[数据库迁移]-ES集群的部署
森格 | 2023年1月
上一篇文件我们已经把Linux系统的LVM逻辑卷完成了,那下面我们就该把es集群环境搭建起来了,主要是以shell脚本来进行一键部署。
上文回顾:[数据库迁移]-LVM逻辑卷管理
一、环境介绍
1.1 环境配置说明
es 集 群: 三个节点形成es集群,kibana单独在一台机器上。
es 版 本: 7.5.1
所需插件: ik分词器(7.5.1),repository-oss(阿里云OSS插件,版本7.4.0.1)
机器配置: 8C16G,挂载500G磁盘
1.2 版本注意事项
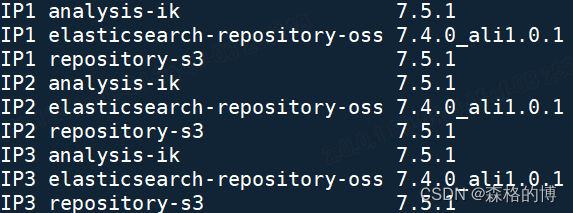
1)在插件版本选择上,务必与es集群的版本一致,不然在启动es集群时会报错。拿IK分词器举例,下图为ik分词器的配置文件中的解释,也就是说当插件被加载时,插件的版本会被检查,es会拒绝启动当存在错误的插件版本。

2)对于其他插件,例如阿里云开源的OSS插件,不是每个小版本都做了发布,如果要与es版本对上,请下载对应大版本的相近小版本的插件包,然后修改plugin-descriptor.properties文件中的参数值:
elasticsearch.version = 自建Elasticsearch的版本
1.3 下载地址
下载地址推荐: https://elasticsearch.cn/download/
二、环境部署
ES集群的部署主要分为以下几步:
1)创建es用户
2)安装ntp服务
3)配置系统文件
4)安装elasticsearch
5)安装kibana
6)安装相关插件
7)注册服务
8)设置密码
注:本次环境部署主要以shell脚本的形式实现,每小节会展示对应函数,本次集群节点数为3,节点数较少,未利用ansiable实现分发安装。
2.1 创建es用户
这里我们直接创建es用户即可,系统会默认归属于es用户组,会在Linux文件夹/home建立一个以用户名为名的文件夹。若先建立组再创建用户添加到组中会导致我们使用es用户时环境变量显示问题。
shell脚本:
#step1:添加es用户
AddUser() {
#用户组名及用户名
user=es
echo -e "\033[47;30;30m=========开始添加ES用户=========\033[0m"
#create user in not exists
egrep "^$user" /etc/passwd >&/dev/null
if [ $? -ne 0 ]; then
echo "es用户不存在,新建es用户"
adduser $user
#检查用户是否新建成功
egrep "^$user" /etc/passwd >&/dev/null
if [ $? -eq 0 ]; then
echo "新建es用户成功!"
fi
else
echo "es用户已存在,无需新建!"
fi
echo -e "\033[33;30;31m======================================================\033[0m"
echo -e "\033[47;30;30m=========添加ES用户操作完成=========\033[0m"
}
查看用户目录:
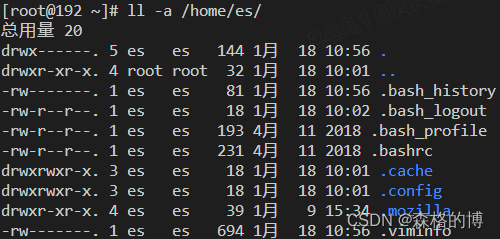
有如上目录结构即为成功。
注:脚本中,将命令的结果写入&/dev/null,成功则返回0,$?为取上一次执行命令的结果,下述脚本函数类似。
2.2 安装ntp服务
NTP: Network Time Protocol,网络时间协议。它的作用就是来做时间同步,类比小时候我们家中墙上挂的钟表,走一段时间会变慢,我们就要去根据网络时间去调整一样。这样一来就为网络内设备提供了标准的时间基准。倘若不进行设置,那么各个服务器的延迟太大会出问题。
shell脚本:
#step2:设置ntp服务
Ntp_Install() {
echo -e "\033[33;30;31m======================================================\033[0m"
echo -e "\033[47;30;30m=========开始设置ntp时间同步=========\033[0m"
#install if not installed
rpm -qa | grep ntp >&/dev/null
if [ $? -eq 0 ]; then
echo "ntp installed"
ntpq -p >&/dev/null
if [ $? -eq 0 ]; then
echo "ntp正常运行中!"
