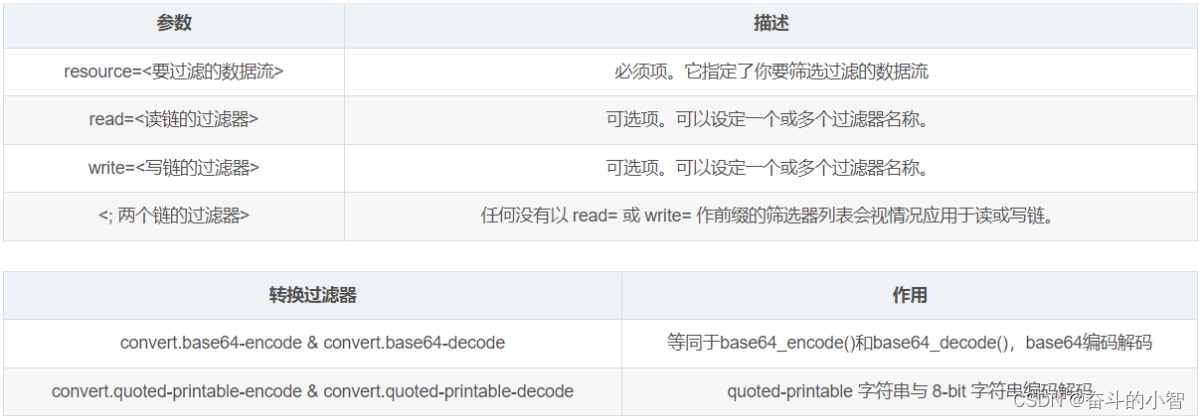
文章目录
- 生成式网络 - 生成合成图像
- 算法一:编码器-解码器
- 算法二:自编码器(Auto-Encoder,AE)
- 算法三:变分自编码器(Variational Auto Encoder,VAE)
- 算法四:生成式对抗网络(Generative Adversarial Nets,GAN)
- (十四)实战:基于VAE变分自编码器生成图像(数据集:MNIST)
- (十五)实战:基于GAN生成式对抗网络生成图像(数据集:MNIST)
生成式网络 - 生成合成图像
概念区分:
判别模型:利用训练样本图像训练模型,然后对新样本图像进行预测。
生成模型:根据一些规则,在原图像的基础上,生成新图像。
算法一:编码器-解码器
编码器解码器在不同领域的应用(图形化)
(1.1)通俗理解
假设你有一本菜谱,这本菜谱有很多章节,每个章节都是文字描写如何烹饪不同的菜。现在我们将所有文字输入到网络中,对于网络来说,其接收到的只是文字信息,它并不知道这本菜谱的构成。Encoder使得网络能理解这本菜谱的结构,对其中的内容进行抽象,形成一些高阶的信息(如:描述做了什么菜),并将这些信息对应到一个简化的空间里。Decoder对这些简化的高阶信息进行理解,对相同语义相近的文字进行分类,并对应到具体的菜式上面(比如:凉菜,面食,鱼,肉等)。
备注0:可以彼此独立使用,但一起使用性能表现良好。
备注1:CNN编码器与RNN解码器可以混合搭配使用,反之亦然;可以根据给定任务任意组合。
备注2:编码器和解码器可以由好多个编码器解码器组成,即由多层组成。
备注3:编码器可以是各种网络。如:线性网络,CNN,RNN,Transformer;
备注4:解码器与编码器可以是相同的网络,也可以是不同的网络。
(1.2)编码器解码器架构
- 编码器处理输入
- 解码器生成输出
当RNN是多层时,解码器每一个时间步的输入是编码器最后一个时间步的输出与解码器上一时间输出的合并。编码器-解码器(seq2seq)

(CNN/RNN)Encoder编码器、Decoder解码器
(CNN/RNN)什么是编码器、解码器?
