前言
检索结果的多样化是检索系统的一个重要研究课题,其可以满足用户的各种兴趣和供应商的平等公平曝光。
然而,检索系统中(搜索与推荐领域)的多样性研究缺乏一个系统的汇总,并且研究点相对零散。本次介绍的paper中,首次提出了一个统一的分类法,用于对搜索和推荐中的多样化指标和方法进行分类,这也是检索系统中研究最为广泛的两个领域。
全文较长,感兴趣的小伙伴建议先收藏~
论文链接:https://arxiv.org/pdf/2212.14464.pdf
introduction
随着信息的爆炸式增长,检索系统越来越重要,其中搜索和推荐是检索系统的两个重要方向,两者都可以被视作是一个排序系统,搜索是根据用户的query检索出相关的doc,推荐是根据用户消费的item历史挖掘用户的兴趣点。
在很长一段时间内,relevance相关性是检索系统重要关注的指标,虽然这些系统能够很好的检索回来相关性的item,但是这在一定程度上伤害了用户和供应商,拿推荐场景来说,对于用户来说容易进入信息茧房,比如对于一个电影检索系统,当一个用户点击了《蝙蝠侠》后,系统之后就只推漫威电影,虽然相关性确实高,但是用户失去了看其他类型的电影的机会。对于供应商来说,系统总是愿意集中去曝光那一部分少的高流量item,对于一些冷启动或者低流量的item就没有机会曝光了,那就导致最后只有少部分受欢迎的供应商能够被曝光,而大部分供应商会放弃这个平台。
在搜索场景下,也面临着一些问题,比如在一个图片检索系统,当有一个query是“捷豹”时,通常返回的是“捷豹汽车”,尽管结果具有很高的相关性,但是这也是不合适的,因为“捷豹”还会有另外的意思比如说是一种动物。
因此近年来,除相关性以外的许多其他指标都受到了极大的关注,其中“多样性”是被最广泛研究的,其不仅可以增加满足用户短期和长期的各种需求,同时也有助于增加供应商(尤其是那些不太受欢迎的提供商)曝光
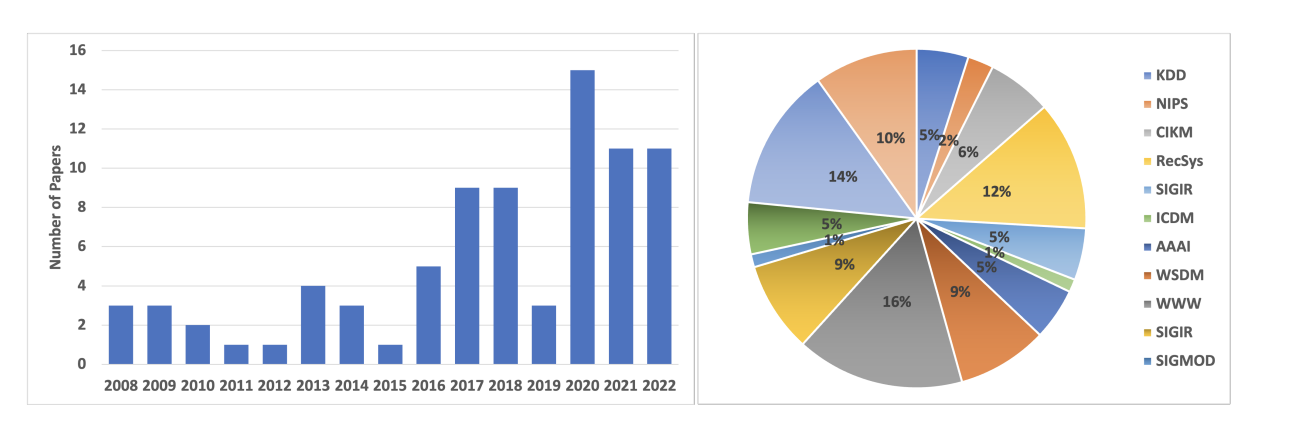
作者从KDD, NeurIPS等收集了80多篇paper,统计如下:
diversity in search
-
Extrinsic Diversity
外在多样性指在结果整体信息的不确定性,比如同样是搜索“辉瑞疫苗”,病人可能关心疫苗的功效,医生可能更关心疫苗的成分,而企业家可能更关心辉瑞这家公司。所以一个系统的外在多样性越大,其搜索的结果应该越能满足各种需求。
-
Intrinsic Diversity
内在多样性不同于外在多样性,其往往是能够知道一个明确的搜索意图的,例如“捷豹 作为动物”的这个query,这个query基本上就没有什么歧义,但是即使这样,用户也是希望搜索出的捷豹图片是各种各样角度或者视角下的捷豹,而不是单一的视角下的捷豹,即避免结果冗余。
diversity concerns in recommendation
