目录
一、业务性编程和广度能力考查
(一)基本定义
(二)必要性分析
二、高频考查样题(编程+扩展问法)
考题1: 用java 代码实现一个死锁用例,说说怎么解决死锁问题?(高频考点)
基本编程能力考查
扩展能力深入
1. 解决死锁问题需要采取的一些常见的方法和策略你能说说吗?
2.回到用例代码下,如何解决死锁问题呢?请修改代码。
3.你能总结下死锁发生的原因吗?
考题2: 请实现让10个任务同时并发启动?(高频考点)
基本编程能力考查
扩展能力深入
1.如果我想确保所有任务完成后再进行后续操作,该如何实现呢?
2.可以模拟增加任务执行时间后,那如何感知处理任务执行过程中的异常呢?
3.如果我想在任务执行后还有后续的其他操作,这个时候该如何进行处理呢?
4.如果想取消正在执行的任务又该如何呢?
5.了解过CompletableFuture吗?说说你对其的理解。
6.如果该方式直接采取CompletableFuture如何实现,给出代码片段。
7.处理任务执行过程中的异常?链式处理任务结果?请回忆CompletableFuture功能点,任意给出一种实现方式,给出代码片段。
考题3 : 请合理的使用Queue来实现一个高并发的生产/消费的场景,给些核心的代码片段。Queue直接使用LinkedList即可(高频考点)
基本编程能力考查
扩展能力深入
1.Java 提供了许多并发容器,如 BlockingQueue,它简化了生产者-消费者模式的实现,并提供了更好的性能和更少的错误机会。如果换做使用BlockingQueue的话,这段代码又该如何写呢?
2.你知道底层BlockingQueue是如何保证你的本次实现的吗?
3.知道高效并发容器 Disruptor吗?这部分是否可以采用其性能会更好?写下关键代码或简单说下Disruptor的原理?
考题4: 考虑到下面一种场景:有一个用户数据接口,要求在 50ms 内返回数据。它的调用逻辑非常复杂,打交道的接口也非常多,需要从 20 多个接口汇总数据。这些接口,最小的耗时也要 20ms,哪怕全部都是最优状态,算下来也需要 20*20 = 400ms。 为了满足要求在 50ms 内返回数据,该如何解决呢?(高频考点)
基本编程能力考查
扩展能力深入
设计一个高效的缓存机制可以显著减少接口调用的频率,并加快系统的响应速度,这个是否有考虑到呢?说下一般高效缓存机制设计方案需要思考的基本内容是什么?
考题5: 默认情况下,我们的应用系统会建议启动一个默认的线程池供异步任务使用,这个线程池一般都会自定义初始化,请你直接写一个自定义的线程池?(高频考点)
基本编程能力考查
扩展能力深入
1.为什么要使用线程池?
2.线程池的线程数量确定?状态分析?关闭方式?请你大致说说。
3.核心线程池ThreadPoolExecutor的参数/常见线程池的创建参数是什么样的?(高频考点)
4.ThreadPoolExecutor的工作流程(高频考点)
5.new ThreadPoolExecutor(10,100,10,TimeUnit.MILLISECONDS,new LinkedBlockingQueue(10));一个这样创建的线程池,当已经有10个任务在运行时,第11个任务提交到此线程池执行的时候会发生什么,为什么?
考题6: SimpleDateFormat 是我们经常用到的日期处理类,但在多线程运行环境下,通过 sonar 扫描提示不可用,比如下面的测试代码,你可以说下其可能运行的结果会有什么问题?(高频考点)
基本编程能力考查
扩展能力深入
1.请解释为什么 SimpleDateFormat 不是线程安全的?
2.SimpleDateFormat 不是线程安全的,那如何在多线程环境中安全地使用它?
3.那请按你说的方法修改代码来验证一下?
4.你在平时多线程相关的编程中还遇到过哪些基本问题呢?请具体说说(面试官会经常问你在多线程使用中遇到的一些问题,以此来判断你实际的应用情况)。
考题7: 如果要你基于 HashMap 和 双向链表实现 LRU,你能说一下整体的设计思路吗?(高频考点)
基本编程能力考查
扩展能力深入
1.当前实现的LRU缓存已经在时间复杂度上达到了O(1),但还有没有其他方式可以进一步提升性能?
2.LRU是一种缓存替换策略,但还有其他的策略如LFU(最少频繁使用)或者FIFO(先进先出),你对这些策略有了解吗?
3.现在重新思考:设计一个支持过期时间的LRU缓存系统(并给出代码实现)。
考题8: 一个网站有 20 亿 url 存在一个黑名单中,这个黑名单要怎么存?若此时随便输入一个 url,你如何快速判断该 url 是否在这个黑名单中?并且需在给定内存空间(比如:500M)内快速判断出。
基本编程能力考查
扩展能力深入
1.布隆过滤器有误判率吗?为啥会误判,举例说明?
2.如何处理布隆过滤器的误判率?在实际应用中有哪些补救措施?
3.如何在插入超过预期数量的元素时处理布隆过滤器的误判率增加问题?
4.布隆过滤器可以合并吗?如何实现?误判率会增加吗?
5.Google的Guava库提供了高效的布隆过滤器实现,如果使用其现成的内容,上面代码该如何实现?
6.Guava的BloomFilter是如何控制误判率和内存使用的?
7.Guava的BloomFilter是否支持扩展,即动态增加元素后仍保持较低的误判率?
8.Guava的BloomFilter是线程安全的吗?如果不是,如何确保线程安全?给出实现?
方法1:显式锁---使用显式锁可以确保在对BloomFilter的每次访问(读或写)时,都只有一个线程能够执行操作。
方法2:使用并发集合---在这种方法中,我们将多个布隆过滤器分片存储在一个并发集合(如ConcurrentHashMap)中,通过将元素散列到不同的布隆过滤器分片来减少争用。
方法3:使用ReadWriteLock---使用ReadWriteLock可以在读操作不需要互斥的情况下提高并发性,只有在写操作时才进行锁定。
考查业务性综合编程能力和知识广度能力不仅是企业选拔优秀开发人员的有效手段,也是开发人员自我提升和职业发展的重要途径。通过重视基本功与业务性编程能力,企业能够更好地实现项目目标,提升整体竞争力;而开发人员则能在激烈的市场竞争中脱颖而出,获得更多职业发展机会。本文聚焦高频的业务性综合编程和知识广度考查题库进行一次总结。传统历史考题见:
高频面试题基本总结回顾(含笔试高频算法整理)_面试题的基本总结回顾(以以往面试过的问题做基本总结)-CSDN博客文章浏览阅读10w+次,点赞323次,收藏2.7k次。1.自我介绍+项目介绍+项目细节/难点提问-------这个主要看个人的经历了,每个人都不一样2.基础知识点考核---------还是可以去增强自己的,也是这次的主要的一些总结思路3.算法题-----------一般都是LeetCode高频题,这个得在找工作之前的好好的练习(d对常见的高频题进行总结分析,见对应的链接提示)_面试题的基本总结回顾(以以往面试过的问题做基本总结)https://zyfcodes.blog.csdn.net/article/details/100706167?spm=1001.2014.3001.5502
一、业务性编程和广度能力考查
(一)基本定义
业务性编程能力指的是开发人员在理解和实现具体业务需求方面的能力。这不仅包括对编程语言、框架和工具的熟练掌握,还涉及对业务逻辑、流程和领域知识的深入理解和灵活运用。在编程结束后或过程中需要扩展分析考查面试者的知识广度。
(二)必要性分析
相对传统的letcode题库和剑指offer题库而言(如下表格的高频考题汇总),更加贴合专业性的考查能力。
| 归属内容 | 对应总结链接 | 笔试定义 | 代表题目展示 |
| 数学思维相关考题 | 数学思维高频考题 | Letcode高频考题 | 众数、快乐数、丑数、回文数、平方根、超级次方、二进制中1的个数等 |
| 字符串相关考题 | 字符串高频考题 | Letcode高频考题 | 最长公共子串、最长回文子串、最长无重复字符子串、最小覆盖子串、字符串相乘、中文数字表达转实际数字格式等 |
| 数组相关考题 | 数组高频考题 | Letcode高频考题 | 找到数组 A 元素组成的小于 n的最大整数、两数之和、三数之和、搜索旋转排序数组、只出现一次的数字、最大子序列、最长连续递增序列、最长公共前缀等 |
| 散列相关考题 | 散列高频考题 | Letcode高频考题 | 重复字符的最长子串、字母异位词分组、LRU缓存机制、重复元素、同构字符串等 |
| 栈相关考题 | 栈高频考题 | Letcode高频考题 | 有效的括号、最小栈、用栈实现队列、用队列实现栈、逆波兰表达式求值、用数组实现一个栈、基本数学运算表达式求值等 |
| 队列相关考题 | 队列高频考题 | Letcode高频考题 | 用队列实现栈、使用栈实现队列、设计循环队列、滑动窗口最大值、队列的最大值、用数组实现一个队列等 |
| 链表相关考题 | 链表高频考题 | Letcode高频考题 | 反转链表、链表中环的检测、链表中环的入口点、删除链表中倒数第K个节点、两个链表的第一个公共节点、链表的中间节点、合并两个有序链表、删除链表中的重复元素等 |
| 树相关考题 | 树高频考题 | Letcode高频考题 | 二叉树的最大深度、对称二叉树、二叉树的最近公共祖先、二叉树的直径、二叉树的层平均值、二叉树的镜像、二叉树的最大宽度、平衡二叉树等 |
| 排序相关考题 | 排序算法高频考题 | Letcode高频考题 | 冒泡排序、鸡尾酒排序、插入排序、选择排序、快速排序、归并排序、堆排序、Top K 问题分析、使用堆排序思想实现优先级队列、计数排序、桶排序、基数排序等 |
| 剑指offer考题 | 剑指offer所有高频考题 | 剑指offer考题汇总分析 | 剑指offer全部高频题罗列 |
| 动态规划考题 | 动态规划高频考题 | Letcode高频考题 | 最大子序和、最长上升子序列、最长公共子序列、最大子数组乘积、编辑距离、单词拆分、爬楼梯、股票买卖问题、最佳买卖股票时机含冷冻期等 |
| 图论考题 | 图论高频考题(国内一般不考) | 进阶分析考题 | 岛屿数量、网络延迟时间、单源最短路径、负权最短路径问题、具有最小生成树的连通图的最小代价、找到最终的安全状态等 |
二、高频考查样题(编程+扩展问法)
考题1: 用java 代码实现一个死锁用例,说说怎么解决死锁问题?(高频考点)
基本编程能力考查
死锁是一个并发编程中常见的问题,它发生在两个或更多线程互相持有对方所需要的资源而无法继续执行的情况。下面是用 Java 代码实现一个简单的死锁示例:
package org.zyf.javabasic.test.thread;
/**
* @program: zyfboot-javabasic
* @description: 死锁用例
* @author: zhangyanfeng
* @create: 2023-08-13 22:37
**/
public class DeadlockExample {
private static Object resource1 = new Object();
private static Object resource2 = new Object();
public static void main(String[] args) {
Thread thread1 = new Thread(() -> {
synchronized (resource1) {
System.out.println("Thread 1: Holding resource 1...");
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("Thread 1: Waiting for resource 2...");
synchronized (resource2) {
System.out.println("Thread 1: Acquired resource 2!");
}
}
});
Thread thread2 = new Thread(() -> {
synchronized (resource2) {
System.out.println("Thread 2: Holding resource 2...");
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("Thread 2: Waiting for resource 1...");
synchronized (resource1) {
System.out.println("Thread 2: Acquired resource 1!");
}
}
});
thread1.start();
thread2.start();
}
}在这个示例中,两个线程(thread1 和 thread2)分别持有 resource1 和 resource2,并试图获取对方的资源。由于每个线程都在等待另一个线程释放资源,因此这段代码会导致死锁。
扩展能力深入
1. 解决死锁问题需要采取的一些常见的方法和策略你能说说吗?
