【论文】https://arxiv.org/pdf/1901.07474.pdf
(以下序号与论文序列不对应)
属性可以看作是高层语义信息,对视点变化和观察条件多样性具有更强的鲁棒性
本文试图解决以下几个重要问题:
(1)传统和基于深度学习的行人属性识别算法之间的联系和区别是什么?从不同的分类规则分析传统和基于深度学习的算法,如基于部件、基于组或端到端学习;
(2)行人属性如何帮助其他相关的计算机视觉任务?还回顾了一些由行人属性引导的计算机视觉任务,如行人再识别、目标检测、行人跟踪等,以充分证明该方法在其他许多相关任务中的有效性和广泛应用;
(3)如何更好地利用深度网络进行行人属性识别,属性识别的未来发展方向是什么?通过评估现有的行人属性识别算法和一些排名靠前的基线方法,得出了一些有用的结论,并提出了一些可能的研究方向。
1.行人属性识别的常规流程
实际视频监控中的行人属性可能包含几十个类别,正如许多流行的基准所定义的那样。独立地学习每个属性是一种直观的想法,但会造成冗余和低效。因此,研究者倾向于在一个模型中估计所有的属性,将每个属性估计视为一个任务。由于多任务学习的优雅和高效,它受到越来越多的关注。另一方面,该模型将给定的行人图像作为输入,输出相应的属性。行人属性识别也属于多标签学习领域。在本节中,我们将从多标签学习和多任务学习两个方面简要介绍用于行人属性识别的常规流程。
1.1 多任务学习
许多事情都是相互关联的。一项任务的学习可能依赖或限制其他任务。即使一个任务被分解,但子任务之间仍然存在一定的相关性。独立处理单个任务容易忽略这种相关性,从而导致最终性能的提升可能遇到瓶颈。
最流行的方法是联合学习多任务以挖掘共享的特征表示。
根据Ruder等人[52]的研究,MTL高效背后的原因可以归结为以下五点:隐式数据增强、注意力聚焦、窃听、表示偏差、正则化。
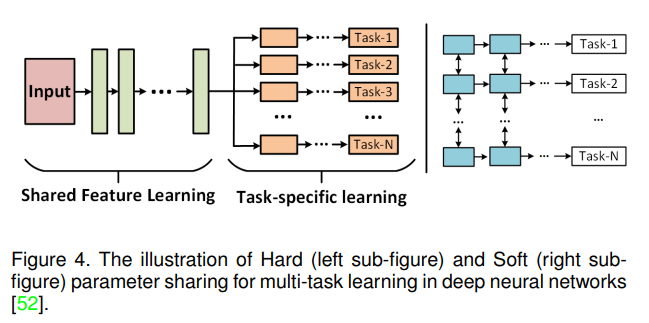
一般来说,基于深度学习的多任务学习有两种方法,即硬参数共享和软参数共享。
硬参数共享通常将浅层作为共享层来学习多个任务的共同特征表示,而将高层作为特定任务的层来学习更具判别性的模式。该模式是深度学习社区中最流行的框架。硬参数共享的说明可以在图4(左子图)中找到。
对于软参数共享的多任务学习(如图4所示(右子图)),它们独立训练每个任务,但通过引入正则化约束,如L2距离[53]和迹范数[54],使不同任务之间的参数相似。
1.2 多标签学习
对于多标签分类算法,可以归纳为以下三种学习策略,如[51]所述:
1)一阶策略:是最简单的形式,可以直接将多类问题转化为多个二分类问题;虽然取得了较好的效率,但该策略无法对多标签之间的相关性进行建模,导致泛型差;
2)二阶策略:考虑了每个标签对之间的相关性,取得了比一阶策略更好的性能;
3)高阶策略:考虑所有标签之间的关系,通过建模每个标签对其他标签的影响来实现多标签识别系统。该方法具有通用性,但复杂度高,在处理大规模图像分类任务时效果不佳。
因此,通常采用以下两种方法进行模型构建:问题转换和算法自适应。
为了简化使用问题转换的多标签分类问题,可以采用现有的广泛使用的框架。具有代表性的算法有:
1)二进制相关算法[55],该算法直接将多标记问题转化为多个二分类问题,最后将所有二分类器融合在一起进行多标签分类。该方法简单直观,但忽略了多个标签之间的相关性;
2)分类器链算法[56],该算法的基本思想是将多标记学习问题转化为二分类链问题。每个二分类器都依赖于链中的前一个分类器;
3)标记排序算法[57],该算法考虑了成对标记之间的相关性,将多标记学习转化为标记排序问题;
4)随机k-标签集算法[58],将多标签分类问题转化为多个分类问题的集合,每个集合中的分类任务是一个多类分类器。而多类分类器需要学习的类别是所有类别的子集。
不同于问题转换,算法自适应直接改进现有算法并应用于多标签分类问题,包括:
1)多标签k近邻(multi-label k-nearest neighbour, ML-kNN[59]),采用KNN技术处理多类别数据,并利用最大后验概率(maximum a posteriori, MAP)规则,根据邻居节点所蕴含的标记信息进行推理预测。
2)多标签决策树(ML-DT[60])尝试用决策树来处理多标签数据,利用基于多标签熵的信息增益准则递归地构建决策树。
3)排序支持向量机(ranking support vector machine, Rank-SVM[61])采用最大间隔策略来处理这个问题,其中一组线性分类器被优化以最小化经验排序损失,并能够使用核技巧处理非线性情况。
4)集体多标签分类器CML[62]采用最大熵原则来处理多标签任务,其中标签之间的相关性被编码为结果分布必须满足的约束。