-
Individual-level Diversity
这个是对用户方面来说的,为了避免给用户每一次推荐的一样,所以多样性就至关重要啦
-
System-level Diversity
这个是对供应商方面来说的,为了体现公平,这个多样性就是保证那些不怎么受欢迎的供应商也具有曝光流量。
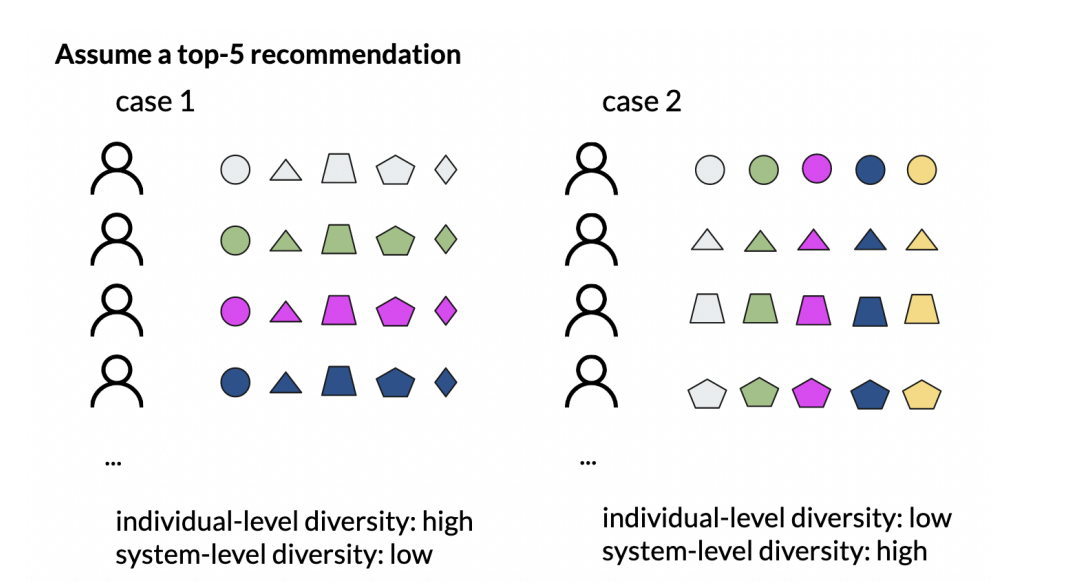
下面这个例子可以很好的说明两者的区别:其中不同的形状代表着不同的供应商,同一个形状下不同的颜色代表着不同的item。在case1中每个用户都可以都得到了不同供应商的item,所以Individual-level Diversity很高,但是所有用户都是得到那五家的item所以System-level Diversity很低;在case2中,每个用户得到的是不同供应商的曝光所以System-level Diversity很高,但是每个用户只是得到了同一个供应商的item,看不到别的供应商的item,所以Individual-level Diversity很低。
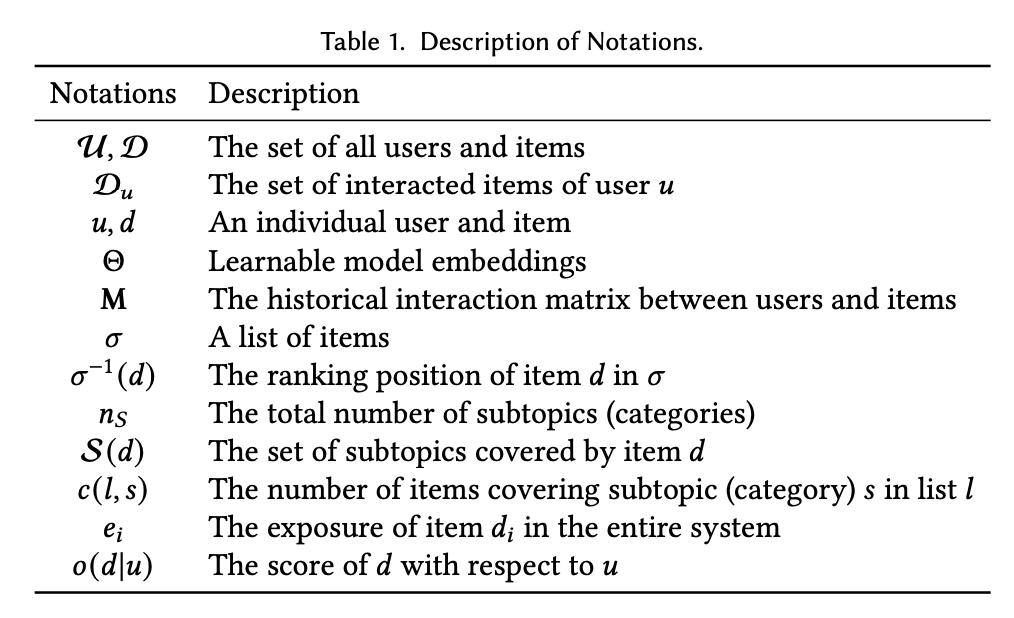
preliminaries and notations
这里定义了一些变量,方便后面讲解
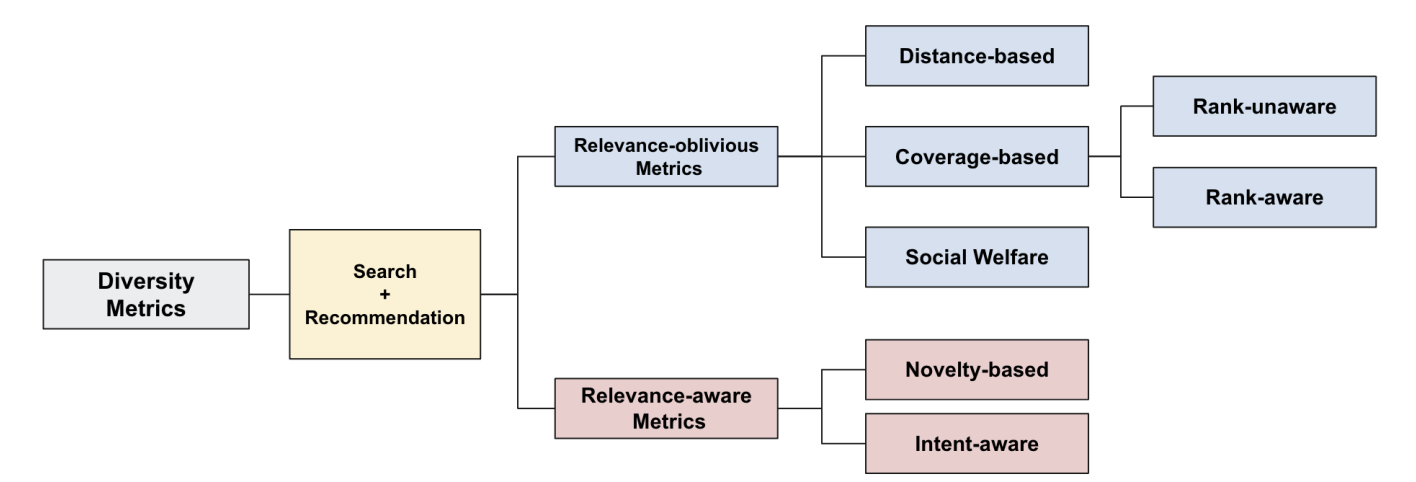
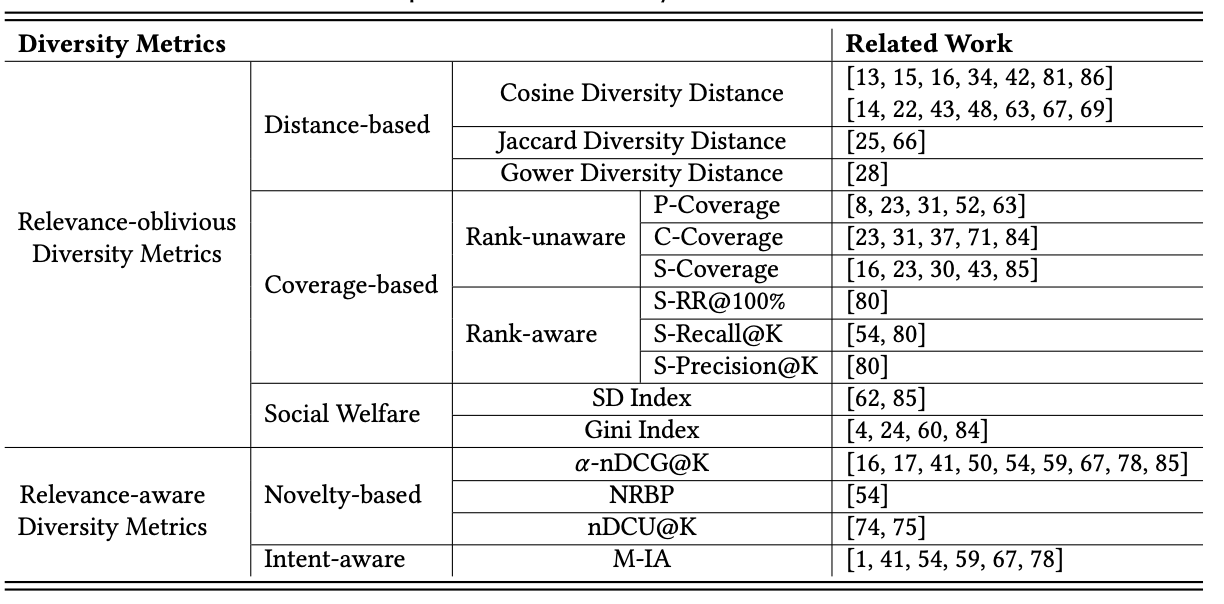
metrics of diversity in search and recommendation
作者对多样性指标进行统一的总结归纳如下:
-
Relevance-oblivious Diversity Metrics
relevance-oblivious 指标不考虑相关性,仅考虑多样性本身,作者进一步将其细化为Distance-based、Coverage-based和Social Welfare。
(1)Distance-based 定义 为检索回来的item列表、 为item 和 的距离,距离越小代表着越相似,多样性就越差,这里最常见的就是ILAD和ILMD,定义如下:
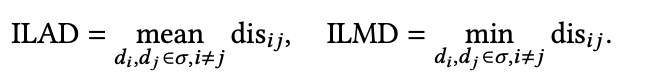
在一些特殊的序列推荐场景中,每次只需要推荐w个连续的item给用户,所以就可以得到ILAD和ILMD两个变种ILALD和ILMLD如下:
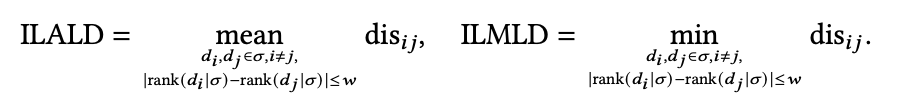
其中 的定义也有很多种,比如
(a) Cosine Diversity Distance : 基于余弦距离,这里通常需要item具有embedding,那么
