HyperDreamBooth是谷歌去年发布的革命性模型训练方法,单张人像20秒内完成模型训练,速度比DreamBooth快25倍,模型小10000倍,但是没有不开源。
今年,论文《HyperDreamBooth: HyperNetworks for Fast Personalization of Text-to-Image Models》被CVPR2024接收,使之再一次进入大众视野,今天就跟大家来介绍一下HyperDreamBooth的相关内容。
首先,HyperDreamBooth是什么呢? 一句话总结,HyperDreamBooth作用和我们已知Textual Inversion、HyperNetwork、DreamBooth、Lora作用类似,是一种用来微调图像生成模型的超级网络。
那么,HyperDreamBooth的优势是什么呢?
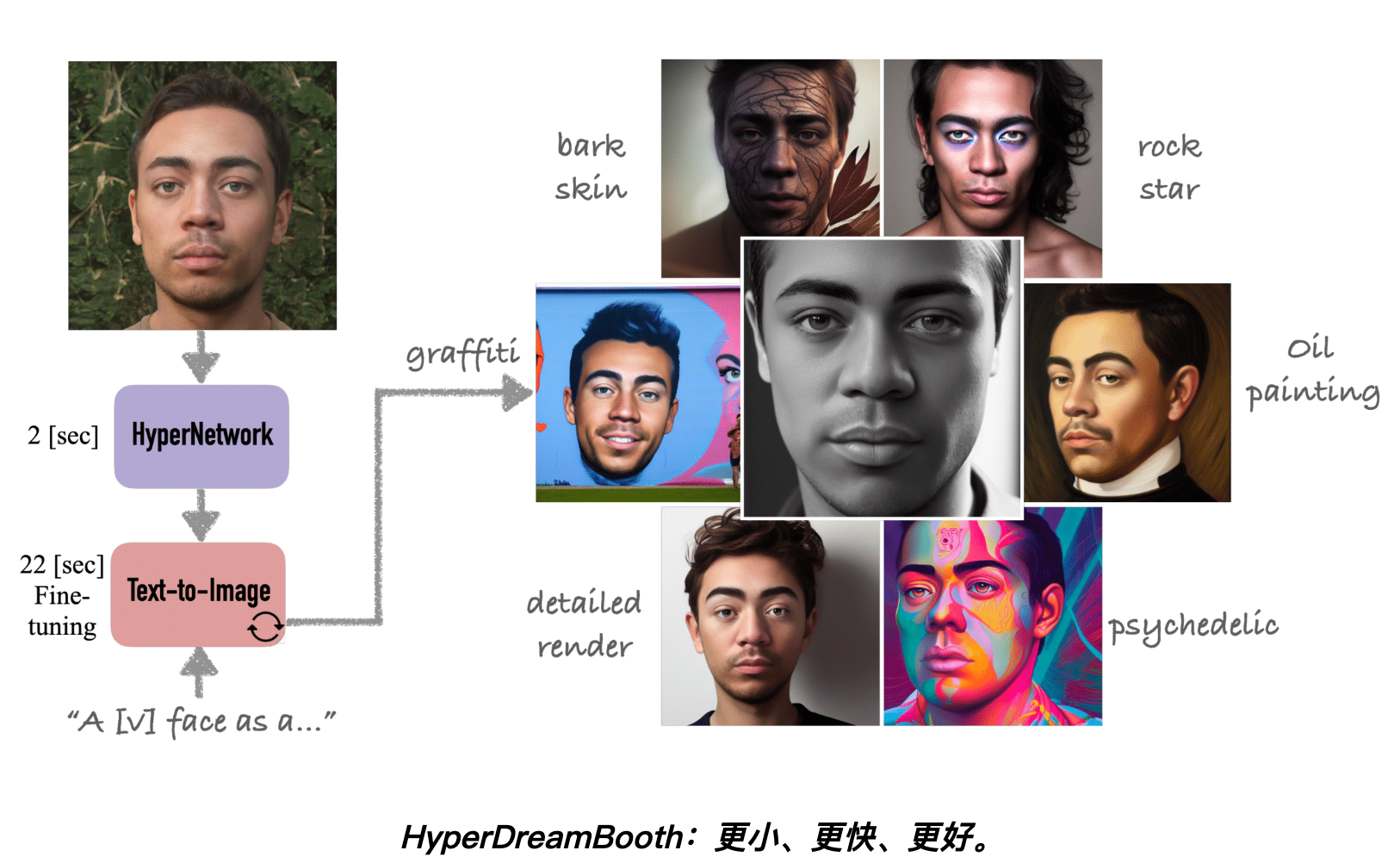
HyperDreamBooth 仅使用一张输入图像20秒内就能完成模型训练,速度比DreamBooth快25倍,比Textual Inversion快125倍。生成的模型比普通DreamBooth模型小10000倍,但是质量和风格多样性与DreamBooth相同。
具体方法是:
-
使用HyperNetwork 生成网络权重子集的初始预测。
-