else
echo "ntp服务异常!"
fi
else
echo "开始安装ntp"
yum -y install ntp
echo "开始配置ntp"
echo "server ntp.aliyun.com iburst" >>/etc/ntp.conf
echo "server ntp1.aliyun.com iburst" >>/etc/ntp.conf
echo "server ntp2.aliyun.com iburst" >>/etc/ntp.conf
echo "server ntp3.aliyun.com iburst" >>/etc/ntp.conf
echo "server ntp4.aliyun.com iburst" >>/etc/ntp.conf
echo "server ntp5.aliyun.com iburst" >>/etc/ntp.conf
systemctl stop ntpd
systemctl enable ntpd
systemctl start ntpd
ntpq -p >&/dev/null
if [ $? -eq 0 ]; then
echo "ntp正常运行中!"
else
echo "ntp服务异常!"
fi
fi
echo -e "\033[33;30;31m======================================================\033[0m"
echo -e "\033[47;30;30m=========设置ntp时间同步操作完成=========\033[0m"
}
在这里,我们和阿里云的NTF服务器时间对齐。
2.3 配置系统文件
这里主要涉及三项内容的设置:
1)limit.conf
该文件涉及到不同对象对系统资源访问的限制。
我们需要更改 nofile(最大打开的文件数)和nproc(进程的最大数目)两个参数的默认值。其中也分soft和hard限制,soft指的是当前系统生效的设置值,软限制也可以理解为警告值。
2)sysctl.conf
该文件包含一些Linux系统的高级选项,与/proc/sys下的内核文件中的变量存在着对应关系。
**vm.max_map_count:**系统虚拟内存映射数,需要大于262144,否则在es的启动过程中会出现如下错误
max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
fs.file-max: 最大打开的文件数,这里的设置和上面 limit.conf 的nofile参数 作用大差不差。
3)交换区swap
对于用Java开发的es而言,会涉及 JVM 的GC机制,但是对于倒排索引就需要常驻内存,在es进行 gc 的时候会遍历所有用到的堆的内存,如果这部分内存是被 swap 出去了,遍历的时候就会有磁盘IO,带来的性能危害将是致命的。
shell脚本:
#step3.1:limits.conf
Limit_Conf() {
echo -e "\033[33;30;31m======================================================\033[0m"
echo -e "\033[47;30;30m=========开始配置limits.conf=========\033[0m"
if [ $(ulimit -n) -ne 65535 ]; then
echo "* soft nofile 65535" >>/etc/security/limits.conf
echo "* hard nofile 65535" >>/etc/security/limits.conf
echo "* soft nproc 65535" >>/etc/security/limits.conf
echo "* hard nproc 65535" >>/etc/security/limits.conf
fi
ulimit -a
echo -e "\033[33;30;31m======================================================\033[0m"
echo -e "\033[47;30;30m=========配置limits.conf完成=========\033[0m"
}
#step3.2:sysctl.conf
Sysctl_Conf() {
echo -e "\033[33;30;31m======================================================\033[0m"
echo -e "\033[47;30;30m=========开始调整sysctl.conf=========\033[0m"
if [ $(cat /proc/sys/vm/max_map_count) -lt 262144 ]; then
echo "vm.max_map_count小于262144"
echo "设置vm.max_map_count为655360"
echo "vm.max_map_count = 655360" >>/etc/sysctl.conf
sysctl -p
if [ $(cat /proc/sys/vm/max_map_count) -eq 655360 ]; then
echo "当前vm.max_map_count:655360,设置成功!"
fi
else
echo "vm.max_map_count大于262144,无需更改!"
fi
if [ $(cat /proc/sys/fs/file-max) -lt 65535 ]; then
echo "fs.file-max小于65535"
echo "设置fs.file-max为65536"
echo "fs.file-max = 65535" >>/etc/sysctl.conf
sysctl -p
if [ $(cat /proc/sys/fs/file-max) -lt 65536 ]; then
echo "当前fs.file-max:65536,设置成功!"