(b) Jaccard Diversity Distance : 这里主要就是基于集合进行计算,其中集合的定义有两种,可以看到是基于item和user两个角度
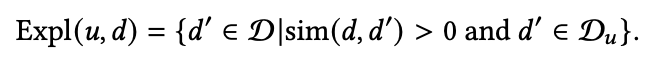
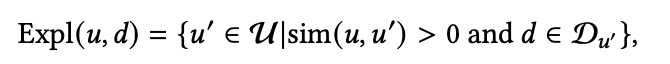
在得到了集合后,就可以得到距离了:
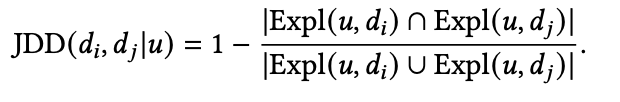
(c)Gower Diversity Distance: 假设$\delta {k} k^{th} w{k}$是对应的权重,那么距离就是:
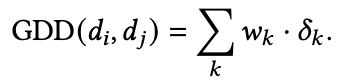
(2)Coverage-based
(a) Rank-unaware
这里在设计指标的时候,不会考虑结果列表的顺序影响,常见的有P-Coverage、C-Coverage、S-Coverage,定义分别如下:
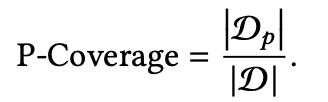
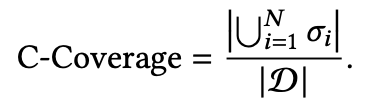
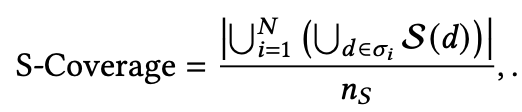
其中 是可提供的所有item集合; 是检索系统可返回的item集合, 是返回的第i个item列表, 是item 覆盖的类别数量, 是代表一共有 个列表。可以看的出P-Coverage其实和常用的准确率定义差不多,C-Coverage在一定程度上可以衡量多样性,而S-Coverage是最被常用的,也和我们理解的多样性最贴切。
(b) Rank-awar
这里在设计的时候,会考虑item的顺序,因为在用户通常比较关心排在前面的几个item,也就说排在前面的几个item得到的曝光往往比较大,而排在后面的item很多,但是得到真实的曝光很少,所以考虑顺序很重要。
这里最常见的就是S-RR@100%、S-Recall@K、S-Precision@K,其定义分别如下:
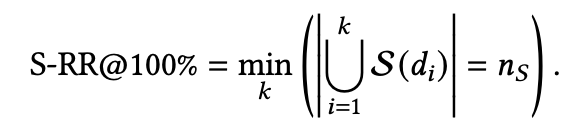
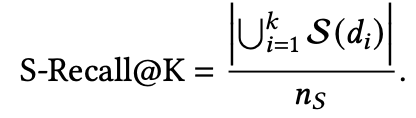
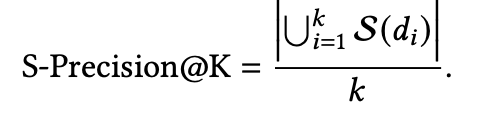
可以看到S-RR@100%是看当需要达到覆盖 个主题时需要的最少的item数量,所以S-RR@100%的值一定是大于等于 的。而后面两个是模仿相关性指标中Recall@K、Precision@K的,大同小异
(3)Social Welfare
其实不仅仅是计算机领域在研究多样性,其他诸如生态学和经济学等都也在研究,所以这里也有一些多样性指标是借鉴其他领域的。
(a) SD Index
其定义如下:
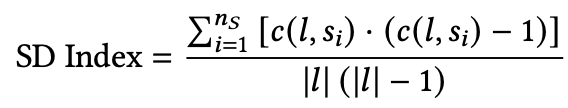