使用快速微调进行细化,以实现对主题细节的高保真度。HyperDreamBooth方法既能保持模型的完整性和风格多样性,又能紧密贴合主题的本质和细节。
相关链接
Github:https://hyperdreambooth.github.io
Paper:https://arxiv.org/abs/2307.06949
论文阅读

HyperDreamBooth:用于快速个性化文本到图像模型的超级网络
摘要
个性化已成为生成式 AI 领域的一个突出方面,它能够合成不同背景和风格的个人,同时保持其身份的高保真度。然而,个性化过程在时间和内存需求方面存在固有的挑战。微调每个个性化模型需要投入大量的 GPU 时间,并且存储每个主题的个性化模型对存储容量的要求很高。
为了克服这些挑战,我们提出了HyperDreamBooth - 一个超级网络,能够从一个人的单张图像中高效地生成一小组个性化权重。通过将这些权重组合到扩散模型中,再加上快速微调,HyperDreamBooth 可以在各种背景和风格中生成一个人的脸部,具有高主题细节,同时还保留了模型对各种风格和语义修改的关键知识。
我们的方法在大约 20 秒内实现了人脸个性化,比 DreamBooth 快25 倍,比 Textual Inversion 快125 倍,使用最少的一参考图像,具有与 DreamBooth 相同的质量和风格多样性。此外,我们的方法产生的模型比普通 DreamBooth 模型小10000 倍。
贡献
