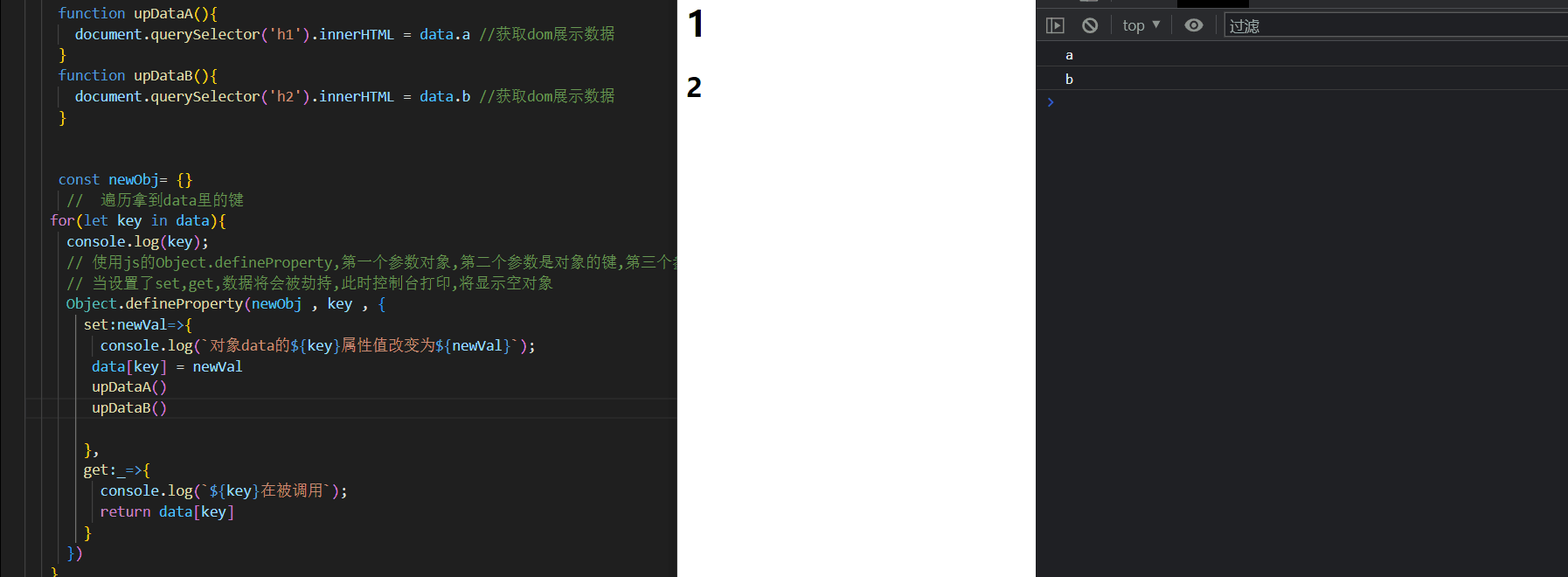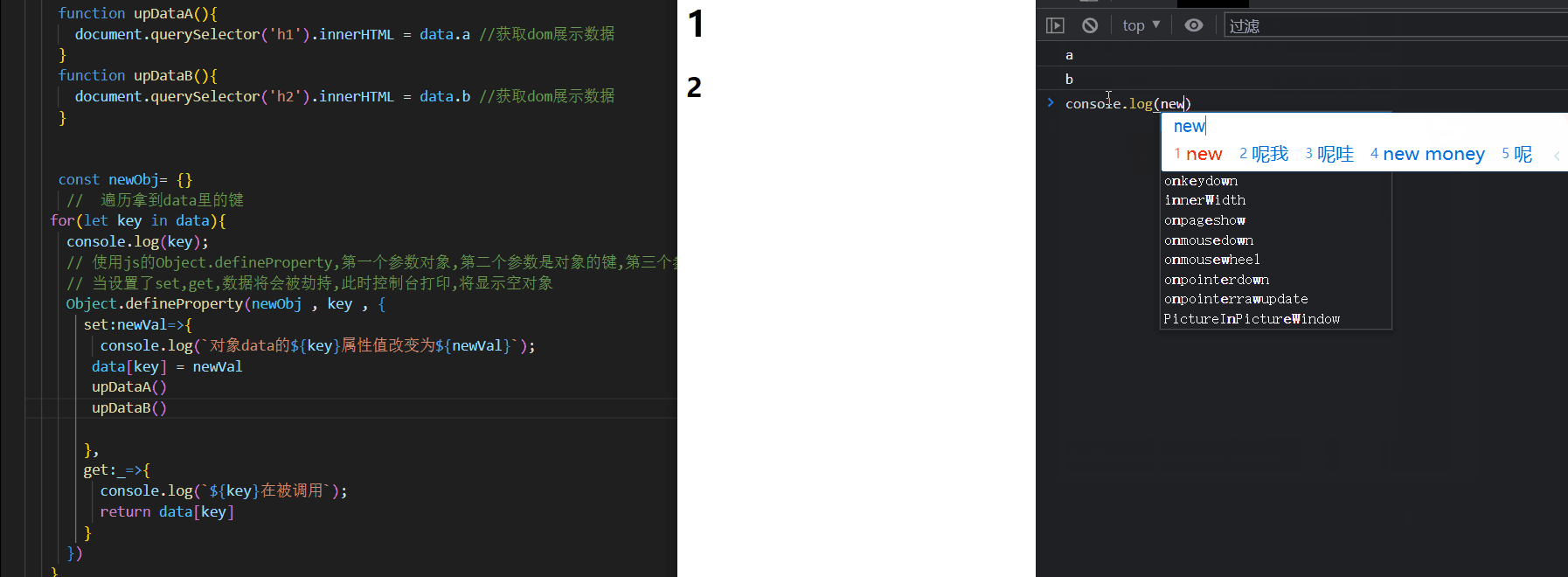