一、Stream流
1.引言
Test:给定一个集合,如果想要筛选出其中以 "a" 开头且长度为3的元素,并添加到新集合中去,最后遍历打印,如何实现?
public class Test {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "aaa", "bbb", "abcd", "dba", "ab", "acd", "bad", "adc");
ArrayList<String> newList = new ArrayList<>();
for (String s : list) {
if (s.startsWith("a") && s.length() == 3) {
newList.add(s);
}
}
for (String s : newList) {
System.out.println(s);//aaa acd adc
}
}
}但这种写法过于复杂,为此提出了 Stream流的思想,可以更方便、高效的进行操作。
2.定义
Stream流:可以理解为一条流水线,可以对流水线上的数据进行各种操作(筛选、打印等)。
作用:结合了 Lambda表达式,简化集合、数组的操作
使用步骤:
① 先得到一个 Stream 流,将数据放上去

② 利用 Stream 流中的中间方法进行各种操作。
③ 利用 Stream 流中的终结方法进行各种操作。

(1)单列集合使用 Stream流
注:单列集合可直接调用 Stream 方法获取stream流
public class ListDemo {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "a", "b", "c", "d", "e", "ff", "ggg");
//1.获取Stream流(流水线),并把集合中的数据放到流水线上
Stream<String> stream1 = list.stream();
//2.使用中间方法过滤一下流水线上的数据
Stream stream2 = stream1.filter(new Predicate<String>() {
@Override
public boolean test(String s) {
return s.length() == 1;
}
});
//3.使用终结方法打印流水线上的数据
stream2.forEach(new Consumer<String>() {
@Override
public void accept(String s) {
System.out.println(s);
}
});
}
}虽然说看着依旧很麻烦,但是如果我们使用 Lambda表达式进行简化:
public class ListDemo {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "a", "b", "c", "d", "e", "ff", "ggg");
list.stream().filter(s -> s.length() == 1).forEach(s -> System.out.println(s));
}
}就可以一行代码解决所有问题,这使得代码的书写方式更加高效、便捷。
(2)双列集合使用 Stream流
注:双列集合是不能直接使用 Stream流的,必须要变成单列集合才可以使用
方法一:使用 keySet 方法得到所有的键,所有的键构成一个单列 Set 集合
方法二:使用 EntrySet 方法将所有的键值对变成 Entry 对象,使其构成一个单列 Set集合
public class MapDemo {
public static void main(String[] args) {
HashMap<String, Integer> hm = new HashMap<>();
hm.put("aaa", 111);
hm.put("bbb", 222);
hm.put("ccc", 333);
hm.put("ddd", 444);
//方式一:将所有的键变成set集合,再获取Stream流
hm.keySet().stream().forEach(s -> System.out.println(s));
//方式二:将键值对变成 Entry对象,存放到Set集合中,再获取Stream流
hm.entrySet().stream().forEach(s -> System.out.println(s));
