文章目录
- 一、数据科学的基本概念
- 1. 数据收集
- 2. 数据清洗
- 3. 数据分析
- 4. 数据可视化
- 5. 机器学习
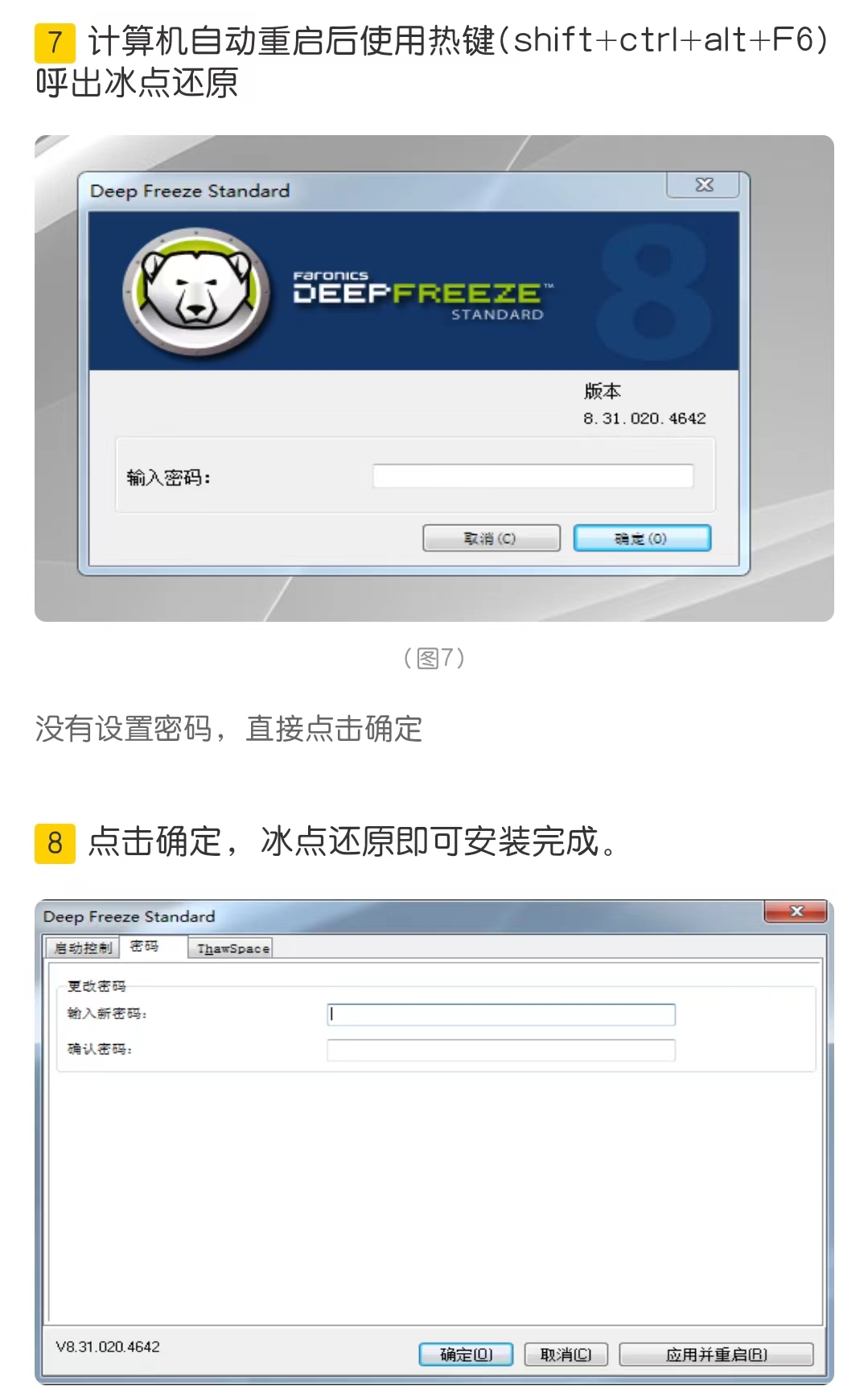
- 二、常用的数据科学库
- 1. Pandas
- 1.1 创建Series和DataFrame
- 1.2 数据操作
- 2. NumPy
- 2.1 创建数组
- 2.2 数组操作
- 3. Scikit-learn
- 3.1 数据预处理
- 3.2 特征工程
- 三、数据预处理与特征工程
- 1. 处理缺失值
- 1.1 删除缺失值
- 1.2 填充缺失值
- 2. 数据去重
- 3. 数据规范化
- 4. 特征提取
- 四、模型构建与评估
- 1. 线性回归
- 1.1 构建线性回归模型
- 2. 决策树
- 2.1 构建决策树模型
- 3. 随机森林
- 3.1 构建随机森林模型
- 五、超参数调优
- 1. 网格搜索
- 1.1 使用网格搜索进行超参数调优
- 2. 随机搜索
- 2.1 使用随机搜索进行超参数调优
- 六、模型部署与应用
- 1. 使用Flask部署模型
- 1.1 保存模型
- 1.2 创建Flask应用
- 1.3 调用API
- 七、实际应用示例
- 1. 房价预测
- 1.1 导入数据
- 1.2 数据预处理
- 1.3 构建和评估模型
- 2. 客户流失预测
- 1.1 导入数据
- 1.2 数据预处理
- 1.3 构建和评估模型
- 结论
Python作为一种灵活且功能强大的编程语言,在数据科学与机器学习领域得到了广泛应用。其丰富的库和工具集使得数据处理、分析、建模和部署变得更加高效。在这篇文章中,我们将深入探讨Python在数据科学与机器学习中的应用,涵盖数据科学的基本概念、常用的数据科学库、数据预处理与特征工程、模型构建与评估、超参数调优、模型部署与应用,以及一些实际应用示例。
一、数据科学的基本概念
数据科学是一门通过数据分析、数据挖掘和机器学习技术来发现数据中隐藏的模式和规律,从而解决实际问题的学科。以下是一些数据科学的基本概念:
1. 数据收集
数据收集是数据科学的第一步,指从各种数据源获取数据的过程。数据源可以是数据库、API、文件(如CSV、Excel)、网页爬虫等。
2. 数据清洗
数据清洗是指对原始数据进行清理和处理,以去除数据中的噪音、错误和缺失值。数据清洗通常包括数据去重、处理缺失值、数据格式转换等。
3. 数据分析
数据分析是指对数据进行统计分析和建模,从中提取有价值的信息。数据分析包括描述性统计分析和推断性统计分析。
4. 数据可视化
数据可视化是指使用图表和图形展示数据分析的结果,以便更直观地理解数据。
5. 机器学习
机器学习是数据科学的重要组成部分,它通过构建和训练模型,使计算机能够自动从数据中学习并作出预测或决策。
二、常用的数据科学库
Python提供了丰富的数据科学库,其中最常用的是Pandas、NumPy和Scikit-learn。
1. Pandas
Pandas是Python中最常用的数据处理和分析库,它提供了高效的数据操作工具。Pandas的核心数据结构是Series和DataFrame。
1.1 创建Series和DataFrame
以下是创建Series和DataFrame的示例:
import pandas as pd
# 创建Series
data = [1, 2, 3, 4, 5]
series = pd.Series(data)
print(series)
# 创建DataFrame
data = {
'Name': ['Alice', 'Bob', 'Charlie', 'David'],
'Age': [24, 27, 22, 32],
'City': ['New York', 'Los Angeles', 'Chicago', 'Houston']
}
df = pd.DataFrame(data)
print(df)
1.2 数据操作
Pandas提供了丰富的数据操作方法,包括选择、过滤、排序、分组等。以下是一些常见的数据操作示例:
# 选择列
print(df['Name'])
# 选择行
print(df.iloc[1])
# 过滤数据
print(df[df['Age'] > 25])
# 排序数据
print(df.sort_values(by='Age'))
# 分组数据
print(df.groupby('City').mean())
2. NumPy
NumPy是Python中最常用的数值计算库,它提供了支持大型多维数组和矩阵运算的功能,以及丰富的数学函数库。
2.1 创建数组
以下是创建NumPy数组的示例:
