1、生产环境发生 cpu 飙高的问题?你是如何定位解决的呢?
我们的线程是运行在 cpu 上面
1. CAS 自旋一直重试导致 cpu 飙高 没有控制自旋次数;乐观锁
2. 死循环;
3. 阿里云 Redis 被注入挖矿程序,建议 Redis 端口不要能够被外网访问;
4. 服务器被 DDOS 工具导致 cpu 飙高,可以通过限流、ip 黑名单、图形验证码防止机器模拟攻击;
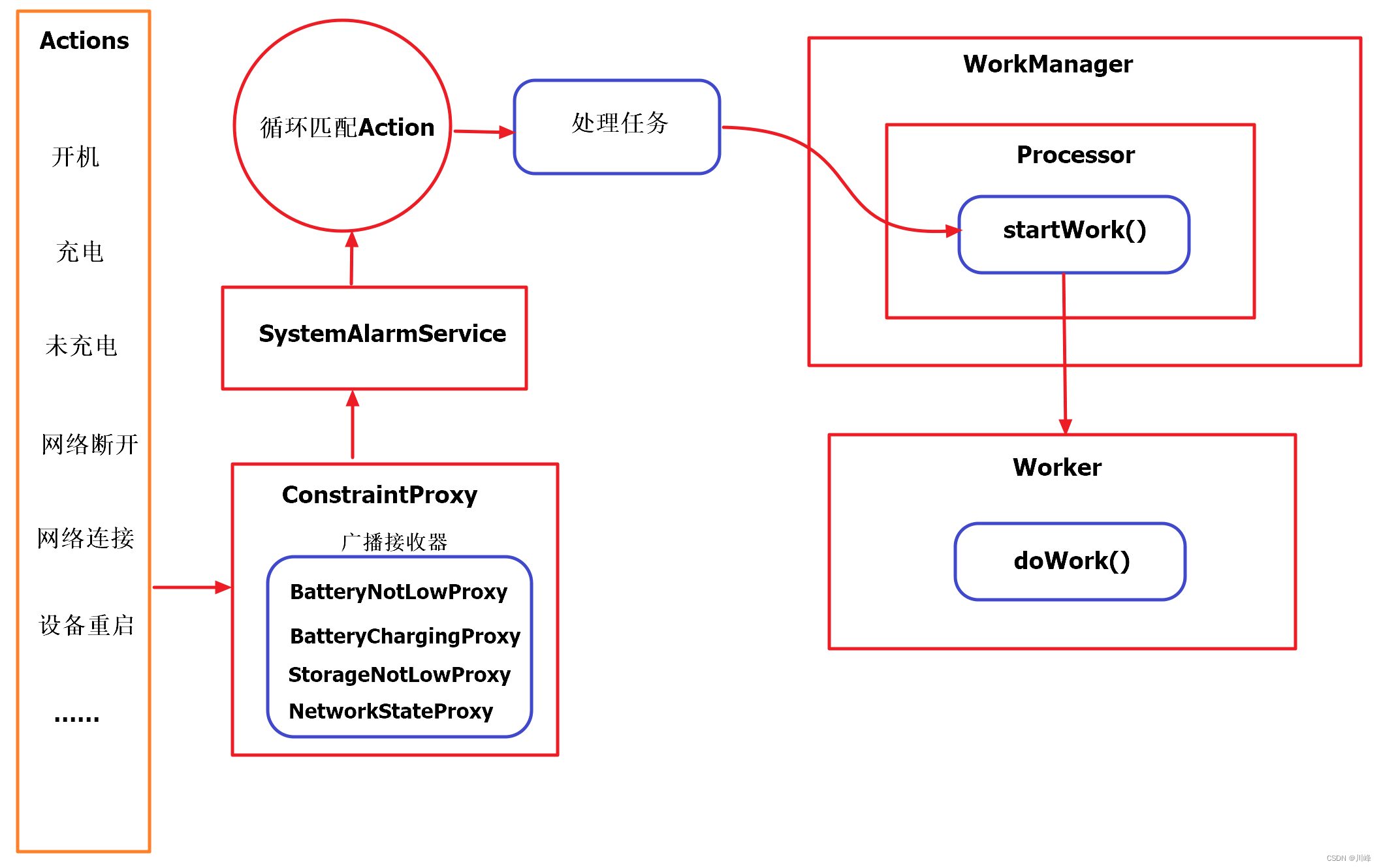
创建过程中,需要配置线程名称呢?