}
}运行结果:

细节:
方式一中的 s 代表键,所以遍历后只有键;方式二中的 s 代表 Entry对象,包含键和值。
(3)数组使用 Stream流
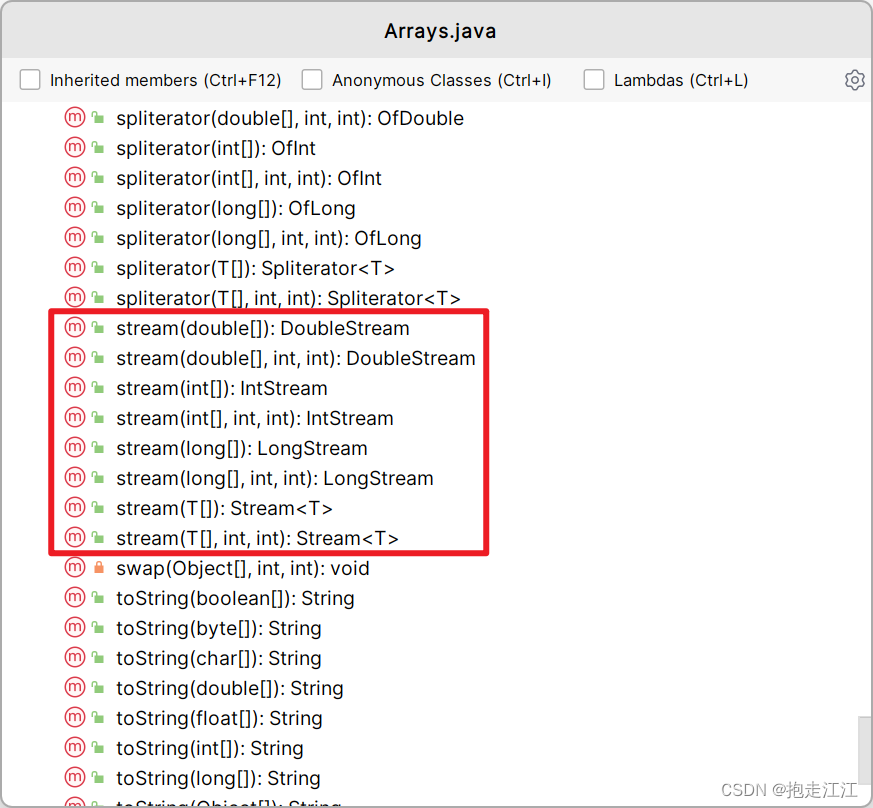
注:数组需要使用 Arrays 工具类提供的 stream 方法,形参为数组。
Arrays 提供了很多 stream 的重载方法,无论数组是任何数据类型,都可以使用。
public class ArrayDemo {
public static void main(String[] args) {
int[] arr = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
Arrays.stream(arr).forEach(i -> System.out.println(i));
}
}(4)零散数据使用 Stream流
注:零散数据必须要是同一数据类型的,需要使用 Stream 接口中的 of 方法获取 Stream 流。
public class DataDemo {
public static void main(String[] args) {
Stream.of(1, 2, 3, 4, 5).forEach(i -> System.out.println(i));
Stream.of("a", "b", "c", "d", "e").forEach(s -> System.out.println(s));
}
}
细节:
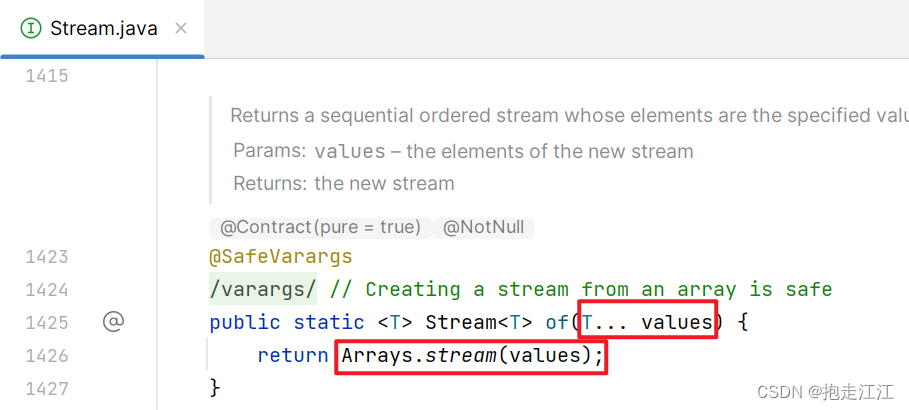
① Stream 接口中的 of 方法的形参是一个可变参数,所以可以添加任意数量的零散数据。
而可变参数实质上就是一个数组,所以 of 方法底层调用的还是 Arrays 中的 stream 方法。
② 由于 Stream 接口中的 of 方法的形参是一个可变参数,所以可以传递一堆零散的数据,也可以传递数组,但数组必须是引用数据类型的。
如果传递基本数据类型,会把整个数组当作一个元素,放到 Stream 中。
public class OfDemo {
public static void main(String[] args) {
int[] arr1 = {1, 2, 3, 4, 5};
Stream.of(arr1).forEach(i -> System.out.println(i));//[I@404b9385
String[] arr2 = {"a", "b", "c", "d", "e"};
Stream.of(arr2).forEach(s -> System.out.println(s));//a b c d e
}
}
结论:数组获取 Stream流,最好使用 Arrays 中的 stream 方法,不建议使用 Stream 中的 of 方法。
3.中间方法
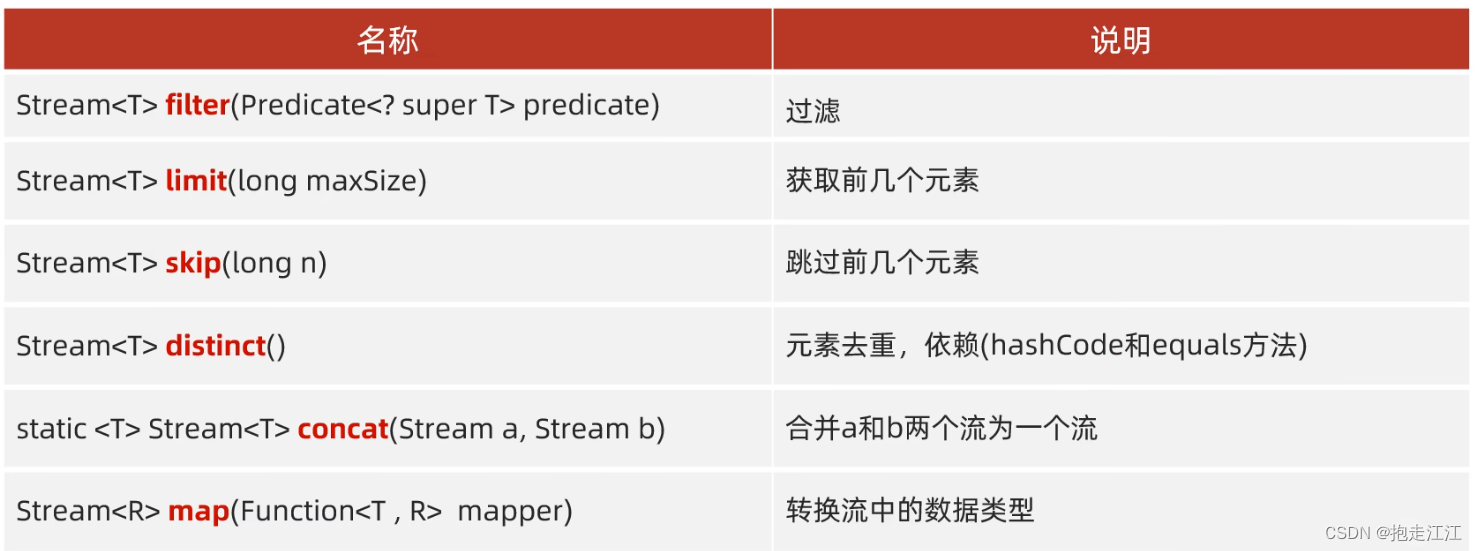
注意:
① 中间方法,会返回新的 Stream 流,原来的 Stream 流只用一次,所以建议使用链式编程。
② 中间方法只修改 Stream 流中的数据,不会对原来集合或者数组中的数据造成影响。
(1)filter 方法

filter 方法中的形参是一个 Predicate 接口,所以需要使用 匿名内部类 创建接口的实现类对象。
public class filterDemo {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "aaa", "bbb", "abcd", "dba", "ab", "acd", "bad", "adc");
list.stream().filter(new Predicate<String>() {
@Override
public boolean test(String s) {
return s.startsWith("a") && s.length() == 3;
}
}).forEach(s -> System.out.println(s));
}
}
在重写的 test 方法中,形参 s 表示集合中的每一个数据,返回值为 boolean 类型。
如果返回值为 true,表示当前数据要留下;
如果返回值为 false,表示当前数据则舍弃不要。
由于 Predicate 接口是函数式接口,所以可以使用 Lambda表达式。