import numpy as np
# 创建一维数组
array1 = np.array([1, 2, 3, 4, 5])
print(array1)
# 创建二维数组
array2 = np.array([[1, 2, 3], [4, 5, 6]])
print(array2)
# 创建全零数组
zeros = np.zeros((3, 3))
print(zeros)
# 创建全一数组
ones = np.ones((3, 3))
print(ones)
# 创建随机数组
random_array = np.random.random((3, 3))
print(random_array)
2.2 数组操作
NumPy提供了丰富的数组操作方法,包括切片、索引、数学运算等。以下是一些常见的数组操作示例:
# 数组切片
print(array2[:, 1])
# 数组索引
print(array2[1, 2])
# 数组加法
print(array1 + array1)
# 数组乘法
print(array1 * 2)
# 数组矩阵乘法
print(np.dot(array2, array2.T))
3. Scikit-learn
Scikit-learn是一个功能强大的Python机器学习库,它提供了丰富的机器学习算法和工具,用于数据预处理、特征工程、模型构建、模型评估和超参数调优。
3.1 数据预处理
Scikit-learn提供了多种数据预处理方法,如标准化、归一化、缺失值处理等。以下是一些示例:
from sklearn.preprocessing import StandardScaler, MinMaxScaler, Imputer
# 标准化
scaler = StandardScaler()
data = [[1, 2], [2, 3], [4, 5]]
scaled_data = scaler.fit_transform(data)
print(scaled_data)
# 归一化
scaler = MinMaxScaler()
scaled_data = scaler.fit_transform(data)
print(scaled_data)
# 缺失值处理
data = [[1, 2], [2, None], [4, 5]]
imputer = SimpleImputer(strategy='mean')
imputed_data = imputer.fit_transform(data)
print(imputed_data)
3.2 特征工程
特征工程是指从原始数据中提取有用的特征,以便进行数据分析和建模。以下是一些示例:
from sklearn.preprocessing import OneHotEncoder, LabelEncoder
# 独热编码
data = [['cat'], ['dog'], ['fish']]
encoder = OneHotEncoder()
encoded_data = encoder.fit_transform(data).toarray()
print(encoded_data)
# 标签编码
data = ['cat', 'dog', 'fish']
label_encoder = LabelEncoder()
encoded_data = label_encoder.fit_transform(data)
print(encoded_data)
三、数据预处理与特征工程
数据预处理和特征工程是数据科学和机器学习的关键步骤。它们包括处理缺失值、数据去重、数据规范化、特征提取等。
1. 处理缺失值
缺失值是数据处理中常见的问题,处理缺失值的方法包括删除缺失值、填充缺失值、插值等。
1.1 删除缺失值
以下是删除缺失值的示例:
# 创建带有缺失值的DataFrame
data = {
'Name': ['Alice', 'Bob', 'Charlie', 'David'],
'Age': [24, None, 22, 32],
'City': ['New York', 'Los Angeles', None, 'Houston']
}
df = pd.DataFrame(data)
# 删除包含缺失值的行
df.dropna(inplace=True)
print(df)
1.2 填充缺失值
以下是填充缺失值的示例:
# 创建带有缺失值的DataFrame
data = {
'Name': ['Alice', 'Bob', 'Charlie', 'David'],
'Age': [24, None, 22, 32],
'City': ['New York', 'Los Angeles', None, 'Houston']