解决死锁问题需要采取一些常见的方法和策略,比如:
- 避免使用多个锁:尽量减少在代码中使用多个锁,这样可以减少死锁的可能性。如果有多个锁,确保线程按照相同的顺序获取锁,这样可以避免循环等待导致的死锁。
- 使用超时机制:在尝试获取锁时,设置一个超时时间,如果在超时时间内无法获取到锁,则放弃该操作,释放已经持有的锁,并进行回退操作,避免死锁发生。
- 使用Lock对象:Java提供了`java.util.concurrent.locks.Lock`接口,它比传统的synchronized块更加灵活,可以使用`tryLock()`方法尝试获取锁,并在获取失败时进行后续处理,从而避免死锁。
- 按顺序获取锁:在使用多个锁的情况下,确保线程按照固定的顺序获取锁,这样可以避免循环等待。
- 死锁检测:有些系统和工具可以进行死锁检测,监测程序运行时的锁和资源使用情况,如果发现潜在的死锁情况,可以采取相应的措施,例如中断某个线程,解除死锁。
请注意,死锁问题可能比较复杂,解决方法需要根据具体的代码和场景来确定。在设计并发程序时,要注意多线程之间的资源竞争和互斥关系,合理地选择锁和同步方式,并进行充分的测试和验证,以确保程序在运行时不会出现死锁问题。
2.回到用例代码下,如何解决死锁问题呢?请修改代码。
从前面的回答中选取一种方法进行解法,如按照固定顺序获取锁,具体代码如下:
package org.zyf.javabasic.test.thread;
/**
* @program: zyfboot-javabasic
* @description: 通过锁排序解决死锁的示例
* @author: zhangyanfeng
* @create: 2023-08-13 22:39
**/
public class DeadlockSolutionExample {
private static final Object resource1 = new Object();
private static final Object resource2 = new Object();
public static void main(String[] args) {
Thread thread1 = new Thread(() -> {
acquireLocks(resource1, resource2);
try {
System.out.println("Thread 1: Holding resource 1 and resource 2...");
// Perform some work while holding the locks
} finally {
releaseLocks(resource1, resource2);
}
});
Thread thread2 = new Thread(() -> {
acquireLocks(resource1, resource2);
try {
System.out.println("Thread 2: Holding resource 1 and resource 2...");
// Perform some work while holding the locks
} finally {
releaseLocks(resource1, resource2);
}
});
thread1.start();
thread2.start();
}
private static void acquireLocks(Object lock1, Object lock2) {
boolean acquired = false;
while (!acquired) {
synchronized (lock1) {
synchronized (lock2) {
acquired = true;
}
}
if (!acquired) {
// Sleep for a short period before trying again
try {
Thread.sleep(50);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
private static void releaseLocks(Object lock1, Object lock2) {
// No action needed for synchronized blocks as locks are automatically released
}
}
当然也可以使用超时机制,用 java.util.concurrent.locks.ReentrantLock 来实现:
package org.zyf.javabasic.test.thread;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
import java.util.concurrent.TimeUnit;
/**
* @program: zyfboot-javabasic
* @description: 通过超时机制解决死锁的示例
* @author: zhangyanfeng
* @create: 2023-08-13 22:37
**/
public class DeadlockSolutionWithTimeout {
private static final Lock lock1 = new ReentrantLock();
private static final Lock lock2 = new ReentrantLock();
public static void main(String[] args) {
Thread thread1 = new Thread(() -> {
try {
if (acquireLocks(lock1, lock2)) {
try {
System.out.println("Thread 1: Holding lock1 and lock2...");
// Perform some work while holding the locks
} finally {
lock1.unlock();
lock2.unlock();
}
} else {
System.out.println("Thread 1: Could not acquire locks, avoiding deadlock.");
}
} catch (InterruptedException e) {
e.printStackTrace();
}
});
Thread thread2 = new Thread(() -> {
try {
if (acquireLocks(lock2, lock1)) {
try {
System.out.println("Thread 2: Holding lock2 and lock1...");
// Perform some work while holding the locks
} finally {
lock2.unlock();
lock1.unlock();
}
} else {
System.out.println("Thread 2: Could not acquire locks, avoiding deadlock.");
}
} catch (InterruptedException e) {
e.printStackTrace();
}
});
thread1.start();
thread2.start();
}
private static boolean acquireLocks(Lock lock1, Lock lock2) throws InterruptedException {
while (true) {
boolean gotLock1 = false;
boolean gotLock2 = false;
try {
// Try to acquire both locks with a timeout
gotLock1 = lock1.tryLock(50, TimeUnit.MILLISECONDS);
gotLock2 = lock2.tryLock(50, TimeUnit.MILLISECONDS);
} finally {
if (gotLock1 && gotLock2) {
return true; // Acquired both locks
}
if (gotLock1) {
lock1.unlock();
}
if (gotLock2) {
lock2.unlock();
}
}
// Sleep for a short period before trying again
Thread.sleep(50);
}
}
}
3.你能总结下死锁发生的原因吗?
死锁是指在并发系统中,两个或多个进程(或线程)因为争夺资源而被永久地阻塞,导致系统无法继续执行的状态。以下是导致死锁发生的常见原因:
- 互斥条件(Mutual Exclusion):某些资源一次只能被一个进程(或线程)使用,如果一个进程占用了资源,其他进程必须等待。
- 请求和保持条件(Hold and Wait):进程占有了至少一个资源,并且在等待其他进程的资源时保持对已占有资源的占用。
- 不可剥夺条件(No Preemption):资源只能由持有者显式地释放,其他进程无法抢占已被占用的资源。
- 循环等待条件(Circular Wait):多个进程形成一种循环等待资源的关系,每个进程都在等待下一个进程所占有的资源。
当这四个条件同时满足时,就可能发生死锁。当系统进入死锁状态后,没有外部干预,系统将无法恢复正常。
为了避免死锁的发生,可以采取以下策略:
- 破坏互斥条件:对于某些资源,允许多个进程共享或同时访问。
- 破坏请求和保持条件:进程请求资源时不保持已占有的资源,而是先释放已占有的资源再重新请求。
- 破坏不可剥夺条件:对于某些资源,允许系统剥夺已占有的资源,将其分配给其他进程。
- 破坏循环等待条件:通过定义资源的线性顺序,要求进程按顺序申请资源,避免形成循环等待的情况。
死锁是一种复杂的并发问题,需要细心的设计和合理的资源管理来避免。在实际开发中,可以使用死锁检测、死锁避免、死锁恢复等技术手段来处理死锁问题。
考题2: 请实现让10个任务同时并发启动?(高频考点)
基本编程能力考查
可以使用多种方法来实现让10个任务同时并发启动。下面使用ExecutorService实现:
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class ConcurrentTasks {
public static void main(String[] args) {
int numberOfTasks = 10;
ExecutorService executor = Executors.newFixedThreadPool(numberOfTasks);
for (int i = 0; i < numberOfTasks; i++) {
Runnable task = new Task("Task " + (i + 1));
executor.execute(task);
}
executor.shutdown();
}
static class Task implements Runnable {
private final String name;
public Task(String name) {
this.name = name;
}
@Override
public void run() {
System.out.println("Executing " + name);
// 在这里放置任务的逻辑
}
}
}创建了一个固定大小的线程池,大小为10,然后循环创建10个任务,并使用 executor.execute(task) 方法将任务提交到线程池中执行。由于线程池的大小为10,因此这10个任务可以同时并发启动执行。
扩展能力深入
1.如果我想确保所有任务完成后再进行后续操作,该如何实现呢?
可以使用 awaitTermination 方法来等待所有任务完成:
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
public class ConcurrentTasks {
public static void main(String[] args) {
int numberOfTasks = 10;
ExecutorService executor = Executors.newFixedThreadPool(numberOfTasks);
for (int i = 0; i < numberOfTasks; i++) {
Runnable task = new Task("Task " + (i + 1));
executor.execute(task);
}
executor.shutdown();
try {
if (!executor.awaitTermination(60, TimeUnit.SECONDS)) {
executor.shutdownNow();
}
} catch (InterruptedException e) {
executor.shutdownNow();
}
System.out.println("All tasks are completed.");
}
static class Task implements Runnable {
private final String name;
public Task(String name) {
this.name = name;
}
@Override
public void run() {
System.out.println("Executing " + name);
try {
Thread.sleep((long) (Math.random() * 1000));
} catch (InterruptedException e) {
System.err.println(name + " was interrupted.");
}
System.out.println(name + " completed.");
}
}
}
2.可以模拟增加任务执行时间后,那如何感知处理任务执行过程中的异常呢?
最直接的方式增加打印或异步处理转发通知,这里针对异常简单打印分析:
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class ConcurrentTasks {
public static void main(String[] args) {
int numberOfTasks = 10;
ExecutorService executor = Executors.newFixedThreadPool(numberOfTasks);
for (int i = 0; i < numberOfTasks; i++) {
Runnable task = new Task("Task " + (i + 1));
executor.execute(task);
}
executor.shutdown();
}
static class Task implements Runnable {
private final String name;
public Task(String name) {
this.name = name;
}
@Override
public void run() {
System.out.println("Executing " + name);
try {
// 模拟任务执行时间
if (Math.random() > 0.8) {
throw new RuntimeException("Error in " + name);
}
Thread.sleep((long) (Math.random() * 1000));
} catch (Exception e) {
System.err.println(name + " failed: " + e.getMessage());
}
System.out.println(name + " completed.");
}
}
}
3.如果我想在任务执行后还有后续的其他操作,这个时候该如何进行处理呢?