(1.2.1)CNN架构定义
在CNN中,编码器 - 解码器网络通常看起来像这样(CNN编码器和CNN解码器),这是执行图像的语义分割的网络。
网络的左半部分Encoder将原始图像的像素映射到特征向量集合的高阶信息(如:汽车,马路,行人)。
网络的右半部分Decoder基于高阶信息,最后生成一张分割图像。并将输出一一映射回"原始"格式(在本例中为图像像素)。
- 编码器:将输入编程成中间表达特征。
- 解码器:将中间表示特征解码成输出。
如图所示:Encoder和Decoder中都存在卷积层,但作用不同。
Encoder阶段(卷积层主要用于提取特征):卷积层获取图像的局部信息,然后输入2x2最大池化层,最后输入到下一层卷积。
Decoder阶段(卷积层主要用于补全特征):将特征图进行上采样,然后交给卷积层进行处理。由于上采样后的2x2区域只有一个前一层传来的1x1特征点,其余区域都是空值,因此这些空值需要被填补成适当的特征值,来让这个区域变得完整并且平滑。这个工作就是由卷基层担任的。

(1.2.2)RNN架构定义
在RNN中,编码器 - 解码器网络通常看起来像这样(RNN编码器和RNN解码器),这是预测传入电子邮件响应的网络。
网络的左半部分Encoder将电子邮件编码为特征向量。
网络的右半部分Decoder对特征向量进行解码,最后生成字预测。
- 编码器:将文本表示成向量。
- 解码器:将向量表示成输出。

算法二:自编码器(Auto-Encoder,AE)
自动编码器是一种特殊的神经网络,用于特征提取和数据降维。
组成:最简单的自动编码器由一个输入层,一个隐含层,一个输出层组成。
隐含层的映射充当编码器。训练时编码器对输入向量进行映射,得到编码后的向量;
输出层的映射充当解码器。训练时解码器对编码向量进行映射,得到重构后的向量。
训练:编码器和解码器(神经网络)同时训练模型,使得重构向量与输入向量之间的误差最小。因此样本X的标签值就是样本自身。
预测:训练完成之后,在预测时只使用编码器而不再需要解码器,将编码器的输出结果进行分类,回归等任务。


算法三:变分自编码器(Variational Auto Encoder,VAE)
VAE的设计原理+损失函数推导
题目:假设有两张训练图像:全月图、半月图。经过训练后,自编码器模型已经能够无损地还原这两张图像。
问题:然而当我们想要生成一张清晰的且类似于3/4全月的图像时,结果确是模糊且无法辨认的乱码图。原因是由于深度神经网络DNN是非线性的变换过程,所以在点与点之间的迁移是没有规律的。
解决方法:**变分自编码器(VAE)**引入噪声,使得图像的编码区域扩大,从而可以有效地覆盖失真区域。在训练过程中,解码器会尽可能还原与原图相似的图像,又会针对噪声的失真点区域使其尽可能同时与全月图、半月图相似。
优点:该方法将参与训练的所有图像的编码方式由离散(图像之间特征相互独立)变为连续(图像之间特征有所关联)。
背景:由于自编码器的潜在变量Z都是从原始图像中产生,导致无法产生新的内容(如:3/4全月的图像)。
创新:VAE对自编码器的潜在变量Z增加正态分布约束(如:噪声);并通过(编码器)神经网络确定参数:均值(原图)和标准差(噪声)。使得可以生成清晰的原图像的同时,生成合成图像。
理论模型:对于生成模型而言,主流的理论模型分为隐马尔科夫模型HMM、朴素贝叶斯模型NB和高斯混合模型GMM。VAE基于高斯混合模型,即任何一个数据的分布,都可以看做是若干高斯分布的叠加。理论证明:当拆分的数量达到512时,其叠加的分布与原始分布的误差非常非常小,此时可以认为两者等同。
前向传播:
(1)将输入样本X通过编码器(神经网络)输出:mu、log_var(相当于均值和方差)
(2)在标准正态分布N(0,1)中,随机采样一个ε,通过ε完成对潜在空间Z的约束。
(3)带入Z计算公式:Z = mu + ε * exp(log_var)。
(4)Z通过解码器生成输出样本X~。
反向传播的损失函数由下面两个度量的和构成:
(1)生成的新图像与原图像的相似度(采用交叉熵损失函数。如:nn.BCELoss)
(2)隐含空间的分布与正态分布的相似度(采用KL散度:Kullback-Leibler divergence)


算法四:生成式对抗网络(Generative Adversarial Nets,GAN)
生成对抗网络(GAN)是一种无监督机器学习算法。
背景:VAE利用潜在空间,能够捕捉到图像的结构变化(倾斜角度、形态变化、表情变化等),可以生成连续的新图像。但训练的损失函数采用均方误差MSE之类的粗略误差衡量,导致生成的图像较为模糊。
优缺点:GAN生成的图像效果优于VAE,但更难训练。 原因:生成器和判别器之间需要很好的同步,但是在实际训练中判别器很容易收敛,而使得传递给生成器的信息变少,导致生成器无法训练自己的损失。
直观理解:伪造者与技术鉴赏者的故事。(1)一个名画伪造者想要伪造一副达芬奇的画作。开始时,伪造者技术不精,但他将自己的一些赝品和达芬奇的真品混在一起,请一个艺术商人对每一幅画进行真实性评估,并向伪造者反馈。告诉他哪些看起来像真迹、哪些看起来不像真迹。(2)伪造者根据这些反馈,改进自己的赝品。随着时间的推移,伪造者技能越来越高,艺术商人也变得越来越擅长找出赝品。最后,他们手上都拥有了一些可以假以乱真的赝品。
> 网络组成:
(1)生成器(Generator)网络:将潜在空间的随机向量作为输入,并将其解码为一张合成图像。最终目的是使生成的合成图像骗过判别器。
(2)判别器(Discriminator)网络:将图像(真实图像或合成图像)作为输入,并预测该图像是真实的还是合成的。最终目的是找出生成器合成的假图像。
对抗网络:生成网络不断优化自己生成的数据让判别网络判断不出来,判别网络也要不断优化自己让自己判断得更准确。二者关系形成对抗,因此叫对抗网络。
GAN如何提升判别器的明辨是非能力?如何使生成的图像越来越逼近真实图像?