public class filterDemo {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "aaa", "bbb", "abcd", "dba", "ab", "acd", "bad", "adc");
list.stream()
.filter(s -> s.startsWith("a") && s.length() == 3)
.forEach(s -> System.out.println(s));
System.out.println(list);//[aaa, bbb, abcd, dba, ab, acd, bad, adc]
}
}
可以看出,最后 list 所打印的数据并没有发生改变。
所以说,stream流 对数据造成的修改,并不会对原来的集合或数组造成影响。
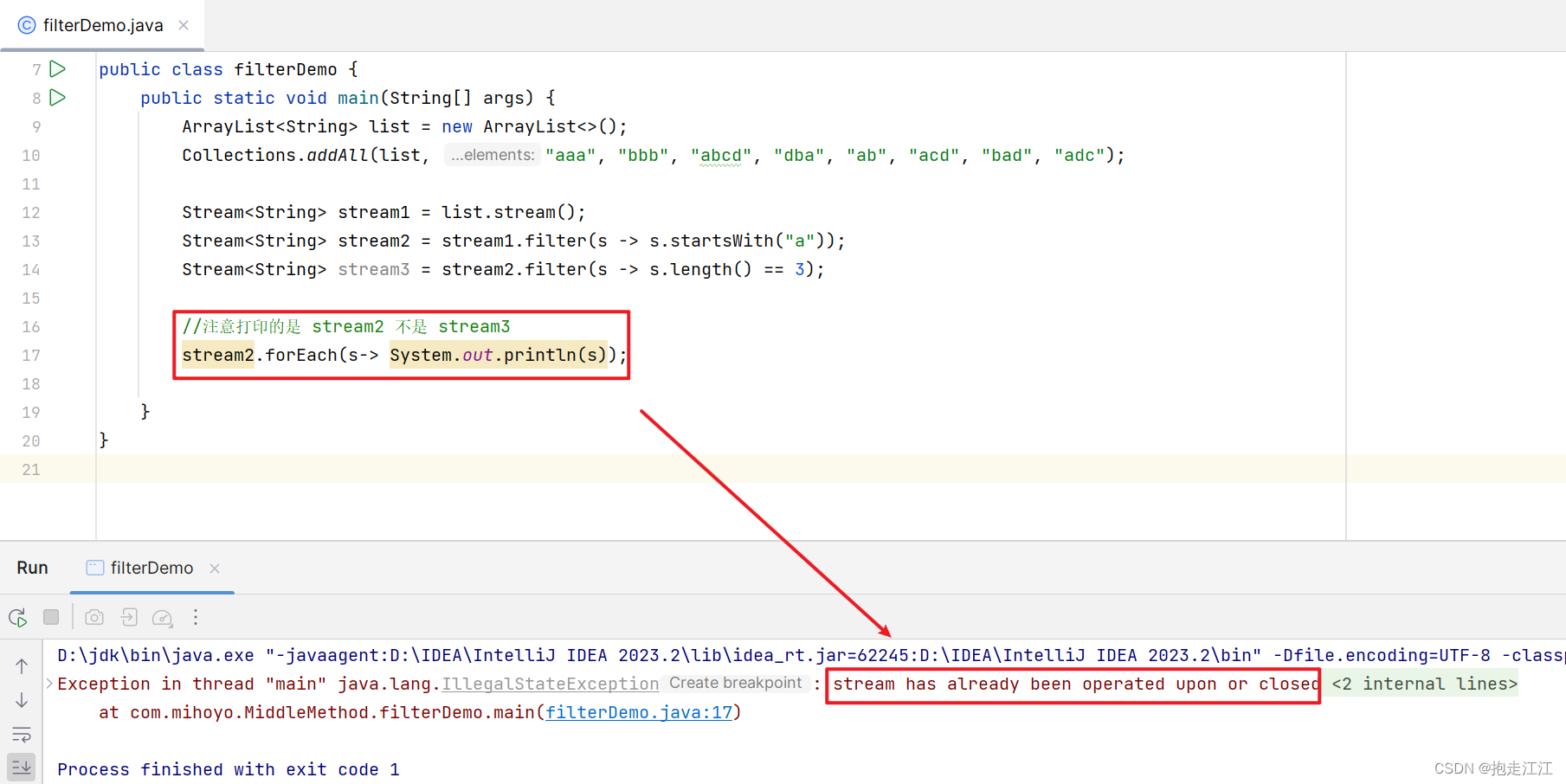
而且 stream 流只能用一次,用完不能再度使用了,否则会报错。
(2) limit 和 skip 方法
public class LimitDemo {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "aaa", "bbb", "abcd", "dba", "ab", "acd", "bad", "adc");
//limit 只获取x个元素
list.stream().limit(3).forEach(s -> System.out.print(s + " "));//aaa bbb abcd
System.out.println();
//skip 跳过x个元素开始获取
list.stream().skip(4).forEach(s -> System.out.print(s + " "));//ab acd bad adc
}
}(3)distinct 和 concat 方法
public class DistinctDemo {
public static void main(String[] args) {
ArrayList<String> list1 = new ArrayList<>();
Collections.addAll(list1, "aa", "bb", "cc", "cc", "cc", "dd");
ArrayList<String> list2 = new ArrayList<>();
Collections.addAll(list2, "ee", "ff", "gg");
//distinct 元素去重(依赖hashcode和equals方法)
list1.stream()
.distinct()
.forEach(s -> System.out.print(s + " "));//aa bb cc dd
System.out.println();
//concat 合并a和b两个流为一个流
Stream.concat(list1.stream(), list2.stream())
.forEach(s -> System.out.print(s + " "));//aa bb cc cc cc dd ee ff gg
}
}细节:
① 通过源码可以发现,distinct 方法的去重机制,底层是依赖 HashSet 实现的去重。
而 HashSet 的不重复性是依靠 hashCode 和 equals 方法得到保证的,所以 distinct 需要依赖它们
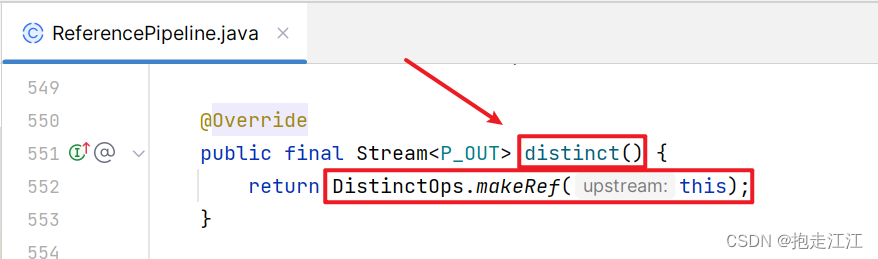

② 调用 concat方法时,需要尽可能的保证两个流的数据类型是一致的。
如果数据类型不一致(分别为 a 和 b),合并后会变成 a 和 b 共同的父类类型。
(4)map 方法
public class MapDemo {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "张三-23", "李四-24", "王五-25", "赵六-26");
//map 转换流中的数据类型
list.stream().map(new Function<String, Integer>() {
@Override
public Integer apply(String s) {
//切割字符串
String[] arr = s.split("-");//[张三,23] [李四,24]...