这个时候,我们应该使用 CompletionService 确保任务完成后进行操作,对应代码如下:
import java.util.concurrent.*;
public class ConcurrentTasks {
public static void main(String[] args) {
int numberOfTasks = 10;
ExecutorService executor = Executors.newFixedThreadPool(numberOfTasks);
CompletionService<String> completionService = new ExecutorCompletionService<>(executor);
for (int i = 0; i < numberOfTasks; i++) {
int taskId = i + 1;
completionService.submit(() -> {
String taskName = "Task " + taskId;
System.out.println("Executing " + taskName);
Thread.sleep((long) (Math.random() * 1000));
return taskName + " completed.";
});
}
executor.shutdown();
for (int i = 0; i < numberOfTasks; i++) {
try {
Future<String> result = completionService.take();
System.out.println(result.get());
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
}
}
}
4.如果想取消正在执行的任务又该如何呢?
可以直接模拟取消,尝试修改代码如下:
import java.util.concurrent.*;
public class ConcurrentTasks {
public static void main(String[] args) {
int numberOfTasks = 10;
ExecutorService executor = Executors.newFixedThreadPool(numberOfTasks);
Future<?>[] futures = new Future<?>[numberOfTasks];
for (int i = 0; i < numberOfTasks; i++) {
int taskId = i + 1;
futures[i] = executor.submit(() -> {
String taskName = "Task " + taskId;
System.out.println("Executing " + taskName);
try {
Thread.sleep((long) (Math.random() * 1000));
} catch (InterruptedException e) {
System.out.println(taskName + " was interrupted.");
}
System.out.println(taskName + " completed.");
});
}
// 模拟某种情况,取消所有任务
for (Future<?> future : futures) {
future.cancel(true);
}
executor.shutdown();
}
}
5.了解过CompletableFuture吗?说说你对其的理解。
CompletableFuture的核心原理是基于Java的Future接口和内部的状态机实现的。它可以通过三个步骤来实现异步操作:
- 创建CompletableFuture对象:通过CompletableFuture的静态工厂方法,我们可以创建一个新的CompletableFuture对象,并指定该对象的异步操作。通常情况下,我们可以通过supplyAsync()或者runAsync()方法来创建CompletableFuture对象。
- 异步操作的执行:在CompletableFuture对象创建之后,异步操作就开始执行了。这个异步操作可以是一个计算任务或者一个IO操作。CompletableFuture会在另一个线程中执行这个异步操作,这样主线程就不会被阻塞。
- 对异步操作的处理:异步操作执行完成后,CompletableFuture会根据执行结果修改其内部的状态,并触发相应的回调函数。如果异步操作成功完成,则会触发CompletableFuture的完成回调函数;如果异步操作抛出异常,则会触发CompletableFuture的异常回调函数。
CompletableFuture的优势在于它支持链式调用和组合操作。通过CompletableFuture的then系列方法,我们可以创建多个CompletableFuture对象,并将它们串联起来形成一个链式的操作流。在这个操作流中,每个CompletableFuture对象都可以依赖于之前的CompletableFuture对象,以实现更加复杂的异步操作。
总的来说,CompletableFuture的原理是基于Java的Future接口和内部的状态机实现的,它可以以非阻塞的方式执行异步操作,并通过回调函数来处理异步操作完成后的结果。通过链式调用和组合操作,CompletableFuture可以方便地实现复杂的异步编程任务。
6.如果该方式直接采取CompletableFuture如何实现,给出代码片段。
使用 CompletableFuture 执行并发任务:
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.ExecutionException;
public class ConcurrentTasksWithCompletableFuture {
public static void main(String[] args) {
int numberOfTasks = 10;
CompletableFuture<String>[] futures = new CompletableFuture[numberOfTasks];
for (int i = 0; i < numberOfTasks; i++) {
int taskId = i + 1;
futures[i] = CompletableFuture.supplyAsync(() -> {
String taskName = "Task " + taskId;
System.out.println("Executing " + taskName);
try {
// 模拟任务执行时间
Thread.sleep((long) (Math.random() * 1000));
} catch (InterruptedException e) {
System.err.println(taskName + " was interrupted.");
}
return taskName + " completed.";
});
}
// 获取所有任务的结果
CompletableFuture<Void> allOf = CompletableFuture.allOf(futures);
allOf.thenRun(() -> {
for (CompletableFuture<String> future : futures) {
try {
System.out.println(future.get());
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
}
}).join();
System.out.println("All tasks are completed.");
}
}
7.处理任务执行过程中的异常?链式处理任务结果?请回忆CompletableFuture功能点,任意给出一种实现方式,给出代码片段。
这里可以根据自己的实际情况进行实现下,比如处理任务执行过程中的异常:
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.ExecutionException;
public class ConcurrentTasksWithCompletableFuture {
public static void main(String[] args) {
int numberOfTasks = 10;
CompletableFuture<String>[] futures = new CompletableFuture[numberOfTasks];
for (int i = 0; i < numberOfTasks; i++) {
int taskId = i + 1;
futures[i] = CompletableFuture.supplyAsync(() -> {
String taskName = "Task " + taskId;
System.out.println("Executing " + taskName);
try {
// 模拟任务执行时间
if (Math.random() > 0.8) {
throw new RuntimeException("Error in " + taskName);
}
Thread.sleep((long) (Math.random() * 1000));
} catch (InterruptedException e) {
System.err.println(taskName + " was interrupted.");
}
return taskName + " completed.";
}).exceptionally(e -> "Task failed: " + e.getMessage());
}
// 获取所有任务的结果
CompletableFuture<Void> allOf = CompletableFuture.allOf(futures);
allOf.thenRun(() -> {
for (CompletableFuture<String> future : futures) {
try {
System.out.println(future.get());
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
}
}).join();
System.out.println("All tasks are completed.");
}
}
以及链式处理任务结果如:
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.ExecutionException;
public class ConcurrentTasksWithCompletableFuture {
public static void main(String[] args) {
int numberOfTasks = 10;
CompletableFuture<String>[] futures = new CompletableFuture[numberOfTasks];
for (int i = 0; i < numberOfTasks; i++) {
int taskId = i + 1;
futures[i] = CompletableFuture.supplyAsync(() -> {
String taskName = "Task " + taskId;
System.out.println("Executing " + taskName);
try {
// 模拟任务执行时间
Thread.sleep((long) (Math.random() * 1000));
} catch (InterruptedException e) {
System.err.println(taskName + " was interrupted.");
}
return taskName + " completed.";
}).thenApply(result -> {
// 在任务完成后进一步处理结果
System.out.println("Processing result of " + result);
return result;
});
}
// 获取所有任务的结果
CompletableFuture<Void> allOf = CompletableFuture.allOf(futures);
allOf.thenRun(() -> {
for (CompletableFuture<String> future : futures) {
try {
System.out.println(future.get());
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
}
}).join();
System.out.println("All tasks are completed.");
}
}
不是固定写法,看面试者的具体思考就行。
考题3 : 请合理的使用Queue来实现一个高并发的生产/消费的场景,给些核心的代码片段。Queue直接使用LinkedList即可(高频考点)
基本编程能力考查
请注意一般LinkedList实现时的基本要求,采用CustomProducerConsumer 类封装了生产者消费者模型的实现细节,使用了 wait() 和 notifyAll() 方法来实现线程之间的等待和通知。生产者通过调用 produce() 方法往缓冲区中放入数据,消费者通过调用 consume() 方法从缓冲区中取出数据。
import java.util.LinkedList;
import java.util.Queue;
class CustomProducerConsumer {
private final Queue<Integer> buffer;
private final int capacity;
public CustomProducerConsumer(int capacity) {
this.capacity = capacity;
this.buffer = new LinkedList<>();
}
public void produce(int value) throws InterruptedException {
synchronized (this) {
while (buffer.size() == capacity) {
wait();
}
buffer.offer(value);
System.out.println("Produced: " + value);
notifyAll();
}
}
public int consume() throws InterruptedException {
synchronized (this) {
while (buffer.isEmpty()) {
wait();
}
int value = buffer.poll();
System.out.println("Consumed: " + value);
notifyAll();
return value;
}
}
}
class Producer implements Runnable {
private final CustomProducerConsumer pc;
public Producer(CustomProducerConsumer pc) {
this.pc = pc;
}
@Override
public void run() {
for (int i = 0; i < 10; i++) {
try {
pc.produce(i);
Thread.sleep(100); // 模拟生产时间
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
class Consumer implements Runnable {
private final CustomProducerConsumer pc;
public Consumer(CustomProducerConsumer pc) {
this.pc = pc;
}
@Override
public void run() {
for (int i = 0; i < 10; i++) {
try {
int value = pc.consume();
Thread.sleep(200); // 模拟消费时间
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public class Main {
public static void main(String[] args) {
CustomProducerConsumer pc = new CustomProducerConsumer(5); // 缓冲区容量为5
Thread producerThread = new Thread(new Producer(pc));
Thread consumerThread = new Thread(new Consumer(pc));
producerThread.start();
consumerThread.start();
}
}扩展能力深入
1.Java 提供了许多并发容器,如 BlockingQueue,它简化了生产者-消费者模式的实现,并提供了更好的性能和更少的错误机会。如果换做使用BlockingQueue的话,这段代码又该如何写呢?
直接进行简化就可以了,具体如下:
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;
class CustomProducerConsumer {
private final BlockingQueue<Integer> buffer;
public CustomProducerConsumer(int capacity) {
this.buffer = new ArrayBlockingQueue<>(capacity);
}
public void produce(int value) throws InterruptedException {
buffer.put(value);
System.out.println("Produced: " + value);
}
public int consume() throws InterruptedException {
int value = buffer.take();
System.out.println("Consumed: " + value);
return value;
}
}
class Producer implements Runnable {
private final CustomProducerConsumer pc;
public Producer(CustomProducerConsumer pc) {
this.pc = pc;
}
@Override
public void run() {
for (int i = 0; i < 10; i++) {
try {
pc.produce(i);
Thread.sleep(100); // 模拟生产时间
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
class Consumer implements Runnable {
private final CustomProducerConsumer pc;
public Consumer(CustomProducerConsumer pc) {
this.pc = pc;
}
@Override
public void run() {
for (int i = 0; i < 10; i++) {
try {
int value = pc.consume();
Thread.sleep(200); // 模拟消费时间
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public class Main {
public static void main(String[] args) {
CustomProducerConsumer pc = new CustomProducerConsumer(5); // 缓冲区容量为5
Thread producerThread = new Thread(new Producer(pc));
Thread consumerThread = new Thread(new Consumer(pc));
producerThread.start();
consumerThread.start();
}
}
2.你知道底层BlockingQueue是如何保证你的本次实现的吗?
BlockingQueue 通过内部锁(ReentrantLock)和条件队列(Condition)来管理并发访问。以下是其实现机制的一些关键点:
- 当生产者调用
put方法时,如果队列满,生产者线程会被阻塞,进入等待状态,直到有空间可用。 - 当消费者调用
take方法时,如果队列空,消费者线程会被阻塞,进入等待状态,直到有新元素可用。
3.知道高效并发容器 Disruptor吗?这部分是否可以采用其性能会更好?写下关键代码或简单说下Disruptor的原理?