fi
else
echo "fs.file-max大于65535,无需更改!"
fi
swappiness=$(cat /proc/sys/vm/swappiness)
if [ $swappiness -ne 0 ]; then
echo "vm.swappiness当前值为:$swappiness,需更改!"
swapoff -a
echo "vm.swappiness = 0" >>/etc/sysctl.conf
sysctl -p
if [ $(cat /proc/sys/vm/swappiness) -ne 0 ]; then
echo "vm.swappiness当前值为0,设置成功!"
fi
else
echo "vm.swappiness当前值为0,无需更改!"
fi
echo -e "\033[33;30;31m======================================================\033[0m"
echo -e "\033[47;30;30m=========调整sysctl.conf完毕=========\033[0m"
}
2.4 安装elasticsearch
对于es这种开箱即用的软件,安装配置过程十分舒适,只需要对配置文件进行简单设置即可使用。主要设置参数有:
1)基本设置
- cluster.name:集群名称,三个节点名称需相同。
- node.name:节点名称,这里用IP来命名。
- http.port:es将要使用的自定义端口。
- transport.port:es的通信端口。
- network.host:网络主机的IP。
- node.master:是否可以当选主节点。
- node.data:是否可以称为数据节点。
- path.data:数据存储路径。
- path.logs:日志存储路径。
- discovery.seed_hosts:初始的主机列表
- cluster.initial_master_nodes:一组符合初始主节点条件的节点。
- reindex.remote.whitelist:reindex的远程白名单。
2)x-pack设置
- xpack.security.enabled:是否开启x-pack。
- xpack.security.transport.ssl.enabled:x-pack是否开启ssl。
- xpack.security.transport.ssl.verification_mode:x-pack认证模式。
- xpack.security.transport.ssl.keystore.path:x-pack密钥库路径。
- xpack.security.transport.ssl.truststore.path:x-pack信任库路径。
shell脚本:
#step4:安装elasticsearch
Es_Install() {
echo -e "\033[33;30;31m======================================================\033[0m"
echo -e "\033[47;30;30m=========开始安装ElasticSearch=========\033[0m"
echo "ElasticSearch版本为:$version"
#create if not exists
mkdir -pv /data/es
mkdir -pv /data/package
cd /data/package
ll /data/package/ | grep "elasticsearch-$version-linux-x86_64.tar.gz" >&/dev/null
if [ $? -ne 0 ]; then
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-$es_version-linux-x86_64.tar.gz
echo -e "\033[47;30;30m=========下载完成,开始解压=========\033[0m"
tar -zxf elasticsearch-$version-linux-x86_64.tar.gz elasticsearch-$version
echo -e "\033[47;30;30m \033[0m"
echo -e "\033[47;30;30m=========解压完成=========\033[0m"
else
echo -e "\033[47;30;30m=========安装包已存在,开始解压=========\033[0m"
tar -zxf elasticsearch-$version-linux-x86_64.tar.gz elasticsearch-$version
#mv elasticsearch-$version-linux-x86_64 elasticsearch-$version
echo -e "\033[47;30;30m \033[0m"
echo -e "\033[47;30;30m=========解压完成=========\033[0m"
fi
echo -e "\033[47;30;30m=========进入目录./elasticsearch-7.5.1=========\033[0m"
cd elasticsearch-$version
echo -e "\033[47;30;30m=========开始设置ElasticSearch的配置文件=========\033[0m"
echo "cluster.name: $clusterName" >>./config/elasticsearch.yml
echo "node.name: $self_IP" >>./config/elasticsearch.yml
echo "http.port: 9200" >>./config/elasticsearch.yml
echo "transport.port: 9300" >>./config/elasticsearch.yml
echo "network.host: 0.0.0.0" >>./config/elasticsearch.yml
echo "node.master: true" >>./config/elasticsearch.yml
echo "node.data: true" >>./config/elasticsearch.yml
echo "path.data: ./data" >>./config/elasticsearch.yml
echo "path.logs: ./logs" >>./config/elasticsearch.yml
echo "discovery.seed_hosts: [\"$node1_IP:9300\",\"$node2_IP:9300\",\"$node3_IP:9300\"]" >>./config/elasticsearch.yml
echo "cluster.initial_master_nodes: ["$node1_IP","$node2_IP","$node3_IP"]" >>./config/elasticsearch.yml
echo "reindex.remote.whitelist: [\"10.8.142.78:9200\",\"10.8.130.148:9200\",\"10.8.142.237:9200\",\"10.8.132.201:9200\"]" >>./config/elasticsearch.yml
echo "#x-pack" >>./config/elasticsearch.yml
echo "#xpack.security.enabled: true" >>./config/elasticsearch.yml
echo "#xpack.security.transport.ssl.enabled: true" >>./config/elasticsearch.yml
echo "#xpack.security.transport.ssl.keystore.path: elastic-certificates.p12" >>./config/elasticsearch.yml
echo "#xpack.security.transport.ssl.truststore.path: elastic-certificates.p12" >>./config/elasticsearch.yml
sed -i "s/-Xms1g/-Xms8g/g" ./config/jvm.options
sed -i "s/-Xmx1g/-Xmx8g/g" ./config/jvm.options
cd ..