代表整个item 类别数, 代表item数量, 代表在列表l中的item覆盖的类别数量 。
这里我们可以举个例子,假设这里一共有三个类别,系统A推荐出了10个item,其覆盖的类别分布是8,1,1;系统B推荐出了10个item,其覆盖的类别分布是4,3,3;那么系统A的SD Index大于系统B即 ,也就是说系统B的多样性比系统A高。
(b) Gini Index
其定义如下:
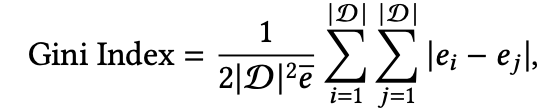
其主要是参考基尼系数的定义来设计的,其中 是item i的曝光数量,可以看到当Gini Index越小,说明每个item都越得到了平均数量的曝光,系统越公平那么多样性就越强。
-
Relevance-aware Diversity Metrics
尽管多样性很重要,但是相关性也同样还是很重要,就比如一个检索系统每次都随机返回一些item,其多样性肯定是很好的,但是其相关性也肯定很低,用户体验也还是很差。
为此可以同时考虑多样性和相关性,这里先介绍两个关于相关性排序的重要属性:Priority和Heaviness。
Priority是指: 是指一个item的相关性分数, 是指 这个item列表的整体相关性分数,当 时即item i的相关性分数小于item i的相关性分数且 即item j展露的位置比item i靠后,那么当交换item i和j的位置后,整个item列表的相关性都会变大即 。
Heaviness是指: 当 ,且 ,那么
一般来说相关性指标都会满足上述两个属性。基于此可以把多样性指标(同时考虑相关性指标)分成如下两类指标
(1)Novelty-based Metrics
这类常见的指标大致可以分为如下几种
(a)𝛼-nDCG@K
我们知道在考虑顺序的相关性指标中NDCG@k是被常用的,其是
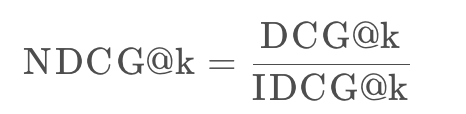
而DCG@k和IDCG@k的定义是:

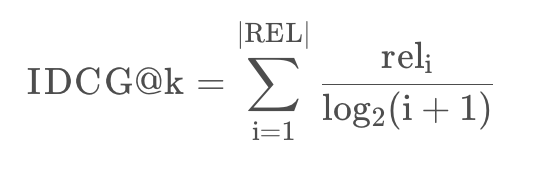
其中 是最理想的排序。于是参考普通的NDCG@k的定义,联合考虑多样性后那么𝛼-nDCG@K就是:
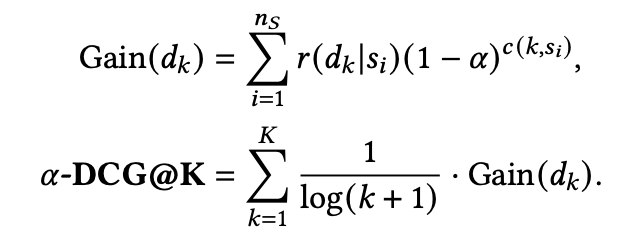
其中 代表到列表第k个位置时所覆盖的item类别数量
(b)NRBP
该指标有一个前提: 代表一个用户浏览到位置k的概率且位置k之前的item用户都会浏览
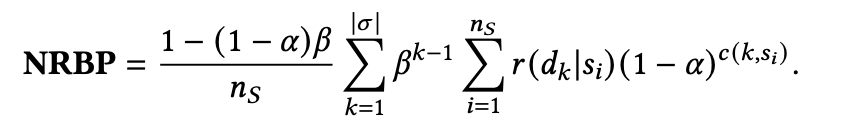
(c)nDCU@K
这里类似𝛼-nDCG@K,其中只不过又扩展了下 ,把其改为了
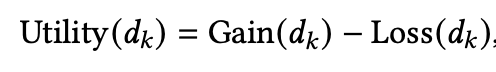
那么最终的指标就是