}
df = pd.DataFrame(data)
# 填充缺失值
df.fillna({'Age': df['Age'].mean(), 'City': 'Unknown'}, inplace=True)
print(df)
2. 数据去重
数据去重是指删除数据中重复的记录。以下是数据去重的示例:
# 创建带有重复值的DataFrame
data = {
'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Alice'],
'Age': [24, 27, 22, 32, 24],
'City': ['New York', 'Los Angeles', 'Chicago', 'Houston', 'New York']
}
df = pd.DataFrame(data)
# 删除重复值
df.drop_duplicates(inplace=True)
print(df)
3. 数据规范化
数据规范化是指将数据转换为统一的格式,以便进行进一步的分析和处理。以下是数据规范化的示例:
# 创建带有不一致格式的DataFrame
data = {
'Name': ['Alice', 'BOB', 'Charlie', 'david'],
'Age': [24, 27, 22, 32],
'City': ['New York
', 'Los Angeles', 'Chicago', 'Houston']
}
df = pd.DataFrame(data)
# 将姓名转换为一致的格式
df['Name'] = df['Name'].str.capitalize()
print(df)
4. 特征提取
特征提取是指从原始数据中提取有用的特征,以便进行数据分析和建模。以下是特征提取的示例:
# 创建带有日期的DataFrame
data = {
'Date': ['2023-01-01', '2023-01-02', '2023-01-03'],
'Value': [100, 200, 150]
}
df = pd.DataFrame(data)
# 提取日期特征
df['Date'] = pd.to_datetime(df['Date'])
df['Year'] = df['Date'].dt.year
df['Month'] = df['Date'].dt.month
df['Day'] = df['Date'].dt.day
print(df)
四、模型构建与评估
模型构建与评估是机器学习的核心步骤。我们将使用Scikit-learn构建和评估模型,包括线性回归、决策树、随机森林等常见算法。
1. 线性回归
线性回归是一种简单的监督学习算法,用于预测目标变量与特征变量之间的线性关系。
1.1 构建线性回归模型
以下示例展示了如何构建和评估线性回归模型:
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# 创建数据
X = [[1], [2], [3], [4], [5]]
y = [1, 3, 2, 3, 5]
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 构建模型
model = LinearRegression()
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 评估模型
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error: {mse}")
2. 决策树
决策树是一种非参数的监督学习算法,用于分类和回归任务。
2.1 构建决策树模型
以下示例展示了如何构建和评估决策树模型:
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
# 创建数据
X = [[0, 0], [1, 1], [1, 0], [0, 1]]
y = [0, 1, 1, 0]
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 构建模型
model = DecisionTreeClassifier()
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 评估模型
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy}")
3. 随机森林
随机森林是一种集成学习算法,通过构建多个决策树并结合其预测结果,来提高模型的准确性和稳定性。
