置namenode的RPC地址
HDFS-SITE.XML_dfs.namenode.rpc-address=namenode:8020
# 设置数据块的副本数量
HDFS-SITE.XML_dfs.replication=3
# MAPRED-SITE.XML配置
# 使用YARN作为MapReduce框架
MAPRED-SITE.XML_mapreduce.framework.name=yarn
# 配置MapReduce的环境变量
MAPRED-SITE.XML_yarn.app.mapreduce.am.env=HADOOP_MAPRED_HOME=${HADOOP_HOME}
MAPRED-SITE.XML_mapreduce.map.env=HADOOP_MAPRED_HOME=${HADOOP_HOME}
MAPRED-SITE.XML_mapreduce.reduce.env=HADOOP_MAPRED_HOME=${HADOOP_HOME}
# 设置MapReduce JobHistory的地址
MAPRED-SITE.XML_mapreduce.jobhistory.address=0.0.0.0:10020
MAPRED-SITE.XML_mapreduce.jobhistory.webapp.address=0.0.0.0:19888
# YARN-SITE.XML配置
# 设置ResourceManager的主机名
YARN-SITE.XML_yarn.resourcemanager.hostname=resourcemanager
# 启用NodeManager的物理内存检查
YARN-SITE.XML_yarn.nodemanager.pmem-check-enabled=true
# 设置NodeManager删除调试信息的延迟时间(秒)
YARN-SITE.XML_yarn.nodemanager.delete.debug-delay-sec=600
# 启用NodeManager的虚拟内存检查
YARN-SITE.XML_yarn.nodemanager.vmem-check-enabled=true
# 启用MapReduce Shuffle服务
YARN-SITE.XML_yarn.nodemanager.aux-services=mapreduce_shuffle
# 设置NodeManager的CPU核数
YARN-SITE.XML_yarn.nodemanager.resource.cpu-vcores=4
