AI预测相关目录
AI预测流程,包括ETL、算法策略、算法模型、模型评估、可视化等相关内容
最好有基础的python算法预测经验
- EEMD策略及踩坑
- VMD-CNN-LSTM时序预测
- 对双向LSTM等模型添加自注意力机制
- K折叠交叉验证
- optuna超参数优化框架
- 多任务学习-模型融合策略
- Transformer模型及Paddle实现
- 迁移学习在预测任务上的tensoflow2.0实现
- holt提取时序序列特征
- TCN时序预测及tf实现
- 注意力机制/多头注意力机制及其tensorflow实现
- 一文解析AI预测数据工程
- FITS:一个轻量级而又功能强大的时间序列分析模型
- DLinear:未来预测聚合历史信息的最简单网络
- LightGBM:更好更快地用于工业实践集成学习算法
- 面向多特征的AI预测指南
- 大模型时序预测初步调研【20240506】
- Time-LLM :超越了现有时间序列预测模型的学习器
- CV预测:快速使用LeNet-5卷积神经网络
- CV预测:快速使用ResNet深度残差神经网络并创建自己的训练集
文章目录
- AI预测相关目录
- 研究背景
- 算法设计
- 实际应用
- 数据集构建及训练代码:
- 预测代码:
- Resnet源码
研究背景
网络的层数越深,理想情况下,网络模型的学习效果越好。但是实际中,单纯地增加网络的深度,网络会变得越来越难训练,而且精度会达到饱和。这主要是由于两种问题造成的:
- (1)梯度弥散/爆炸现象
- (2)退化问题
梯度弥散:又称为梯度消失。在深度神经网络中,如果梯度在反向传播过程中变得非常小,那么权重更新将非常缓慢,导致模型训练非常缓慢或无法收敛。这通常发生在使用Sigmoid或Tanh激活函数的深层网络中。
梯度爆炸:与梯度消失相反,梯度爆炸发生在梯度变得非常大,导致权重更新过大,模型变得不稳定,甚至导致训练过程崩溃。
此外,当模型在训练过程中逐渐失去对某些特征的敏感性,而过度依赖其他特征时,可能会发生特征退化。
解决这些退化现象的方法包括但不限于:使用正则化技术(如L1、L2正则化)、使用不同的激活函数、调整学习率、使用更复杂的优化算法、数据增强、早停法等。
但都治标不治本。
直到深度残差网络思想的出现,它直接改进网络架构。
算法设计
残差学习的基本思想是,如果一个较浅的网络已经能够学习到某些特征,那么在增加网络深度时,可以通过添加恒等映射(即直接将输入复制到输出)来保持这些特征,而不是强迫网络学习恒等函数。这样,即使网络非常深,也能保证网络性能不会下降。
ResNet由多个残差块(Residual Blocks)组成,每个残差块包含两个卷积层,以及一个跳过连接(Skip Connection),它将块的输入直接添加到块的输出。这种设计允许梯度在网络中直接流动,从而缓解了梯度消失问题。
具体如下所示:
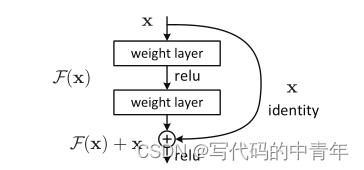

当然,残差块中的卷积层数量、大小可以进行定制,这在学术上叫做“瓶颈结构”,可灵活升降维处理特征;残差可直接加到输出结果中,也可以进行采样,这在学术上叫做“尺寸匹配”,以上种种。但实际的应用开发中,我们其实并不需要关心这些细节设计,了解其架构总体思想即可。
因为其思想下的优秀设计已经有了开源的现成品可以直接使用。
经典设计:

实际应用
数据集构建及训练代码:
数据集长成这样:

代码:
import tensorflow as tf
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
import numpy as np
from tensorflow import keras
from tensorflow.keras import layers, optimizers, datasets, Sequential, metrics,models # 导入TF子库
from resnet import resnet18
#数据准备
train_dir = r'C:\Users\12258\Desktop\maoniushibie1221\data\train'
#数据处理
def get_files(file_dir):
# 存放图片类别和标签的列表:第0类
list_0 = []
label_0 = []
# 存放图片类别和标签的列表:第1类
list_1 = []
label_1 = []
# 存放图片类别和标签的列表:第2类
list_2 = []
label_2 = []
# 存放图片类别和标签的列表:第3类
list_3 = []
label_3 = []
# 存放图片类别和标签的列表:第4类
list_4 = []
label_4 = []
list_5 = []
label_5 = []
list_6 = []
label_6 = []
for file in os.listdir(file_dir):
# print(file)
#拼接出图片文件路径
image_file_path = os.path.join(file_dir,file)
for image_name in os.listdir(image_file_path):
# print('image_name',image_name)
#图片的完整路径
image_name_path = os.path.join(image_file_path,image_name)
# print('image_name_path',image_name_path)
#将图片存放入对应的列表
if image_file_path[-1:] == '1':
list_0.append(image_name_path)
label_0.append(0)
elif image_file_path[-1:] == '2':
list_1.append(image_name_path)
label_1.append(1)
elif image_file_path[-1:] == '3':
list_2.append(image_name_path)
label_2.append(2)
elif image_file_path[-1:] == '4':
list_3.append(image_name_path)
label_3.append(3)
elif image_file_path[-1:] == '5':
list_3.append(image_name_path)
label_3.append(4)
elif image_file_path[-1:] == '6':
list_3.append(image_name_path)
label_3.append(5)
else :
list_4.append(image_name_path)
label_4.append(6)
# 合并数据
image_list = np.hstack((list_0, list_1, list_2, list_3, list_4,list_5,list_6))
label_list = np.hstack((label_0, label_1, label_2, label_3, label_4,label_5,label_6))
#利用shuffle打乱数据
temp = np.array([image_list, label_list])
temp = temp.transpose() # 转置
np.random.shuffle(temp)
#将所有的image和label转换成list
image_list = list(temp[:, 0])
image_list = [i for i in image_list]
label_list = list(temp[:, 1])