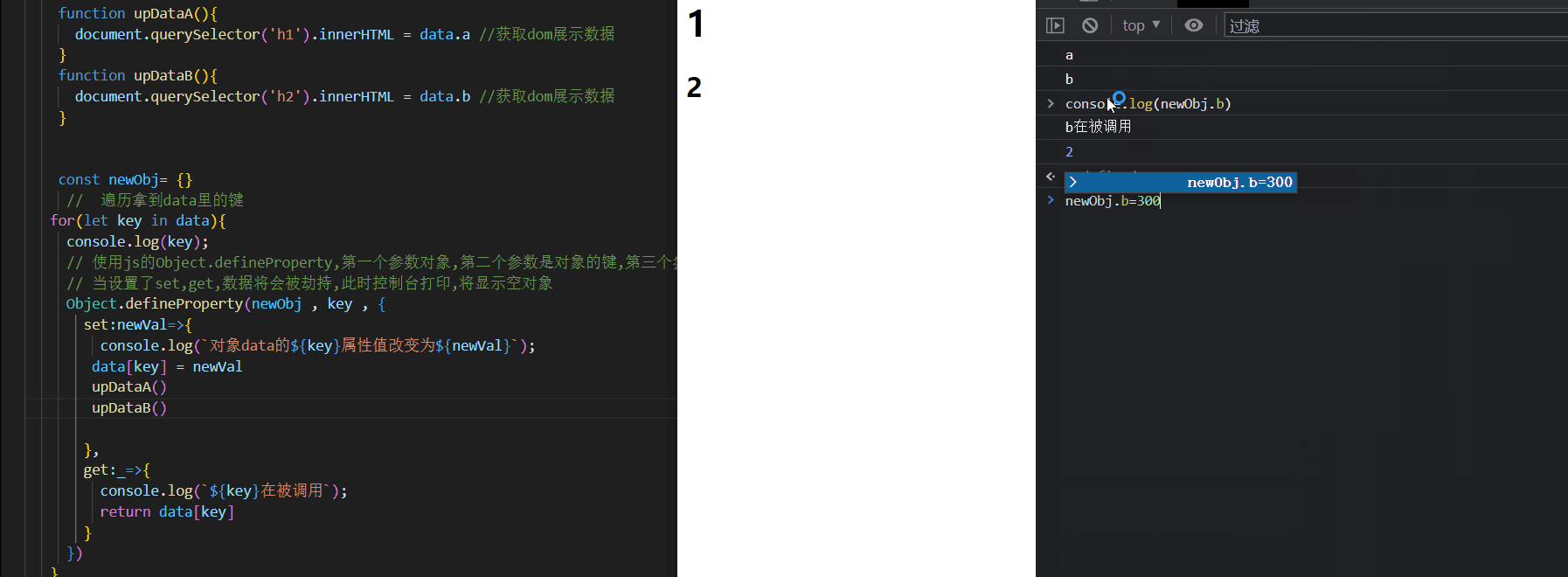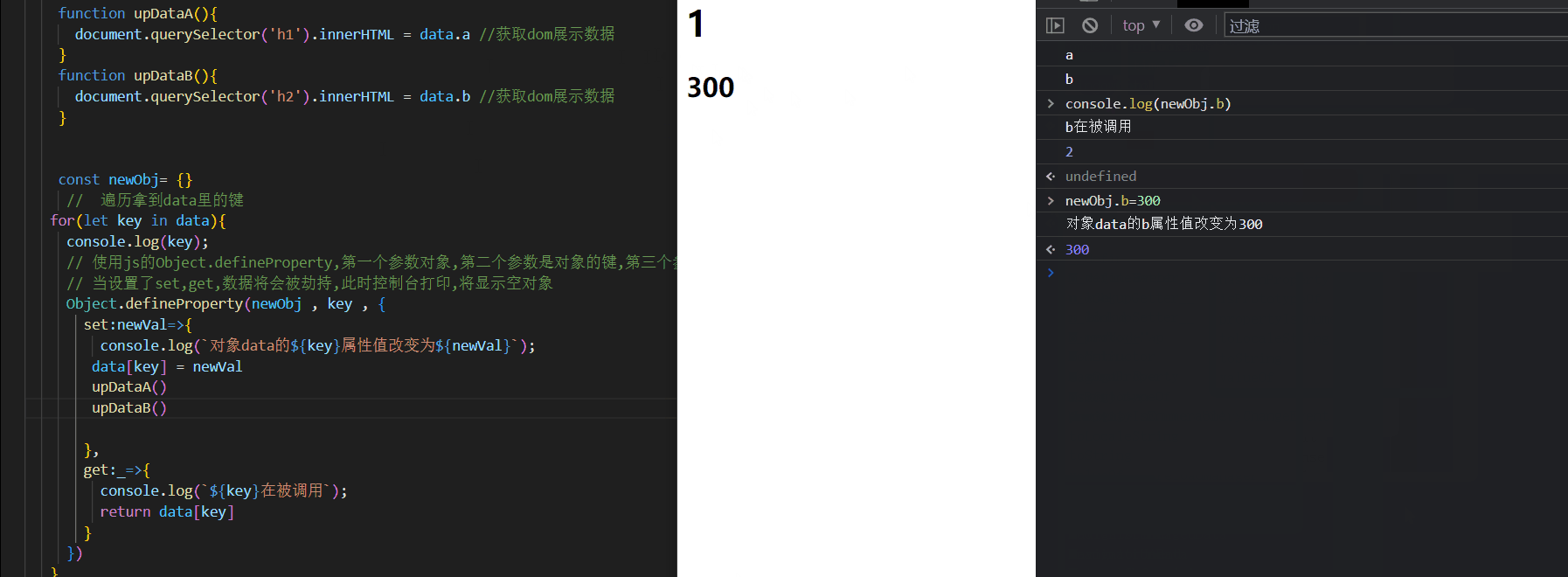
