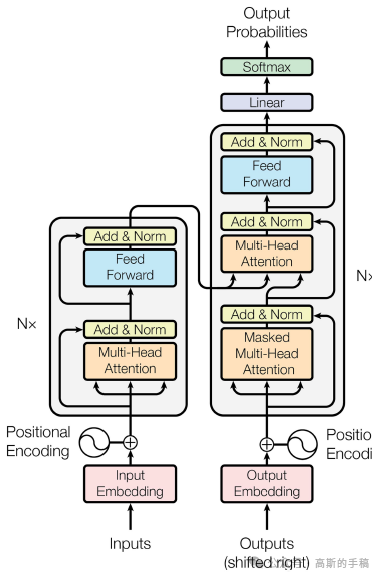
递归神经网络在很长一段时间内是序列转换任务的主导模型,其固有的序列本质阻碍了并行计算。因此,在2017年,谷歌的研究人员提出了一种新的用于序列转换任务的模型架构Transformer,它完全基于注意力机制建立输入与输出之间的全局依赖关系。在训练阶段,Transformer可以并行计算,大大减小了模型训练难度,提高了模型训练效率。Transformer由编码器和解码器两部分构成。其编解码器的子模块为多头注意力MHA和前馈神经网络FFN。此外,Transformer还利用了位置编码、层归一化、残差连接、dropout等技巧来增强模型性能。
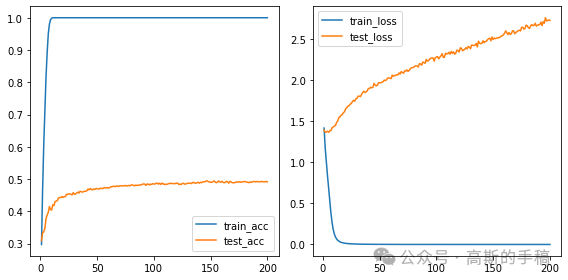
鉴于此,简单地采用Transformer对滚动轴承进行故障诊断,没有经过什么修改,效果不是很好,准确率较低,数据集采用江南大学轴承数据集。
import numpy as npimport torchimport torch.nn as nnimport torch.nn.functional as Fimport torch.optim as optimimport scipy.io as ioimport pandas as pdimport matplotlib.pyplot as pltfrom torch.utils.data import Dataset, DataLoaderd_k = 64d_v = 64class ScaledDotProductAttention(nn.Module):def __init__(self):super(ScaledDotProductAttention, self).__init__()def forward(self, Q, K, V):scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k)weights = nn.Softmax(dim=-1)(scores)context = torch.matmul(weights, V)return context, weights# Q = torch.randint(0, 9, (4, 8, 512)).to(torch.float32)# K = torch.randint(0, 4, (4, 8, 512)).to(torch.float32)# V = torch.randint(0, 2, (4, 8, 512)).to(torch.float32)# SDPA = ScaledDotProductAttention()# context, weights = SDPA(Q, K, V)# print(weights.shape)# print(V.shape)# print(context.shape)d_embedding = 512n_heads = 2batch_size = 32seq_len = 4class MultiHeadAttention(nn.Module):def __init__(self):super(MultiHeadAttention, self).__init__()self.W_Q = nn.Linear(d_embedding, d_k*n_heads)self.W_K = nn.Linear(d_embedding, d_k*n_heads)self.W_V = nn.Linear(d_embedding, d_v*n_heads)self.Linear = nn.Linear(n_heads*d_v, d_embedding)self.layer_norm = nn.LayerNorm(d_embedding)def forward(self, Q, K, V):residual, batch_size = Q, Q.size(0)# input[batch_size, len, d_embedding]->output[batch_size, len, d_k*n_heads]-># {view}->output[batch_size, len, n_heads, d_k]->{transpose}->output[batch_size, n_heads, len, d_k]q_s = self.W_Q(Q).view(batch_size, -1, n_heads, d_k).transpose(1, 2)k_s = self.W_K(K).view(batch_size, -1, n_heads, d_k).transpose(1, 2)v_s = self.W_V(V).view(batch_size, -1, n_heads, d_v).transpose(1, 2)context, weights = ScaledDotProductAttention()(q_s, k_s, v_s)context = context.transpose(1, 2).contiguous().view(batch_size, -1, n_heads*d_v)output = self.Linear(context)output = self.layer_norm(output + residual)return output, weights# data = torch.randn([4, 4, 512])# # [4, 4, 512]->[4, 4, 2, 64]->[4, 2, 4, 64]->{SDPA}->[4, 2, 4, 64]->{transpose}->[4, 4, 2, 64]->{view}->[4, 4, 128]->{Linear}->[4, 4, 512]# # q_s.shape[4, 2, 4, 64]=[batch_size, n_heads, len, d_v]->weight = q_s .* k_s = [4, 2, 4, 4]->weight .* q_v = [4, 2, 4, 64]# MHA = MultiHeadAttention()# output, weights = MHA(data, data, data)# print(output.shape, weights.shape)class PoswiseFeedForward(nn.Module):def __init__(self, d_ff=1024):super(PoswiseFeedForward, self).__init__()self.conv1 = nn.Conv1d(in_channels=d_embedding, out_channels=d_ff, kernel_size=1)self.conv2 = nn.Conv1d(in_channels=d_ff, out_channels=d_embedding, kernel_size=1)self.layernorm = nn.LayerNorm(d_embedding)def forward(self, inputs):residual = inputsoutput = nn.ReLU()(self.conv1(inputs.transpose(1, 2)))output = self.conv2(output).transpose(1, 2)output = self.layernorm(output + residual)return output# data = torch.randn([4, 4, 512])# PFF = PoswiseFeedForward()# output = PFF(data)# print(output.shape)class EncoderLayer(nn.Module):def __init__(self):super(EncoderLayer, self).