# 设置YARN应用程序的类路径
YARN-SITE.XML_yarn.application.classpath=opt/hadoop/etc/hadoop:/opt/hadoop/share/hadoop/common/lib/*:/opt/hadoop/share/hadoop/common/*:/opt/hadoop/share/hadoop/hdfs:/opt/hadoop/share/hadoop/hdfs/lib/*:/opt/hadoop/share/hadoop/hdfs/*:/opt/hadoop/share/hadoop/mapreduce/*:/opt/hadoop/share/hadoop/yarn:/opt/hadoop/share/hadoop/yarn/lib/*:/opt/hadoop/share/hadoop/yarn/*
# CAPACITY-SCHEDULER.XML配置
# 设置容量调度器的最大应用数量
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.maximum-applications=10000
# 设置容量调度器最大AM资源百分比
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.maximum-am-resource-percent=0.1
# 设置资源计算器
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.resource-calculator=org.apache.hadoop.yarn.util.resource.DefaultResourceCalculator
# 配置默认队列
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.root.queues=default
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.root.default.capacity=100
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.root.default.user-limit-factor=1
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.root.default.maximum-capacity=100
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.root.default.state=RUNNING
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.root.default.acl_submit_applications=*
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.root.default.acl_administer_queue=*
# 设置节点本地延迟
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.node-locality-delay=40
# 配置队列映射
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.queue-mappings=
CAPACITY-SCHEDULER.XML_yarn.scheduler.capacity.queue-mappings-override.enable=false
这是文件夹下的两个文件
然后运行 docker-compose -p project1 up -d
第一次运行需要拉取大概2个G的镜像,如果网络失败请自行搜索如何给 Docker Desktop 换源或者开不可描述的软件的 TUN 模式