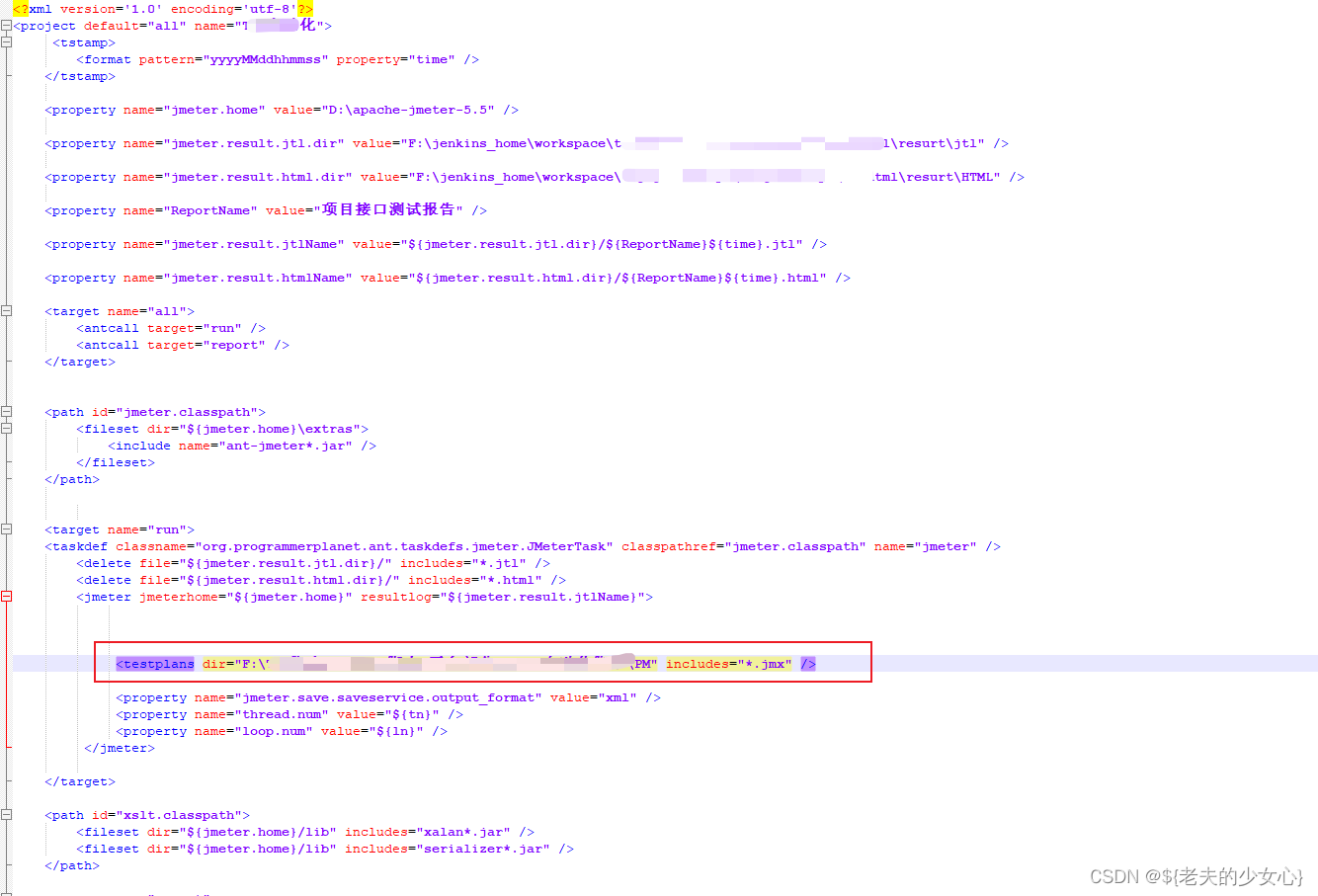
YOLO系列
- 1. 不同阶段算法优缺点分析
- 2. IOU指标计算
- 3. MAP指标计算
- **指标分析**
- 如何计算MAP
- 4 YOLOv1
- 4.1 YOLOv1核心思想
- 4.2 YOLOv1网络架构
- 那么,7 * 7 * 30的输出是怎么来呢?