label_list = [int(float(i)) for i in label_list]
# print(image_list)
# print(label_list)
return image_list, label_list
def get_tensor(image_list, label_list):
ims = []
for image in image_list:
#读取路径下的图片
x = tf.io.read_file(image)
#将路径映射为照片,3通道
x = tf.image.decode_jpeg(x,channels=3)
#修改图像大小
x = tf.image.resize(x,[56,56])
#将图像压入列表中
ims.append(x)
#将列表转换成tensor类型
img = tf.convert_to_tensor(ims)
y = tf.convert_to_tensor(label_list)
return img,y
def preprocess(x,y):
#归一化
x = tf.cast(x,dtype=tf.float32) / 255.0
y = tf.cast(y, dtype=tf.int32)
return x,y
#训练图片与标签
image_list, label_list = get_files(train_dir)
x_train, y_train = get_tensor(image_list, label_list)
#载入训练数据集
db_train = tf.data.Dataset.from_tensor_slices((x_train, y_train))
# # shuffle:打乱数据,map:数据预处理,batch:一次取喂入10样本训练
db_train = db_train.shuffle(1000).map(preprocess).batch(10)
# 模型搭建
model = resnet18()
model.build(input_shape=(None, 56, 56, 3))
model.summary()
# 模型装配
model.compile(optimizer=optimizers.SGD(lr=0.03), # 指定Adam优化器,学习率为0.01
loss=tf.losses.SparseCategoricalCrossentropy(from_logits=True), # 指定采用交叉熵损失函数,包含Softmax
metrics=['accuracy']) # 指定评价指标为准备率
# 模型训练
# 输入训练集train_dataset,训练8个epochs; 每训练完2个epochs,对验证集val_dataset验证一次
model.fit(db_train, epochs=8)
model.save_weights('model_weight')
预测代码:
import tensorflow as tf
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
import numpy as np
from tensorflow import keras
from tensorflow.keras import layers, optimizers, datasets, Sequential, metrics,models # 导入TF子库
from resnet import resnet18
#数据准备
train_dir = r'C:\Users\12258\Desktop\maoniushibie1221\data\train'
#数据处理
def get_files(file_dir):
# 存放图片类别和标签的列表:第0类
list_0 = []
label_0 = []
# 存放图片类别和标签的列表:第1类
list_1 = []
label_1 = []
# 存放图片类别和标签的列表:第2类
list_2 = []
label_2 = []
# 存放图片类别和标签的列表:第3类
list_3 = []
label_3 = []
# 存放图片类别和标签的列表:第4类
list_4 = []
label_4 = []
list_5 = []
label_5 = []
list_6 = []
label_6 = []
for file in os.listdir(file_dir):
# print(file)
#拼接出图片文件路径
image_file_path = os.path.join(file_dir,file)
for image_name in os.listdir(image_file_path):
# print('image_name',image_name)
#图片的完整路径
image_name_path = os.path.join(image_file_path,image_name)
# print('image_name_path',image_name_path)
#将图片存放入对应的列表
if image_file_path[-1:] == '1':
list_0.append(image_name_path)
label_0.append(0)
elif image_file_path[-1:] == '2':
list_1.append(image_name_path)
label_1.append(1)
elif image_file_path[-1:] == '3':
list_2.append(image_name_path)
label_2.append(2)
elif image_file_path[-1:] == '4':
list_3.append(image_name_path)
label_3.append(3)
elif image_file_path[-1:] == '5':
list_3.append(image_name_path)
label_3.append(4)
elif image_file_path[-1:] == '6':
list_3.append(image_name_path)
label_3.append(5)
else :
list_4.append(image_name_path)
label_4.append(6)
# 合并数据
image_list = np.hstack((list_0, list_1, list_2, list_3, list_4,list_5,list_6))
label_list = np.hstack((label_0, label_1, label_2, label_3, label_4,label_5,label_6))
#利用shuffle打乱数据
temp = np.array([image_list, label_list])
temp = temp.transpose() # 转置
np.random.shuffle(temp)
#将所有的image和label转换成list
image_list = list(temp[:, 0])
image_list = [i for i in image_list]
label_list = list(temp[:, 1])
label_list = [int(float(i)) for i in label_list]
# print(image_list)
# print(label_list)
return image_list, label_list
def get_tensor(image_list, label_list):
ims = []
for image in image_list:
#读取路径下的图片
x = tf.io.read_file(image)
#将路径映射为照片,3通道
x = tf.image.decode_jpeg(x,channels=3)
#修改图像大小
x = tf.image.resize(x,[56,56])
#将图像压入列表中
ims.append(x)
#将列表转换成tensor类型
img = tf.convert_to_tensor(ims)
y = tf.convert_to_tensor(label_list)
return img,y
def preprocess(x,y):
#归一化
x = tf.cast(x,dtype=tf.float32) / 255.0
y = tf.cast(y, dtype=tf.int32)
return x,y
#训练图片与标签
image_list, label_list = get_files(train_dir)
x_train, y_train = get_tensor(image_list, label_list)
#载入训练数据集
db_train = tf.data.Dataset.from_tensor_slices((x_train, y_train))
# # shuffle:打乱数据,map:数据预处理,batch:一次取喂入10样本训练
db_train = db_train.shuffle(1000).map(preprocess).batch(10)
# 模型搭建
model = resnet18()
model.build(input_shape=(None, 56, 56, 3))
model.summary()
# 模型装配
model.compile(optimizer=optimizers.SGD(lr=0.03), # 指定Adam优化器,学习率为0.01
loss=tf.losses.SparseCategoricalCrossentropy(from_logits=True), # 指定采用交叉熵损失函数,包含Softmax
metrics=['accuracy']) # 指定评价指标为准备率
# 模型训练
# 输入训练集train_dataset,训练8个epochs; 每训练完2个epochs,对验证集val_dataset验证一次
model.fit(db_train, epochs=8)
model.save_weights('model_weight')
Resnet源码
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, Sequential
class BasicBlock(layers.Layer):
def __init__(self, filter_num, stride=1):
super(BasicBlock, self).__init__()
self.conv1 = layers.Conv2D(filter_num, (3, 3), strides=stride, padding='same')
self.bn1 = layers.BatchNormalization() # BN层
self.relu = layers.Activation('relu') # ReLU激活函数
self.conv2 = layers.Conv2D(filter_num, (3, 3), strides=1, padding='same')
self.bn2 = layers.BatchNormalization() # BN层
if stride != 1:
self.downsample = Sequential() # 下采样
self.downsample.add(layers.Conv2D(filter_num, (1, 1), strides=stride))
else:
self.downsample = lambda x:x # 恒等映射
def call(self, inputs, training=None):
out = self.conv1(inputs)
out = self.bn1(out,training=training)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out,training=training)
identity = self.downsample(inputs) # 恒等映射
output = layers.add([out, identity]) # 主路与支路(恒等映射)相加
output = tf.nn.relu(output) # ReLU激活函数
return output
class ResNet(keras.Model):
def __init__(self, layer_dims, num_classes=100):
super(ResNet, self).__init__()
# 第一层
self.stem = Sequential([layers.Conv2D(64, (3, 3), strides=(1, 1)),
layers.BatchNormalization(),
layers.Activation('relu'),
layers.MaxPool2D(pool_size=(2, 2), strides=(1, 1), padding='same')
])
# 中间层的四个残差块:conv2_x,conv3_x,conv4_x,conv5_x
self.layer1 = self.build_resblock(64, layer_dims[0])
self.layer2 = self.build_resblock(128, layer_dims[1], stride=2)
self.layer3 = self.build_resblock(256, layer_dims[2], stride=2)
self.layer4 = self.build_resblock(512, layer_dims[3], stride=2)
# 全局平均池化
self.avgpool = layers.GlobalAveragePooling2D()
# 全连接层
self.fc = layers.Dense(num_classes)
def call(self, inputs, training=None):
x = self.stem(inputs,training=training)
x = self.layer1(x,training=training)
x = self.layer2(x,training=training)
x = self.layer3(x,training=training)
x = self.layer4(x,training=training)
x = self.avgpool(x)
x = self.fc(x)
return x
# 构建残差块(将几个相同的残差模块堆叠在一起)
def build_resblock(self, filter_num, blocks, stride=1):
res_blocks = Sequential()
# 可能会进行下采样
res_blocks.add(BasicBlock(filter_num, stride))
for _ in range(1, blocks):
res_blocks.add(BasicBlock(filter_num, stride=1))
return res_blocks
def resnet18():
return ResNet([2, 2, 2, 2])
def resnet34():
return ResNet([3, 4, 6, 3])