核心:生成器与判别器的损失函数
######################################################################
# 11、定义判断器对【真图片】的损失函数
outputs = D(images) # 前向传播(判别器)
d_loss_real = criterion(outputs, real_labels) # 判别器的损失loss
real_score = outputs
# 22、定义判别器对【假图片】的损失函数
z = torch.randn(batch_size, latent_size).to(device)
fake_images = G(z) # 前向传播(生成器)
outputs = D(fake_images) # 前向传播(判别器)
d_loss_fake = criterion(outputs, fake_labels) # 判别器的损失loss
fake_score = outputs
# 33、判别器的总损失loss
d_loss = d_loss_real + d_loss_fake
######################################################################
# 定义生成器对假图片的损失函数。
z = torch.randn(batch_size, latent_size).to(device)
fake_images = G(z) # 前向传播(生成器)
outputs = D(fake_images) # 前向传播(判别器)
g_loss = criterion(outputs, real_labels) # 生成器的损失loss
# 要求判别器生成的图片越来越像真图片,故损失函数中的标签改为真图片的标签,即希望生成的假图片,越来越靠近真图片。
######################################################################
10大典型的GAN算法 + GAN 的13种实际应用
GAN 的变种 :DCGAN、CGAN、CycleGAN、CoGAN、ProGAN、WGAN、SAGAN、BigGAN
GAN 的13种实际应用
(1)生成图像数据集。人工智能的训练是需要大量的数据集的,如果全部靠人工收集和标注,成本是很高的。GAN 可以自动的生成一些数据集,提供低成本的训练数据。
(2)生成人脸照片
(3)漫画人物
(4)自动生成人体模特 - 并且使用新的姿势
(5)给出多个不同角度的2D图像 - 自动生成3D模型
(6)图像到图像的转换
(7)文字到图像的转换
(8)语意 – 图像 – 照片 的转换
(9)根据人脸自动生成对应的表情
(10)可以生成特定的照片,例如:更换头发颜色、更改面部表情、甚至是改变性别。
(11)预测不同年龄阶段,你会长成什么样。
(12)提高图像分辨率。
(13)修复图像缺失区域。
(十四)实战:基于VAE变分自编码器生成图像(数据集:MNIST)
链接:https://pan.baidu.com/s/1X62pFmLRx7LDKwxG624KgA?pwd=5zf0
提取码:5zf0

import os
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
from torchvision import transforms
from torchvision.utils import save_image
import matplotlib.pyplot as plt
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True' # "OMP: Error #15: Initializing libiomp5md.dll"
#################################################################
class VAE(nn.Module):
"""VAE模型"""
def __init__(self, image_size=784, h_dim=400, z_dim=20):
super(VAE, self).__init__()
self.fc1 = nn.Linear(image_size, h_dim)
self.fc2 = nn.Linear(h_dim, z_dim)
self.fc3 = nn.Linear(h_dim, z_dim)
self.fc4 = nn.Linear(z_dim, h_dim)
self.fc5 = nn.Linear(h_dim, image_size)
def encode(self, x):
"""Encoder编码器"""
h = F.relu(self.fc1(x))
return self.fc2(h), self.fc3(h)
def reparameterize(self, mu, log_var):
"""标准正态分布约束"""
std = torch.exp(log_var / 2)
# 从N(0,1)中随机采样
eps = torch.randn_like(std)
return mu + eps * std
def decode(self, z):
"""Decoder编码器"""
h = F.relu(self.fc4(z))
return F.sigmoid(self.fc5(h))
def forward(self, x):
"""前向传播"""
mu, log_var = self.encode(x)
z = self.reparameterize(mu, log_var)
x_reconst = self.decode(z)
return x_reconst, mu, log_var
#################################################################
# (1)超参数定义
image_size = 784
h_dim = 400
z_dim = 20
num_epochs = 30
batch_size = 128
learning_rate = 0.001
#################################################################
# (2)数据加载
# 在当前目录,若不存在则新建文件夹:ave_samples(用于存储解码器生成的图像)
sample_dir = 'ave_samples'
if not os.path.exists(sample_dir):
os.makedirs(sample_dir)
dataset = torchvision.datasets.MNIST(root='data', train=True, transform=transforms.ToTensor(), download=True) # 下载MNIST数据集
data_loader = torch.utils.data.DataLoader(dataset=dataset, batch_size=batch_size, shuffle=True) # 数据加载器
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 是否有可用GPU,否则CPU
model = VAE().to(device) # 模型实例化