- 4.3 损失函数
- 4.3.1 位置误差
- 4.3.2 置信度误差(含object)
- 4.3.3 置信度误差(不含object)
- 4.3.4 分类误差
- 4.4 总结
1. 不同阶段算法优缺点分析
检测任务分为两种类型:
-
单阶段检测算法:YOLO系列
最核心的优势:速度非常快,适合做实时检测任务! 但是缺点也是有的,效果通常情况下不会太好!
-
二阶段检测算法:Faster-RCNN,MASK-RCNN
速度通常较慢(5FPS),但是效果通常还是不错的!
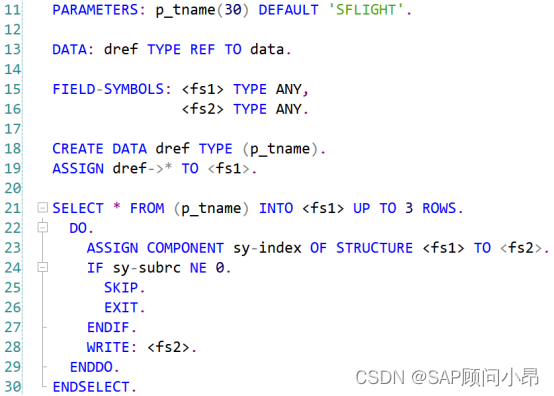
2. IOU指标计算
其实很简单的理解就是交并比,两个框分别是预测结果与地面真值
3. MAP指标计算

首先要认识基础的精确度和召回率的计算公式,这是一个例子:

指标分析
基于置信度阈值来计算,例如分别计算0.9;0.8; 0.7

0.9时: TP+FP = 1,TP = 1 ; FN = 2; Precision=1/1; Recall=1/3;
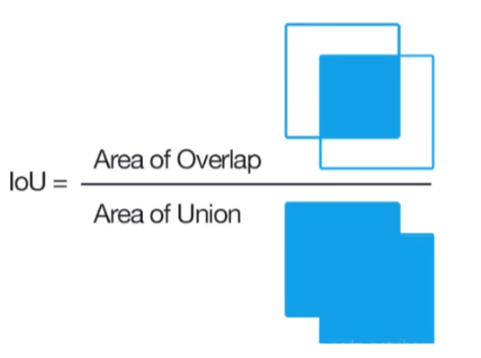
如何计算MAP
采用P–R图:需要把所有阈值都考虑进来;MAP就是所有类别的平均
最理想的情况就是框柱整个坐标系以接近1,图中(左)蓝色实线代表P–R曲线(精确度&召回率),红色虚线代表所计算的区域,即选择时选择蓝色实线的最大值;图(右)展示了所画出的四个区域,计算面积就是MAP的值
4 YOLOv1
- 经典的one-stage方法
You Only Look Once,名字就已经说明了一切!
把检测问题转化成回归问题(即(x,y,w,h)),一个CNN就搞定了!
可以对视频进行实时检测,应用领域非常广!