等到出现下图则运行成功
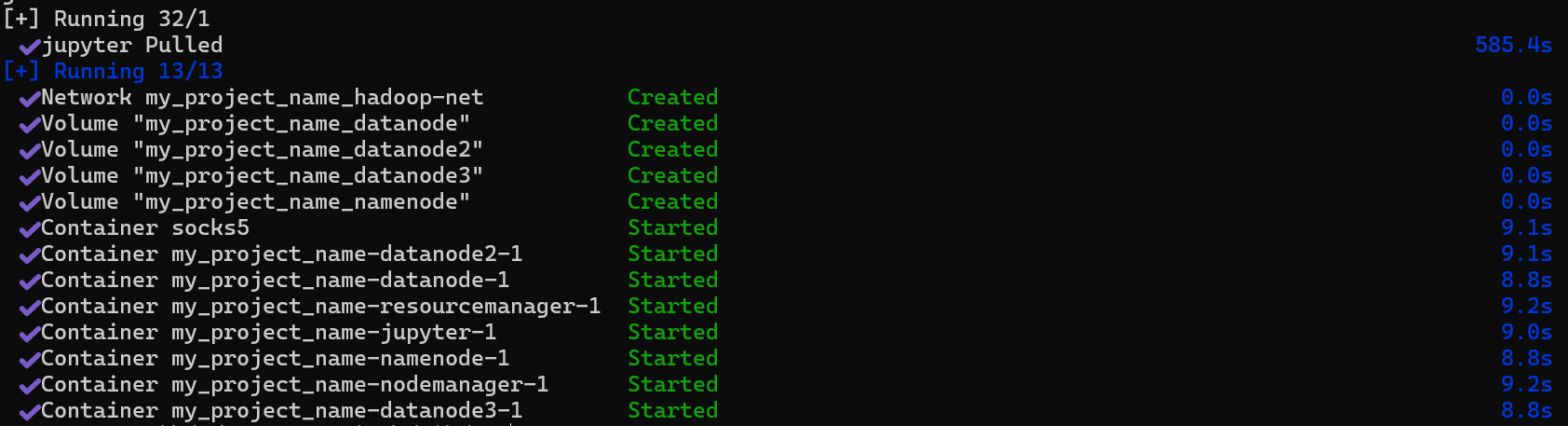
运行docker ps即可看到运行中的容器,如果缺少哪个容器了应该是端口号冲突导致,可以运行docker-compose logs查看日志并修改docker-compose.yml中的端口映射

第三步
浏览器打开127.0.0.1:8888,即可看到 Jupyter Web UI
第四步
打开 http://127.0.0.1:9870/ 即可看到 Hadoop 的 Namenode Web UI
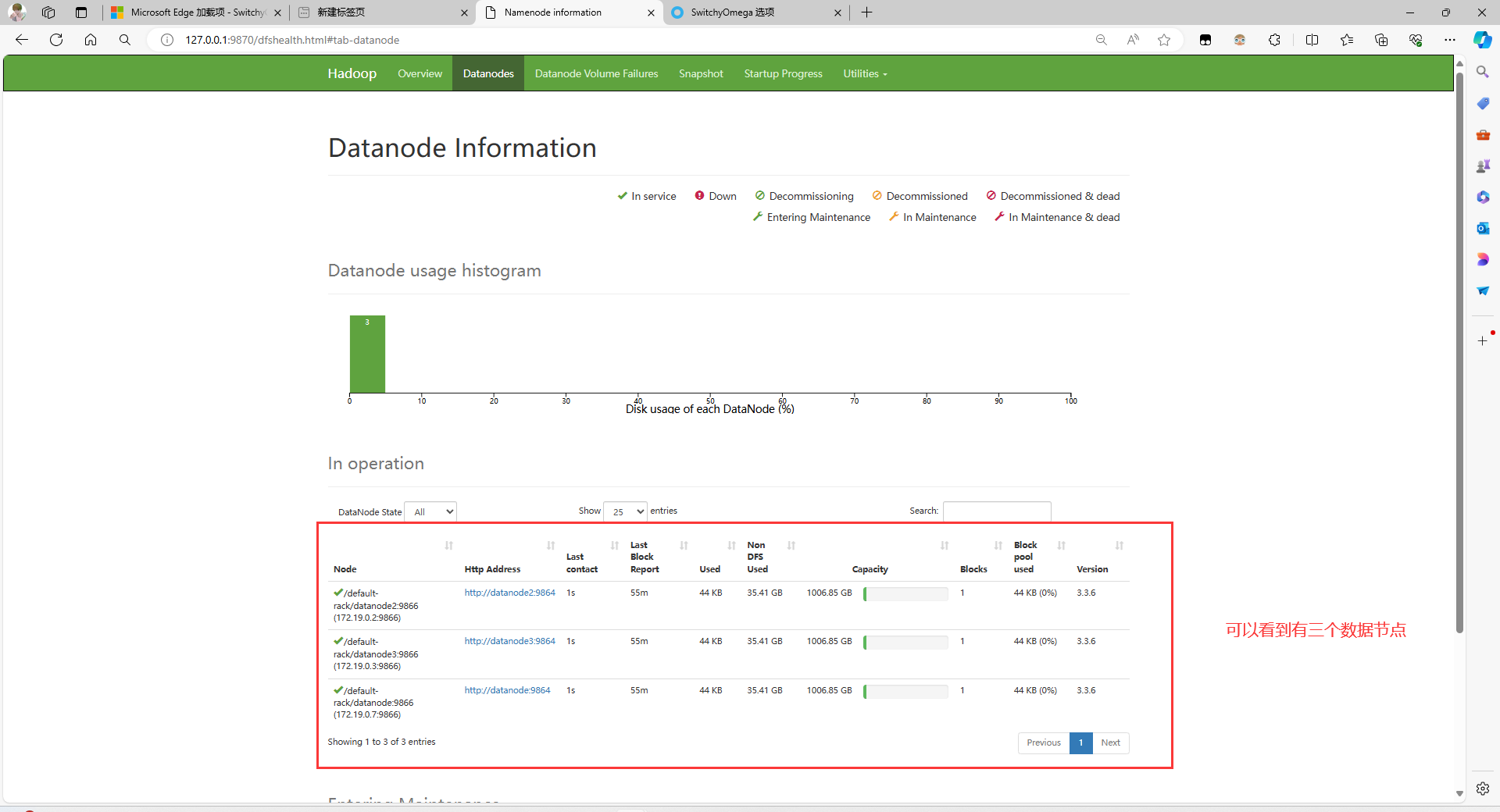
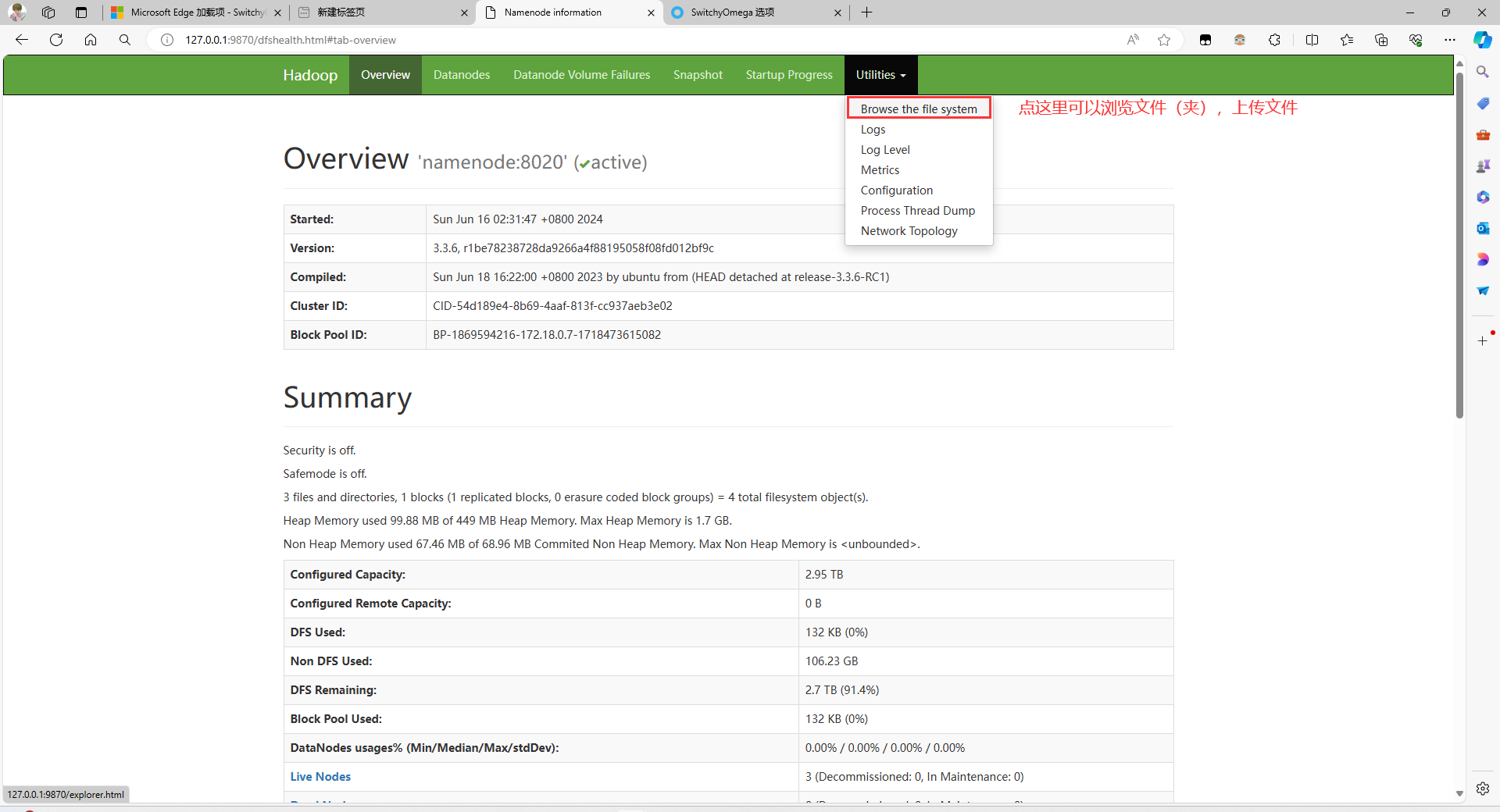
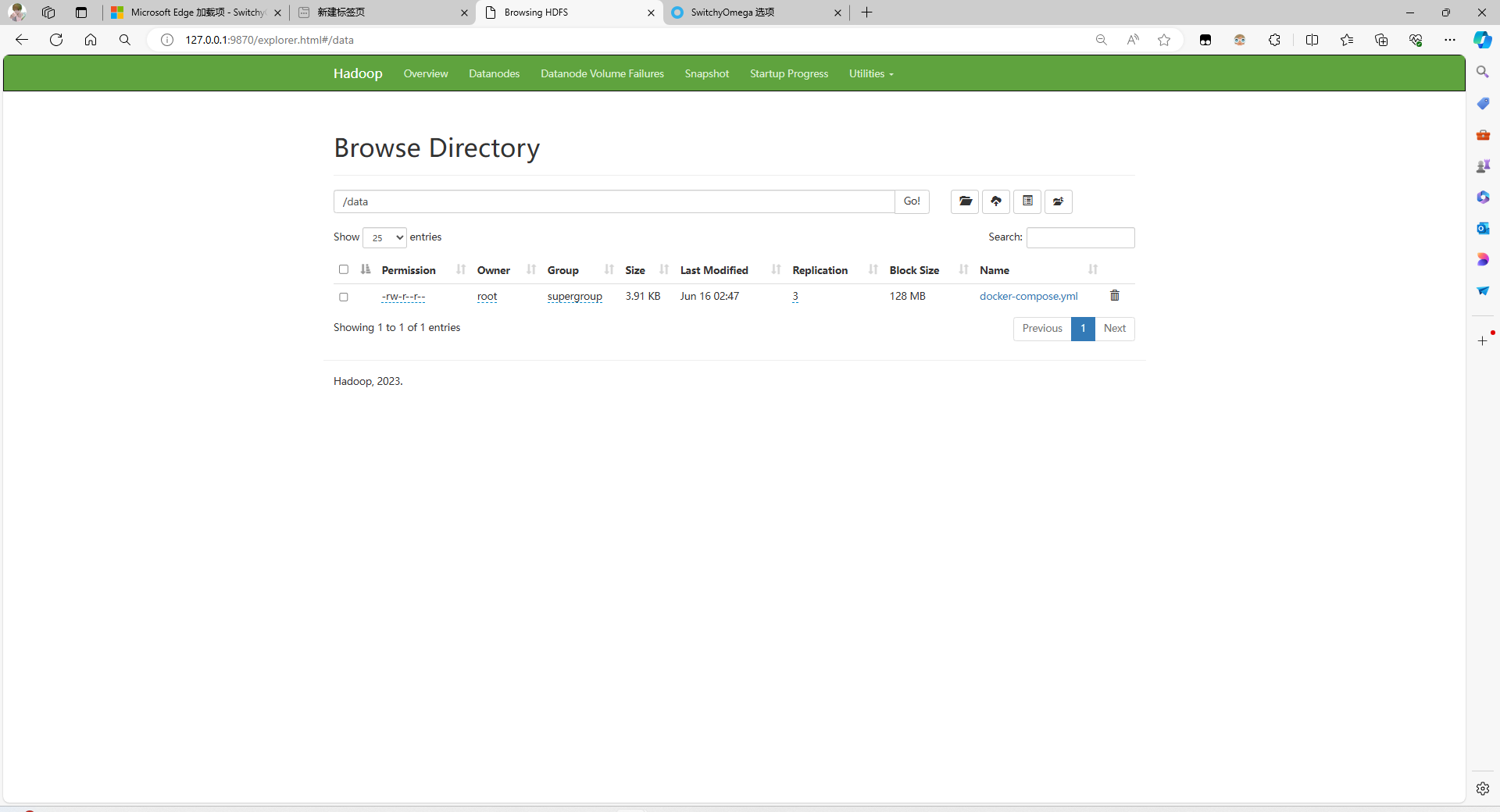
注意:如果想从这里上传文件,需要将浏览器的网络代理到刚刚创建的 socks5 代理容器里面,下面是 Edge 浏览器设置代理教程
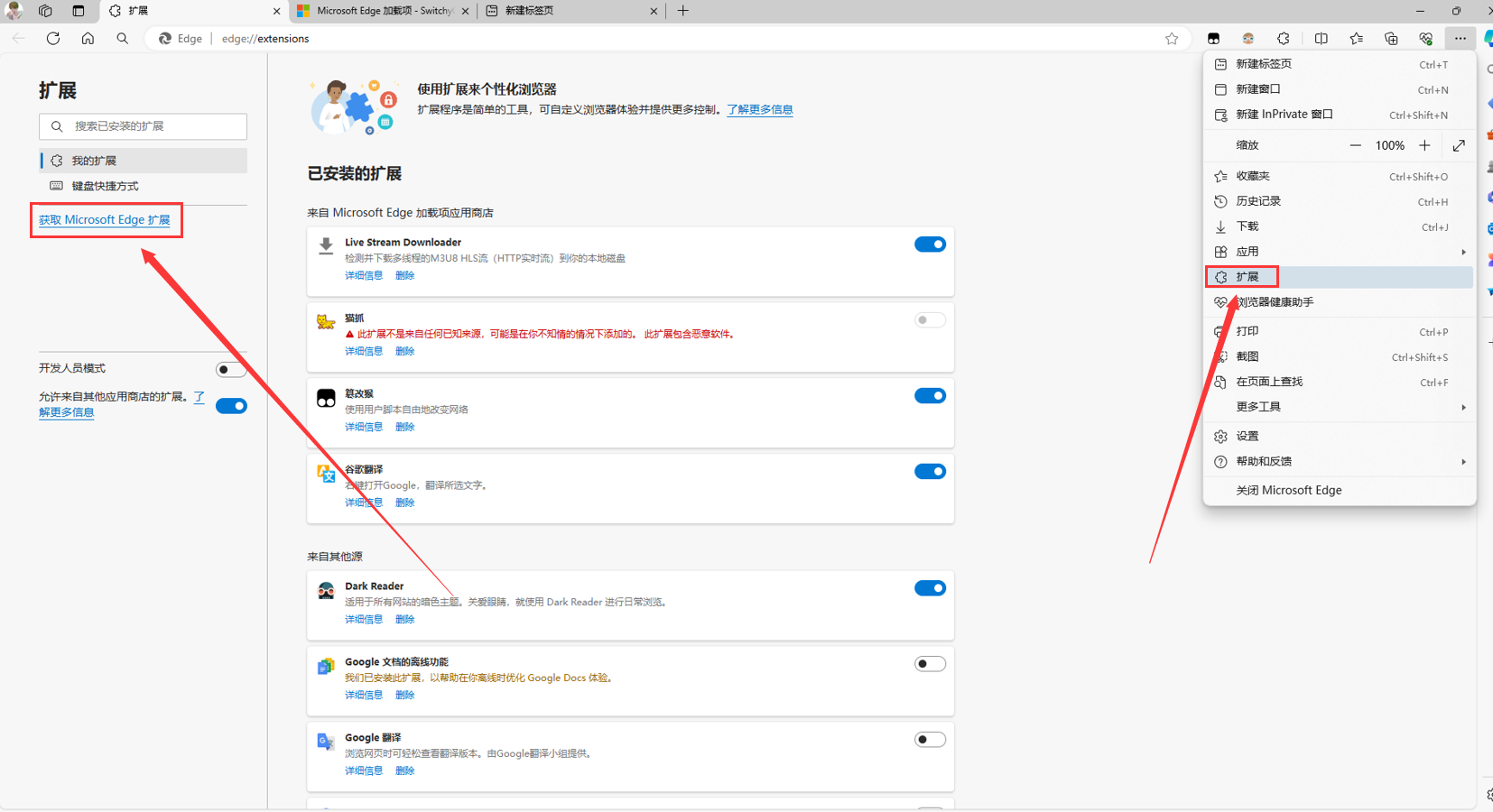
搜索SwitchyOmega并获取
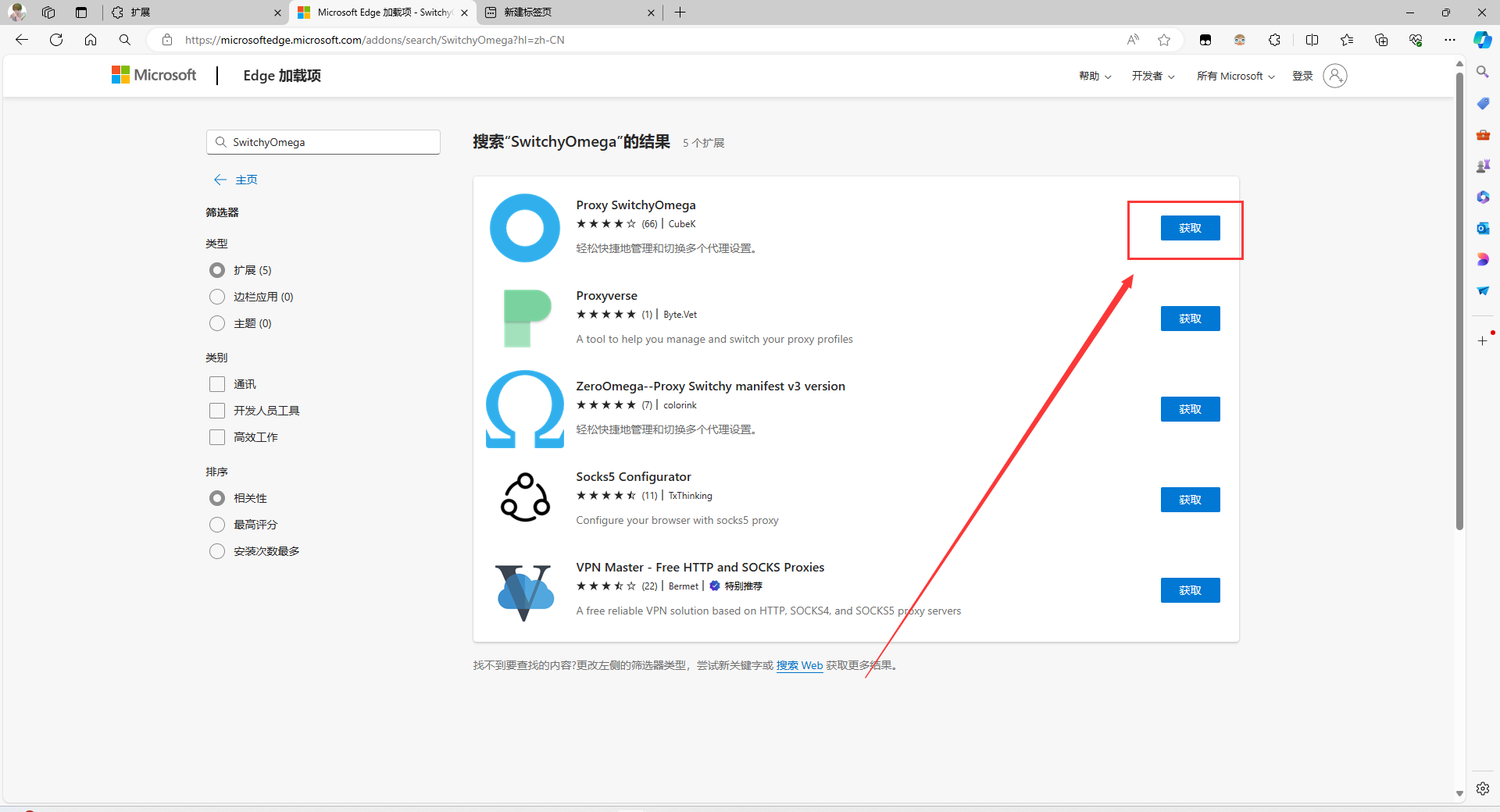