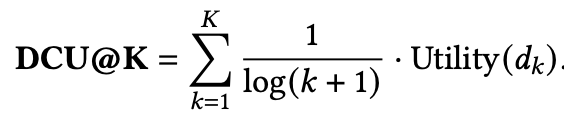
那么这里的 和 又具体代表什么呢?其实它没有明确的定义。是一个比较宽泛的定义,但大体含义就是前者代表用户在看到第k个item后所获得的增益或者说满意度(包括相关性和多样性两方面),而后者的含义就是代表用户在看到第k个item后所付出的代价(包括需要的时间精力等等)
(2)Intent-aware Metrics
在考虑多样性的时候,不是说越覆盖的item 类别越多就越好,还需要考虑哪个类别是用户最感兴趣的,假设有两个类别: 和 ,现在有两个item 和 ,其中 的整体排序得分为5比较高,但是其和 的相关性较差,和 较高;而 的整体排序得分为4比较低,但是其和 的相关性较差,和 较高;一些传统的相关性指标都会把 排在 前面,但是实际上用户更喜欢 。基于此定义了如下:
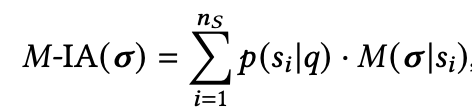
其中 就是传统的指标比如nDCG、MRR、MAP等等。
offline approaches for enhancing diversity
下面我们先来看看通过离线增强多样性的方法,这里主要有三大类
(1)Pre-processing Methods
这类方法主要就是在模型训练前阶段进行干预,大体上可以归纳为如下三种:
(a)Pre-define User Types
这里就是对用户进行分类,比如一个时尚购买网站可以把用户分为(i)礼物类型,就是给他人买礼物(ii)从众心理,他人买啥我买啥;等等吧,然后每个类型返回5个item,然后组合着给用户推荐,最后的实验结果显示C-Coverage指标从24%提高到了78%,每个用户的消费能力也提高了$13。
(b)Pre-define Sampling Strategies
这里主要就是在抽样这里进行设计等等,目前图网络类算法如GNN很多,它把user和item当作图中的节点,交互行为为边,为每个user和item学习一个embedding;可以想象到越受欢迎的item越被抽中的概率越大,因为他们的边很多,这在一定程度上就限制了多样性。
为此可以对抽样环节进行干预,比如可以对不受欢迎的item进行抽样权重的增强同时对受欢迎的item进行抽样权重的降权;又比如在负采样环节可以把负样本的候选框定在同类别但是是负样本下,这样不同类别的item 由于没怎么见过,在embedding空间上就不会那么远,进而导致item结果列表就更可能出现多类别的item,提高多样性。
(c)Pre-define Ground-truth Label
这里主要就是提前给模型准备label,而这个label是同时考虑了相关性和多样性,所以最后模型就可以同时具备多样性和相关性;这里的做法可以分为两步,第一步就是先过滤出分数较高的item候选集 ,选的逻辑也很简单,只要当前这个item的分数高于该用户所有item分数的平均值就进入 。第二步就是从 中进一步筛选出 ,选的逻辑就是:
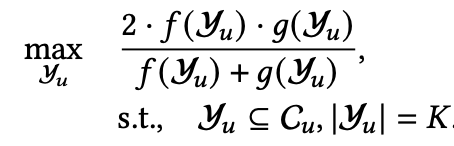
和 分别是量化相关性和多样性,其中 :
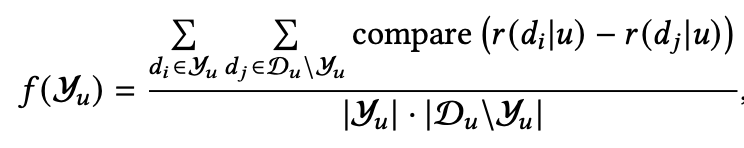
采用的是ILAD的指标。
(2)In-processing Methods
这里主要就是在训练模型的时候进行干预,主要就是如下两个方面:
(a)Diversity as Regularizatio
这里直接在训练loss加多样性正则:
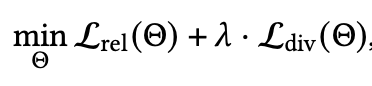
其中 和 分别代表相关性和多样性loss,其中多样性loss可以用ILAD等等;其中一些研究还可以定义如下:
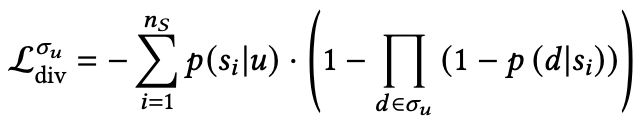
代表着用户 对 主题的喜欢程度, 代表着item 对 主题的相关性。
(b)Diversity as Score
这类方法首先是把多样性看作一个分数,具体的定义item 的分数是:
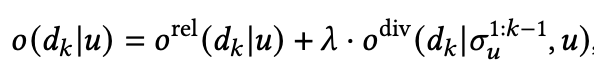
其中 和 分别用于衡量相关性和多样性,其中 即user embedding和item embedding的内积;而多样性如下:
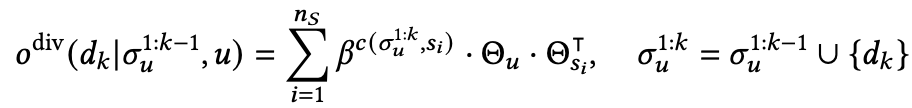
是一个衰减参数,取值范围为(0,1), 代表user的embedding; 代表 item 类别 的embedding; 代表在 中覆盖 的item数量。
至此每个item有了分数之后,随机抽取一对item 后其交叉墒便loss是:
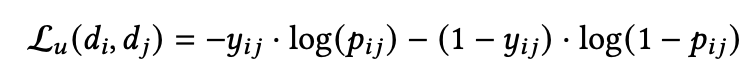
如果item 排在 前面那么 ,相反为0;
(3)Post-processing Methods
这里主要就是模型排序完进行后处理干预,即根据相关性指标和多样性指标进行重排,这里通常可以分为如下两种:
(a)Greedy-based Methods
这种就是在每一个位置贪婪的进行最大化相关性和多样性,常见的有MMR和DDP两种。
(i) MMR
该思想就是最大化边界相关性,所谓边界相关性是指当一个item和一个user的相关性很高且和之前的item相关性很低的时候就具有很高的边界相关性,基于这个思想定义如下:
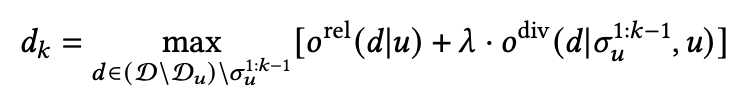
可以看到和Diversity as Score处介绍的公式比较相似,其中 采取的还是通过用的已经训练好的embedding内积的方式得到,但是 变为了:
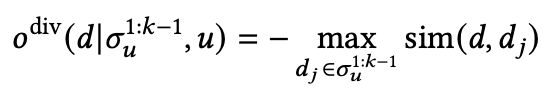