Disruptor 非常适合需要极低延迟和高吞吐量的应用场景,例如金融系统、高频交易系统、日志处理系统等。然而,由于其复杂的实现和特定的设计,对于一般的并发需求,BlockingQueue 仍然是更简单且足够高效的选择。
Disruptor 的核心设计是一个环形缓冲区(RingBuffer),用于存储事件。它通过无锁(lock-free)的方式处理生产者和消费者之间的并发访问,避免了上下文切换和锁竞争的开销。核心组件:
- RingBuffer:一个预分配的数组,用于存储事件。它使用序列号来追踪事件的位置。
- Sequencer:负责管理序列号的分配和进度。生产者和消费者通过序列号来协调访问。
- EventProcessor:消费者线程,负责处理事件。
- WaitStrategy:定义消费者等待新事件的策略,常见的策略包括阻塞等待(BlockingWaitStrategy)和自旋等待(BusySpinWaitStrategy)。
使用 Disruptor 实现生产者-消费者模式基本如下:
import com.lmax.disruptor.*;
import com.lmax.disruptor.dsl.Disruptor;
import com.lmax.disruptor.dsl.ProducerType;
import java.nio.ByteBuffer;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
class LongEvent {
private long value;
public long getValue() {
return value;
}
public void setValue(long value) {
this.value = value;
}
}
class LongEventFactory implements EventFactory<LongEvent> {
@Override
public LongEvent newInstance() {
return new LongEvent();
}
}
class LongEventProducer {
private final RingBuffer<LongEvent> ringBuffer;
public LongEventProducer(RingBuffer<LongEvent> ringBuffer) {
this.ringBuffer = ringBuffer;
}
public void produce(long value) {
long sequence = ringBuffer.next(); // Grab the next sequence
try {
LongEvent event = ringBuffer.get(sequence); // Get the entry in the Disruptor
event.setValue(value); // Fill with data
} finally {
ringBuffer.publish(sequence); // Publish the sequence
}
}
}
class LongEventHandler implements EventHandler<LongEvent> {
@Override
public void onEvent(LongEvent event, long sequence, boolean endOfBatch) {
System.out.println("Consumed: " + event.getValue());
}
}
public class DisruptorExample {
public static void main(String[] args) throws InterruptedException {
ExecutorService executor = Executors.newCachedThreadPool();
LongEventFactory factory = new LongEventFactory();
int bufferSize = 1024;
Disruptor<LongEvent> disruptor = new Disruptor<>(factory, bufferSize, executor, ProducerType.SINGLE, new BlockingWaitStrategy());
disruptor.handleEventsWith(new LongEventHandler());
disruptor.start();
RingBuffer<LongEvent> ringBuffer = disruptor.getRingBuffer();
LongEventProducer producer = new LongEventProducer(ringBuffer);
for (long l = 0; l < 10; l++) {
producer.produce(l);
Thread.sleep(100); // 模拟生产时间
}
disruptor.shutdown();
executor.shutdown();
}
}
考题4: 考虑到下面一种场景:有一个用户数据接口,要求在 50ms 内返回数据。它的调用逻辑非常复杂,打交道的接口也非常多,需要从 20 多个接口汇总数据。这些接口,最小的耗时也要 20ms,哪怕全部都是最优状态,算下来也需要 20*20 = 400ms。 为了满足要求在 50ms 内返回数据,该如何解决呢?(高频考点)
基本编程能力考查
要实现从多个接口并行地获取数据,并在规定的时间内返回,可以使用 CompletableFuture 的一些高级特性,比如 anyOf 和 allOf。这些特性能帮助我们高效地处理异步操作并组合它们的结果。利用 CompletableFuture 的组合和超时机制来确保在规定的时间内返回数据:
import java.util.*;
import java.util.concurrent.*;
import java.util.stream.Collectors;
public class ParallelDataFetcher {
private static final int TIMEOUT = 50; // 50ms
public static void main(String[] args) {
List<Callable<Map<String, Object>>> tasks = createTasks();
// Measure start time
long startTime = System.currentTimeMillis();
// Fetch data in parallel
try {
Map<String, Object> result = fetchDataInParallel(tasks);
// Measure end time
long endTime = System.currentTimeMillis();
long duration = endTime - startTime;
// Output results
System.out.println("Final Result: " + result);
System.out.println("Total Execution Time: " + duration + " ms");
// Verify if the execution time is within the expected limit
if (duration <= TIMEOUT) {
System.out.println("Test passed: Execution time is within 50ms.");
} else {
System.out.println("Test failed: Execution time exceeds 50ms.");
}
} catch (InterruptedException | ExecutionException | TimeoutException e) {
e.printStackTrace();
}
}
private static List<Callable<Map<String, Object>>> createTasks() {
// Simulating creation of tasks to call 20 different interfaces
List<Callable<Map<String, Object>>> tasks = new ArrayList<>();
for (int i = 1; i <= 20; i++) {
final int index = i;
tasks.add(() -> {
// Simulate interface call with 20ms delay
Thread.sleep(20);
Map<String, Object> data = new HashMap<>();
data.put("data" + index, "value" + index);
return data;
});
}
return tasks;
}
private static Map<String, Object> fetchDataInParallel(List<Callable<Map<String, Object>>> tasks) throws InterruptedException, ExecutionException, TimeoutException {
ExecutorService executor = Executors.newFixedThreadPool(tasks.size());
List<CompletableFuture<Map<String, Object>>> futures = tasks.stream()
.map(task -> CompletableFuture.supplyAsync(() -> {
try {
return task.call();
} catch (Exception e) {
throw new RuntimeException(e);
}
}, executor))
.collect(Collectors.toList());
// Combine results of all futures with timeout
CompletableFuture<Void> allOf = CompletableFuture.allOf(futures.toArray(new CompletableFuture[0]));
CompletableFuture<Map<String, Object>> resultFuture = allOf.thenApply(v -> futures.stream()
.map(future -> {
try {
return future.get(TIMEOUT, TimeUnit.MILLISECONDS);
} catch (InterruptedException | ExecutionException | TimeoutException e) {
return Collections.<String, Object>emptyMap();
}
})
.flatMap(map -> map.entrySet().stream())
.collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue)));
// Get result with timeout
Map<String, Object> result = resultFuture.get(TIMEOUT, TimeUnit.MILLISECONDS);
executor.shutdown();
return result;
}
}
扩展能力深入
设计一个高效的缓存机制可以显著减少接口调用的频率,并加快系统的响应速度,这个是否有考虑到呢?说下一般高效缓存机制设计方案需要思考的基本内容是什么?
以我个人的答案来看,应该要有几下即方面的考虑:
考虑缓存类型选择:选择适合的缓存类型是设计缓存机制的第一步。
- 本地缓存(如 Guava Cache、Caffeine):适用于单节点应用,响应速度快,但不适合分布式环境。
- 分布式缓存(如 Redis、Memcached):适用于分布式系统,支持大规模数据缓存和高可用性。
考虑缓存策略:缓存策略决定了如何管理缓存中的数据,包括缓存的存储、过期和更新等。
- LRU(Least Recently Used):当缓存满时,移除最近最少使用的数据。
- LFU(Least Frequently Used):当缓存满时,移除使用频率最低的数据。
- TTL(Time to Live):为每个缓存项设置一个过期时间,到期后自动移除。
考虑缓存层次:可以设计多级缓存机制,以充分利用不同层次缓存的优势:
- 一级缓存:本地缓存,速度最快,适合缓存频繁访问的数据。
- 二级缓存:分布式缓存,适合共享数据和大规模缓存需求。
考虑缓存更新机制:缓存更新机制决定了如何保持缓存数据的一致性:
- 写入时更新:每次数据更新时,同步更新缓存。
- 定期刷新:定期检查和更新缓存中的数据。
- 失效更新:缓存失效后,再从源获取数据并更新缓存。
考虑缓存穿透、击穿和雪崩防护:设计时需要考虑缓存穿透、击穿和雪崩的问题:
- 缓存穿透:对于不存在的缓存数据,查询数据库时,可以使用布隆过滤器来防止缓存穿透。
- 缓存击穿:对于热点数据,可以使用互斥锁或者单次加载机制,防止大量并发请求同时查询数据库。
- 缓存雪崩:可以设置不同的过期时间,避免缓存集中失效。
考题5: 默认情况下,我们的应用系统会建议启动一个默认的线程池供异步任务使用,这个线程池一般都会自定义初始化,请你直接写一个自定义的线程池?(高频考点)
基本编程能力考查
当我们在 Spring 应用中需要自定义线程池时,可以通过配置一个 ThreadPoolTaskExecutor Bean 来实现自定义的线程池:
package org.zyf.javabasic.thread;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
/**
* @program: zyfboot-javabasic
* @description: 自定义的线程池
* @author: zhangyanfeng
* @create: 2022-02-09 22:54
**/
@Configuration
public class ZYFThreadPoolConfig {
@Bean
public ThreadPoolTaskExecutor customThreadPoolTaskExecutor() {
ThreadPoolTaskExecutor taskExecutor = new ThreadPoolTaskExecutor();
taskExecutor.setCorePoolSize(100);
taskExecutor.setMaxPoolSize(200);
taskExecutor.setQueueCapacity(100);
taskExecutor.setKeepAliveSeconds(60);
taskExecutor.setThreadNamePrefix("custom-thread-");
taskExecutor.initialize();
return taskExecutor;
}
}
我们设置了核心线程数、最大线程数、队列容量、线程存活时间、线程名前缀等参数,并调用 initialize() 方法进行初始化,最后返回该实例供其他组件使用。这种方式更符合 Spring 的管理和注入特性,使得线程池的配置更加方便、易于维护。
扩展能力深入
这部分很多考题可直接见:Java高频面试基础知识点整理
1.为什么要使用线程池?
