💛前情提要💛
本文是传知代码平台中的相关前沿知识与技术的分享~
接下来我们即将进入一个全新的空间,对技术有一个全新的视角~
本文所涉及所有资源均在传知代码平台可获取
以下的内容一定会让你对AI 赋能时代有一个颠覆性的认识哦!!!
以下内容干货满满,跟上步伐吧~
📌导航小助手📌
- 💡本章重点
- 🍞一. 概述
- 🍞二. 核心逻辑
- 🍞三. 论文工作阐述
- 🍞四. 本文优化点
- 🍞五. 演示效果
- 🫓总结
💡本章重点
- 【算法】实体关系抽取
🍞一. 概述
实体关系抽取是自然语言处理领域的一个常见任务,它常常和实体识别任务伴生,他们都属于图谱三元组的提取任务。实体识别任务提取出实体,实体关系抽取任务则是负责判断两个实体之间的关系。
例如:
在句子"Albert Einstein was born in Ulm"中,实体识别任务会识别出"Albert Einstein"和"Ulm"两个实体,而实体关系抽取任务则会判断这两个实体之间的关系是“出生地”(place of birth)。

🍞二. 核心逻辑
本文对于实体关系抽取任务的实现基于论文 Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification,并做出一定的优化。
🍞三. 论文工作阐述
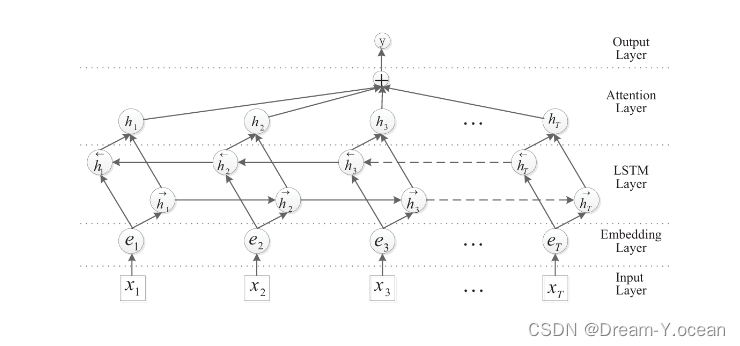
论文中的实体识别模型采用了BERT、BILSTM和注意力机制的结合结构。具体来说,BERT提供了强大的文本表示能力,能够生成丰富的上下文感知词向量。通过预训练的BERT模型,输入的文本可以被转化为高质量的向量表示,捕捉到词语的语义和句法信息。
在BERT生成的词向量基础上,加入了BILSTM层。BILSTM是LSTM(长短期记忆网络)的双向版本,它能够同时考虑前向和后向的上下文信息,进一步增强了对句子结构的理解能力。BILSTM的引入使得模型能够更好地捕捉到句子中每个词语的前后依赖关系,从而提升对复杂语言现象的建模能力。
为了进一步提高模型的性能,还加入了注意力机制。注意力机制通过赋予不同词语不同的权重,帮助模型集中关注对实体识别任务至关重要的词语和特征。这种机制能够动态地调整每个词语的权重,使得模型在处理长文本时,仍然能够高效地捕捉到关键的信息。
🍞四. 本文优化点
实体向量嵌入方式的优化
对于实体关系抽取任务,一般而言,输入包含需要判断的句子和两个实体,常见的嵌入方式是计算两个实体在句子中的位置向量,来标注实体。然而,仅仅根据两个词来进行关系识别,可能导致模型很难深入理解句意,难以理解隐藏在句子中的实体关系。
依存解析器通过Stanford CoreNLP的依存解析算法,对输入句子进行依存关系分析。依存关系解析将句子看作一个图,词语作为节点,词语之间的依存关系则作为节点之间的连接关系。
在解析器的基础上,生成依存矩阵。该矩阵表示句子中词语之间的依存关系。矩阵的每个元素对应于句子中两个词语之间的依存连接强度或类型。
将生成的依存矩阵结合到输入的句子中,使用图神经网络(Graph Neural Networks, GNNs)对句子进行处理。GNNs能够有效地利用依存关系信息,优化实体向量的嵌入方式。通过将句子建模为一个图,GNNs可以在节点(词语)之间传播信息,从而捕捉到更丰富的语义和上下文特征。
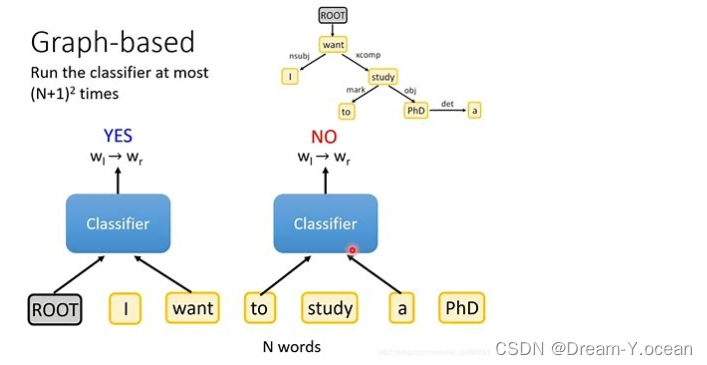
这种方法显著优化了实体向量的嵌入方式,使得模型不仅能够关注两个实体本身,还能够充分理解它们在句子中的上下文和依存关系。这种深层次的语义理解,能够大幅提高实体关系抽取任务的准确性和鲁棒性。
下面的代码展示了修改后的嵌入模型:模型先经过BERT编码,然后结合依存矩阵,输入到图神经网络中,得到可用来训练的向量
def forward(self, sentence,label1,label2):
# Step 1: BERT Encoding
bert_outputs = self.encode_sentence(sentence)
print(len(bert_outputs[0]))
bert_outputs_label1,bert_outputs_label2 = self.encode_sentence_and_label(sentence,label1,label2)
# Step 2: Dependency Parsing
dependency_matrix = self.word_parse_dependency(sentence,len(bert_outputs[0]))