//获取年龄
String ageStr = arr[1];
//类型转化
int age = Integer.parseInt(ageStr);
return age;
}
}).forEach(i -> System.out.print(i + " "));//23 24 25 26
}
}
细节:
① map 的形参是一个Function 接口,接口中有两个泛型:
第一个泛型:流中原本元素的数据类型
第二个泛型:转换后元素的数据类型(要和重写的 apply 方法的返回值类型一致)
② apply 方法的形参 s 表示流中的每一个数据,返回值表示转换之后的数据。
③ Function 是一个函数式接口,所以可以使用 Lambda表达式。

public class MapDemo {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "张三-23", "李四-24", "王五-25", "赵六-26");
//map 转换流中的数据类型
list.stream()
.map(s -> Integer.parseInt(s.split("-")[1]))
.forEach(i -> System.out.print(i + " "));//23 24 25 26
}
}4.终结方法

(1)forEach 和 count 方法
public class CountDemo {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "aa", "bb", "cc", "dd", "ee");
//forEach 遍历
list.stream().forEach(s-> System.out.print(s + " "));//aa bb cc dd ee
//count 统计流中数据的个数
long count=list.stream().count();
System.out.println(count);//5
}
}细节:
forEach 方法的返回值类型是 void,count 方法的返回值类型是 long。
都不是 流Stream<T>,所以是终结方法,调用之后就不能调用其他 Stream接口中的API。
(2)toArray 方法
public class ToArrayDemo {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "aa", "bb", "cc", "dd", "ee");
//toArray 收集流中的数据,存放到数组中
//1.空参-->返回 Object 类型的数组
Object[] arr1 = list.stream().toArray();
System.out.println(Arrays.toString(arr1));//[aa, bb, cc, dd, ee]
//2.带参-->返回指定类型的数组
String[] arr2 = list.stream().toArray(new IntFunction<String[]>() {
@Override
public String[] apply(int value) {
return new String[value];
}
});
System.out.println(Arrays.toString(arr2));//[aa, bb, cc, dd, ee]
}
}
细节:
Stream 接口提供了两个重载的 toArray方法:
空参的 toArray:返回 Object 类型的数组
带参的 toArray:返回指定类型的数组

② toArray方法的形参是一个 IntFunction 接口,接口的泛型是具体类型的数组。
重写的 apply 方法的形参 value:流中数据的个数
重写的 apply 方法的返回值:具体类型的数组(数组的长度就是 value )。
③ toArray 方法的参数的作用:负责创建一个指定类型的数组
toArray 方法的底层:会依次得到流中的每一个数据,并把数据放到数组中
toArray 方法的返回值:是一个装着流里面所有数据的数组
④ IntFunction 接口是一个函数式接口,可以使用 Lambda 表达式

public class ToArrayDemo {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "aa", "bb", "cc", "dd", "ee");
//toArray 收集流中的数据,存放到数组中
String[] arr2=list.stream()