更详细的见文章:对Java线程池ThreadPoolExecutor的理解分析
Java的线程池是运用场景最多的并发框架,几乎所有需要异步或者并发执行任务的程序都可以使用线程池。
合理使用线程池能带来的好处:
- 降低资源消耗。 通过重复利用已经创建的线程降低线程创建的和销毁造成的消耗。例如,工作线程Woker会无线循环获取阻塞队列中的任务来执行。
- 提高响应速度。 当任务到达时,任务可以不需要等到线程创建就能立即执行。
- 提高线程的可管理性。 线程是稀缺资源,Java的线程池可以对线程资源进行统一分配、调优和监控。
2.线程池的线程数量确定?状态分析?关闭方式?请你大致说说。
更详细的见文章 :对Java线程池ThreadPoolExecutor的理解分析
线程池的线程数量怎么确定
- 一般来说,如果是CPU密集型应用,则线程池大小设置为N+1。
- 一般来说,如果是IO密集型应用,则线程池大小设置为2N+1。
在IO优化中,线程等待时间所占比例越高,需要越多线程,线程CPU时间所占比例越高,需要越少线程。这样的估算公式可能更适合:最佳线程数目 = ((线程等待时间+线程CPU时间)/线程CPU时间 )* CPU数目
线程池的五种运行状态
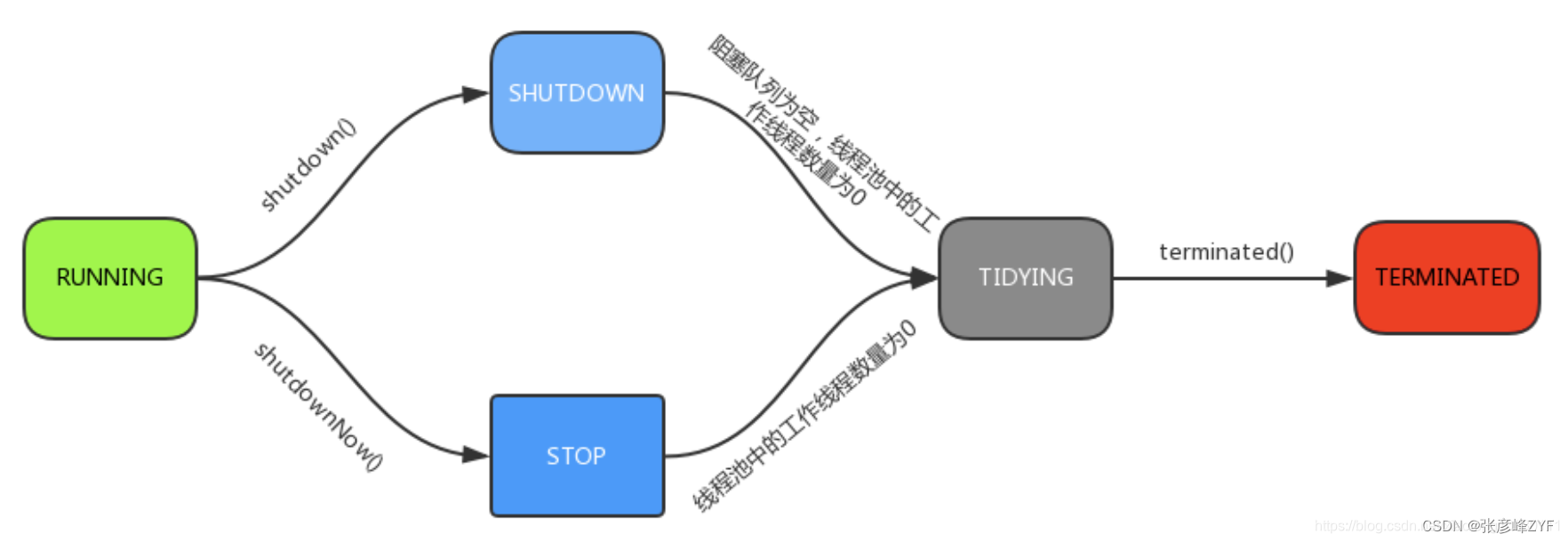
- RUNNING : 该状态的线程池既能接受新提交的任务,又能处理阻塞队列中任务。
- SHUTDOWN:该状态的线程池**不能接收新提交的任务**,**但是能处理阻塞队列中的任务**。处于 RUNNING 状态时,调用 shutdown()方法会使线程池进入到该状态。注意: finalize() 方法在执行过程中也会隐式调用shutdown()方法。
- STOP: 该状态的线程池不接受新提交的任务,也不处理在阻塞队列中的任务,还会中断正在执行的任务。在线程池处于 RUNNING 或 SHUTDOWN 状态时,调用 shutdownNow() 方法会使线程池进入到该状态;
- TIDYING: 如果所有的任务都已终止,workerCount (有效线程数)=0 。线程池进入该状态后会调用 terminated() 钩子方法进入TERMINATED 状态。
- TERMINATED: 在terminated()钩子方法执行完后进入该状态,默认terminated()钩子方法中什么也没有做。
线程池的关闭(shutdown或者shutdownNow方法)
可以通过调用线程池的shutdown或者shutdownNow方法来关闭线程池:遍历线程池中工作线程,逐个调用interrupt方法来中断线程。
shutdown方法与shutdownNow的特点:
- shutdown方法将线程池的状态设置为SHUTDOWN状态,只会中断空闲的工作线程。
- shutdownNow方法将线程池的状态设置为STOP状态,会中断所有工作线程,不管工作线程是否空闲。
调用两者中任何一种方法,都会使isShutdown方法的返回值为true;线程池中所有的任务都关闭后,isTerminated方法的返回值为true。
通常使用shutdown方法关闭线程池,如果不要求任务一定要执行完,则可以调用shutdownNow方法。
3.核心线程池ThreadPoolExecutor的参数/常见线程池的创建参数是什么样的?(高频考点)
更详细的见文章 :对Java线程池ThreadPoolExecutor的理解分析
可以通过ThreadPoolExecutor来创建一个线程池,先上代码吧:
new ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime,
TimeUnit unit, BlockingQueue<Runnable> workQueue, RejectedExecutionHandler handler)常用的5个,核心池、最大池、空闲时间、时间的单位、阻塞队列;另外两个:拒绝策略、线程工厂类
- corePoolSize:指定了线程池中的线程数量
- maximumPoolSize:指定了线程池中的最大线程数量
- keepAliveTime:线程池维护线程所允许的空闲时间
- unit: keepAliveTime 的单位。
- workQueue:任务队列,被提交但尚未被执行的任务。
- threadFactory:线程工厂,用于创建线程,一般用默认的即可。
- handler:拒绝策略。当任务太多来不及处理,如何拒绝任务。
4.ThreadPoolExecutor的工作流程(高频考点)
更详细的见文章 :对Java线程池ThreadPoolExecutor的理解分析
一个新的任务到线程池时,线程池的处理流程如下:
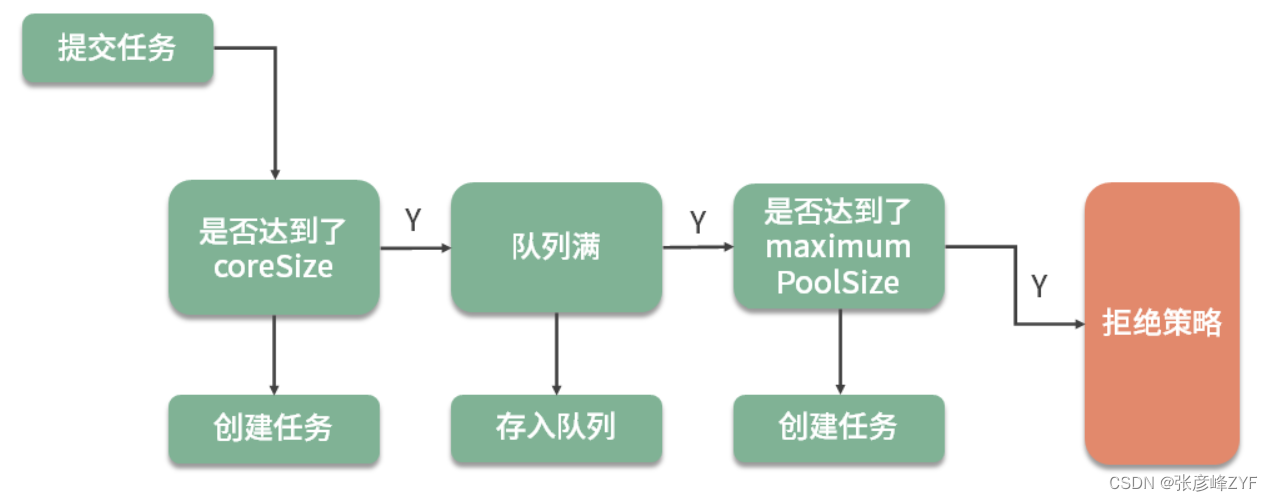
线程池判断核心线程池里的线程是否都在执行任务。 如果不是,创建一个新的工作线程来执行任务。如果核心线程池里的线程都在执行任务,则进入下个流程。
线程池判断阻塞队列是否已满。 如果阻塞队列没有满,则将新提交的任务存储在阻塞队列中。如果阻塞队列已满,则进入下个流程。
线程池判断线程池里的线程是否都处于工作状态。 如果没有,则创建一个新的工作线程来执行任务。如果已满,则交给饱和策略来处理这个任务。
5.new ThreadPoolExecutor(10,100,10,TimeUnit.MILLISECONDS,new LinkedBlockingQueue(10));一个这样创建的线程池,当已经有10个任务在运行时,第11个任务提交到此线程池执行的时候会发生什么,为什么?
在这样创建的线程池中,当已经有10个任务在运行时,第11个任务提交到此线程池执行时,会发生以下情况:
- 因为线程池的核心线程数为10,最大线程数为100,所以前10个任务会立即启动并被线程池中的10个核心线程执行。
- 第11个任务会被放入线程池的任务队列中,即LinkedBlockingQueue中。
- 由于任务队列的大小为10,而此时已经有10个任务在队列中等待执行,所以第11个任务会被成功添加到队列中。
- 如果任务队列被填满,并且当前线程池中的线程数量还未达到最大线程数(100),则会创建新的线程执行任务。
- 如果任务队列已满,并且当前线程池中的线程数量已经达到最大线程数(100),则新的任务将无法被提交到线程池中,并且会根据线程池的拒绝策略进行处理。默认情况下,线程池的默认拒绝策略是抛出 RejectedExecutionException 异常。
总之,当已经有10个任务在运行时,第11个任务提交到此线程池执行时,如果任务队列未满,则任务会被成功添加到队列中;如果任务队列已满,并且线程池中的线程数量已经达到最大线程数,则根据线程池的拒绝策略进行处理。
考题6: SimpleDateFormat 是我们经常用到的日期处理类,但在多线程运行环境下,通过 sonar 扫描提示不可用,比如下面的测试代码,你可以说下其可能运行的结果会有什么问题?(高频考点)
package org.zyf.javabasic.thread;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
/**
* @program: zyfboot-javabasic
* @description: SimpleDateFormat 的案例
* @author: zhangyanfeng
* @create: 2022-04-19 13:17
**/
public class SimpleDateFormatExample {
private static SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
public static void main(String[] args) {
Runnable task = () -> {
String dateString = sdf.format(new Date()); // 格式化日期
try {
Date date = sdf.parse(dateString); // 解析日期
System.out.println(date);
} catch (ParseException e) {
e.printStackTrace();
}
};
// 创建多个线程并启动
for (int i = 0; i < 5; i++) {
new Thread(task).start();
}
}
}
基本编程能力考查
在这个例子中,多个线程同时访问了同一个 SimpleDateFormat 实例 sdf,并在其中进行日期的格式化和解析操作。由于 SimpleDateFormat 不是线程安全的,会导致并发修改内部状态,引发解析出错、格式化错误等问题。
扩展能力深入
1.请解释为什么 SimpleDateFormat 不是线程安全的?
