小鹏汽车一面面经
公众号:阿Q技术站
来源:职言详情页 (maimai.cn)
文章目录
- 小鹏汽车一面面经
- 1、String类型为什么不可变?
- 1. 安全性
- 2. 缓存和性能优化
- 3. 哈希码缓存
- 4. 类设计和接口
- 5. 简单性和可读性
- 2、在浏览器中输入url地址到显示主页的过程?
- 1. 输入 URL 并解析
- 2. DNS 解析
- 3. 建立 TCP 连接
- 4. 发送 HTTP 请求
- 5. 服务器处理请求并返回响应
- 6. 浏览器接收响应并开始渲染
- 7. 显示主页
- 3、为什么要三次握手?二次握手或者四次握手会怎么样?
- 三次握手
- 为什么需要三次握手?
- 二次握手的问题
- 四次握手的问题
- 4、日常开发中用过哪些设计模式,具体的应用场景是什么?
- 5、 redis 的并发竞争 Key 问题?
- 1. 使用 Redis 事务
- 2. 使用 Lua 脚本
- 3. 使用分布式锁
- 4. 使用 Redis 乐观锁
- 6、redis 常见数据结构以及使用场景分析?
- 1. 字符串(String)
- 2. 列表(List)
- 3. 集合(Set)
- 4. 有序集合(Sorted Set)
- 5. 哈希表(Hash)
- 使用场景分析
- 7、redis 持久化机制(怎么保证 redis 挂掉之后再重启数据可以进行恢复)?
- RDB 持久化
- RDB 的优点:
- RDB 的缺点:
- AOF 持久化
- AOF 的优点:
- AOF 的缺点:
- 选择持久化机制
- 8、如何理解事务?如何理解事务的隔离等级?
- 事务的特性(ACID)
- 事务的隔离级别
- 9、binlog、undelog、redolog的区别是什么?为什么不推荐使用长事务?
- 1. binlog(二进制日志)
- 2. undolog(回滚日志)
- 3. redo log(重做日志)
- 不推荐使用长事务的原因
- 10、算法题:如何判断链表中存在环?
- 思路
- 参考代码
- Java

1、String类型为什么不可变?
1. 安全性
不可变对象是线程安全的,因为它们的状态在创建之后无法更改。多线程环境中,不需要对不可变对象进行同步处理,可以避免线程安全问题。例如,多个线程可以安全地共享和使用同一个 String 对象而不需要同步。
2. 缓存和性能优化
由于 String 对象不可变,它们可以被安全地缓存。例如,字符串常量池(String Pool)利用了不可变性的特性,通过缓存相同的字符串对象来减少内存开销和提高性能。在 Java 中,当创建一个字符串字面量时,JVM 会先检查字符串池中是否已经存在相同的字符串,如果存在则直接返回该对象的引用,否则创建新的字符串对象并放入池中。
3. 哈希码缓存
不可变对象的哈希码在对象创建时计算,并且在整个生命周期中不变。因此,不可变对象可以安全地缓存哈希码,提高哈希表(如 HashMap)的性能。对于可变对象,每次哈希码计算都可能不同,不能进行这种优化。
4. 类设计和接口
不可变对象可以被安全地传递、共享和缓存,而无需担心对象的状态会被外部修改。这使得不可变对象在设计类和接口时更容易使用。例如,String 类型可以作为安全的键(key)用于哈希表(如 HashMap)中。
5. 简单性和可读性
不可变对象的行为是确定的、可预测的。这简化了代码的理解和维护,因为开发人员可以放心对象的状态不会在不可预见的地方被修改。
2、在浏览器中输入url地址到显示主页的过程?
