参考视频:
企业级数据中台功能演示_哔哩哔哩_bilibili
具体项目:
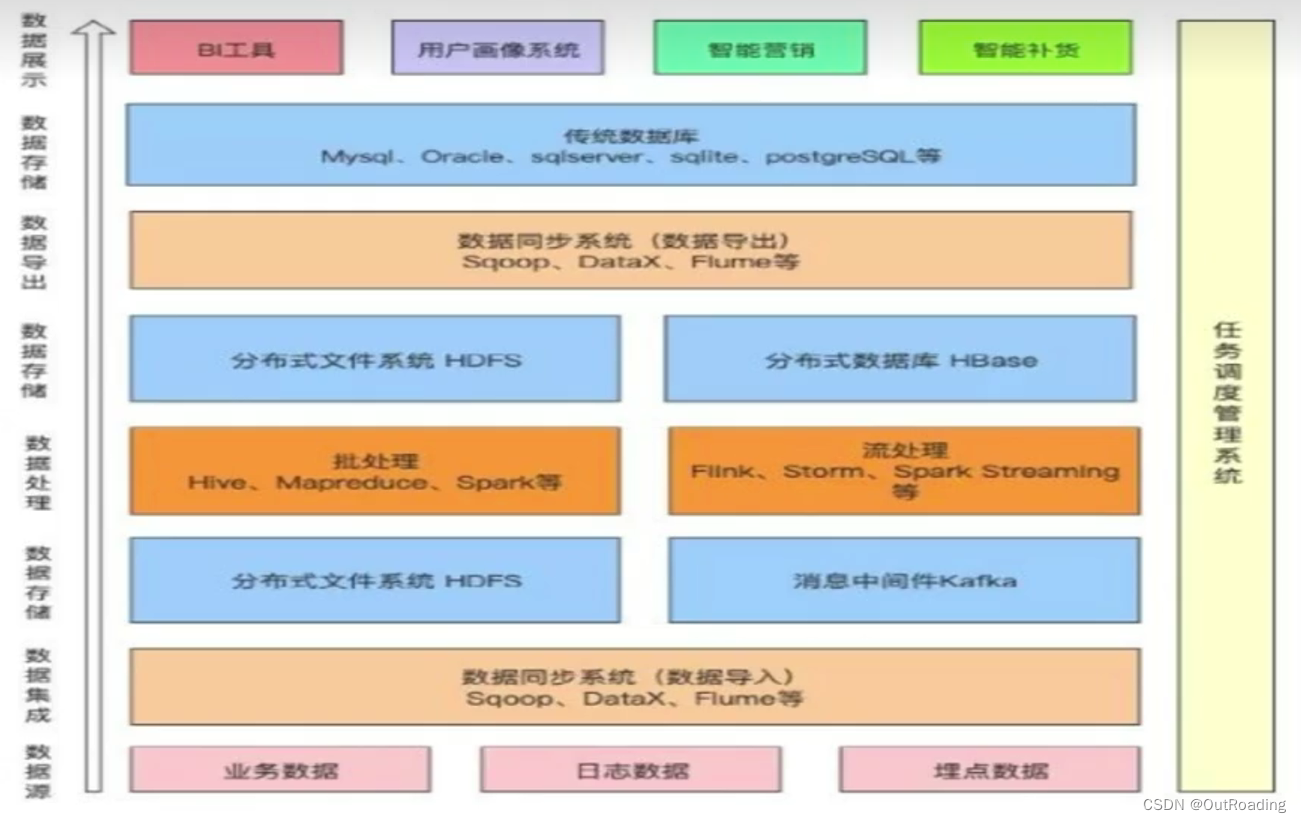
平台基础设施:
系统管理,系统监控(登录/操作日志),任务调度
元数据管理:
业务系统管理/数据源管理/数据表管理/字段管理
数据源,元数据,数据授权,变更记录,数据检索,数据地图,数据血缘,SQL工作台
数据标准管理:
标准字段,对照表,字典对照,对照统计
数据质量管理:
规则配置,问题统计,质量报告,定时任务,任务日志
数据集市管理:
数据服务,数据脱敏,接口日志,服务集成,服务日志
可视化管理:
数据集,图表配置,看板配置
预警
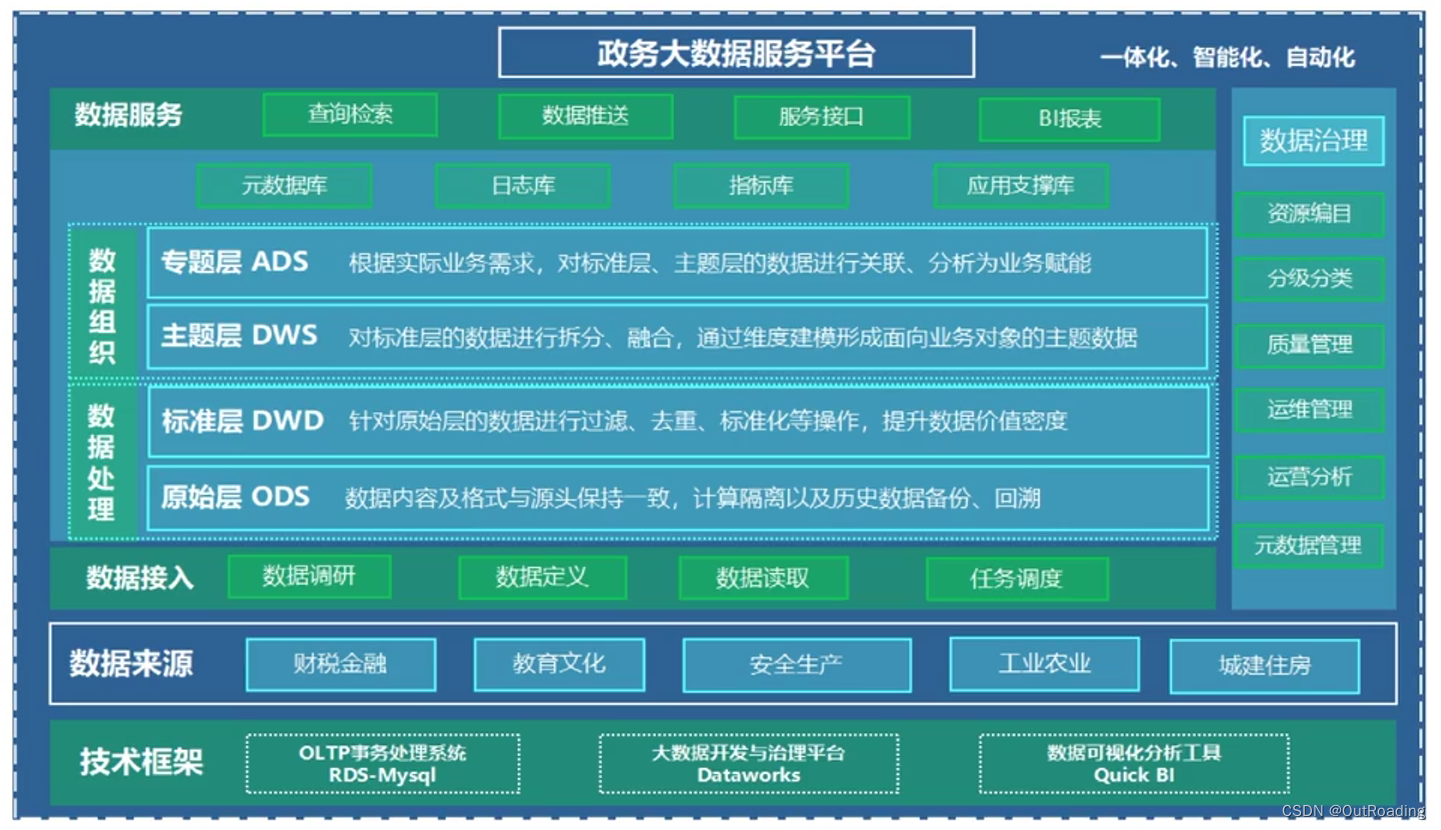
数据服务:
查询检索,比对订阅,模型分析,数据推送
质量管理:
数据处理:数据关联,数据比对,数据标识,数据分发
标准库DWD:数据精细化,标准化,规范化
问题库
数据清洗:数据过滤,数据去重,格式转换,内容校验
唯一性,完整性,准确性,一致性,关联性,及时性
问题统计
核查规则
质量报告
原始库(ODS):数据溯源,数据去重,格式转换,内容校验
元数据库
数据接入:数据探查,数据定义,数据读取,数据对账
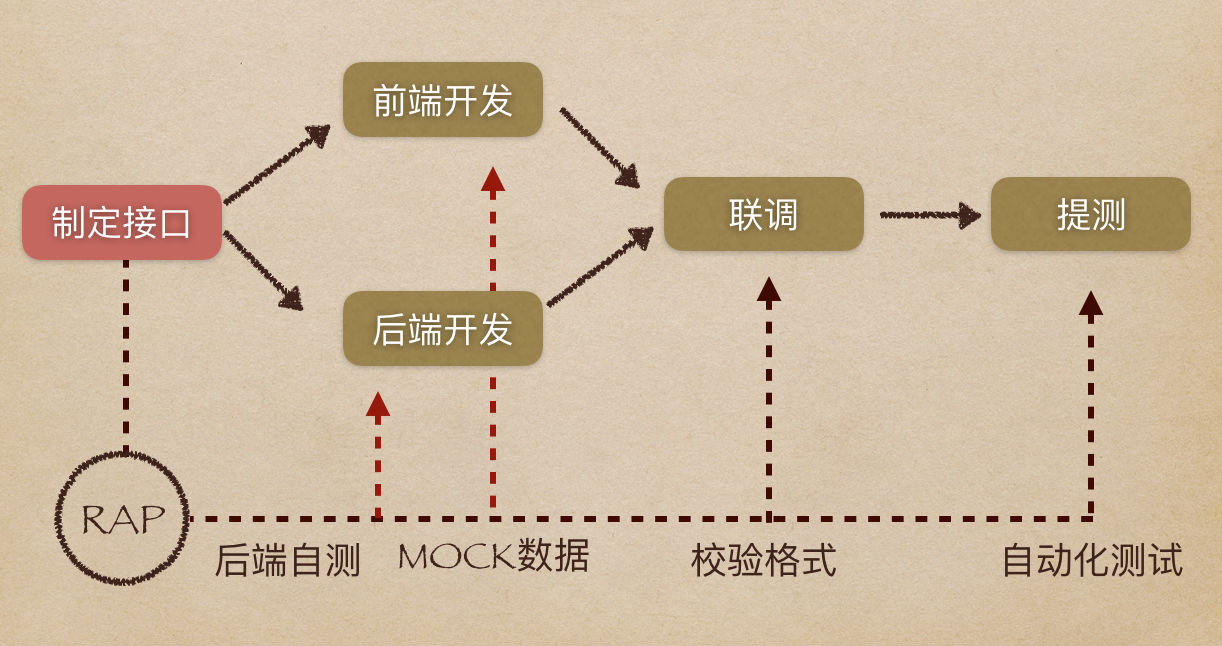
业务流程:任务信息-》源库选择-》目标库选择 -》映射配置 -》 调度规则 -》 确认
定时任务:
定时同步任务
每次定时任务执行日志
定时任务:制定规则,每天定时检查质量
监控质量的定时任务,运行的状态情况
数据集市:
库表转换成api接口,对外提供数据服务
1 提供全局管理,控制返回使用方的字段范围,可以 脱敏
内容:
API名称,版本,路径,请求方式,返回格式,IP黑名单,调用频率,发布,备注
接口日志:
每个接口的调用情况:成功/失败,调用数据量,ip,用户,时间
可视化服务集成:
库表里查询的数据,以图表形式,更直观展示给业务人员
数据集:
图表配置:
看板配置:
血缘管理:
业务库-》ods -》dwd -》dws
原始库(ODS):数据溯源,数据备份
标准库(DWD):数据精细化,标准化,规范化
主题库(DWS):eg:竞品分析,不同维度获取对应数据
专题库(APP):针对不同需求加工不同的专题表
数据接入:
任务信息-》源库选择-》目标库选择 -》映射配置 -》 调度规则 -》 确认
数据探查:
业务系统探查:
提供方信息:系统部门,名称,级别,上线时间,状态,业务联系人
数据源探查:
存储介质探查:
数据库类型(ORACLE,MYSQL,Redis,Hbase)
文件服务器类型(Kafka,FTP,HDFS)
访问方式探查:
ip,端口,用户名,账户,密码,存储路径,查询用户,字符集等
数据集探查(表):
基础信息探查: 表标识,表名
属性信息探查: 事实表,维度表,业务分类
规模信息探查: 总量,增量,存储大小,存储周期,更新频率,更新方式,
状态信息探查: 启用/停用状态
数据项探查(字段):
基础信息探查:标识,名称,类型,长度,精度
属性信息探查:字典项,标准数据,增量字段,逐渐字段,外键字段
问题信息探查:有效性,合规性,空置率
数据定义:
业务系统定义:
业务系统id,名称,部门,上下线时间,系统状态,联系人,电话
数据源定义:
数据源id,类型(01hive,02oracle),业务系统id,ip,端口,登录,密码
数据集定义:
对象id,对象标识,对象名称,类型(01表02视图)数据条数,存储大小,资源分类,更新频率(每日),更新方式(全表),业务系统id,数据源id,资源状态
数据项定义:
数据线id,数据对象id,数据线标识,数据线名称,数据线类型,长度,精度,空置率,是否代码项,关联表代码表,是否主键,是否增量字段
数据读取:
描述:维度表,事实表概念以及读取模式设计