(ii)DDP
这里也很简单,主要就是理解了如下矩阵就可以,对角线代表item和user的相关性分数,非对角线代表着item之间的相似性,那么 ,可以看到主要就是相关性减去相似性,也就是说item和user之间的相关性越大,item和item之间的相似性越小,那么么 就越大,也就是代表这item 列表结果和用户相关性越好,且item多样性越好
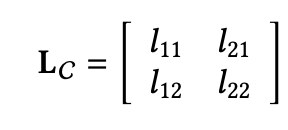
为此理论上找到 全局最大值即可,但是这毕竟难,于是就可以借助贪婪算法在每个位置找item
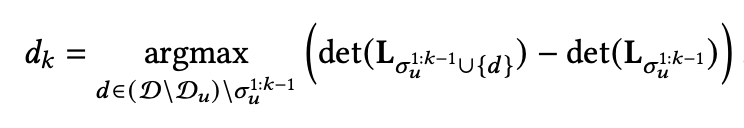
(b)Refinement-based Methods
这类方法不像上面启发式的一个一个的item往下选,Refinement-based类的方法采用的是在一个已经排好序列表上进行第二次交换或者替换item顺序来干预。
比如先分别根据相关性分数和多样性分数来对列表进行降序排序,然后再合并成一个最终的列表,最简单的方式就是先选出topk个相关性分数高的 item,然后从第一个开始根据多样性和下一个 item交换顺序即如果能增加多样性就交换,不过为了保险也设置了一个最低相关性门限值,防止最后整体相关性骤降。
online approches for diversity
上面我们介绍的都是一些离线的方法,用离线准备好的数据训练一个模型线上使用,但是有一些场景下离线的训练数据是不那么容易获得的,比如冷启动问题,一个新用户来了后是没有历史数据可供其训练的,只能就是先展示一个列表,再拿到其反馈后为下一刷更新模型
-
Bandit Strategies
这里把在线学习问题看作一个是多臂老虎机问题,其是一个最简单的强化学习研究分支,一些术语和背景大家可以自行查阅相关资料,有很多,其核心如下:
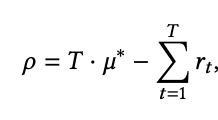
这里使用的是Regret,也就是距离理想状态的差距来定义。当然了也可以用Reward来量化,也就是玩了多轮游戏以后的总收益。
现在要做的就是把多样性指标揉进去即可,通常有两种思路如下:
(a)Diversity as Score
这里就是把多样性看成是一个分数即每次选item的时候的一个分数,比如一个用户从上到下浏览列表,直到遇到一个喜欢的点击,然后就停止浏览了。假设用户点击了item收益Reward就是1否则就是0,那么这个问题就可以看成是一个多臂老虎机问题即:
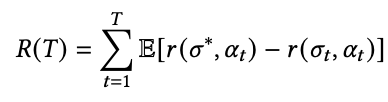
其中 和 分别代表最理想item列表和展现列表, 是一个vector,代表了一个item排序分数;其中这个分数就是综合考虑了多样性和相关性的分数。具体的可以使用前面介绍的各种多样性指标。