.toArray(value -> new String[value]);
System.out.println(Arrays.toString(arr2));//[aa, bb, cc, dd, ee]
}
}(3)collect 方法
public class CollectDemo {
public static void main(String[] args) {
//需求:将男性数据存放到一个集合当中
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "张三-男-23", "张三-男-23", "李四-女-24", "王五-男-25", "赵六-女-26");
//collect 收集流中的数据,存放到集合中
//1.收集到List集合当中
List<String> newList = list.stream()
.filter(s -> "男".equals(s.split("-")[1]))
.collect(Collectors.toList());
System.out.println(newList);//[张三-男-23, 张三-男-23, 王五-男-25]
//2.收集到Set集合当中
Set<String> newSet = list.stream()
.filter(s -> "男".equals(s.split("-")[1]))
.collect(Collectors.toSet());
System.out.println(newSet);//[张三-男-23, 王五-男-25]
}
}细节:
① Collectors 是 Stream 流的一个工具类,提供了 toList,toSet,toMap 方法,将流中的数据存放到各种集合中
② toList 底层会创建一个 ArrayList 集合,toSet 底层会创建一个 HashSet 集合
③ 由于 HashSet 的无序和不重复性,所以 toSet 产生的集合中的数据是无序且不重复的。
而 toList 产生的集合中的数据是有序且可以重复的。
public class CollectDemo2 {
public static void main(String[] args) {
//需求:将男性数据存放到一个Map集合当中,键为姓名,值为年龄
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "张三-男-23", "李四-女-24", "王五-男-25", "赵六-女-26");
//3.收集到Map集合当中
Map<String, Integer> newMap = list.stream()
.filter(s -> "男".equals(s.split("-")[1]))
.collect(Collectors.toMap(new Function<String, String>() {
@Override
public String apply(String s) {
return s.split("-")[0];
}
}, new Function<String, Integer>() {
@Override
public Integer apply(String s) {
return Integer.parseInt(s.split("-")[2]);
}
}));
System.out.println(newMap);//{张三=23, 王五=25}
}
}细节:
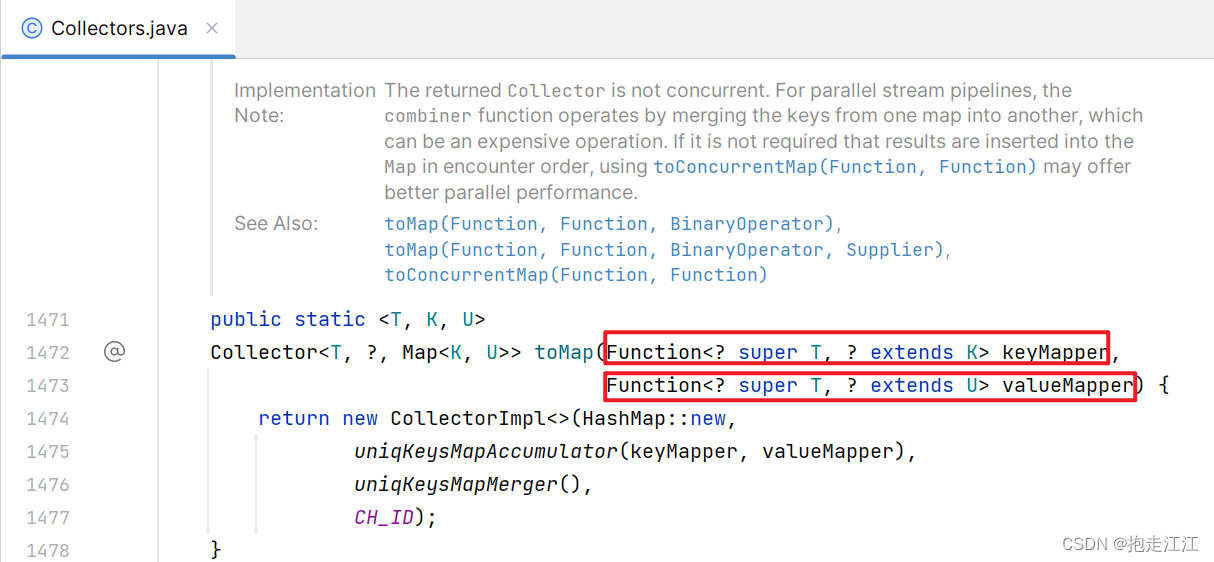
① toMap 方法中有两个形参:
参数一表示键的生成规则;
参数二表示值的生成规则。
参数一中:
Function 中:
泛型一:表示流中的每一个数据的类型
泛型二:表示创建的 Map 集合中的键的数据类型
apply 方法中:
形参:依次表示流里面的每一个数据
方法体:生成键的代码
返回值:生成的键
参数二中:
Function 中:
泛型一:表示流中的每一个数据的类型
泛型二:表示创建的 Map 集合中的值的数据类型
apply 方法中:
形参:依次表示流里面的每一个数据
方法体:生成值的代码
返回值:生成的值
② toMap 底层会创建一个 HashMap 集合
③ 由于 Map 集合中键的不可重复性,所以初始数据不能有相同的键,否则调用 toMap 时会报错。
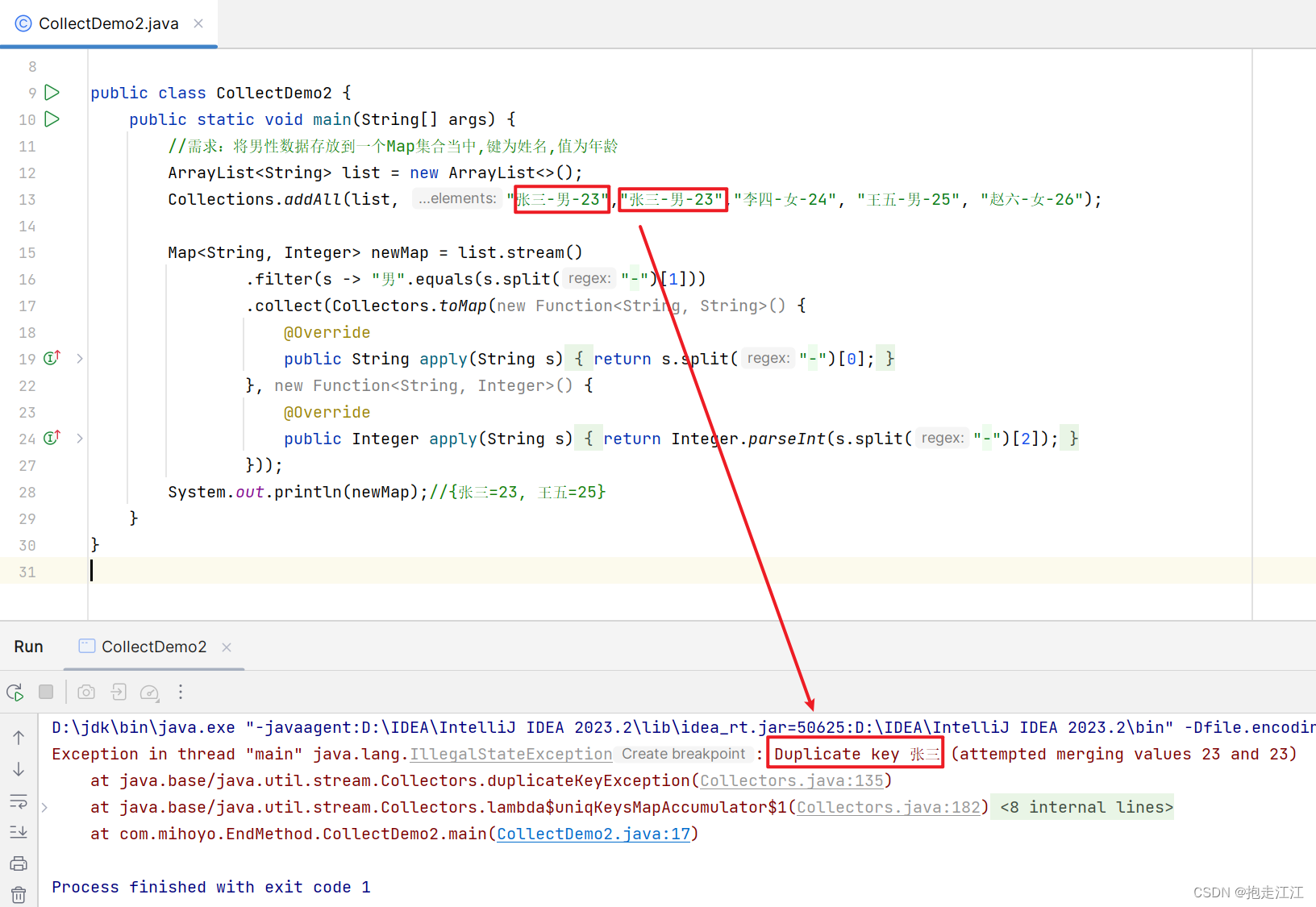
④ Function 接口是一个函数式接口,所以可以使用 Lambda 表达式。