阿里巴巴的 java 开发手册 使用到线程池建议配置线程池名称
方便在后期可以定位是那个业务相关的线程。
分析思路:
1. 查看当前的操作系统中(top) 那个进程 cpu 使用率是最高的;
2. 找到该操作系统中 最高使用率 进程 分析该进程里面具体线程 谁 cpu 使用率是最高的
3. 在根据线程名称 搜索“java 代码” 找到具体发生 cpu 飙高的代码
工具:
使用 D:\path\jdk\jdk8\jdk\bin jvisualvmq.exe/Arthas 工具
2、生产环境发生内存泄漏问题?你是如何解决的呢?
内存泄漏(Memory Leak)是指程序中已动态分配的堆内存由于某种原因程序未释放或无法释放,造成系统内存的浪费,导致程序运行速度减慢甚至系统崩溃等严重后果。
内存泄漏发生的案例:
1. ThreadLocal 内存泄漏问题
2. HashMap 自定义 key 避免内存泄漏问题
通过以上案例排查内存泄漏问题
排查思路:查找到 java 虚拟机 哪些对象占用空间最大 前 20 个 列出分析
生产环境发生内存溢出问题?你是如何解决的呢?
3、生产环境遇到了报错?你是如何定位解决的呢?
1. 传统的方式 在生产环境中遇到报错问题,我们是通过搜索日志的方式,排查具体的错误。适合于服务器端 是单机或者少量集群的节点
Tail -200f
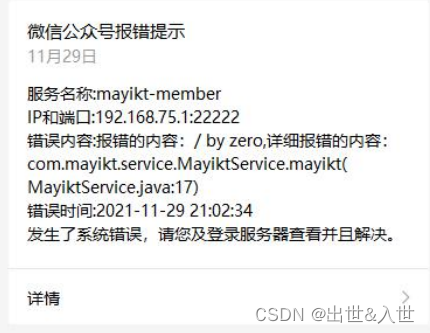
2.采用 aop 形式拦截系统错误日志,在将这些错误日志调用微信公众号接口 主动告诉给我们的开发人员生产环境发生了故障。
3. 我们公司采用 apm 系统 skywalking ,监控整个微服务 如果服务在一段时间内发生了故障或者报错 会主动调用微信模板接口通知给开发人员 生产环境发生了故障。在通过 skywalking 追踪 链可以直接查看到具体的错误信息内容
4、生产环境服务器宕机,如何解决呢?
1. 我们公司生产环境,会对我们服务器 实现多个节点集群,如果某台服务器发生了宕机 会自动实现故障转移,保证服务的高可用。
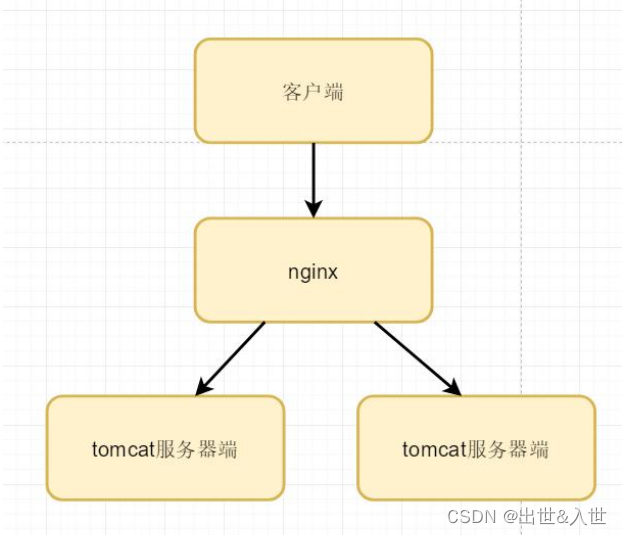
2. 如果服务器宕机 我们可以在服务器上安装 keepalived 监听 java 进程,如果该java 进程发生了宕机 会自动尝试重启该 java 进程,这是属于软件层面。如果是物理机器比如关机了,可以使用硬件方式自动重启服务器 例如向日葵
3.如果服务器发生了宕机,尝试重启 n 多次还是失败,我们可以使用容器快速动态的实现扩容(docker 或者 k8s)k8s
4.重启该服务,如果重启多次还是失败 则会发送短信模板的形式通知给运维人员。
注意:千万不要回答 直接重启服务器端。
物理机器关机----tomcat 服务器宕机
5、调用接口的时候,如果服务器端一直没有及时响应 怎么解决?