SimpleDateFormat 不是线程安全的主要原因是它内部维护了一个 Calendar 对象来进行日期的格式化和解析操作,而 Calendar 不是线程安全的。当多个线程同时访问同一个 SimpleDateFormat 实例时,会导致对其内部的 Calendar 对象进行并发修改,从而引发线程安全问题,例如解析出错、格式化错误等。
2.SimpleDateFormat 不是线程安全的,那如何在多线程环境中安全地使用它?
要在多线程环境中安全地使用 SimpleDateFormat,可以采用以下方法:
-
使用 ThreadLocal:为每个线程分配一个独立的 SimpleDateFormat 实例,避免多个线程共享同一个实例。可以将 SimpleDateFormat 放入 ThreadLocal 中,在每个线程中获取和使用,确保线程间互不干扰。
-
使用局部变量:在每次使用 SimpleDateFormat 的时候,创建一个新的 SimpleDateFormat 实例,并在使用结束后将其销毁。这样可以确保每个线程都拥有自己的 SimpleDateFormat 实例,避免了线程间的竞争和共享。
-
使用 JDK8 的 java.time 包:java.time 包提供了线程安全的日期时间类,如 DateTimeFormatter,可以替代 SimpleDateFormat 进行日期的格式化和解析操作。这些类设计为线程安全,不需要额外的同步措施即可在多线程环境中使用。
3.那请按你说的方法修改代码来验证一下?
可以使用 ThreadLocal 来为每个线程创建一个独立的 SimpleDateFormat 实例,并使用 java.time 包中的 DateTimeFormatter 类进行日期时间格式化。这样可以确保在多线程环境下安全地处理日期时间,避免了线程间的竞争和共享:
import java.text.SimpleDateFormat;
import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter;
/**
* @program: zyfboot-javabasic
* @description: SimpleDateFormat 的案例
* @author: zhangyanfeng
* @create: 2022-04-19 13:33
**/
public class ThreadSafeDateFormats {
// 使用 ThreadLocal 创建线程安全的 SimpleDateFormat 实例
private static final ThreadLocal<SimpleDateFormat> dateFormatThreadLocal = ThreadLocal.withInitial(() -> new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"));
// 使用 java.time 包中的线程安全类 DateTimeFormatter
private static final DateTimeFormatter dateTimeFormatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
public static void main(String[] args) {
// 使用 ThreadLocal 的 SimpleDateFormat
Runnable task1 = () -> {
SimpleDateFormat dateFormat = dateFormatThreadLocal.get();
String formattedDate = dateFormat.format(System.currentTimeMillis());
System.out.println("ThreadLocal: " + formattedDate);
};
// 使用 java.time 包的 DateTimeFormatter
Runnable task2 = () -> {
String formattedDate = dateTimeFormatter.format(LocalDateTime.now());
System.out.println("DateTimeFormatter: " + formattedDate);
};
// 创建多个线程并启动
for (int i = 0; i < 5; i++) {
new Thread(task1).start();
new Thread(task2).start();
}
}
}
4.你在平时多线程相关的编程中还遇到过哪些基本问题呢?请具体说说(面试官会经常问你在多线程使用中遇到的一些问题,以此来判断你实际的应用情况)。
一些示例:
- 线程池的不正确使用,造成了资源分配的不可控;
- I/O 密集型场景下,线程池开得过小,造成了请求的频繁失败;
- 线程池使用了 CallerRunsPolicy 饱和策略,造成了业务线程的阻塞;
- SimpleDateFormat 造成的时间错乱。
考题7: 如果要你基于 HashMap 和 双向链表实现 LRU,你能说一下整体的设计思路吗?(高频考点)
基本编程能力考查
整体的设计思路是:可以使用 HashMap 存储 key,这样可以做到 put 和 get key的时间都是 O(1),而 HashMap 的 Value 指向双向链表实现的 LRU 的 Node 节点,如图所示:
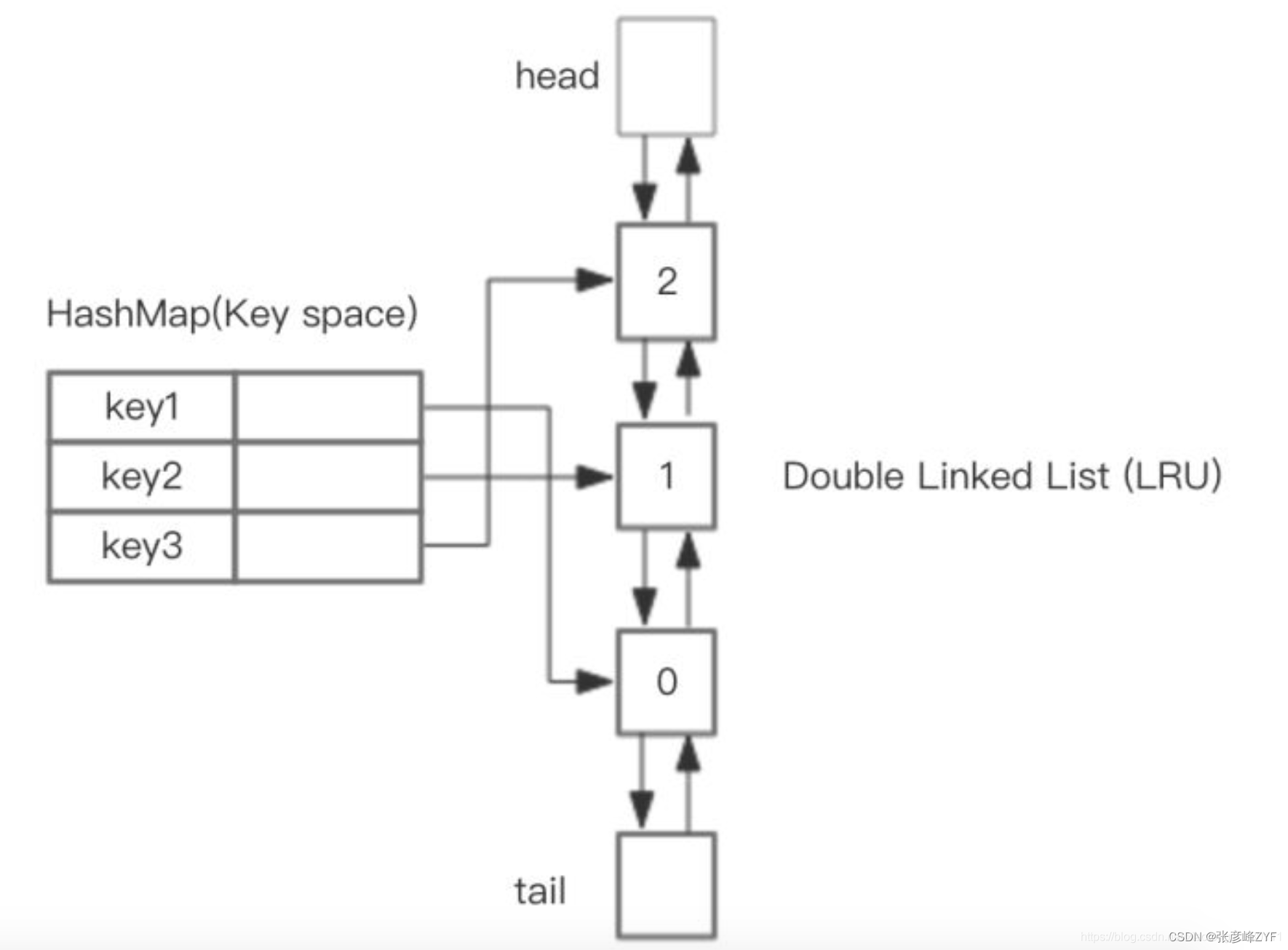
LRU 存储是基于双向链表实现的,下面的图演示了它的原理。其中 h 代表双向链表的表头,t 代表尾部。首先预先设置 LRU 的容量,如果存储满了,可以通过 O(1) 的时间淘汰掉双向链表的尾部,每次新增和访问数据,都可以通过 O(1)的效率把新的节点增加到对头,或者把已经存在的节点移动到队头。
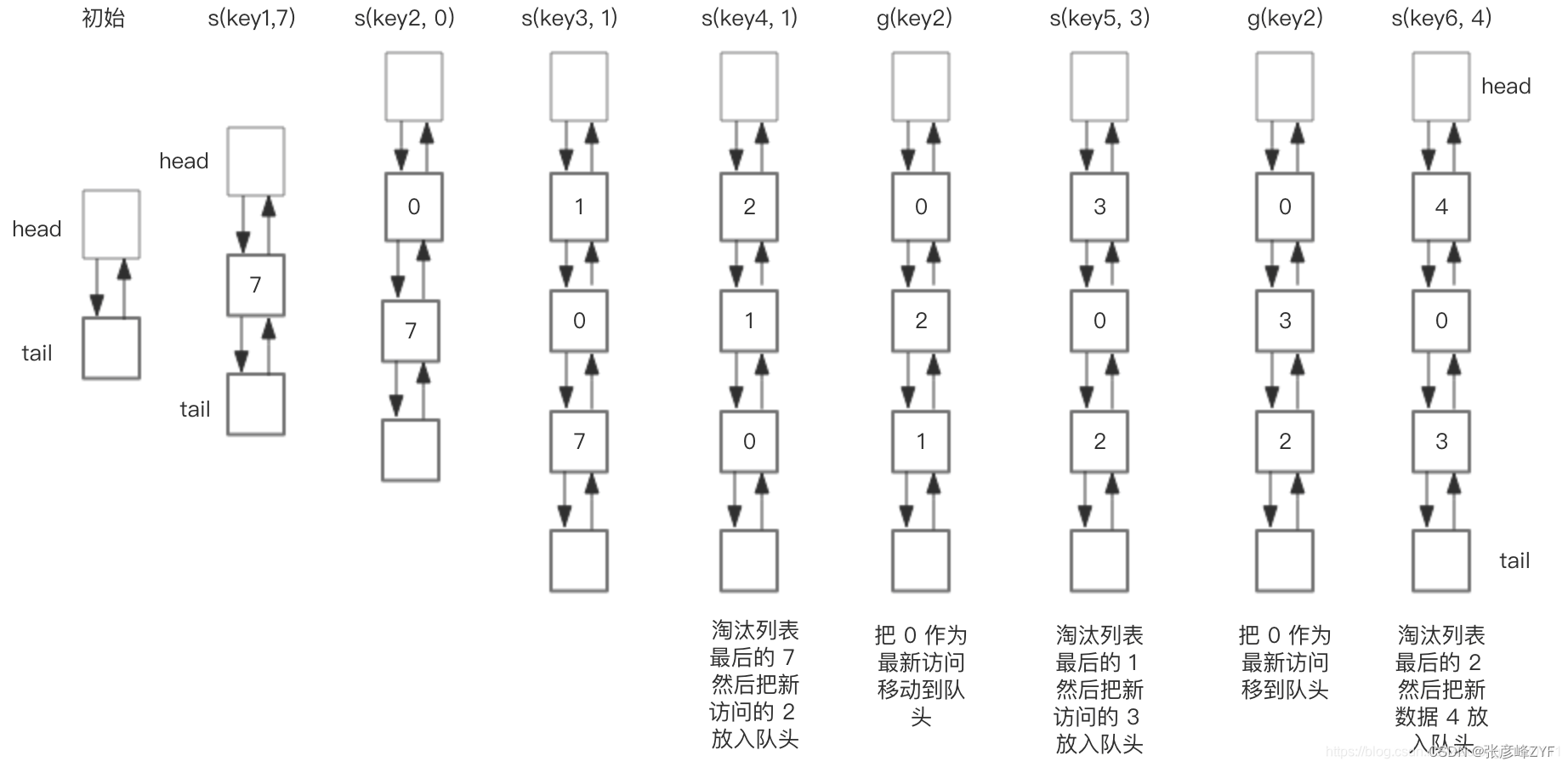
总结一下核心操作的步骤:
- put(key, value),首先在 HashMap 找到 Key 对应的节点,如果节点存在,更新节点的值,并把这个节点移动队头。如果不存在,需要构造新的节点,并且尝试把节点塞到队头,如果LRU空间不足,则通过 tail 淘汰掉队尾的节点,同时在 HashMap 中移除 Key。
- get(key),通过 HashMap 找到 LRU 链表节点,把节点插入到队头,返回缓存的值。
定义基本结构:
class DLinkedNode {
String key;
int value;
DLinkedNode pre;
DLinkedNode post;
}具体手写代码如下:
package org.zyf.javabasic.letcode.hash;
import java.util.HashMap;
import java.util.Map;
/**
* @author yanfengzhang
* @description 设计和实现一个 LRU (最近最少使用) 缓存机制。它应该支持以下操作:获取数据 get 和写入数据 put 。
* 获取数据 get(key) - 如果密钥 (key) 存在于缓存中,则获取密钥的值(总是正数),否则返回 -1。
* 写入数据 put(key, value) - 如果密钥不存在,则写入其数据值。当缓存容量达到上限时,
* 它应该在写入新数据之前删除最近最少使用的数据值,从而为新的数据值留出空间。
* <p>
* 进阶:你是否可以在 O(1) 时间复杂度内完成这两种操作?