public class CollectDemo2 {
public static void main(String[] args) {
//需求:将男性数据存放到一个Map集合当中,键为姓名,值为年龄
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "张三-男-23", "张三-男-23", "李四-女-24", "王五-男-25", "赵六-女-26");
Map<String, Integer> newMap = list.stream()
.filter(s -> "男".equals(s.split("-")[1]))
.collect(Collectors.toMap(
s -> s.split("-")[0],
s -> Integer.parseInt(s.split("-")[2])));
System.out.println(newMap);//{张三=23, 王五=25}
}
}二、方法引用
1.定义
方法引用:把已经存在的方法拿过来用,当作函数式接口中重写的抽象方法的方法体。

方法引用可以比 Lambda表达式 的写法更加简便。

使用方法引用必须满足以下四个条件:
① 引用处必须是函数式接口。
② 被引用方法必须已经存在(如果不存在,需要自定义方法或者使用第三方工具类)。
③ 被引用方法的形参和返回值必须要和抽象方法保持一致。
④ 被引用方法的功能要满足当前需求。
public class Demo {
public static void main(String[] args) {
//需求:创建一个数组,进行倒序排列
Integer[] arr1 = {3, 5, 6, 7, 1, 2, 4};
Integer[] arr2 = {3, 5, 6, 7, 1, 2, 4};
//匿名内部类
Arrays.sort(arr1, new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2 - o1;
}
});
System.out.println(Arrays.toString(arr1));//[7, 6, 5, 4, 3, 2, 1]
//方法引用
Arrays.sort(arr2, Demo::subtraction);
System.out.println(Arrays.toString(arr2));//[7, 6, 5, 4, 3, 2, 1]
}
public static int subtraction(int num1, int num2) {
return num2 - num1;
}
}2.分类
(1)引用静态方法
格式:类名::静态方法名(如:Integer::parseInt)
需求:将字符串集合中的数字,都变成 int 类型
一般写法:
public class StaticFunDemo {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "1", "2", "3", "4", "5");
list.stream().map(new Function<String, Integer>() {
@Override
public Integer apply(String s) {
return Integer.parseInt(s);
}
}).forEach(i -> System.out.print(i + " "));//1 2 3 4 5
}
}
但是这种写法过于麻烦,我们可以尝试使用方法引用。
Function 已经是一个函数式接口,但有没有一个方法能满足后面 3 个条件呢?

答案是有的,Integer 类中的 parseInt 方法正好满足剩下三个条件。
形参、返回值、功能全都符合,所以可以使用方法引用。
public class StaticFunDemo {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "1", "2", "3", "4", "5");
//方法引用
list.stream()
.map(Integer::parseInt)
.forEach(i -> System.out.print(i + " "));//1 2 3 4 5
}
}
(2)引用成员方法
格式:对象::成员方法
① 其他类:其他类对象::方法名
② 本类:this::方法名
③ 父类:super::方法名
需求:筛选出以“a”开头且长度为3的元素
一般写法:
public class FunDemo {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "aaa", "bbb", "abcd", "dba", "ab", "acd", "bad", "adc");
//匿名内部类
list.stream().filter(new Predicate<String>() {
@Override
public boolean test(String s) {
return s.startsWith("a") && s.length() == 3;
}
}).forEach(s -> System.out.print(s + " "));//aaa acd adc
}
}很显然,这种方法 java必然没有定义,所以需要自己定义一个方法。
① 可以在其他类中定义成员方法,再引用
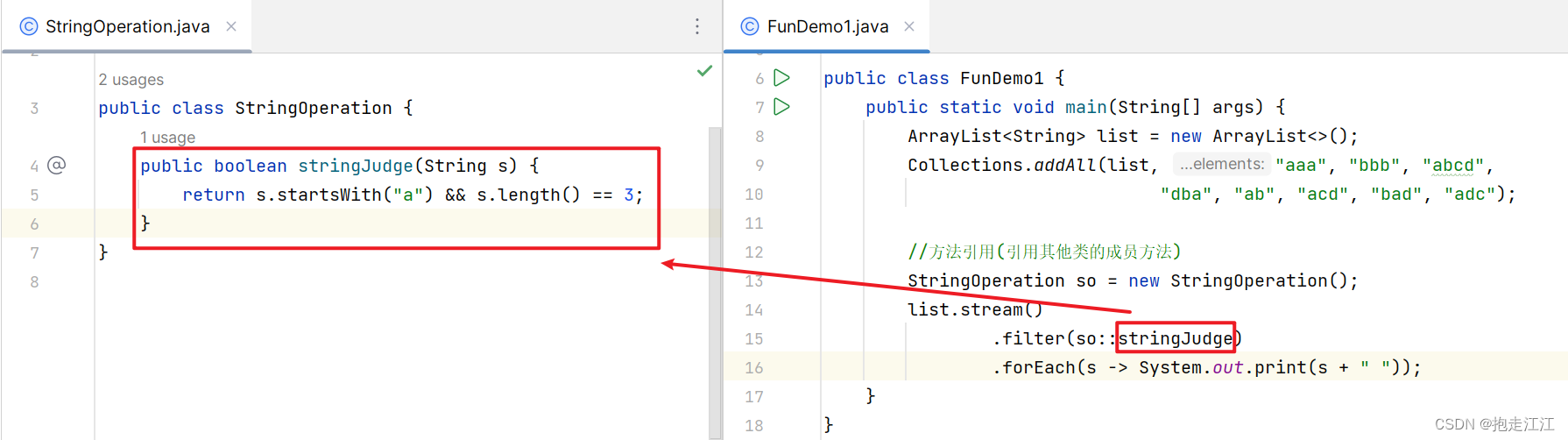
② 可以在本类中定义成员方法,再引用
public class FunDemo{
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "aaa", "bbb", "abcd", "dba", "ab", "acd", "bad", "adc");
//方法引用(引用本类成员方法)
list.stream()
.filter(new FunDemo()::stringJudge)
.forEach(s -> System.out.print(s + " "));
}
public boolean stringJudge(String s){
return s.startsWith("a") && s.length() == 3;
}
}细节:
main:静态方法(类方法) stringJudge:成员方法(实例方法)
静态方法只能访问静态成员,在静态方法中,是不存在 this 的。
所以如果要在静态方法中引用本类的成员方法,
不能用 this::方法名,只能 new 对象,用 对象::方法名。
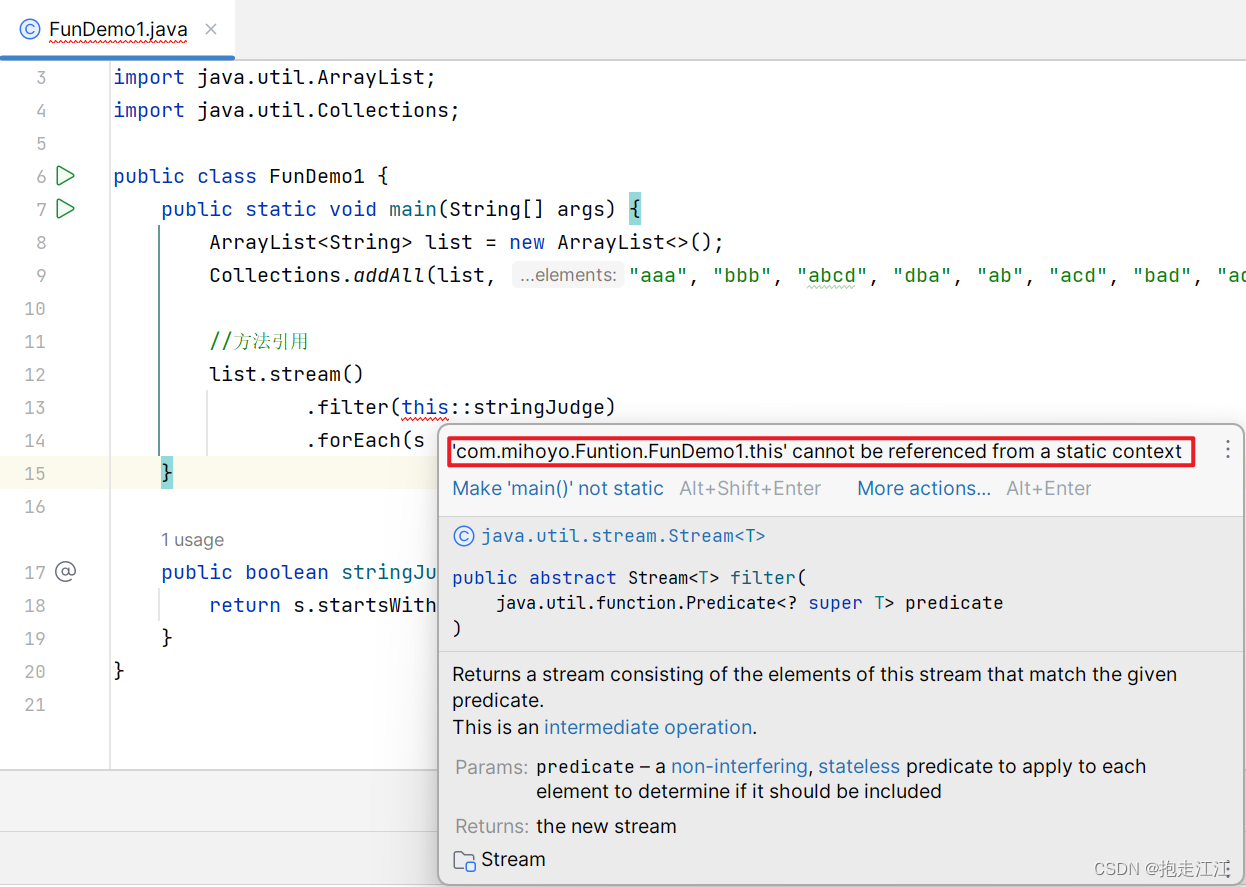
同理,静态方法中也是不存在 super 的。
所以不能通过 super 引用父类中的成员方法,只能通过创建父类对象再引用。
结论:通过 this 或 super 引用成员方法,引用处不能是静态方法。
(3)引用构造方法
格式:类名::new(如:Student::new)
目的:创建这个类的对象
需求:集合中存储姓名和年龄,要求封装成 Student 对象并收集到 List 集合中。
一般写法:
public class Student {
private String name;
private int age;
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}public class ConstructionDemo {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "张三-23", "李四-24", "王五-25", "赵六-26");
//匿名内部类
List<Student> newList = list.stream().map(new Function<String, Student>() {
@Override
public Student apply(String s) {
String[] arr = s.split("-");
String name = arr[0];
int age = Integer.parseInt(arr[1]);
return new Student(name, age);
}
}).collect(Collectors.toList());
}
}Function 是一个函数式接口,但这个重写的 apply 方法,很显然 Java 并没有提供。
apply 方法的功能是为了根据字符串,创造一个 Student 对象。
但现在,Student 的构造方法中,只有无参和全参的。
所以,我们需要自定义一个新的构造方法,形参是一个字符串,满足该功能。
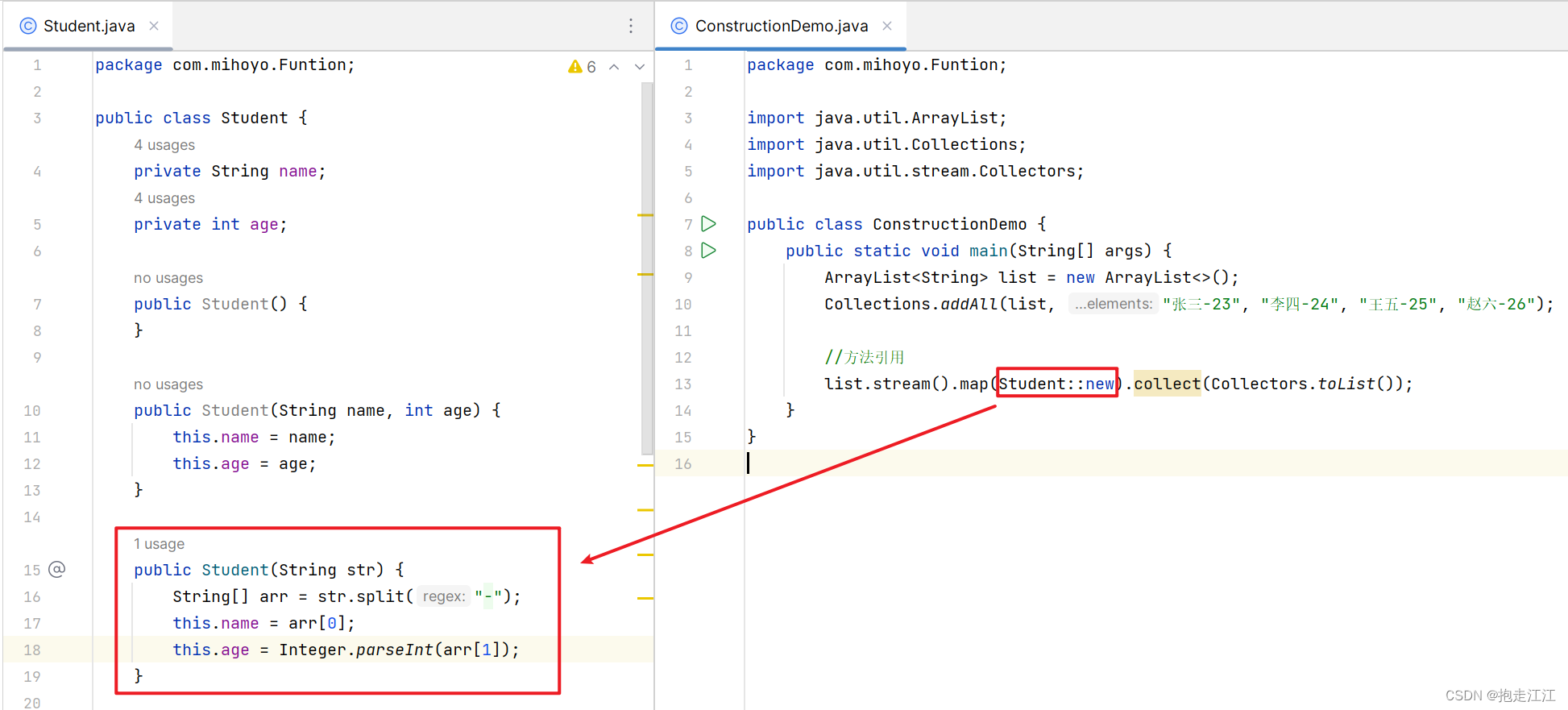
注:由于构造方法的功能就是创造一个该类的对象,所以在引用构造方法时,不必在乎构造方法的返回值 。
(4) 其他引用方式
Ⅰ、使用类名引用成员方法
格式:类名::成员方法(如:String::substring)
规则(只针对该方式):
① 引用处必须是函数式接口
② 被引用的方法必须已经存在