Ddd 服务网格 云原生
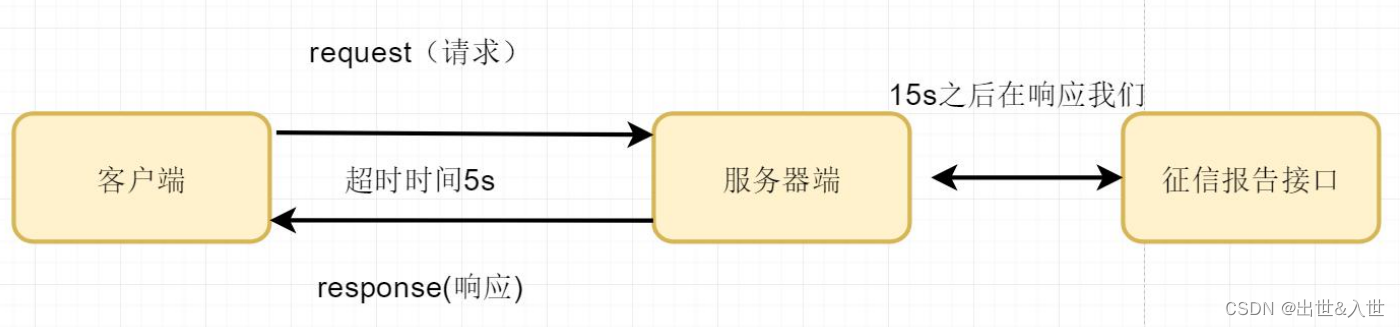
1.如果调用接口发生了响应延迟:是因为我们 http 请求是采用同步的形式,基于请求与响应模型如果服务器端没有及时响应给客户端,客户端就会认为接口超时,接口发生了超时客户端会不断重试 ,重试的过程中 会导致 幂等性问题幂等性问题(需要保证业务唯一性。)
例如:服务器端 调用网络连接(调用征信接口、发送短信、连接 mysql、redis)
2.如果接口响应非常慢,就需要对代码做优化例如 加上缓存减轻 db 查询压力、减少 GC 回收频率
3.如果接口代码在怎么优化 就是执行非常耗时时间,因为采用 mq 异步的形式不能够使用 同步形式。
举例子:接口代码里面 需要调用非常多接口 在响应客户端
接口代码:
1.调用征信报告接口---15s-30s
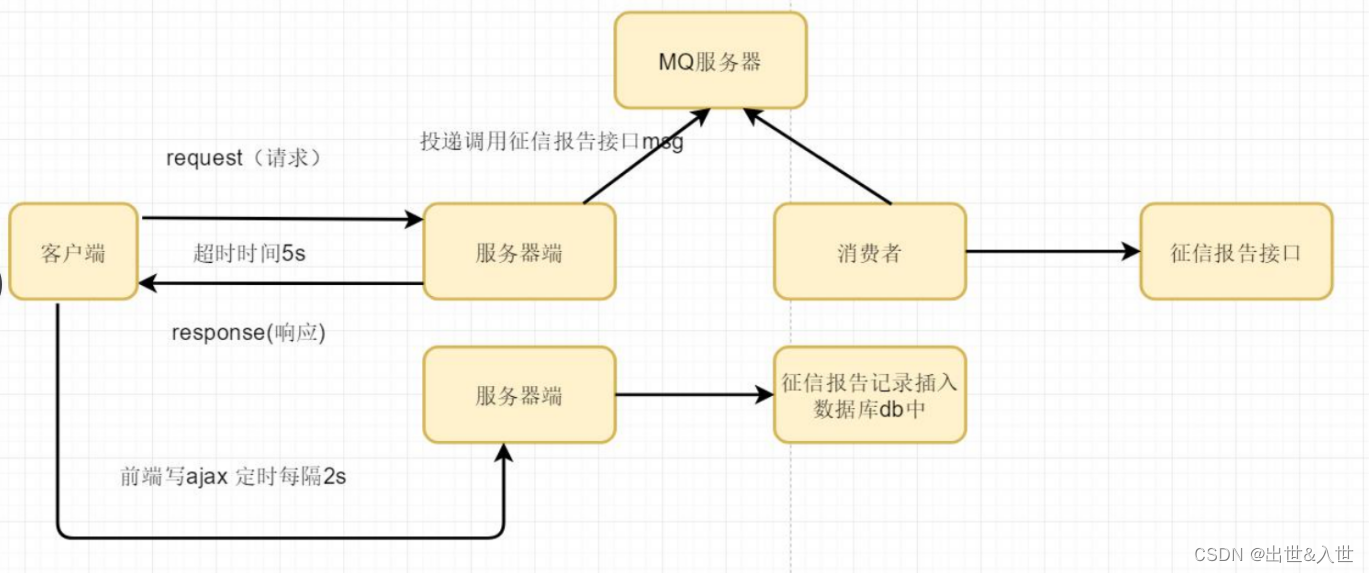
6、服务正在发布中?如何不影响用户使用?