* @date 2023/4/9 19:11
*/
public class LRUCache {
class DLinkedNode {
int key;
int value;
DLinkedNode prev;
DLinkedNode next;
}
private Map<Integer, DLinkedNode> cache = new HashMap<>();
private int size;
private int capacity;
private DLinkedNode head, tail;
public LRUCache(int capacity) {
this.size = 0;
this.capacity = capacity;
head = new DLinkedNode();
tail = new DLinkedNode();
head.next = tail;
tail.prev = head;
}
public int get(int key) {
DLinkedNode node = cache.get(key);
if (node == null) {
return -1;
}
/*将节点移动到双向链表头部*/
moveToHead(node);
return node.value;
}
public void put(int key, int value) {
DLinkedNode node = cache.get(key);
if (node == null) {
/*如果节点不存在,则创建一个新节点并加入到双向链表头部和哈希表中*/
DLinkedNode newNode = new DLinkedNode();
newNode.key = key;
newNode.value = value;
cache.put(key, newNode);
addToHead(newNode);
size++;
if (size > capacity) {
/*如果超出容量,则删除双向链表尾部节点并在哈希表中删除对应的键值对*/
DLinkedNode tail = removeTail();
cache.remove(tail.key);
size--;
}
} else {
/*如果节点存在,则更新节点的值,并将节点移动到双向链表头部*/
node.value = value;
moveToHead(node);
}
}
private void addToHead(DLinkedNode node) {
/*将节点加入到双向链表头部*/
node.prev = head;
node.next = head.next;
head.next.prev = node;
head.next = node;
}
private void removeNode(DLinkedNode node) {
/*从双向链表中删除节点*/
node.prev.next = node.next;
node.next.prev = node.prev;
}
private void moveToHead(DLinkedNode node) {
/*将节点移动到双向链表头部*/
removeNode(node);
addToHead(node);
}
private DLinkedNode removeTail() {
/*删除双向链表尾部节点,并返回被删除的节点*/
DLinkedNode tail = this.tail.prev;
removeNode(tail);
return tail;
}
/**
* 可以看到,LRU 缓存机制在存储容量达到最大值时,
* 能够正确地淘汰最近最少使用的节点,
* 并保证每个节点的访问顺序符合 LRU 缓存机制的要求。
*/
public static void main(String[] args) {
LRUCache cache = new LRUCache(2);
cache.put(1, 1);
cache.put(2, 2);
/*output: 1*/
System.out.println(cache.get(1));
cache.put(3, 3);
/*output: -1*/
System.out.println(cache.get(2));
cache.put(4, 4);
/*output: -1*/
System.out.println(cache.get(1));
/*output: 3*/
System.out.println(cache.get(3));
/*output: 4*/
System.out.println(cache.get(4));
}
}扩展能力深入
1.当前实现的LRU缓存已经在时间复杂度上达到了O(1),但还有没有其他方式可以进一步提升性能?
当前的实现已经达到了O(1)的时间复杂度,但在高并发环境下,仍然可以进一步优化性能。比如:
基于哈希表和跳表的并发版本实现:
- 使用哈希表和跳表相结合的方式,其中哈希表负责快速查找键值对,而跳表则负责维护键值对的有序性。
- 跳表的特点是具有较好的并发性能,因为它支持基于CAS(Compare and Swap)的原子操作。
使用读写锁优化:使用读写锁,将对缓存的读操作和写操作分别进行加锁。
- 读操作的并发性能可以得到保证,因为多个线程可以同时对缓存进行读取操作而不会产生竞争。
- 写操作的并发性能也可以得到一定程度的提升,因为多个线程可以同时进行读操作,而写操作会独占锁,不会和读操作产生竞争。
这样可以进一步提升LRU缓存在高并发环境下的性能表现,使其更加适用于实际的生产环境。
2.LRU是一种缓存替换策略,但还有其他的策略如LFU(最少频繁使用)或者FIFO(先进先出),你对这些策略有了解吗?
LFU(Least Frequently Used):
- LFU算法根据数据被访问的频率,淘汰访问频率最低的数据。这意味着即使某个数据最近被访问过,但如果其访问频率很低,也有可能被淘汰。
- LFU适用于需要保留访问频率高的数据的场景,例如缓存系统中的热门数据,因为这些数据虽然可能在短时间内只被访问过一次,但由于其访问频率高,应该被保留在缓存中。
FIFO(First In, First Out):
- FIFO算法按照数据最早进入缓存的顺序,淘汰最早进入缓存的数据。这意味着最先进入缓存的数据会被最先淘汰。
- FIFO适用于需要保持数据的顺序性的场景,例如缓存系统中需要按照数据进入的顺序进行处理的场景。
在选择缓存替换策略时,需要根据具体的应用场景和业务需求来进行选择:
- 如果需要保留最近访问的数据,可以选择LRU。
- 如果需要保留访问频率高的数据,可以选择LFU。
- 如果需要保持数据的顺序性,可以选择FIFO。
在实际应用中,有时也会根据具体情况采用混合策略,或者根据数据的特性动态选择最合适的替换策略。
3.现在重新思考:设计一个支持过期时间的LRU缓存系统(并给出代码实现)。
该系统应该支持以下操作:
- 获取数据(get):如果密钥存在于缓存中且未过期,则获取密钥的值,否则返回 -1。
- 写入数据(put):如果密钥不存在,则写入其数据值。当缓存容量达到上限时,应淘汰最近最少使用的数据,且可以设置每个数据项的过期时间。
请说下思路并给出代码。
实现支持过期时间的LRU缓存系统可以基于已有的LRU缓存实现进行扩展。
数据结构设计:首先,可以沿用LRU缓存系统的数据结构设计,包括双向链表和哈希表。在双向链表中的节点(Node)结构中,需要添加一个字段来存储每个数据项的过期时间戳。
数据插入(put)操作:在执行put操作时,除了判断缓存容量是否已满以及数据是否已存在之外,还需要为新插入的数据项设置过期时间。可以在put操作时为每个数据项设置一个过期时间戳,例如当前时间加上一定的过期时间间隔。
数据获取(get)操作:在执行get操作时,需要检查被访问的数据项是否已过期。如果数据项的过期时间早于当前时间,则表示该数据已过期,需要将其从缓存中移除并返回 -1。如果数据项的过期时间晚于等于当前时间,则表示数据未过期,可以返回其值,并将其移动到双向链表的头部表示最近使用过。
过期数据的清理:可以定期或在每次访问数据时检查缓存中的数据项是否已过期,如果已过期则进行清理。清理过期数据的方式可以是在get操作时进行,或者定期启动一个后台线程进行扫描和清理。
更新数据过期时间:在每次对数据进行访问时,可以根据需要更新数据项的过期时间。例如,在每次get操作时,如果数据项未过期,则可以更新其过期时间为当前时间加上一定的过期时间间隔,以延长其在缓存中的存储时间。
基于Java的支持过期时间的LRU缓存系统的实现思路代码:
import java.util.HashMap;
import java.util.Map;
class LRUCache {
class Node {
int key;
int value;
long expireTime;
Node prev;
Node next;
}
private Map<Integer, Node> cache;
private int capacity;
private Node head;
private Node tail;
public LRUCache(int capacity) {
this.cache = new HashMap<>();
this.capacity = capacity;
head = new Node();
tail = new Node();
head.next = tail;
tail.prev = head;
}
public int get(int key) {
Node node = cache.get(key);
if (node == null || node.expireTime < System.currentTimeMillis()) {
return -1; // 数据不存在或已过期
}
moveToHead(node);
return node.value;
}
public void put(int key, int value, long expireTime) {
Node node = cache.get(key);
if (node == null) {
node = new Node();
node.key = key;
node.value = value;
node.expireTime = System.currentTimeMillis() + expireTime;
cache.put(key, node);
addToHead(node);
if (cache.size() > capacity) {
Node removed = removeTail();
cache.remove(removed.key);
}
} else {
node.value = value;
node.expireTime = System.currentTimeMillis() + expireTime;
moveToHead(node);
}
}
private void addToHead(Node node) {
node.prev = head;
node.next = head.next;
head.next.prev = node;
head.next = node;
}
private void removeNode(Node node) {
node.prev.next = node.next;
node.next.prev = node.prev;
}
private void moveToHead(Node node) {
removeNode(node);
addToHead(node);
}
private Node removeTail() {
Node removed = tail.prev;
removeNode(removed);
return removed;
}
}
考题8: 一个网站有 20 亿 url 存在一个黑名单中,这个黑名单要怎么存?若此时随便输入一个 url,你如何快速判断该 url 是否在这个黑名单中?并且需在给定内存空间(比如:500M)内快速判断出。
基本编程能力考查
要在有限的内存空间内存储和快速判断一个URL是否在一个20亿条URL的黑名单中,可以使用布隆过滤器(Bloom Filter)。布隆过滤器是一种空间效率很高的概率型数据结构,可以用于判断一个元素是否属于一个集合。它能够以较小的内存开销和快速查询来满足这种需求。
对应代码实现如下:
package org.zyf.javabasic.test;
import java.nio.charset.StandardCharsets;
import java.util.BitSet;
import java.util.Random;
/**
* @program: zyfboot-javabasic
* @description: 布隆过滤器
* @author: zhangyanfeng
* @create: 2021-08-10 22:44
**/
public class BloomFilter {
private BitSet bitSet;
private int bitSize;
private int[] hashSeeds;
private int hashFunctionCount;
public BloomFilter(int expectedInsertions, double falsePositiveProbability) {
// 计算位数组大小和哈希函数数量
this.bitSize = (int) (-expectedInsertions * Math.log(falsePositiveProbability) / (Math.log(2) * Math.log(2)));
this.hashFunctionCount = (int) (bitSize / expectedInsertions * Math.log(2));
this.bitSet = new BitSet(bitSize);
this.hashSeeds = new int[hashFunctionCount];
Random random = new Random();
for (int i = 0; i < hashFunctionCount; i++) {
hashSeeds[i] = random.nextInt();
}
}
public void add(String url) {
byte[] bytes = url.getBytes(StandardCharsets.UTF_8);
for (int seed : hashSeeds) {
int hash = hash(bytes, seed);
bitSet.set(Math.abs(hash % bitSize));
}
}
public boolean contains(String url) {
byte[] bytes = url.getBytes(StandardCharsets.UTF_8);
for (int seed : hashSeeds) {
int hash = hash(bytes, seed);
if (!bitSet.get(Math.abs(hash % bitSize))) {
return false;
}
}
return true;
}
private int hash(byte[] bytes, int seed) {
int result = 0;
for (byte b : bytes) {
result = result * seed + b;
}
return result;
}
public static void main(String[] args) {
int expectedInsertions = 2000000000; // 20亿
double falsePositiveProbability = 0.01; // 1% 的误判率
BloomFilter bloomFilter = new BloomFilter(expectedInsertions, falsePositiveProbability);
// 插入URL
bloomFilter.add("http://example.com");
// 查询URL
System.out.println(bloomFilter.contains("http://example.com")); // true
System.out.println(bloomFilter.contains("http://example.org")); // false
}
}
扩展能力深入
1.布隆过滤器有误判率吗?为啥会误判,举例说明?