业务表分类属性:
字典表:结构简单,规模小,更新变化频率低
事实表:描述某一事物的活动信息,数据规模,eg:账单表
维度表:描述事实表某一维度的特性,规模复杂,eg:商品维度,用户维护
同步策略和手段:
同步方式:
全量:
增量:
增量更新
增量追加
同步周期:
实时:mysql)binlog,(oracle)cdc,kafka,flink,sparkstreaming
分钟级实时:固定变量(T+1),数据偏移量
离线同步:小时,天周月等,固定变量(T+1),数据偏移量
其他信息:
公共字段,入库时间,更新时间,业务数据MD5
数据对账:
全量抽取的表不需要对账,所以增量数据要做对账
具体操作:增量同步业务数据的基础上,再全量同步对账表
对账表:业务表的主键,业务表的增量字段,业务表的全字段MD5值
数据量一致性分析:相同时间范围,比较主键值差异
数据内容一致性分析:相同范围、主键值,比较业务字段MD5值差异
数据处理:
描述:结构化,半结构化,非结构化数据区别
结构化:完整的结构规则,可以通过关系型数据库表形式进行存储
半结构化:又基本固定结构的模式,eg:日志文件,XML文档,JSON,Email
通过Kettle或者函数 转换成结构化数据存储
非结构化数据:无固定模式的数据,eg:PDF,WORD,PPT,图片,视频
机器学习,算法提取结构化数据
文本信息提取:
要素信息:姓名,身份证,电话,账户,地址
关键词摘要:
关系提取:人员关系
音频信息提取:
特征信息:声纹特征,语种特征
语音转文本:文本信息提取
视频图信息提取:
特征信息:人像信息,物品信息,场景信息,字幕信息
文本信息提取,音频信息提取
非结构化数据存储策略
非结构化数据提取范围
数据清洗:(ods->dwd)
数据过滤:
基于样本数据过滤:比如某个字段带test是测试数据
基于业务规则过滤:无效数据,针对业务情况
数据去重:
数据同步过程产生的全字段重复:
业务规则重复:
格式转换:
日期时间格式
全角转半角
大小写统一
经纬度统一
内容校验:
合规性校验:身份证合规性,电话号码,组织机构代码
一致性校验:属性一致性,关系一致性
其他校验:值域范围,数据格式,空值校验,准确性校验,完整性校验
数据标准化:(ODS->dwd)
和数据清洗的区别:
数据清洗:是对不合规数据的处理,问题数据反馈进行核实
数据标准化:各个系统建立统一标准,内容转化
标准化范围:
代码标准化:统一性别是1男2女
数据格式标准化:统一日期格式:yyyy-MM-dd
命名标准化:统一人员姓名:name
标准化工作场景及优化手段:(kettle,大部分都是这个基础上增加了资源调度,日志监控,权限管理等模块)
脚本开发模式 -》 产品开发模式 -》 元数据驱动模式
基于元数据管理推动大数据体系自动化建设:
标准数据元:
eg:标志符 标识代码 属性类别 类型 长度 精度 格式
性别 BZ00011 代码 String 2
标准数据里,加上标识代码列,标准值
数据治理:
元数据管理价值及建设目标(数据治理的最重要模块)
1 实现所有数据建设成果落地
数据库元数据:定义表的内容:表名称,描述,字段名称,类型,长度
数据同步策略
数据清洗规则
分级分类信息等
运维监控
质量规则
2 保障数据处理过程可管、可控、可查:
一般统一存储在:关系型数据库,体量核实,速度快,丰富的内置函数
业务流程经常更新:比如调整同步周期频率,任务执行计划更新的同时要更新元数据
比如筛选时间的元数据信息,查看是否做了格式校验
3 驱动数仓建设流程化、规范化、自动化
存在更新的情况,开发修改了数据,但忽略元数据的更新,影响统计指标
解决方案:
1 加强流程管理,必须把元数据维护起来,成本压力上来
2 监控脚本:业务数据和元数据进行监控,业务数据或跟元数据现在定义策略不一致时,及时发出通知
元数据模型设计:
建模过程:概念模型,逻辑模型,物理模型
分类标准:
技术元数据:
技术职称信息:存储信息,标识信息,类型信息,权限信息,索引信息等
业务元数据:
业务策略定义:更新频率,更新方式,业务分类,字段熟悉,业务规则等
操作元数据:
处理过程记录:访问日志,运行日志,申请记录,调用记录,监控日志等
模型范围:业务系统,
数据源:
访问方式:ip,端口,账户,密码,服务名,查询用户,接口调用方式,请求内容
数据源状态:试运行,上线,下线
所属系统:
提供形式:数据库等类型
数据集:
技术元数据:
资源标识,权限(只读,可更新)总条数,总大小,日增量
业务元数据:
资源id,名称,摘要,业务分类,表情信息,业务系统id数据源id,状态(试运行,上线,下线)
数据项:
业务元数据:
数据项id,数据项名称,字段属性(主键/外键/增量:关联外键表,字典字段:关联字段表,关联条件)
技术元数据:
字段标识,类型,长度,精度,空值率,值域分布
定期对元数据管理系统进行备份
元数据管理,不仅是源库表,还包括分层的每一个表
大数据常用的软件:
调度:
oozie,azkaban,海豚,quartz
同步:
离线抽取:
sqoop:: 在Hadoop(Hive)与关系数据库间相互进行数据的传递
datax: 各种异构数据源之间高效的数据同步功能
实时抽取:
flume: 日志存到hdfs
cancal:
基于数据库增量日志解析,提供增量数据实时订阅和消费,目前主要支持了MySQL
工作原理:伪装成MySQL slave,监听binlog日志
StreamSets:
拖拽式的可视化界面,实现数据管道(Pipelines)的设计和定时任务调度
数据源支持MySQL、Oracle等结构化和半/非结构化,目标源支持HDFS、Hive等
debezuim:
捕获变更数据(CDC)的开源工具
抽取 数据库日志 来变更的
构建在 Apach Kafka之上,并提供Kafka连接器来监视特定的数据库管理
清洗工具:
Kettle