3.1 构建随机森林模型
以下示例展示了如何构建和评估随机森林模型:
from sklearn.ensemble import RandomForestClassifier
# 创建数据
X = [[0, 0], [1, 1], [1, 0], [0, 1]]
y = [0, 1, 1, 0]
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 构建模型
model = RandomForestClassifier(n_estimators=10)
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 评估模型
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy}")
五、超参数调优
超参数调优是机器学习中提高模型性能的重要步骤。Scikit-learn提供了多种超参数调优方法,如网格搜索(Grid Search)和随机搜索(Random Search)。
1. 网格搜索
网格搜索是一种系统的超参数调优方法,通过遍历所有可能的参数组合,找到最佳参数。
1.1 使用网格搜索进行超参数调优
以下示例展示了如何使用网格搜索进行超参数调优:
from sklearn.model_selection import GridSearchCV
# 创建数据
X = [[0, 0], [1, 1], [1, 0], [0, 1]]
y = [0, 1, 1, 0]
# 构建模型
model = DecisionTreeClassifier()
# 定义参数网格
param_grid = {
'max_depth': [1, 2, 3],
'min_samples_split': [2, 3, 4]
}
# 进行网格搜索
grid_search = GridSearchCV(model, param_grid, cv=3)
grid_search.fit(X, y)
# 打印最佳参数
print(f"Best Parameters: {grid_search.best_params_}")
2. 随机搜索
随机搜索是一种更高效的超参数调优方法,通过随机选择参数组合,找到近似最佳参数。
2.1 使用随机搜索进行超参数调优
以下示例展示了如何使用随机搜索进行超参数调优:
from sklearn.model_selection import RandomizedSearchCV
# 创建数据
X = [[0, 0], [1, 1], [1, 0], [0, 1]]
y = [0, 1, 1, 0]
# 构建模型
model = DecisionTreeClassifier()
# 定义参数分布
param_dist = {
'max_depth': [1, 2, 3, None],
'min_samples_split': [2, 3, 4]
}
# 进行随机搜索
random_search = RandomizedSearchCV(model, param_dist, cv=3, n_iter=5)
random_search.fit(X, y)
# 打印最佳参数
print(f"Best Parameters: {random_search.best_params_}")
六、模型部署与应用
模型部署与应用是机器学习项目的最后一步。我们将讨论如何将训练好的模型部署到生产环境,并通过API进行调用。
1. 使用Flask部署模型
Flask是一个轻量级的Web框架,非常适合用于部署机器学习模型。以下示例展示了如何使用Flask部署机器学习模型:
1.1 保存模型
首先,我们需要保存训练好的模型:
import pickle
from sklearn.linear_model import LinearRegression
# 创建并训练模型
model = LinearRegression()
X = [[1], [2], [3], [4], [5]]
y = [1, 3, 2, 3, 5]
model.fit(X, y)
# 保存模型
with open('model.pkl', 'wb') as file:
pickle.dump(model, file)
1.2 创建Flask应用
接下来,我们创建一个Flask应用来加载和调用模型:
from flask import Flask, request, jsonify
import pickle
app = Flask(__name__)
# 加载模型
with open('model.pkl', 'rb') as file:
model = pickle.load(file)
@app.route('/predict', methods=['POST'])
def predict():
data = request.get_json(force=True)
prediction = model.predict([data['input']])
return jsonify({'prediction': prediction[0]})
if __name__ == '__main__':
app.run(debug=True)
1.3 调用API
启动Flask应用后,可以通过HTTP请求调用API:
import requests
url = 'http://127.0.0.1:5000/predict'
data = {'input': [2]}
response = requests.post(url, json=data)
print(response.json())
七、实际应用示例
以下是两个实际应用示例,演示如何使用Python进行数据科学和机器学习。
1. 房价预测
以下示例展示了如何使用Scikit-learn构建和评估一个简单的房价预测模型:
1.1 导入数据
import pandas as pd
# 导入数据
data = pd.read_csv('house_prices.csv')
print(data.head())
1.2 数据预处理
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# 选择特征和目标
X = data[['GrLivArea', 'TotalBsmtSF', 'GarageArea']]
y = data['SalePrice']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 标准化数据
scaler = StandardScaler
()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
1.3 构建和评估模型
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# 构建模型
model = LinearRegression()
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 评估模型
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error: {mse}")
2. 客户流失预测
以下示例展示了如何使用Scikit-learn构建和评估一个客户流失预测模型:
1.1 导入数据
import pandas as pd
# 导入数据
data = pd.read_csv('customer_churn.csv')
print(data.head())
1.2 数据预处理
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
# 选择特征和目标
X = data.drop('Churn', axis=1)
y = data['Churn']
# 编码分类特征
label_encoder = LabelEncoder()
for column in X.select_dtypes(include=['object']).columns:
X[column] = label_encoder.fit_transform(X[column])
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
1.3 构建和评估模型
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# 构建模型
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 评估模型
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy}")
结论
Python是数据科学与机器学习中的一种强大工具,提供了丰富的库和工具集,使得数据处理、分析、建模和部署变得更加高效。在本文中,我们深入探讨了数据科学的基本概念、常用的数据科学库(如Pandas、NumPy和Scikit-learn)、数据预处理与特征工程、模型构建与评估、超参数调优、模型部署与应用,以及一些实际应用示例。希望这篇文章能帮助你更好地理解和应用Python中的数据科学与机器学习技术,从而在实际项目中获得更多的洞察和成功。