布隆过滤器是一种用于快速判断一个元素是否存在于集合中的数据结构,它使用一系列哈希函数和位数组来实现。布隆过滤器在判断元素存在性时非常高效,但也有可能发生误判,即判断一个元素存在于集合中,但实际上并不存在。
误判主要由以下几个因素引起:
- 哈希碰撞: 布隆过滤器使用多个哈希函数来将元素映射到位数组中的位置。如果两个不同的元素映射到了相同的位置,就会产生哈希碰撞。这样,即使一个元素在位数组中被标记为存在,也可能是因为另一个元素的哈希函数产生了相同的位置。
- 位数组大小: 布隆过滤器的位数组大小决定了其容纳元素的能力。如果位数组大小有限,当插入大量元素时,不可避免地会出现冲突,导致误判。
举个例子来说明:
假设我们有一个位数组大小为 8,并使用两个哈希函数来映射元素到位数组上的位置。现在,我们向布隆过滤器插入两个元素:A 和 B。元素 A 经过两个哈希函数后映射到位数组的第 2 和第 5 个位置,元素 B 映射到位数组的第 3 和第 6 个位置。
如果现在我们想判断元素 C 是否存在于集合中,它经过哈希函数后映射到位数组的第 2 和第 6 个位置,与元素 A 和元素 B 的映射位置重合。这将导致布隆过滤器错误地判断元素 C 存在于集合中,尽管实际上并没有插入过元素 C。
因此,布隆过滤器在设计和使用时需要权衡容错性和误判率。可以通过增加位数组大小、使用更多的哈希函数等方式来降低误判率,但同时也会增加内存占用和计算成本。
2.如何处理布隆过滤器的误判率?在实际应用中有哪些补救措施?
误判率无法完全消除,但可以通过一些方式减轻其影响,比如:
- 二次检查: 在关键业务场景中,使用布隆过滤器作为第一层筛选,再通过其他准确但较慢的方法进行二次验证。
- 动态调整: 根据实际使用情况动态调整布隆过滤器的参数(如位数组大小和哈希函数数量)或重建过滤器。
- 分层过滤器: 使用多个不同参数的布隆过滤器分层过滤,降低每层的误判率。
3.如何在插入超过预期数量的元素时处理布隆过滤器的误判率增加问题?
可以使用可扩展布隆过滤器(Scalable Bloom Filter),它通过创建多个布隆过滤器并在每个过滤器达到容量限制时添加新的过滤器来动态扩展。每个新的过滤器都有不同的误判率,这样可以在保证误判率上限的同时扩展容量。
4.布隆过滤器可以合并吗?如何实现?误判率会增加吗?
可以合并两个相同大小、使用相同哈希函数的布隆过滤器。合并操作是对两个布隆过滤器的位数组进行按位或操作。例如:
BitSet mergedBitSet = (BitSet) bitSet1.clone();
mergedBitSet.or(bitSet2);合并后的布隆过滤器包含两个原始过滤器中的所有元素,但误判率也会增加。
5.Google的Guava库提供了高效的布隆过滤器实现,如果使用其现成的内容,上面代码该如何实现?
优点: 易用且经过优化,直接上代码:
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
/**
* @program: zyfboot-javabasic
* @description: 布隆过滤器
* @author: zhangyanfeng
* @create: 2021-08-10 22:49
**/
public class BloomFilterExample {
public static void main(String[] args) {
BloomFilter<CharSequence> bloomFilter = BloomFilter.create(
Funnels.stringFunnel(Charsets.UTF_8), 2000000000, 0.01);
// 添加URL到布隆过滤器
bloomFilter.put("http://example.com");
// 查询URL是否在布隆过滤器中
System.out.println(bloomFilter.mightContain("http://example.com")); // true
System.out.println(bloomFilter.mightContain("http://example.org")); // false
}
}
6.Guava的BloomFilter是如何控制误判率和内存使用的?
通过两个参数来控制:预计插入的元素数量和期望的误判率。布隆过滤器会根据这两个参数来计算所需的位数组大小和哈希函数数量。位数组越大,误判率越低;哈希函数越多,误判率越低,但插入和查询时间也会增加。
7.Guava的BloomFilter是否支持扩展,即动态增加元素后仍保持较低的误判率?
Guava的BloomFilter不支持动态扩展。一旦初始化了位数组大小和哈希函数数量,它们是固定的。如果实际插入的元素数量超过预期,会导致误判率上升。解决方案之一是使用可扩展布隆过滤器(Scalable Bloom Filter),但这需要自己实现,Guava没有直接提供这种功能。
8.Guava的BloomFilter是线程安全的吗?如果不是,如何确保线程安全?给出实现?
Guava的BloomFilter本身不是线程安全的。为了在多线程环境中安全地使用Guava的BloomFilter,我们可以采用多种策略来确保线程安全:
- 显式锁: 简单直接,但可能会导致较高的锁竞争。
- 并发集合: 通过分片减少竞争,但增加了复杂度和内存开销。
- 读写锁: 提高读操作的并发性,但复杂度相对较高。
现在可以选择任意方式进行代码实现。
方法1:显式锁---使用显式锁可以确保在对BloomFilter的每次访问(读或写)时,都只有一个线程能够执行操作。
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
import java.nio.charset.Charset;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
public class ThreadSafeBloomFilter<T> {
private final BloomFilter<T> bloomFilter;
private final Lock lock;
public ThreadSafeBloomFilter(int expectedInsertions, double falsePositiveProbability) {
this.bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charset.forName("UTF-8")), expectedInsertions, falsePositiveProbability);
this.lock = new ReentrantLock();
}
public void put(T element) {
lock.lock();
try {
bloomFilter.put(element);
} finally {
lock.unlock();
}
}
public boolean mightContain(T element) {
lock.lock();
try {
return bloomFilter.mightContain(element);
} finally {
lock.unlock();
}
}
}
方法2:使用并发集合---在这种方法中,我们将多个布隆过滤器分片存储在一个并发集合(如ConcurrentHashMap)中,通过将元素散列到不同的布隆过滤器分片来减少争用。
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
import java.nio.charset.Charset;
import java.util.concurrent.ConcurrentHashMap;
public class ConcurrentBloomFilter<T> {
private final ConcurrentHashMap<Integer, BloomFilter<T>> bloomFilters;
private final int numberOfFilters;
public ConcurrentBloomFilter(int numberOfFilters, int expectedInsertions, double falsePositiveProbability) {
this.bloomFilters = new ConcurrentHashMap<>();
this.numberOfFilters = numberOfFilters;
for (int i = 0; i < numberOfFilters; i++) {
bloomFilters.put(i, BloomFilter.create(Funnels.stringFunnel(Charset.forName("UTF-8")), expectedInsertions, falsePositiveProbability));
}
}
private int getFilterIndex(T element) {
return element.hashCode() % numberOfFilters;
}
public void put(T element) {
int index = getFilterIndex(element);
bloomFilters.get(index).put(element);
}
public boolean mightContain(T element) {
int index = getFilterIndex(element);
return bloomFilters.get(index).mightContain(element);
}
}
方法3:使用ReadWriteLock---使用ReadWriteLock可以在读操作不需要互斥的情况下提高并发性,只有在写操作时才进行锁定。
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
import java.nio.charset.Charset;
import java.util.concurrent.locks.ReadWriteLock;
import java.util.concurrent.locks.ReentrantReadWriteLock;
public class ReadWriteLockBloomFilter<T> {
private final BloomFilter<T> bloomFilter;
private final ReadWriteLock readWriteLock;
public ReadWriteLockBloomFilter(int expectedInsertions, double falsePositiveProbability) {
this.bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charset.forName("UTF-8")), expectedInsertions, falsePositiveProbability);
this.readWriteLock = new ReentrantReadWriteLock();
}
public void put(T element) {
readWriteLock.writeLock().lock();
try {
bloomFilter.put(element);
} finally {
readWriteLock.writeLock().unlock();
}
}
public boolean mightContain(T element) {
readWriteLock.readLock().lock();
try {
return bloomFilter.mightContain(element);
} finally {
readWriteLock.readLock().unlock();
}
}
}