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate) # 优化器(Adam)
#################################################################
# (3)开始训练模型
for epoch in range(num_epochs):
model.train() # 模型训练
for i, (x, _) in enumerate(data_loader):
model.zero_grad() # 模型梯度清零
x = x.to(device).view(-1, image_size) # 改变数组形状并传递数据
x_reconst, mu, log_var = model(x) # 前向传播
reconst_loss = F.binary_cross_entropy(x_reconst, x, size_average=False) # 交叉熵损失函数(度量新图像与原图像的相似度)
kl_div = - 0.5 * torch.sum(1 + log_var - mu.pow(2) - log_var.exp()) # KL散度(度量隐含空间的分布与正态分布的相似度)
loss = reconst_loss + kl_div # 损失值(两者相加的总损失)
optimizer.zero_grad() # 梯度清零
loss.backward() # 反向传播
optimizer.step() # 梯度更新
# 每100个批次,打印结果。
if (i + 1) % 100 == 0:
print("Epoch[{}/{}], Step [{}/{}], Reconst Loss: {:.4f}, KL Div: {:.4f}"
.format(epoch + 1, num_epochs, i + 1, len(data_loader), reconst_loss.item(), kl_div.item()))
with torch.no_grad(): # 强制之后的内容不进行计算图构建。
# (在自定义文件夹中)保存采样图像,即潜在向量Z通过解码器生成的新图像
z = torch.randn(batch_size, z_dim).to(device)
out = model.decode(z).view(-1, 1, 28, 28)
save_image(out, os.path.join(sample_dir, 'sampled-{}.png'.format(epoch + 1)))
# (在自定义文件夹中)保存重构图像,即原图像通过解码器生成的图像
out, _, _ = model(x)
x_concat = torch.cat([x.view(-1, 1, 28, 28), out.view(-1, 1, 28, 28)], dim=3)
save_image(x_concat, os.path.join(sample_dir, 'reconst-{}.png'.format(epoch + 1)))
#################################################################
# (4)画图
reconsPath = './ave_samples/reconst-30.png' # (随机选择)重构图像
genPath = './ave_samples/sampled-30.png' # (随机选择)新生成图像
Reconstruct_Image = plt.imread(reconsPath)
Generate_Image = plt.imread(genPath)
plt.subplot(121), plt.imshow(Reconstruct_Image), plt.title('Reconstruct_Image'), plt.axis('off')
plt.subplot(122), plt.imshow(Generate_Image), plt.title('Generate_Image'), plt.axis('off')
plt.show()
(十五)实战:基于GAN生成式对抗网络生成图像(数据集:MNIST)
链接:https://pan.baidu.com/s/1X62pFmLRx7LDKwxG624KgA?pwd=5zf0
提取码:5zf0

import os
import torch
import torchvision
import torch.nn as nn
from torchvision import transforms
from torchvision.utils import save_image
import matplotlib.pyplot as plt
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True' # "OMP: Error #15: Initializing libiomp5md.dll"
###################################################################
# (1)超参数定义
latent_size = 64
hidden_size = 256
image_size = 784
num_epochs = 10
batch_size = 100
###################################################################
# (2)数据加载
# 在当前目录,创建不存在的目录gan_samples
sample_dir = 'gan_samples'
if not os.path.exists(sample_dir):
os.makedirs(sample_dir)
trans = transforms.Compose([transforms.ToTensor(), transforms.Normalize([0.5], [0.5])])
mnist = torchvision.datasets.MNIST(root='data', train=True, transform=trans, download=False)
data_loader = torch.utils.data.DataLoader(dataset=mnist, batch_size=batch_size, shuffle=True)
###################################################################
# (3)模型定义
# 构建判断器
D = nn.Sequential(
nn.Linear(image_size, hidden_size),
nn.LeakyReLU(0.2),
nn.Linear(hidden_size, hidden_size),
nn.LeakyReLU(0.2),
nn.Linear(hidden_size, 1),
nn.Sigmoid())
# 构建生成器,这个相当于AVE中的解码器
G = nn.Sequential(
nn.Linear(latent_size, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, image_size),
nn.Tanh())
###################################################################