Faster R-CNN map较高,但fps远不能达到实时监测的要求
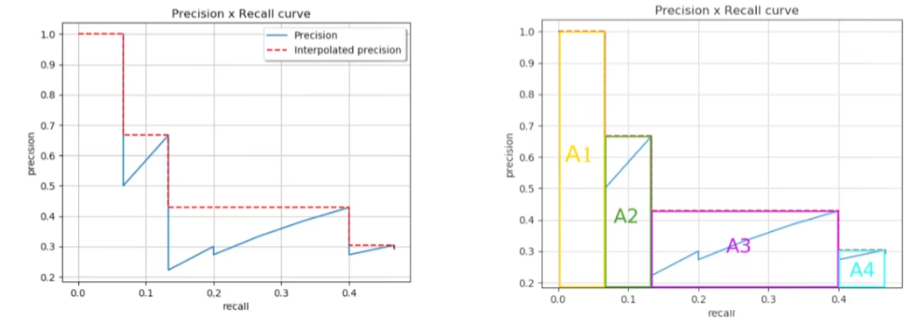
4.1 YOLOv1核心思想
将输入图像划分成两种候选框,计算并选择IOU最大的候选框 ,还有置信度来确定预测是否准确。最终想要得到的就是最右边的三个框。
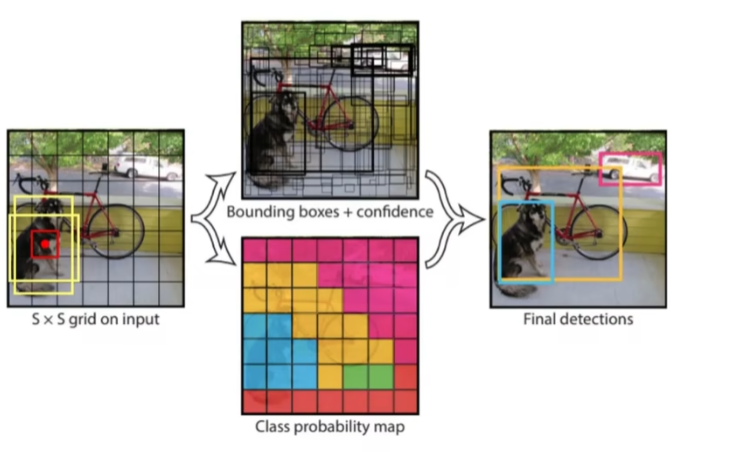
4.2 YOLOv1网络架构

YOLOv1的卷积层在后代已经被优化了,所以不需要仔细看。
在上图中,值得关注的是两个全连接层,因为全连接层的存在,因此在最开始输入的图像大小还必须是固定的,7 * 7 * 4096 ;7 * 7 * 1470,这是两个全连接层的参数。
那么,7 * 7 * 30的输出是怎么来呢?
之前已经说过,v1会生成两个预测框B1,B2,那就已经有两个输出分别为
B1:(x1,y1,w1,h1,C1);B2:(x2,y3,w2,h2,C2),其中C代表置信度,这已经占了10个位置,剩下的二十个代表的其实是网络中可识别的类别共计20类。
每个数字的含义:
- 10 =(X,Y,H,W,C) * B (2个)
- 当前数据集中有20个类别
- 7 * 7表示最终网格的大小