我们的工作旨在解决DreamBooth 的大小和速度问题,同时保持模型完整性、可编辑性和主题保真度。我们提出以下贡献:
-
轻量级 DreamBooth (LiDB) - 个性化的文本转图像模型,其中定制部分大小约为 100KB。这是通过在低秩自适应权重空间内由随机正交不完全基生成的低维权重空间中训练 DreamBooth 模型来实现的。
-
HyperNetwork架构利用轻量级 DreamBooth 配置,并为文本到图像扩散模型中的给定主题生成权重的自定义部分。这些提供了强大的定向初始化,使我们能够进一步微调模型,以便在几次迭代内实现强大的主题保真度。我们的方法比DreamBooth 快25 倍,同时实现类似的性能。
-
我们提出了秩放松微调技术,其中 LoRA DreamBooth 模型的秩在优化过程中得到放松,以实现更高的主题保真度,这使我们能够使用超网络通过初始近似值初始化个性化模型,然后使用秩放松微调来近似高级主题细节。
方法
超网络
我们的方法由 3 个核心元素组成:轻量级 DreamBooth (LiDB)、预测 LiDB 权重的超网络和等级宽松快速微调。
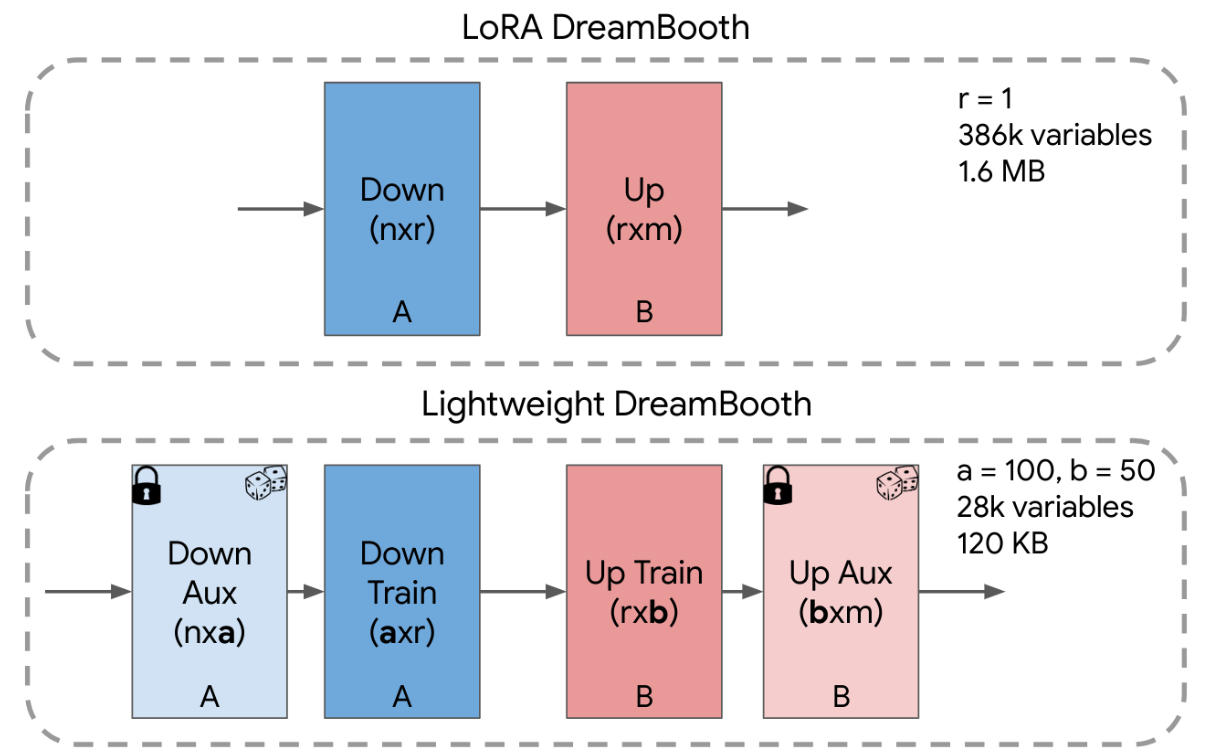
轻量级 DreamBooth (LiDB) 的核心思想是进一步分解 1 级 LoRa 残差的权重空间。具体来说,我们使用 1 级 LoRA 权重空间内的随机正交不完全基来实现这一点。