# (4)加载模型并定义相关函数
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
D = D.to(device) # 将判别器迁移到设备上
G = G.to(device) # 将生成器迁移到设备上
criterion = nn.BCELoss() # 判别器的E交叉熵损失函数(BC)
d_optimizer = torch.optim.Adam(D.parameters(), lr=0.0002) # 判别器的优化器Adam
g_optimizer = torch.optim.Adam(G.parameters(), lr=0.0002) # 生成器的优化器Adam
###################################################################
# Clamp函数x限制在区间[min, max]内
def denorm(x):
out = (x + 1) / 2
return out.clamp(0, 1)
# 开始训练
total_step = len(data_loader)
for epoch in range(num_epochs):
for i, (images, _) in enumerate(data_loader):
images = images.reshape(batch_size, -1).to(device) # 改变数组形状
real_labels = torch.ones(batch_size, 1).to(device) # 定义图像的真标签(全1)
fake_labels = torch.zeros(batch_size, 1).to(device) # 定义图像的假标签(全0)
# ================================================================== #
# 训练判别器 #
# ================================================================== #
# 11、定义判断器对【真图片】的损失函数
outputs = D(images) # 前向传播(判别器)
d_loss_real = criterion(outputs, real_labels) # 判别器的损失loss
real_score = outputs
# 22、定义判别器对【假图片】的损失函数
z = torch.randn(batch_size, latent_size).to(device)
fake_images = G(z) # 前向传播(生成器)
outputs = D(fake_images) # 前向传播(判别器)
d_loss_fake = criterion(outputs, fake_labels) # 判别器的损失loss
fake_score = outputs
# 33、判别器的总损失loss
d_loss = d_loss_real + d_loss_fake
d_optimizer.zero_grad() # 判别器的梯度清零
g_optimizer.zero_grad() # 生成器的梯度清零
d_loss.backward() # 判别器的反向传播
d_optimizer.step() # 判别器的梯度更新
# ================================================================== #
# 训练生成器 #
# ================================================================== #
# 定义生成器对假图片的损失函数。
# 要求判别器生成的图片越来越像真图片,故损失函数中的标签改为真图片的标签,即希望生成的假图片,越来越靠近真图片。
z = torch.randn(batch_size, latent_size).to(device)
fake_images = G(z) # 前向传播(生成器)
outputs = D(fake_images) # 前向传播(判别器)
g_loss = criterion(outputs, real_labels) # 生成器的损失loss
d_optimizer.zero_grad() # 判别器的梯度清零
g_optimizer.zero_grad() # 生成器的梯度清零
g_loss.backward() # 生成器的反向传播
g_optimizer.step() # 生成器的梯度更新
# 每200个批次,打印结果
if (i + 1) % 200 == 0:
print('Epoch [{}/{}], Step [{}/{}], d_loss: {:.4f}, g_loss: {:.4f}, D(x): {:.2f}, D(G(z)): {:.2f}'
.format(epoch+1, num_epochs, i + 1, total_step, d_loss.item(), g_loss.item(),
real_score.mean().item(), fake_score.mean().item()))
# 保存真图片
if (epoch + 1) == 1:
images = images.reshape(images.size(0), 1, 28, 28)
save_image(denorm(images), os.path.join(sample_dir, 'real_images.png'))
# 保存假图片
fake_images = fake_images.reshape(fake_images.size(0), 1, 28, 28)
save_image(denorm(fake_images), os.path.join(sample_dir, 'fake_images-{}.png'.format(epoch + 1)))
# 保存预训练模型
torch.save(G.state_dict(), 'G.ckpt')
torch.save(D.state_dict(), 'D.ckpt')
###################################################################
for epoch in range(num_epochs):
fake_images_path = './gan_samples/fake_images-' + str(epoch+1) + '.png'
fake_image = plt.imread(fake_images_path)
plt.subplot(int(num_epochs/5), 5, epoch+1), plt.imshow(fake_image), plt.title('fake_images' + str(epoch+1))
plt.show()
reconsPath = './gan_samples/real_images.png'
Image = plt.imread(reconsPath)
plt.imshow(Image), plt.title('real_images'), plt.axis('off')
plt.show()





![[JAVA安全]JACKSON反序列化](https://img-blog.csdnimg.cn/d842c8aa280e4f688a137daaea110042.png)