配置代理,协议为socks5,地址为本机127.0.0.1,端口为docker-compose.yml里面socks5服务映射的10802端口
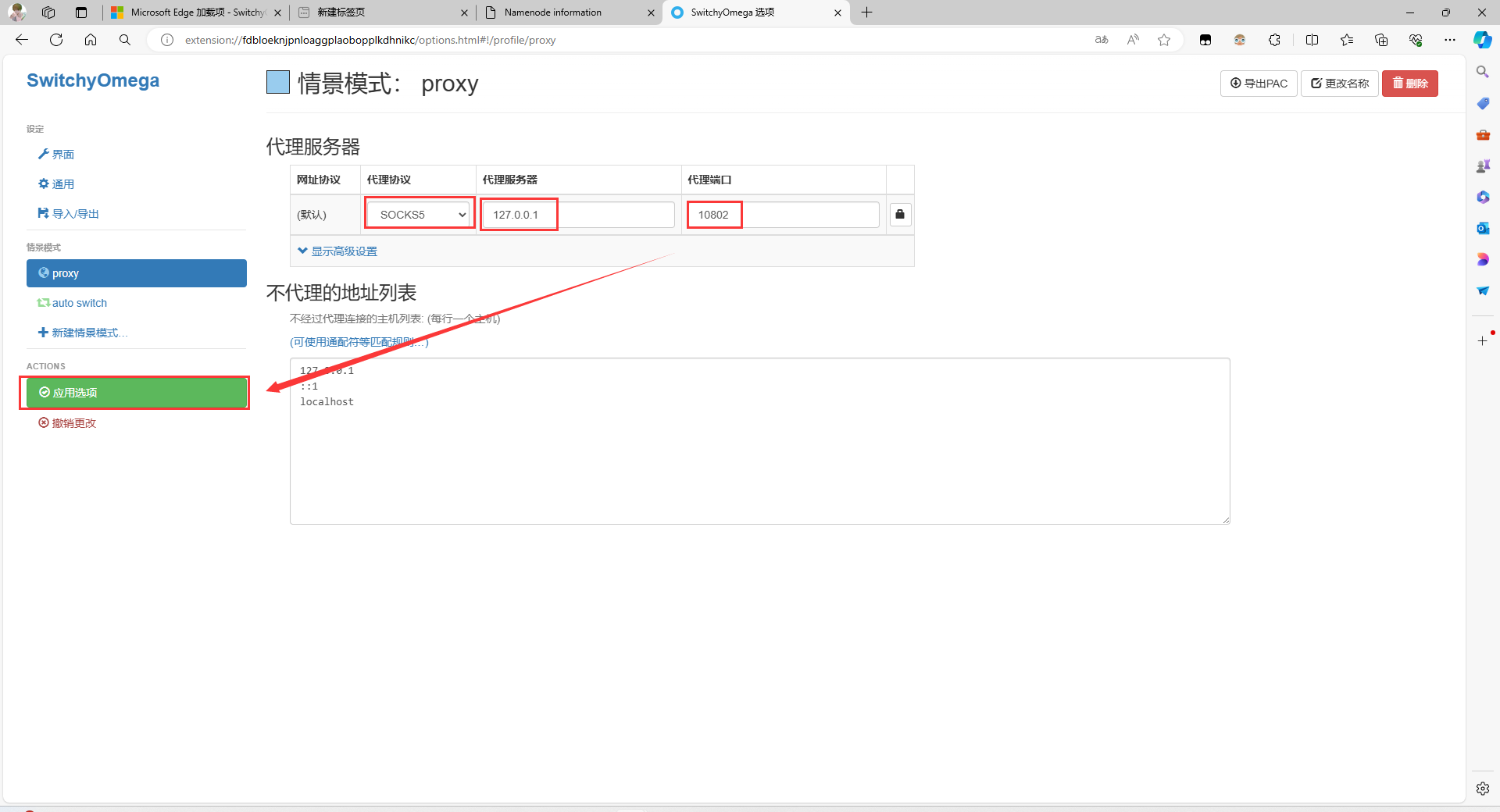
记得选择代理然后刷新网页

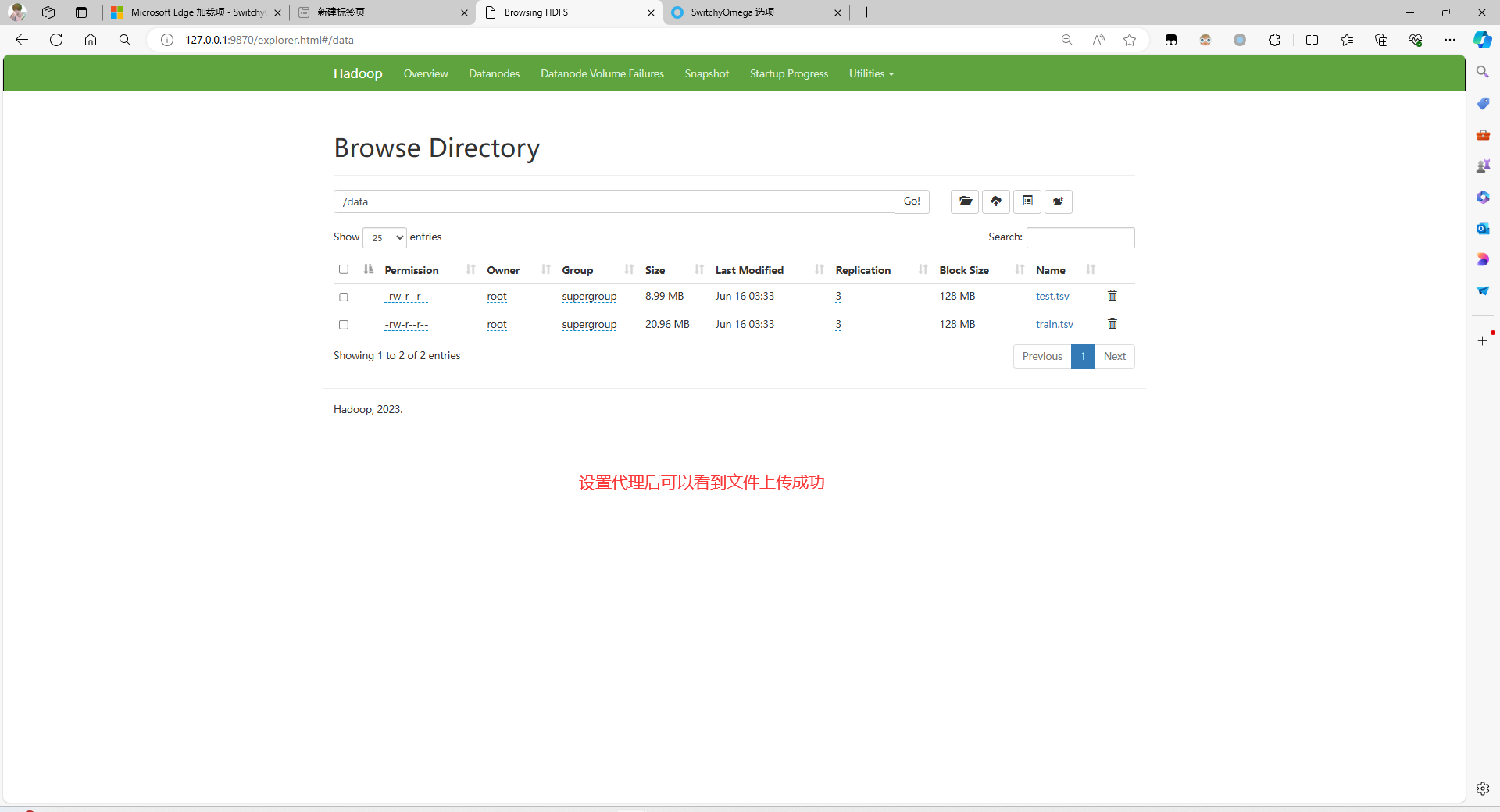
后续
在 Jupyter 中需要修改 HDFS 的 URL
hdfs://namenode/data/train.tsv,其中/data/train.tsv为 HDFS 里面的文件路径
from pyspark import SparkConf, SparkContext
from py4j.java_gateway import java_import
# 检查是否已经存在SparkContext实例
if 'sc' in globals():
sc.stop()
# 创建新的SparkContext实例
conf = SparkConf().setAppName("HDFSExample").setMaster("local")
sc = SparkContext(conf=conf)
# 导入必要的Java类
java_import(sc._gateway.jvm, "org.apache.hadoop.conf.Configuration")
java_import(sc._gateway.jvm, "org.apache.hadoop.fs.FileSystem")
java_import(sc._gateway.jvm, "org.apache.hadoop.fs.Path")
# 创建Hadoop配置对象
hadoop_conf = sc._gateway.jvm.Configuration()
hadoop_conf.set("fs.defaultFS", "hdfs://namenode")
hdfs = sc._gateway.jvm.FileSystem.get(hadoop_conf)
# 设置文件路径
file_path = "hdfs://namenode/data/train.tsv"
# 获取文件状态并读取文件大小
path = sc._gateway.jvm.Path(file_path)
file_status = hdfs.getFileStatus(path)
file_size = file_status.getLen()
print(f"File path: {file_path}")
print(f"File size: {file_size} bytes")