mkdir -pv /data/es
mv elasticsearch-$version /data/es/
chown -R $user:$user /data/es
}
注:先将x-pack的内容注释掉,不然es会起不来。
2.5 安装kibana
这里将Kibana单独部署至一台机器,为了让es集群的性能更佳,Kibana的配置较为简单,主要设置三个参数:
- server.port:服务占用的端口。
- server.host:服务的主机。
- elasticsearch.hosts:es集群的主机。
shell脚本:
#step5:安装kibana
Kibana_Install() {
echo -e "\033[33;30;31m======================================================\033[0m"
echo -e "\033[47;30;30m=========开始安装Kibana=========\033[0m"
echo "Kibana版本为:$version"
#create if not exists
#mkdir -pv /data/es
mkdir -pv /data/pro_oa_es_cluster/
mkdir -pv /data/package
cd /data/package
ll /data/package/ | grep "kibana-$version-linux-x86_64.tar.gz" >&/dev/null
if [ $? -ne 0 ]; then
wget https://artifacts.elastic.co/downloads/kibana/kibana-$version-linux-x86_64.tar.gz
echo -e "\033[47;30;30m=========下载完成,开始解压=========\033[0m"
tar -zxf kibana-$version-linux-x86_64.tar.gz
mv kibana-$version-linux-x86_64 kibana-$version
echo -e "\033[47;30;30m \033[0m"
echo -e "\033[47;30;30m=========解压完成=========\033[0m"
else
echo -e "\033[47;30;30m=========安装包已存在,开始解压=========\033[0m"
tar -zxf kibana-$version-linux-x86_64.tar.gz
mv kibana-$version-linux-x86_64 kibana-$version
echo -e "\033[47;30;30m \033[0m"
echo -e "\033[47;30;30m=========解压完成=========\033[0m"
fi
echo -e "\033[47;30;30m=========进入目录./kibana-$version=========\033[0m"
cd kibana-$version
echo -e "\033[47;30;30m=========开始设置Kibana的配置文件=========\033[0m"
echo "server.port: 5601" >>./config/kibana.yml
echo "server.host: 0.0.0.0" >>./config/kibana.yml
echo "elasticsearch.hosts: [\"http://$node1_IP:9200\",\"http://$node1_IP:9200\",\"http://$node1_IP:9200\"]" >>./config/kibana.yml
cd ..