1. 输入 URL 并解析
当用户在浏览器的地址栏中输入 URL(如 http://www.xxx.com)并按下回车键时,浏览器开始处理该请求。
2. DNS 解析
浏览器首先需要将域名(如 www.example.com)解析为 IP 地址。这个过程包括以下步骤:
- 浏览器查找 DNS 缓存,看看是否已经缓存了该域名的 IP 地址。
- 如果浏览器缓存中没有找到,操作系统会查找其本地 DNS 缓存。
- 如果操作系统缓存中也没有找到,操作系统会向配置的 DNS 服务器发送查询请求。
- DNS 服务器查询解析链路,最终将域名解析为 IP 地址,并返回给操作系统。
- 操作系统将 IP 地址返回给浏览器。
3. 建立 TCP 连接
有了 IP 地址后,浏览器与服务器建立 TCP 连接。这个过程包括三次握手(Three-way handshake):
- 浏览器发送一个 SYN 包(同步序列编号)到服务器。
- 服务器响应一个 SYN-ACK 包(同步确认)。
- 浏览器发送一个 ACK 包(确认),TCP 连接建立。
4. 发送 HTTP 请求
TCP 连接建立后,浏览器会向服务器发送一个 HTTP 请求。
5. 服务器处理请求并返回响应
服务器接收到请求后,处理请求,生成响应内容,并返回给浏览器。响应内容包括 HTTP 状态码、响应头和响应主体。
6. 浏览器接收响应并开始渲染
浏览器接收 HTTP 响应后,开始渲染页面。这个过程包括以下步骤:
- 解析 HTML:浏览器解析 HTML 内容,构建 DOM 树。
- 解析 CSS:如果 HTML 中包含 CSS 文件或内嵌样式,浏览器会解析 CSS 内容,构建 CSSOM 树(CSS 对象模型)。
- 解析 JavaScript:如果 HTML 中包含 JavaScript 文件或内嵌脚本,浏览器会解析并执行 JavaScript 代码,可能会修改 DOM 树或 CSSOM 树。
- 构建渲染树:根据 DOM 树和 CSSOM 树,浏览器构建渲染树(Render Tree),这是一种表示页面布局和样式的内部表示。
- 布局(Layout):根据渲染树计算每个节点在屏幕上的位置和大小。这一步称为布局或回流(Reflow)。
- 绘制(Painting):将渲染树的每个节点绘制到屏幕上,这一步称为绘制或重绘(Repaint)。
7. 显示主页
经过上述步骤后,浏览器将渲染的页面内容显示给用户,用户可以看到主页。
3、为什么要三次握手?二次握手或者四次握手会怎么样?
三次握手
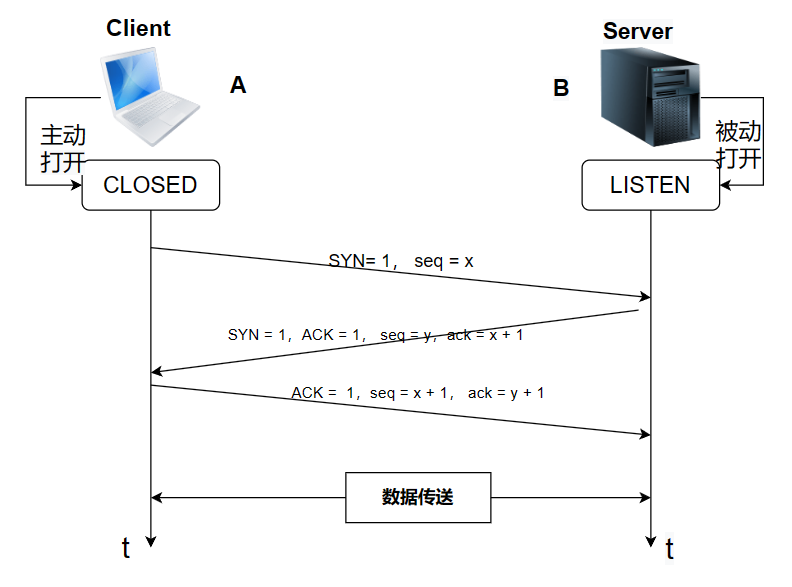
在建立连接之前,Client处于CLOSED状态,而Server处于LISTEN的状态。
- 第一次握手(SYN-1):
- 客户端发送一个带有 SYN 标志的 TCP 报文段给服务器,表示客户端请求建立连接。
- 客户端选择一个初始序列号(ISN)并将其放入报文段中,进入 SYN_SENT 状态。
- 第二次握手(SYN + ACK):
- 服务器收到客户端发送的 SYN 报文段后,如果同意建立连接,会发送一个带有 SYN 和 ACK 标志的报文段给客户端,表示服务器接受了客户端的请求,并带上自己的 ISN。
- 服务器进入 SYN_RCVD 状态。
- 第三次握手(ACK):
- 客户端收到服务器发送的 SYN+ACK 报文段后,会发送一个带有 ACK 标志的报文段给服务器,表示客户端确认了服务器的响应。
- 客户端和服务器都进入 ESTABLISHED 状态,连接建立成功,可以开始进行数据传输。
为什么需要三次握手?