# Step 3: GAT Encoding
bert_outputs = bert_outputs[0] # .numpy()
x = self.gat(bert_outputs, adj_matrix_tensor)
output_ids = torch.cat((bert_outputs_label1[0], x,bert_outputs_label2[0]), dim=1)
return output_ids
实体识别层模型的优化
在论文的基础上,将注意力层优化成为池化注意力机制层,另外根据两个实体在句子的位置,将句子划分为五个部分,分别进行池化操作,让模型学习实体在句子中的相关特征。
例如,池化操作可以采用最大池化或平均池化的方法,聚合注意力权重,从而增强模型对重要特征的识别能力。
预处理代码如下:根据两个实体在句子的位置,将句子划分为五个部分,分别进行池化操作,让模型学习实体在句子中的相关特征
def forward(self, entity1, entity2, left, middle, right):
entity1 = self.calc_pool(entity1)
entity2 = self.calc_pool(entity2)
left = self.calc_pool(left)
middle = self.calc_pool(middle)
right = self.calc_pool(right)
if left is None:
T = torch.cat((entity1, middle, entity2, right), dim=1)
elif middle is None:
T = torch.cat((left, entity1, entity2, right), dim=1)
elif right is None:
T = torch.cat((left, entity1, middle, entity2), dim=1)
else:
T = torch.cat((left, entity1, middle, entity2, right), dim=1)
T = torch.mean(T, dim=0)
T = T.unsqueeze(0)
y = self.fc(T)
相关学习率调整算法
使用了Adam优化算法,这是目前深度学习中非常流行的一种优化算法。定义了一个学习率调度器。具体来说,它使用了基于指标变化调整学习率的调度器。
通过结合优化器和学习率调度器,能够在训练过程中动态调整学习率,提高模型的训练效率和效果。优化器负责更新模型参数,而调度器根据模型性能自动调整学习率,以便在训练后期进行更精细的优化。
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate, weight_decay=1e-5)
scheduler = ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=3, verbose=True)
🍞五. 演示效果
本项目分别在3种关系类别和22种关系类别进行测试,实验结果表明,类别越多模型的性能会有所下降,这可能是受到预训练模型本身的限制
Epoch 5/15, Training Loss: 219.9698, Training Accuracy: 0.9237
total time: 816.9306426048279
Epoch 5/15, Validation Loss: 0.0611, Validation Accuracy: 0.8360
训练之后,代码会自动保存最好的模型,调用模型,可以利用模型来预测一句话的种两个实体之间的关系,下面是一个演示结果:
输入句子
text = "据报道,东方航空股临时停牌传将与上航合并"
entity1= "东方航空"
entity2="上航"
输出类别
合并
🫓总结
综上,我们基本了解了“一项全新的技术啦” 🍭 ~~
恭喜你的内功又双叒叕得到了提高!!!
感谢你们的阅读😆
后续还会继续更新💓,欢迎持续关注📌哟~
💫如果有错误❌,欢迎指正呀💫
✨如果觉得收获满满,可以点点赞👍支持一下哟~✨
【传知科技 – 了解更多新知识】



![[大模型]XVERSE-7B-chat WebDemo 部署](https://img-blog.csdnimg.cn/direct/6217e32fe0a64f2c9a95361ec720c3c3.png#pic_center)