- (S * S) * (B * 5+C)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VrBCqJiO-1674872650313)(C:\Users\hp\AppData\Roaming\Typora\typora-user-images\image-20230128100347551.png)]
4.3 损失函数
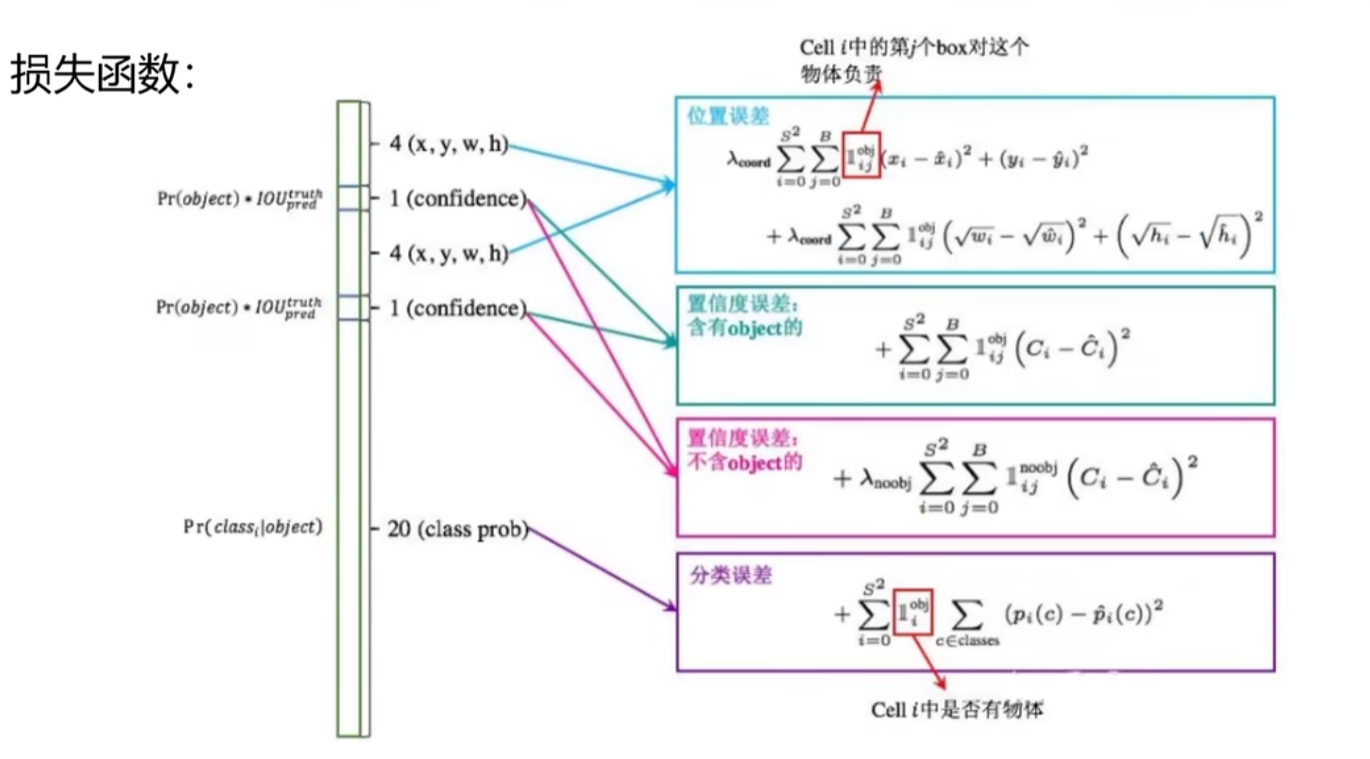
4.3.1 位置误差
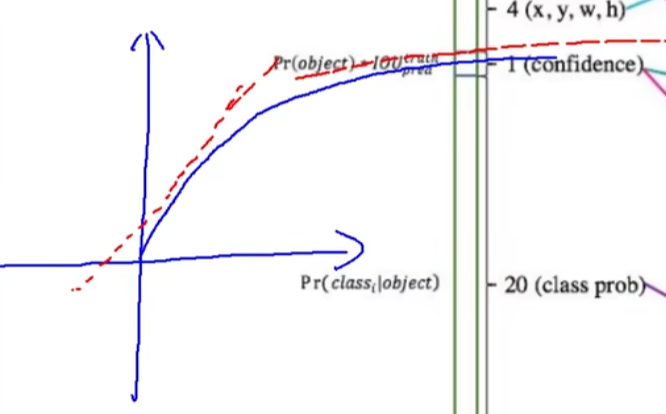
对于x,y,w,h要指定一个函数来最小化与真实值的误差

前半部分是x,y;后半是w,h;加根号的意义是为了解决小物体中偏移量不敏感的问题,就如图所示:
4.3.2 置信度误差(含object)
图像分前景和背景,预测框想要选择的是前景。
先算预测框与真实值的IOU,再与IOU最大的框进行预测(大于阈值)。

4.3.3 置信度误差(不含object)
比上一节多加了一个参数λ,其目的是为了减弱占更多空间的背景的影响
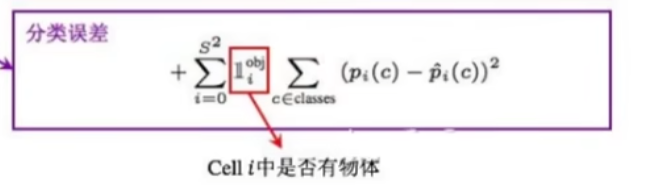
4.3.4 分类误差
4.4 总结
全部加在一起就是总的损失函数。

![[Android开发基础2] 七大常用界面控件(附综合案例)](https://img-blog.csdnimg.cn/82fe577a45df449ba7eb17807bfbc3ad.png)