- 确保双方都能发送和接收数据:
- 第一次握手确认客户端的发送能力和服务器的接收能力。
- 第二次握手确认服务器的发送能力和客户端的接收能力。
- 第三次握手确认客户端的发送能力和服务器的接收能力。
- 防止旧的连接请求误导双方:
- 通过三次握手,双方都能确认对方的状态是最新的,有效避免了网络中的旧的、延迟的SYN包造成的错误连接。
- 防止重复数据包干扰:
- 三次握手确保双方都能有效处理重复的数据包,并建立一个唯一的连接。
二次握手的问题
如果采用二次握手(即省略第三次握手),可能会导致以下问题:
- 旧的重复连接请求:旧的 SYN 包在网络中延迟传输,服务器可能误认为是新的连接请求,发送 SYN-ACK 包,但客户端不知道这个连接,可能导致连接建立异常。
- 无法确认客户端的接收能力:服务器在发送 SYN-ACK 包后,不知道客户端是否已成功收到,如果客户端未收到,服务器会一直等待 ACK 包,导致资源浪费。
四次握手的问题
如果采用四次握手(即增加额外的确认步骤),虽然能增加连接建立的可靠性,但也会带来额外的开销和复杂性,增加连接建立的延迟。TCP 设计中,三次握手已经足够确保连接的可靠性和双方通信的能力,再增加步骤则显得不必要且低效。
4、日常开发中用过哪些设计模式,具体的应用场景是什么?
5、 redis 的并发竞争 Key 问题?
Redis 在高并发场景下并发竞争 Key 通常发生在多个客户端同时对同一个 Key 进行读写操作时,可能会导致数据不一致或竞争条件。
1. 使用 Redis 事务
Redis 事务可以确保一系列命令按顺序执行,避免并发插入。
import redis.clients.jedis.Jedis;
import redis.clients.jedis.Transaction;
public class RedisTransactionExample {
public static void main(String[] args) {
Jedis jedis = new Jedis("localhost", 6379);
try {
// 开启事务
Transaction transaction = jedis.multi();
transaction.set("key1", "value1");
transaction.incr("key2");
// 提交事务
transaction.exec();
} catch (Exception e) {
e.printStackTrace();
} finally {
jedis.close();
}
}
}
2. 使用 Lua 脚本
Lua 脚本可以确保在服务器端原子性地执行一系列操作。
import redis.clients.jedis.Jedis;
import redis.clients.jedis.Response;
import redis.clients.jedis.Transaction;
public class RedisLuaScriptExample {
public static void main(String[] args) {
Jedis jedis = new Jedis("localhost", 6379);
String luaScript =
"local current = redis.call('GET', KEYS[1]) " +
"if current == ARGV[1] then " +
" return redis.call('SET', KEYS[1], ARGV[2]) " +
"else " +
" return nil " +
"end";
String result = (String) jedis.eval(luaScript, 1, "key1", "old_value", "new_value");
if (result == null) {
System.out.println("Key value mismatch or key does not exist.");
} else {
System.out.println("Script executed successfully.");
}
jedis.close();
}
}
3. 使用分布式锁
可以使用分布式锁来避免并发竞争。Redisson 是一个 Redis 客户端,可以用于实现分布式锁。
import org.redisson.Redisson;
import org.redisson.api.RLock;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
import java.util.concurrent.TimeUnit;
public class RedisDistributedLockExample {
public static void main(String[] args) {
Config config = new Config();
config.useSingleServer().setAddress("redis://localhost:6379");
RedissonClient redisson = Redisson.create(config);
RLock lock = redisson.getLock("myLock");
try {
// 尝试获取锁,等待时间为 10 秒,锁超时时间为 10 秒
if (lock.tryLock(10, 10, TimeUnit.SECONDS)) {
try {
// 加锁成功,执行相关业务逻辑
System.out.println("Lock acquired.");
} finally {
// 释放锁
lock.unlock();
}
} else {
System.out.println("Failed to acquire lock.");
}
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
redisson.shutdown();
}
}
}
4. 使用 Redis 乐观锁
Redis 的 WATCH 命令可以用来实现乐观锁,监视一个或多个 Key,在事务执行前检查这些 Key 是否被修改。
import redis.clients.jedis.Jedis;
import redis.clients.jedis.Transaction;
public class RedisOptimisticLockExample {
public static void main(String[] args) {
Jedis jedis = new Jedis("localhost", 6379);
while (true) {
jedis.watch("key1");
int value = Integer.parseInt(jedis.get("key1"));
Transaction transaction = jedis.multi();
transaction.set("key1", String.valueOf(value + 1));
if (transaction.exec() != null) {
break;
}
}
jedis.close();
}
}
6、redis 常见数据结构以及使用场景分析?