该方法也可以理解为将 LoRA 的下 (A) 和上 (B) 矩阵进一步分解为两个矩阵,其中“Aux”层使用行正交向量随机初始化并冻结。令人惊讶的是,我们发现,当 a=100 和 b=50 时,我们获得的模型只有 30K 个可训练变量,大小为 120 KB,个性化结果强大且保持主题保真度、可编辑性和风格多样性。
HyperDreamBooth训练和快速微调
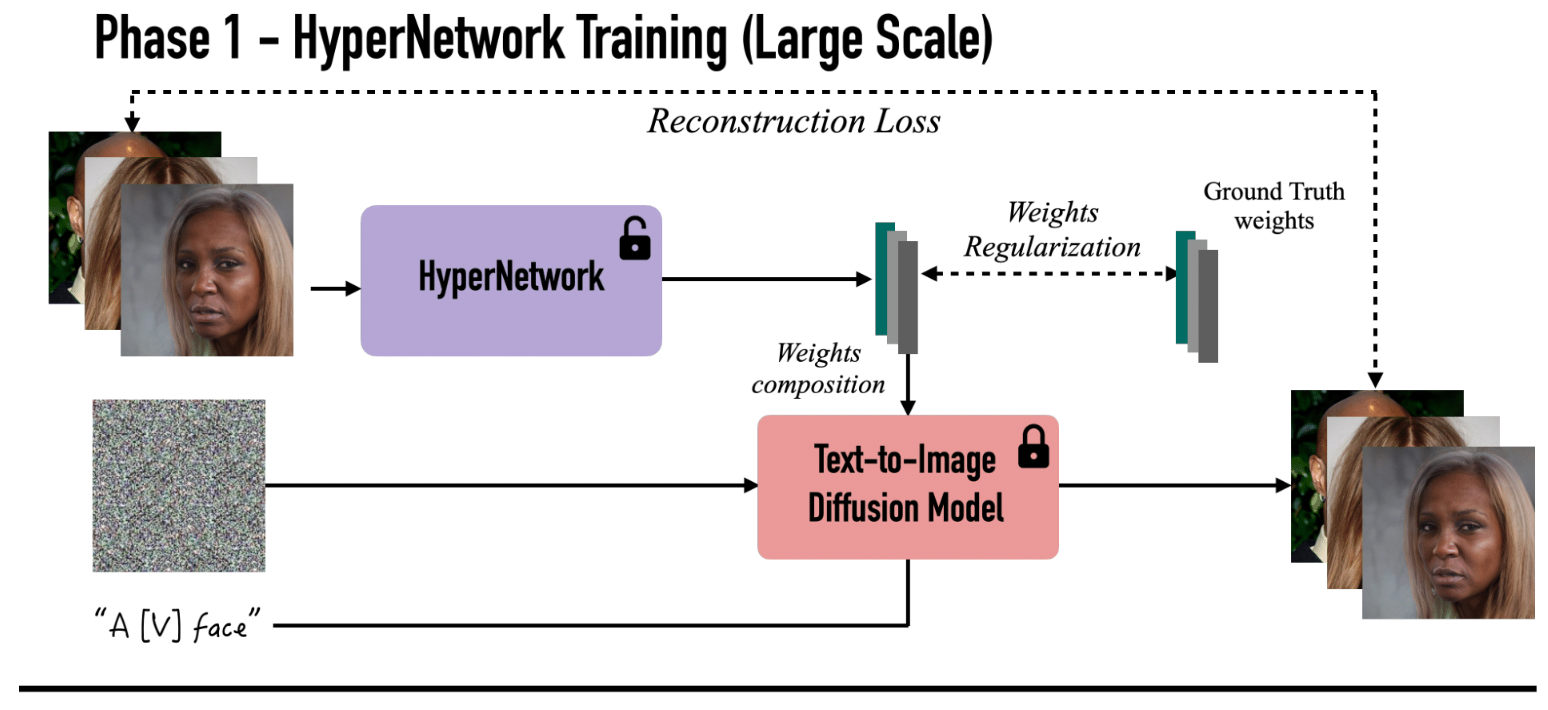
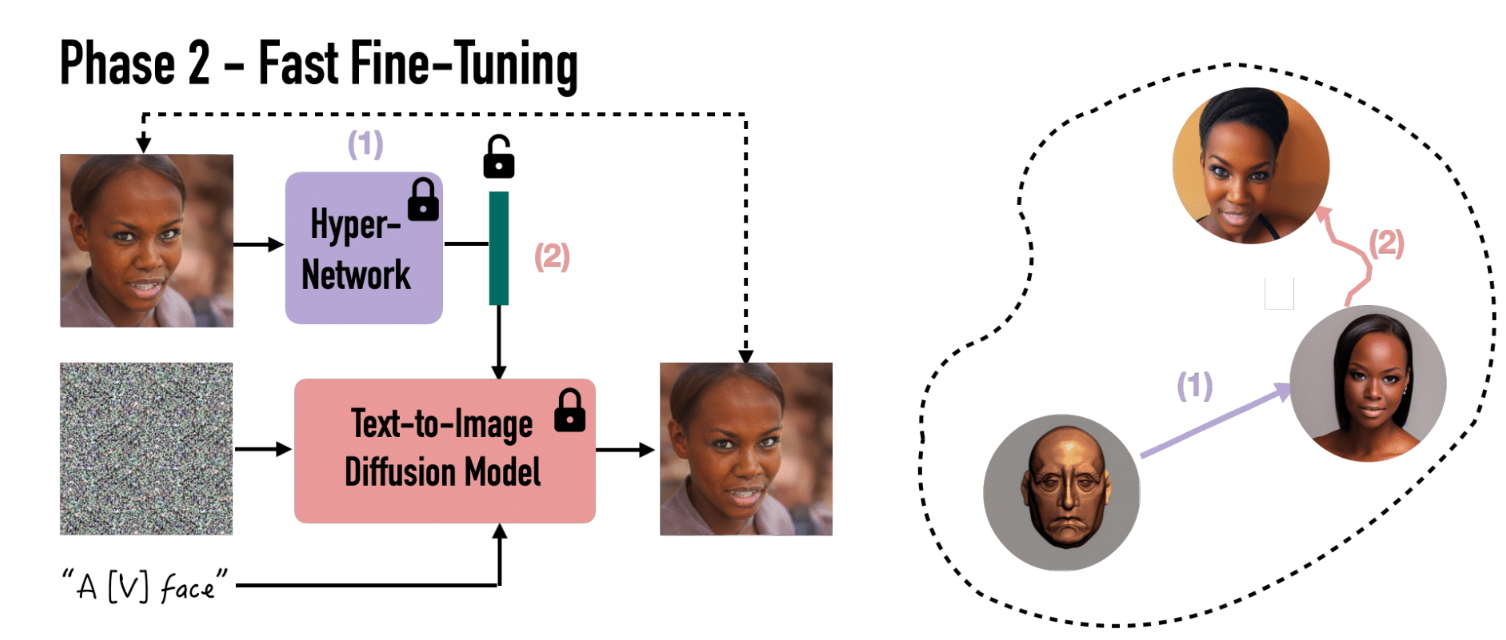
-
第一阶段:训练超网络,根据人脸图像预测网络权重,以便文本到图像的扩散网络根据句子输出人脸“一张 [v] 脸”如果将预测权重应用于它。我们使用预先计算的个性化权重进行监督,使用 L2 损失以及 vanilla 扩散重建损失。
-
第二阶段:给定一张人脸图像,我们的超网络会预测网络权重的初始猜测,然后使用重建损失对其进行微调以提高保真度。
超网络架构
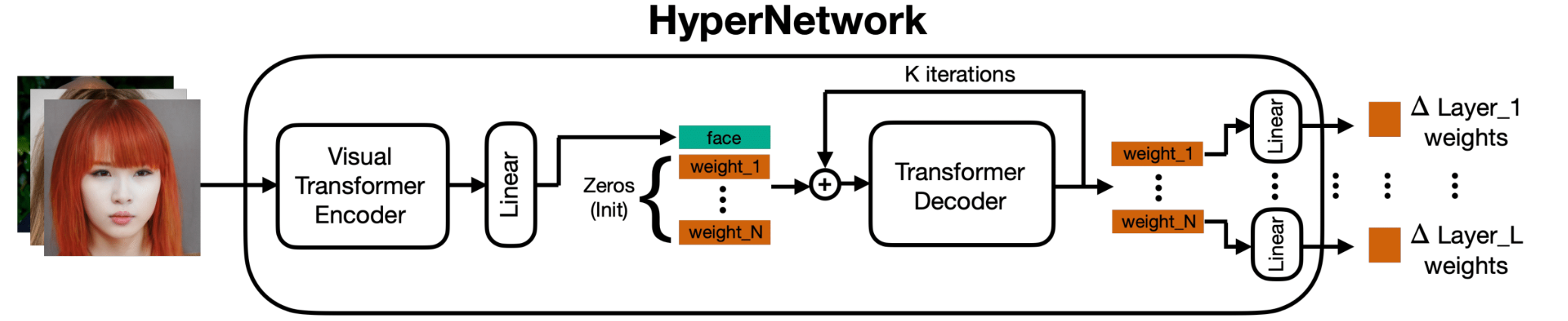
我们的超网络由一个可视化变换器 (ViT) 编码器组成,该编码器将人脸图像转换为潜在人脸特征,然后将其连接到由零启动的潜在层权重特征。变换器解码器接收连接特征的序列,并通过使用增量预测细化初始权重以迭代方式预测权重特征的值。通过将解码器输出传递到可学习的线性层,可以获得将添加到扩散网络的最终层权重增量。