mv kibana-$version /data/pro_oa_es_cluster/
}
2.6 安装相关插件
我们只需要把es的插件下载解压,放在es目录下的plugins文件夹下,再重启es,通过Kibana,GET /_cat/_plugins就可看到我们安装的插件,关于版本问题阿里的oss版本问题已在1.2章节说明。
如果想了解更多关于OSS的可以查看:通过OSS将自建Elasticsearch数据迁移至阿里云
shell脚本:
#step6.1:安装IK分词器
IK_Install() {
echo -e "\033[33;30;31m======================================================\033[0m"
echo -e "\033[47;30;30m=========开始配置IK分词器=========\033[0m"
echo "IK分词器版本为:$version"
#create if not exists
mkdir -pv /data/es
mkdir -pv /data/package
cd /data/package
#ll /data/package/ | grep "elasticsearch-analysis-ik-$version.zip"
cd /data/package/
if [ $? -ne 0 ]; then
#下载太慢,提前放至 /tmp
mv /tmp/elasticsearch-analysis-ik-$version.zip /data/package/
#wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v$version/elasticsearch-analysis-ik-$version.zip
echo -e "\033[47;30;30m=========下载完成,开始解压=========\033[0m"
unzip -q elasticsearch-analysis-ik-$version.zip -d analysis-ik
echo -e "\033[47;30;30m \033[0m"
echo -e "\033[47;30;30m=========解压完成=========\033[0m"
else
echo -e "\033[47;30;30m=========安装包已存在,开始解压=========\033[0m"
unzip -q elasticsearch-analysis-ik-$version.zip -d analysis-ik
echo -e "\033[47;30;30m \033[0m"
echo -e "\033[47;30;30m=========解压完成=========\033[0m"
fi
mv analysis-ik /data/es/elasticsearch-$version/plugins/
}
#step6.2:安装repository-oss
Oss_Install() {
echo -e "\033[33;30;31m======================================================\033[0m"
echo -e "\033[47;30;30m=========开始配置repository-oss=========\033[0m"
echo "IK分词器版本为:$version"
#create if not exists
mkdir -pv /data/es
mkdir -pv /data/package
cd /data/package
#ll /data/package/ | grep "elasticsearch-repository-oss-7.4.0.1.zip"
cd /data/package/
if [ $? -ne 0 ]; then
#下载太慢,提前放至 /tmp
mv /tmp/elasticsearch-repository-oss-7.4.0.1.zip /data/package/
#wget https://github.com/aliyun/elasticsearch-repository-oss/releases/download/v7.4.0/elasticsearch-repository-oss-7.4.0.1.zip
echo -e "\033[47;30;30m=========下载完成,开始解压=========\033[0m"
unzip -q elasticsearch-repository-oss-7.4.0.1.zip -d repository-oss
echo -e "\033[47;30;30m \033[0m"
echo -e "\033[47;30;30m=========解压完成=========\033[0m"
else
echo -e "\033[47;30;30m=========安装包已存在,开始解压=========\033[0m"
unzip -q elasticsearch-repository-oss-7.4.0.1.zip -d repository-oss
echo -e "\033[47;30;30m \033[0m"
echo -e "\033[47;30;30m=========解压完成=========\033[0m"
fi
sed -i "s/elasticsearch.version=7.4.0/elasticsearch.version=7.5.1/g" ./repository-oss/plugin-descriptor.properties
mv repository-oss /data/es/elasticsearch-$version/plugins/
}
2.7 注册服务
为elasticsearch和kibana注册服务,便于我们的管理。
shell脚本:
SignUp_Es_Service() {
ll /usr/lib/systemd/system/elasticsearch.service >&/dev/null
if [ $? -eq 0 ]; then
echo -e "\033[47;30;30m=========删除原elasticsearch.service文件=========\033[0m"
cd /usr/lib/systemd/system/
rm -rf elasticsearch.service
fi
echo -e "\033[47;30;30m=========注册es服务=========\033[0m"
cat >/usr/lib/systemd/system/elasticsearch.service <<EOF
[Unit]
Description=elasticsearch
After=network.target
[Service]
Type=forking
User=es
ExecStart=/data/es/elasticsearch-$version/bin/elasticsearch -d
PrivateTmp=true
# 指定此进程可以打开的最大文件数
LimitNOFILE=655350
# 指定此进程可以打开的最大进程数
LimitNPROC=655350
# 最大虚拟内存
LimitAS=infinity