服务正在发布中,该 jar 中正在启动... 客户端访问的时候,一直阻塞等待。
1.使用 nginx 故障转移即可。
2.灰度发布 先发布一小部分 如果没有问题 在让所有用户都可以访问。灰度发布 nginx+nacos gateway+nacos(推荐) 或者是 k8s 实现。
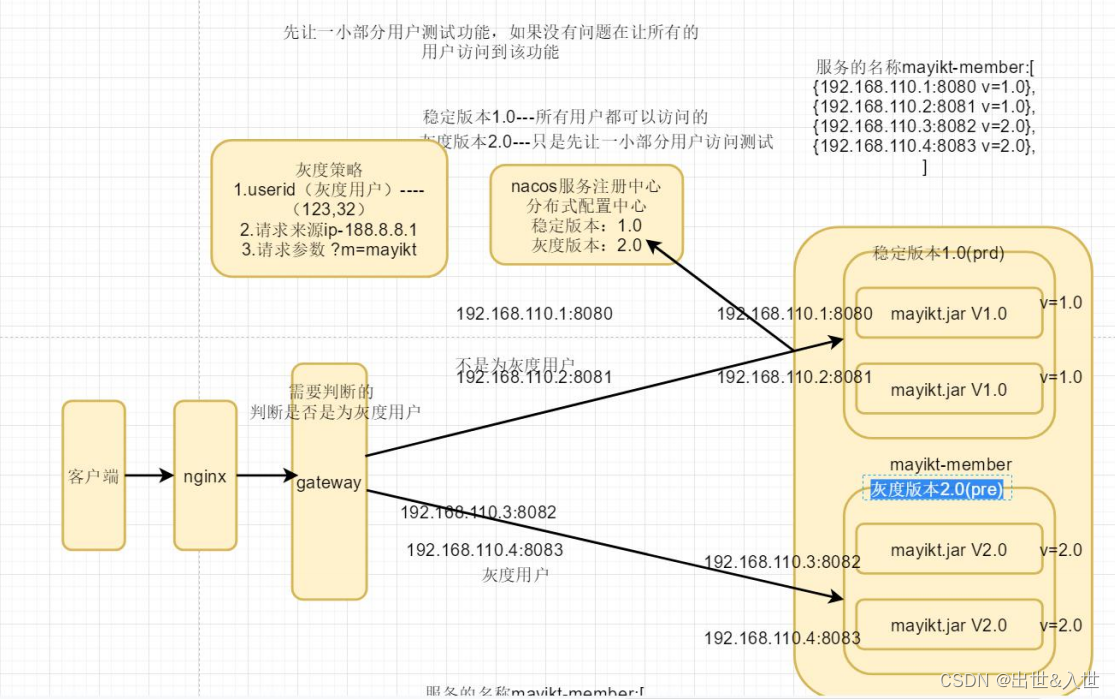
7、你在开发过程中,遇到哪些难题?你是怎么解决的呢
如果在面试的过程中被面试官问到:你在开发过程中,遇到哪些难题?
不要答:空指针异常、常见错误异常。
遇到问题→你是如何分析的?→如何排查的?→最终是怎么解决的?
1.分布式事务
2.分布式幂等
例如 我们公司提供了一个接口,被其他公司进行调用。他的公司在调用我们公司接口的过程中,我们的接口响应超时了,最终触发了客户端重试了,重试的过程当中请求的参数都是相同的,导致我们接口会重复执行业务逻辑。
解决办法: 全局 id 业务上防重复、 在 db 层面去重复 例如 创建唯一约束
3.定时任务调度
例如:我们项目在生产环境中做定时任务,如果集群的情况下 定时任务重复执行。 解决该问题
1.在打 jar 包的时候 加上一个开关 只让一个 jar 包执行定时任务
2.整合分布式任务调度平台 xxljob 最终分片执行 定时任务集群的执行
定时任务 1 【】跑批 1-10 万 定时任务 2 11-20 万
4.数据同步延迟问题
我们公司 使用 canal 解决 mysql 与 redis+kafka 数据同步问题发现就是在并发的情况下同步非常延迟,我们整合 kafka 分区模型根据每张表都有自己独立的 topic 主题,每个 topic 主题有自己独立分区 每个分区有自己独立消费者 ,解决消息顺序一致性问题。
6. 安全性问题
7. 生产环境发生 cpu 飙高、内存泄漏
8. 因为我们的项目前后端分离 跨域的问题
.......真实业务场景当中遇到难题






![[PyTorch]在PyTorch环境下使用Tensorboard](https://img-blog.csdnimg.cn/053f8d3953af478db203619e1b53b4bb.png)