1. 字符串(String)
- 使用场景:存储单个值,如用户信息、计数器等。
- 示例命令:SET、GET、INCR、DECR。
SET user:1 "{name: 'Alice', age: 30}"
GET user:1
INCR counter
2. 列表(List)
- 使用场景:存储有序的字符串列表,如消息队列、最新消息列表等。
- 示例命令:LPUSH、RPUSH、LPOP、RPOP、LRANGE。
LPUSH messages "Hello"
RPUSH messages "World"
LPOP messages
LRANGE messages 0 -1
3. 集合(Set)
- 使用场景:存储无序的唯一元素,如标签、好友列表等。
- 示例命令:SADD、SREM、SMEMBERS、SISMEMBER。
SADD tags "redis"
SADD tags "database"
SMEMBERS tags
SISMEMBER tags "redis"
4. 有序集合(Sorted Set)
- 使用场景:存储有序的唯一元素,每个元素都关联一个分数,常用于排行榜、计分系统等。
- 示例命令:ZADD、ZRANGE、ZREVRANGE、ZSCORE。
ZADD leaderboard 100 "Alice"
ZADD leaderboard 200 "Bob"
ZRANGE leaderboard 0 -1 WITHSCORES
ZREVRANGE leaderboard 0 -1 WITHSCORES
5. 哈希表(Hash)
- 使用场景:存储对象的字段和值,如存储用户对象、文章对象等。
- 示例命令:HSET、HGET、HMSET、HGETALL。
HSET user:1 name "Alice"
HSET user:1 age 30
HMSET user:2 name "Bob" age 25
HGET user:1 name
HGETALL user:1
使用场景分析
- 缓存:使用字符串存储缓存数据,列表存储消息队列,集合存储用户标签等。
- 计数器:使用字符串的 INCR 命令实现计数器功能。
- 会话管理:使用哈希表存储用户会话信息,如用户登录状态、权限等。
- 发布订阅:使用发布订阅功能实现消息广播。
- 排行榜:使用有序集合存储用户分数,实现排行榜功能。
- 实时统计:使用计数器、有序集合等数据结构实现实时统计功能。
7、redis 持久化机制(怎么保证 redis 挂掉之后再重启数据可以进行恢复)?
RDB 持久化
RDB 持久化是通过将 Redis 在内存中的数据以快照的形式写入到硬盘的一个文件中。RDB 持久化可以手动执行,也可以通过配置自动执行。当 Redis 需要持久化数据时,它会 fork 出一个子进程来处理持久化工作,父进程继续处理客户端请求。
RDB 的优点:
- RDB 文件是一个紧凑的二进制文件,适合用于备份和恢复数据。
- RDB 持久化对 Redis 的性能影响较小,因为持久化过程由子进程完成,不会阻塞主进程处理客户端请求。
RDB 的缺点:
- 如果 Redis 挂掉时还没有执行 RDB 持久化,会丢失最后一次持久化后的数据。
- 执行 RDB 持久化时,会阻塞 Redis 主进程,可能会影响服务的响应速度。
AOF 持久化
AOF 持久化是通过将 Redis 的写操作以追加的方式记录到一个文件中。当 Redis 重启时,会重新执行 AOF 文件中的写操作来恢复数据。AOF 文件中的写操作以 Redis 协议格式保存,方便阅读和恢复。
AOF 的优点:
- AOF 文件是一个文本文件,可以直接查看和修改,方便调试和恢复。
- AOF 持久化记录了每次写操作,因此可以尽可能地减少数据丢失的风险。
AOF 的缺点:
- AOF 文件比 RDB 文件大,恢复速度比 RDB 慢。
- AOF 持久化对于写密集型工作负载可能会有一定的性能影响。
选择持久化机制
- 如果对数据的完整性要求很高,可以选择使用 AOF 持久化。
- 如果对数据的实时性要求较高,可以选择使用 RDB 持久化。
- 也可以同时开启两种持久化机制,这样可以在 Redis 重启时先使用 AOF 文件恢复数据,然后再使用 RDB 文件进一步恢复数据,以提高数据的完整性和实时性。
8、如何理解事务?如何理解事务的隔离等级?