__init__()self.enc_self_attn = MultiHeadAttention()self.pos_ffn = PoswiseFeedForward()def forward(self, enc_inputs):enc_outputs, attn_weights = self.enc_self_attn(enc_inputs, enc_inputs, enc_inputs)enc_outputs = self.pos_ffn(enc_outputs)return enc_outputs, attn_weightsn_layers = 2num_classes = 4class Encoder(nn.Module):def __init__(self):super(Encoder, self).__init__()self.layers = nn.ModuleList(EncoderLayer() for _ in range(n_layers))self.linear = nn.Linear(seq_len * d_embedding, num_classes)def forward(self, enc_inputs):for layer in self.layers:enc_outputs, _ = layer(enc_inputs)enc_outputs = enc_outputs.view(-1, seq_len * d_embedding)enc_outputs = self.linear(enc_outputs)return enc_outputsfrom sklearn.model_selection import train_test_splitfrom torch.utils.data import TensorDataset, DataLoaderimport osgpu = "0"os.environ['CUDA_DEVICE_ORDER'] = 'PCI_BUS_ID'os.environ['CUDA_VISIBLE_DEVICES'] = gpudevice = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')epochs = 200lr = 0.0001normal_data = torch.cat([torch.Tensor(pd.read_csv('./dataset/n600_3_2.csv', header=None).values[:409600].reshape(-1, seq_len, d_embedding)).to(torch.float32),\torch.Tensor(pd.read_csv('./dataset/n800_3_2.csv', header=None).values[:409600].reshape(-1, seq_len, d_embedding)).to(torch.float32),\torch.Tensor(pd.read_csv('./dataset/n1000_3_2.csv', header=None).values[:409600].reshape(-1, seq_len, d_embedding)).to(torch.float32)], dim=0)inner_data = torch.cat([torch.Tensor(pd.read_csv('./dataset/ib600_2.csv', header=None).values[:409600].reshape(-1, seq_len, d_embedding)).to(torch.float32),\torch.Tensor(pd.read_csv('./dataset/ib800_2.csv', header=None).values[:409600].reshape(-1, seq_len, d_embedding)).to(torch.float32),\torch.Tensor(pd.read_csv('./dataset/ib1000_2.csv', header=None).values[:409600].reshape(-1, seq_len, d_embedding)).to(torch.float32)])outer_data = torch.cat([torch.Tensor(pd.read_csv('./dataset/ob600_2.csv', header=None).values[:409600].reshape(-1, seq_len, d_embedding)).to(torch.float32),\torch.Tensor(pd.read_csv('./dataset/ob800_2.csv', header=None).values[:409600].reshape(-1, seq_len, d_embedding)).to(torch.float32),\torch.Tensor(pd.read_csv('./dataset/ob1000_2.csv', header=None).values[:409600].reshape(-1, seq_len, d_embedding)).to(torch.float32)])roller_data = torch.cat([torch.Tensor(pd.read_csv('./dataset/tb600_2.csv', header=None).values[:409600].reshape(-1, seq_len, d_embedding)).to(torch.float32),\torch.Tensor(pd.read_csv('./dataset/tb800_2.csv', header=None).values[:409600].reshape(-1, seq_len, d_embedding)).to(torch.float32),\torch.Tensor(pd.read_csv('./dataset/tb1000_2.csv', header=None).values[:409600].reshape(-1, seq_len, d_embedding)).to(torch.float32)])data = torch.cat((normal_data, inner_data, outer_data, roller_data), dim=0)labels = torch.cat([torch.Tensor(np.repeat(i, normal_data.shape[0])).to(torch.long) for i in range(num_classes)])x_train, x_test, y_train, y_test = train_test_split(data, labels, test_size=0.3)train_dataset = TensorDataset(x_train, y_train)test_dataset = TensorDataset(x_test, y_test)train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=True)model = Encoder()model = model.to(device)criterion = nn.CrossEntropyLoss()optimizer = optim.Adam(model.parameters(), lr=lr)epoch_counter = []# train_counter = [i for i in range(1, EPOCH + 1)]# test_counter = [i for i in range(1, EPOCH + 1)]train_error = []test_error = []train_acc = []train_loss = []test_acc = []test_loss = []for epoch in range(epochs):print('------------------------\nEpoch: %d------------------------' % (epoch + 1))model.train()sum_loss = 0.0correct = 0.0total = 0.0for i, data in enumerate(train_loader, 0):length = len(train_loader)inputs, labels = datainputs, labels = inputs.to(device), labels.to(device)optimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()sum_loss += loss.item()_, predicted = torch.max(outputs.data, 1) # predicted denotes indice of the max number in output's second dimensiontotal += labels.size(0)correct += predicted.eq(labels.data).cpu().sum()print('[epoch:%d, iter:%d] Loss: %.03f | Acc: %.3f%% ' % (epoch + 1, (i + 1 + epoch * length), sum_loss / (i + 1), 100. * correct / total))epoch_counter.append(epoch+1)train_loss.append(sum_loss / len(train_loader))train_acc.append(correct / total)train_error.append(100. - 100. * correct / total)print("-------------------TEST------------------")with torch.no_grad():real_label = []pred_label = []sum_test_loss = 0.0correct_test = 0total_test = 0 # num of total test samplesfor data in test_loader:model.eval()input_test, label_test = datainput_test, label_test = input_test.to(device), label_test.to(device)output_test = model(input_test)test_losses = criterion(output_test, label_test)sum_test_loss += test_losses.item()_, predicted_test = torch.max(output_test.data, 1)total_test += label_test.size(0)correct_test += (predicted_test == label_test.data).cpu().sum()real_label.append(label_test.cpu())pred_label.append(predicted_test.cpu())test_loss.append(sum_test_loss / len(test_loader))test_acc.append(correct_test / total_test)print('=================测试分类准确率为:%.2f%%===================' % (100. * correct_test / total_test))acc = 100. * correct / totalreal_label = np.array(torch.cat(real_label, dim=0))pred_label = np.array(torch.cat(pred_label, dim=0))def save_np_files(filename, data):np.save('./acc&loss/' + filename + '.npy', np.array(data))save_np_files("real_label", real_label)save_np_files("pred_label", pred_label)save_np_files("epoch", epoch_counter)save_np_files("train_acc", train_acc)save_np_files("train_loss", train_loss)save_np_files("test_acc", test_acc)save_np_files("test_loss", test_loss)train_acc = np.load('./acc&loss/train_acc.npy')train_loss = np.load('./acc&loss/train_loss.npy')test_acc = np.load('./acc&loss/test_acc.npy')test_loss = np.load('./acc&loss/test_loss.npy')epoch = np.load('./acc&loss/epoch.npy')plt.figure(figsize=(8, 4))plt.subplot(121)plt.plot(epoch, train_acc, label="train_acc")plt.plot(epoch, test_acc, label="test_acc")plt.legend()plt.subplot(122)plt.plot(epoch, train_loss, label="train_loss")plt.plot(epoch, test_loss, label="test_loss")plt.legend()plt.tight_layout()plt.show()