(b)Diversity as Architecture
这里就是从每个类别中抽取item出来,这个规则就保证了每个类别都可以覆盖,一定程度上就保证了多样性。
除此之外,上面的做法对每个用户最终展示的结果都一样,这就不够个性化,为此可以为每个用户应用多臂老虎机。
-
Reinforcement Learning
尽管上述多臂老虎机能够处理一些在线学习的问题,但是其也有很明显的局限性,比如其只能处理一个场景即假设用户的兴趣偏好不变,而且其只能出来即时奖励,而一些长期的奖励也同样发挥着重要的作用。为此很有必要引入强化学习框架。
最常见的比如强化学习中的DQN网络,这也是一大类网络,感兴趣的小伙伴可以去看笔者之前写过的一篇文章:https://blog.csdn.net/weixin_42001089/article/details/81448677
openness and future directions
可以看到多样性研究其实很有必要,也已经有了很多相关的工作,但是目前依然有很多局限性,本节主要就是列举一些局限性和未来可能的研究方向。
-
Time Dependency
现在检索系统的研究都局限在一个时间点下,但是不同的用户随着时间的不同对多样性的要求也是不一样的,比如当一个新用户刚来的时候可以多推一些各种各样的item,增加多样性,让用户能够有足够的选择去探索他的多样性,但是随着时间的累积,系统能够自己适应的在多样性和相关性之间找到平衡。
-
Direct Optimization of Metrics
目前的一些多样性指标比较难被直接优化比如coverage-based metrics和SD Index,因此探索一个区分这些指标的端到端的训练也是一个比较重要的方向。
-
Diversity in Explainability
目前的多样性仅仅就是指的item列表的展现多样性,但是多样性实际上是可以有其他维度的比如可解释性,目前的可解释就是通过用户自己历史交互了哪些item或者借助其他人的行为来解释,但这不是唯一的,也不一定是最好的,因此研究item和user到底哪些feature导致了多样性也是很有趣的一个方向,目前该方向的研究比较少。
关注
欢迎关注,下期再见啦~
知乎,csdn,github,微信公众号
本文由 mdnice 多平台发布

![[PyTorch]在PyTorch环境下使用Tensorboard](https://img-blog.csdnimg.cn/053f8d3953af478db203619e1b53b4bb.png)





![[数据库迁移]-ES集群的部署](https://img-blog.csdnimg.cn/c25adad0549c4981a481da29e1654e7f.png#pic_center)