③ 被引用方法的形参,需要和抽象方法的第二个形参到最后一个形参保持一致,返回值需要保持一致
④ 被引用方法的功能需要满足当前的需求
抽象方法形参的解释:
第一个参数: 表示被引用方法的调用者,决定了可以引用哪些类中的方法。
在 Stream流中,第一个参数一般都表示流中的每一个数据。
假设该数据是String 类型,则使用该方式进行方法引用,只能引用 String 类中的成员方法。
第二个参数到最后一个参数: 需要跟被引用方法的形参保持一致。
如果抽象方法没有第二个参数,说明被引用的方法是需要的是无参的成员方法。
需求:将集合中的字符串变成大写后,进行输出。
一般写法:
public class ClassFunDemo {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "aaa", "bbb", "ccc", "ddd");
//匿名内部类
//小写(String)--> 大写(String)
list.stream().map(new Function<String, String>() {
@Override
public String apply(String s) {
return s.toUpperCase();
}
}).forEach(s -> System.out.print(s + " "));
}
}抽象方法 apply 中的第一个形参是 String s,表示被引用方法的调用者,也就代表了只能引用 String 类中 的成员方法。
而 apply 没有第二个形参,所以被引用的方法应该是无参的成员方法。

所以, 引用处可以直接引用 String 类中的 toUpperCase 方法。
public class ClassFunDemo {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "aaa", "bbb", "ccc", "ddd");
//方法引用
list.stream().map(String::toUpperCase).forEach(s -> System.out.print(s + " "));
}
}注意:
① 这种方式比较特殊,所以不能按照初始规则,需要满足一些特殊的规则。
(被引用方法的形参,要和抽象方法的第二个形参到最后一个形参保持一致,返回值需要保持一致)
② 这种方式有很大的局限性:
在(2)中只要创建类的对象,就可以引用该类的成员方法,所以可以引用所有类的成员方法。
但这种方式是跟抽象方法第一个参数有关,这个参数是什么类型,就只能引用这个类的成员方法。
II、引用数组的构造方法
格式:数据类型[]::new(如:int[]::new)
目的:创建一个指定类型的数组
需求:集合中存储了一些整数,将它们收集到数组中
一般写法:
public class ArrayFunDemo {
public static void main(String[] args) {
ArrayList<Integer> list = new ArrayList<>();
Collections.addAll(list, 1, 2, 3, 4, 5);
//匿名内部类
Integer[] arr = list.stream().toArray(new IntFunction<Integer[]>() {
@Override
public Integer[] apply(int value) {
return new Integer[value];
}
});
System.out.println(Arrays.toString(arr));//[1, 2, 3, 4, 5]
}
}方法引用:
public class ArrayFunDemo {
public static void main(String[] args) {
ArrayList<Integer> list = new ArrayList<>();
Collections.addAll(list, 1, 2, 3, 4, 5);
//方法引用
Integer[] arr = list.stream().toArray(Integer[]::new);
System.out.println(Arrays.toString(arr));//[1, 2, 3, 4, 5]
}
}细节:
① 数组的类型,必须和流中数据的类型保持一致
② 这里不能写 int[]::new,因为原本的写法中,数组的类型是在 IntFunction 接口的泛型中。
而泛型中不能是基本数据类型,只能是引用数据类型,所以只能是 Integer。