- 导入maven依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
<exclusions>
<exclusion>
<groupId>org.junit.vintage</groupId>
<artifactId>junit-vintage-engine</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.shardingsphere/shardingsphere-jdbc-core-spring-boot-starter -->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.1.1</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.11</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.1.1</version>
</dependency>
- 构建自己的数据库表,这里我随便弄了两个表
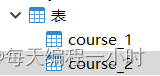
表中的字段是这样子的
- 不分库但是分表的yml配置
spring:
application:
name: shardingdemo
shardingsphere:
datasource:
names: master
master:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://xxxxx:3306/xxxx?useUnicode=true&characterEncoding=utf8&verifyServerCertificate=false&useSSL=true
username: xxxx
password: xxxx
# 配置虚拟表映射
sharding:
tables:
course:
actualDataNodes: master.course_$->{1..2}
tableStrategy:
inline:
shardingColumn: id
algorithmExpression: course_$->{id%2+1}
keyGenerator:
column: id
type: SNOWFLAKE
props:
worker:
id: 1
props:
sql.show: true
这个yml文件的意思是只进行分表,但是不进行分库,course总共有两张表,在插入的时候,对id字段进行雪花赋值,然后进行 id%+1的算法,得出插入哪张course