变换器解码器非常适合这种类型的权重预测任务,因为扩散 UNet 或文本编码器的输出顺序依赖于层的权重,因此为了个性化模型,不同层的权重是相互依赖的。在以前的工作中,这种依赖关系在超网络中没有严格建模,而使用具有位置嵌入的变换器解码器,可以建模这种位置依赖关系 - 类似于语言模型变换器中单词之间的依赖关系。
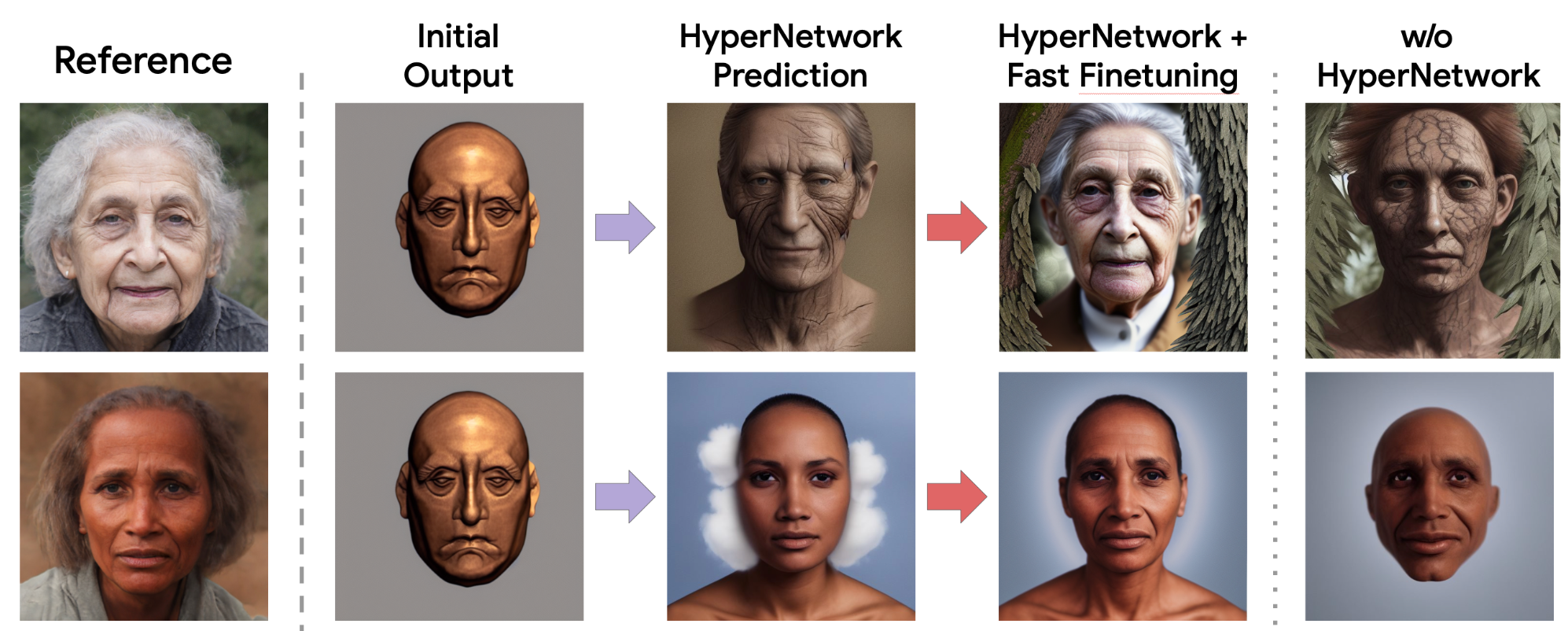
HyperNetwork + Fast Finetuning 取得了很好的效果。下面我们针对每个参考(行)展示了初始超网络预测(HyperNetwork Prediction 列)的输出,以及 HyperNetwork 预测和快速微调(HyperNetwork + Fast Finetuning)后的结果。我们还展示了没有 HyperNetwork 预测组件的生成结果,以证明其重要性。
实验
结果展示
我们的方法可以生成各种主题的新颖艺术和风格化结果(如输入图像所示,左侧),具有相当大的可编辑性,同时保持了主题主要面部特征的完整性。输出图像带有以下标题(从左上到右下):“Instagram 上的 [V] 脸自拍照”、“皮克斯角色的 [V] 脸”、“皮肤粗糙的 [V] 脸”、“摇滚明星的 [V] 脸}。最右边:专业拍摄的 [V] 脸”。

结果比较