# 最大文件大小
LimitFSIZE=infinity
# 超时设置 0-永不超时
TimeoutStopSec=0
# SIGTERM是停止java进程的信号
KillSignal=SIGTERM
# 信号只发送给给JVM
KillMode=process
# java进程不会被杀掉
SendSIGKILL=no
# 正常退出状态
SuccessExitStatus=143
[Install]
WantedBy=multi-user.target
EOF
chmod 777 /usr/lib/systemd/system/elasticsearch.service
systemctl daemon-reload
systemctl enable elasticsearch.service
systemctl start elasticsearch.service
}
#step7.2:注册kibana服务
SignUp_Kibana_Service() {
ll /usr/lib/systemd/system/kibana.service >&/dev/null
if [ $? -eq 0 ]; then
echo -e "\033[47;30;30m=========删除原kibana.service文件=========\033[0m"
cd /usr/lib/systemd/system/
rm -rf kibana.service
fi
echo -e "\033[47;30;30m=========注册kibana服务=========\033[0m"
cat >/usr/lib/systemd/system/kibana.service <<EOF
[Unit]
Description=kibana
After=network.target
[Service]
Type=simple
User=root
ExecStart=/data/pro_oa_es_cluster/kibana-$version/bin/kibana --allow-root
PrivateTmp=true
# 指定此进程可以打开的最大文件数
LimitNOFILE=655350
# 指定此进程可以打开的最大进程数
LimitNPROC=655350
# 最大虚拟内存
LimitAS=infinity
# 最大文件大小
LimitFSIZE=infinity
# 超时设置 0-永不超时
TimeoutStopSec=0
# SIGTERM是停止java进程的信号
KillSignal=SIGTERM
# 信号只发送给给JVM
KillMode=process
# java进程不会被杀掉
SendSIGKILL=no
# 正常退出状态
SuccessExitStatus=143
[Install]
WantedBy=multi-user.target
EOF
chmod 777 /usr/lib/systemd/system/kibana.service
systemctl daemon-reload
systemctl enable kibana.service
systemctl start kibana.service
}
注意自行修改脚本的start表达式的路径。
2.8 es集群设置密码
对于现在的es还是一个“裸奔”状态,为了防止他人恶意创建节点加入集群,我们需要开启x-pack为集群设置密码。
1)开启x-pack功能
之前我们已经在配置文件中添加了xpack的配置,现在只需将注释取消即可。

sed -i 's/#xpack.security/xpack.security/g' /data/es/elasticsearch-7.5.1/config/elasticsearch.yml

2)生成TSL和身份验证
利用es自带elasticsearch-certutil的命令生成证书,各节点通过证书进行安全通信。
cd /data/es/elasticsearch-7.5.1/bin/
./elasticsearch-certutil cert -out config/elastic-certificates.p12 -pass ""
将config/目录下生成的证书elastic-certificates.p12复制到其他两个节点的config目录下。
修改证书权限
# 注意:默认证书权限是600,运行elasticsearch程序的用户没有权限读取,会造成elasticsearch启动失败
chmod 644 elastic-certificates.p12
3)重启es集群
完成上面两步骤后,重启集群使新配置生效。
4)手动设置密码
进入某个节点的bin目录下设置密码,其他节点会自动同步数据。
./elasticsearch-setup-passwords interactive
# 输出结果
Initiating the setup of passwords for reserved users elastic,apm_system,kibana,logstash_system,beats_system,remote_monitoring_user.
You will be prompted to enter passwords as the process progresses.
Please confirm that you would like to continue [y/N]y # 输入y
# 直接输入密码,然后再重复一遍密码,中括号里是账号
Enter password for [elastic]:
Reenter password for [elastic]:
Enter password for [apm_system]:
Reenter password for [apm_system]:
Enter password for [kibana]:
Reenter password for [kibana]:
Enter password for [logstash_system]:
Reenter password for [logstash_system]:
Enter password for [beats_system]:
Reenter password for [beats_system]:
Enter password for [remote_monitoring_user]:
Reenter password for [remote_monitoring_user]:
Changed password for user [apm_system]
Changed password for user [kibana]
Changed password for user [logstash_system]
Changed password for user [beats_system]
Changed password for user [remote_monitoring_user]
Changed password for user [elastic]
也可以自动生成密码,./elasticsearch-setup-passwords auto,生成后及时保存密码信息。
三、总结
到这里我们的es集群的搭建就完成了,密码设置并未使用脚本配置,后续希望借助ansiable改善安装的流程。