事务是指一组操作被视为一个不可分割的工作单元,要么全部执行成功,要么全部执行失败。在数据库中,事务是指一系列数据库操作组成的逻辑工作单元,这些操作要么全部执行成功,要么全部不执行,不会出现部分执行成功的情况。
事务的特性(ACID)
- 原子性(Atomicity):事务是一个原子操作,要么全部成功,要么全部失败回滚,不会出现部分执行的情况。
- 一致性(Consistency):事务执行前后,数据库的状态必须保持一致性,即数据库从一个一致性状态转变到另一个一致性状态。
- 隔离性(Isolation):事务的执行不受其他事务的影响,每个事务都感觉不到其他事务同时在执行。
- 持久性(Durability):事务一旦提交,其结果就是永久性的,即使系统崩溃,数据库也能够恢复到提交事务后的状态。
事务的隔离级别
事务的隔离级别定义了一个事务内部的操作对其他事务的可见性,以及其他事务对该事务的影响程度。常见的隔离级别有:
- 读未提交(Read Uncommitted):事务中的修改,即使没有提交,对其他事务也是可见的。这种隔离级别会导致脏读、不可重复读和幻读的问题。
- 读已提交(Read Committed):事务只能看到已经提交的事务所做的修改。这种隔离级别解决了脏读问题,但仍可能出现不可重复读和幻读的问题。
- 可重复读(Repeatable Read):事务执行期间看到的数据保持一致,即使其他事务对数据进行了修改,事务也只能看到自己开始前的数据状态。这种隔离级别解决了不可重复读问题,但仍可能出现幻读问题。
- 串行化(Serializable):事务顺序执行,事务之间完全隔离,可以避免脏读、不可重复读和幻读的问题,但会降低并发性能。
9、binlog、undelog、redolog的区别是什么?为什么不推荐使用长事务?
1. binlog(二进制日志)
- 作用:记录对数据库执行的所有更改操作,包括增删改操作,但不包括查询操作。
- 使用场景:用于数据库的备份、恢复和复制。
- 优点:可以通过 replay binlog 的方式将主库的操作同步到从库,实现数据的复制和主从架构。
- 缺点:对于每次操作都会记录一条日志,可能会导致 binlog 文件较大。
2. undolog(回滚日志)
- 作用:记录事务执行过程中对数据页所做的所有修改,用于事务的回滚操作。
- 使用场景:用于保证事务的原子性。
- 优点:可以确保事务执行过程中出现问题时,可以回滚到事务开始前的状态。
- 缺点:增加了数据库的存储开销。
3. redo log(重做日志)
- 作用:记录事务对数据库所做的修改,但与 undolog 不同的是,redo log 是物理日志,记录的是数据页的修改操作,而不是逻辑修改。
- 使用场景:用于保证事务的持久性,即事务提交后,数据的修改是永久性的。
- 优点:可以确保数据库在崩溃后可以通过重做日志来恢复到事务提交后的状态。
- 缺点:增加了数据库的 I/O 开销。
不推荐使用长事务的原因
- 锁资源:长事务持有的锁资源会导致其他事务无法访问需要的资源,影响数据库的并发性能。
- 内存占用:长事务可能导致数据库需要维护的 undo 日志和 redo 日志过大,占用大量内存空间。
- 数据一致性:长事务会增加系统发生故障的风险,一旦系统崩溃,长事务可能无法正常提交或回滚,导致数据不一致。
10、算法题:如何判断链表中存在环?
思路
- 定义两个指针
slow和fast,初始时都指向链表的头节点head。 slow每次向后移动一个节点,fast每次向后移动两个节点。这样,如果链表中有环,fast最终会追上slow。- 如果
fast为nullptr或者fast->next为nullptr,则说明链表中不存在环,返回false。 - 如果
fast和slow相遇,则说明链表中存在环,返回true。
参考代码
Java
class ListNode {
int val;
ListNode next;
ListNode(int x) {
val = x;
next = null;
}
}
public class Solution {
public boolean hasCycle(ListNode head) {
// 定义快慢指针,并初始化为链表头节点
ListNode slow = head;
ListNode fast = head;
// 使用快慢指针判断链表中是否存在环
while (fast != null && fast.next != null) {
slow = slow.next; // 慢指针每次移动一步
fast = fast.next.next; // 快指针每次移动两步
if (slow == fast) { // 如果快慢指针相遇,说明存在环
return true;
}
}
// 如果快指针到达链表尾部,说明不存在环
return false;
}
}
public class Main {
public static void main(String[] args) {
// 创建一个有环的链表
ListNode head = new ListNode(3);
head.next = new ListNode(2);
head.next.next = new ListNode(0);
head.next.next.next = new ListNode(-4);
head.next.next.next.next = head.next; // 尾节点连接到第二个节点,形成环
Solution sol = new Solution();
System.out.println(sol.hasCycle(head)); // 输出 true,表示链表中存在环
}
}



![[AI StoryDiffusion] 创造神奇故事,AI漫画大乱斗!](https://img-blog.csdnimg.cn/img_convert/c66405c7434764a89d9a40b411cddc50.jpeg)