我们针对两种不同的身份和五种不同的文体提示,比较了我们的方法 (HyperDreamBooth)、DreamBooth 和 Textual Inversion 的随机生成样本。我们观察到,我们的方法在保留身份的同时通常实现了非常强的可编辑性,在单参考方案中通常超越了竞争方法。

社会影响
这项工作旨在为用户提供一种工具,以增强他们的创造力和通过直观的方式通过创作表达自己的能力。然而,先进的图像生成方法会以复杂的方式影响社会。我们提出的方法继承了许多可能影响此类图像生成的担忧,包括改变敏感的个人特征,如肤色、年龄和性别,以及重现预先训练模型的训练数据中已经存在的不公平偏见。我们工作中使用的底层开源预训练模型 Stable Diffusion 表现出其中一些担忧。与我们的工作相关的所有担忧都出现在最近的个性化工作中,唯一的增加的风险是我们的方法比以前的工作更高效、更快。
特别是,我们在实验中没有发现与以前关于偏见或有害内容的工作有任何不同,并且我们定性地发现我们的方法在不同种族、年龄和其他重要的个人特征中同样有效。然而,未来在生成建模和模型个性化方面的研究必须继续调查和重新验证这些问题。
结论
在这项工作中,我们提出了HyperDreamBooth一种基于文本到图像扩散模型的快速轻量级主题驱动的个性化新方法。我们的方法利用一个超级网络来生成具有后续快速秩放松的扩散模型的轻量级DreamBooth (LiDB)参数与DreamBooth等相比,实现了尺寸和速度的显著减小的微调 基于优化的个性化工作。我们已经证明,我们的方法可以产生高质量的不同风格、不同语义修饰的不同面孔图像。