为什么Spark 比 MapReduce 更快
DAG相比hadoop的mapreduce在大多数情况下可以减少磁盘I/O次数
因为mapreduce计算模型只能包含一个map和一个reduce,所以reduce完后必须进行落盘,而DAG可以连续shuffle的,也就是说一个DAG可以完成好几个mapreduce,所以DAG只需要在最后一个shuffle落盘,就比mapreduce减少了落盘次数
spark shuffle 的优化
mapreduce在shuffle时默认进行排序,spark在shuffle时则只有部分场景才需要排序(bypass技师不需要排序),排序是非常耗时的,这样就可以加快shuffle速度
spark支持将需要反复用到的数据进行缓存
所以对于下次再次使用此rdd时,不再再次计算,而是直接从缓存中获取,因此可以减少数据加载耗时,所以更适合需要迭代计算的机器学习算法
任务级别并行度上的不同
mapreduce采用多进程模型,而spark采用了多线程模型,多进程模型的好处是便于细粒度控制每个任务占用的资源,但每次任务的启动都会消耗一定的启动时间,即mapreduce的map task 和reduce task是进程级别的,都是jvm进程,每次启动都需要重新申请资源,消耗不必要的时间,而spark task是基于线程模型的,通过复用线程池中的线程来减少启动,关闭task所需要的开销(多线程模型也有缺点,由于同节点上所有任务运行在一个进行中,因此,会出现严重的资源争用,难以细粒度控制每个任务占用资源)
Spark 的 shuffle介绍
Spark 与 MapReduce 的 shuffle 的区别
整体功能
两者并没有大的差别。 都是将 mapper(Spark 里是 ShuffleMapTask)的输出进行 partition,不同的 partition 送到不同的 reducer(Spark 里 reducer 可能是下一个 stage 里的 ShuffleMapTask,也可能是 ResultTask)。Reducer 以内存作缓冲区,边 shuffle 边 aggregate 数据,等到数据 aggregate 好以后进行 reduce(Spark 里可能是后续的一系列操作)。
实现流程
两者差别不小。 Hadoop MapReduce 是 sort-based,进入 combine和 reduce的 records 必须先 sort。这样的好处在于 combine/reduce可以处理大规模的数据,因为其输入数据可以通过外排得到(mapper 对每段数据先做排序,reducer 的 shuffle 对排好序的每段数据做归并)。以前 Spark 默认选择的是 hash-based,通常使用 HashMap 来对 shuffle 来的数据进行合并,不会对数据进行提前排序。如果用户需要经过排序的数据,那么需要自己调用类似 sortByKey的操作。在Spark 1.2之后,sort-based变为默认的Shuffle实现。
计算流程
两者也有不少差别。 Hadoop MapReduce 将处理流程划分出明显的几个阶段:map, spill, merge, shuffle, sort, reduce等。每个阶段各司其职,可以按照过程式的编程思想来逐一实现每个阶段的功能。在 Spark 中,没有这样功能明确的阶段,只有不同的 stage 和一系列的 transformation,所以 spill, merge, aggregate 等操作需要蕴含在 transformation中。
Spark 3.0的新特性对比Spark2.0
动态分区裁剪
即Dynamic Partition Pruning,在3.0以前不支持动态分区,所谓的动态分区是针对分区表中多个表进行join的时候运行时(runtime)推断出来的信息,在on后面的条件语句满足一定的要求后就会进行自动动态分区裁剪优化。
3.0以前:
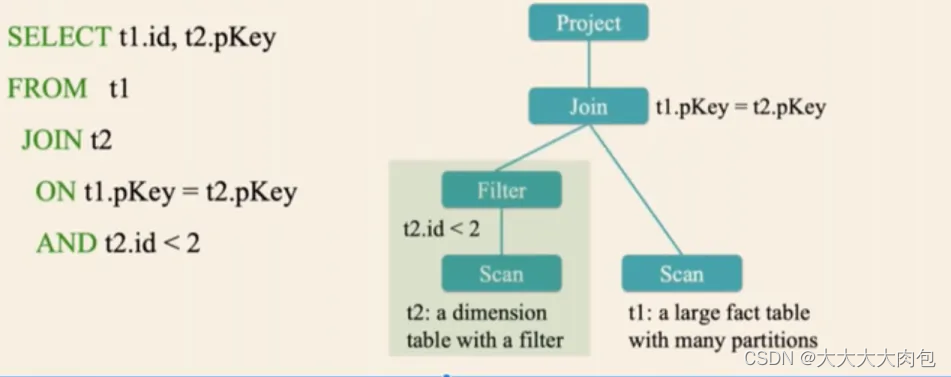
3.0以后:
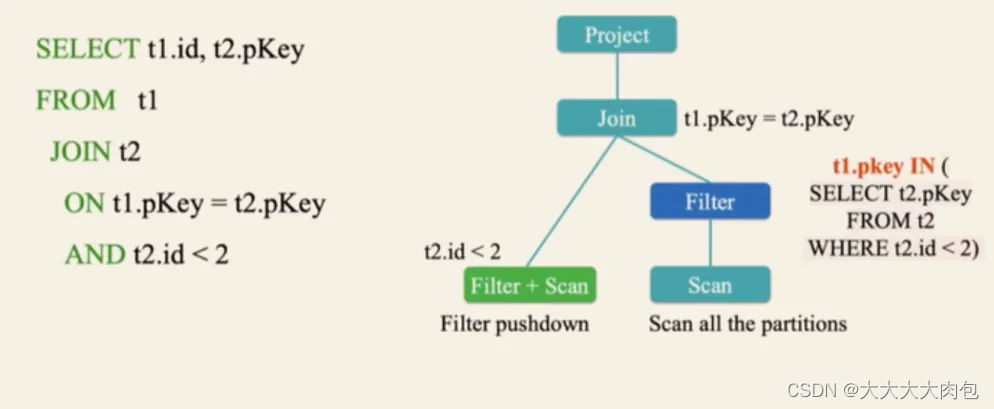
自适应查询执行
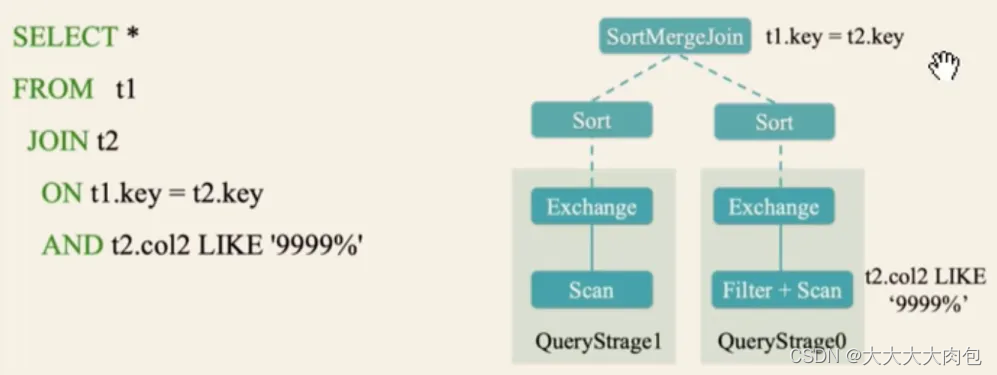
即Adaptive Query Execution,指对执行计划按照实际数据分布和组织情况,评估其执行所消耗的时间和资源,从而选择代价最小的计划执行。
- 减少 Reducer 的数量
- 将 Sort Merge Join 转换为 Broadcast Hash Join
- 处理数据倾斜
3.0以前:
3.0以后:
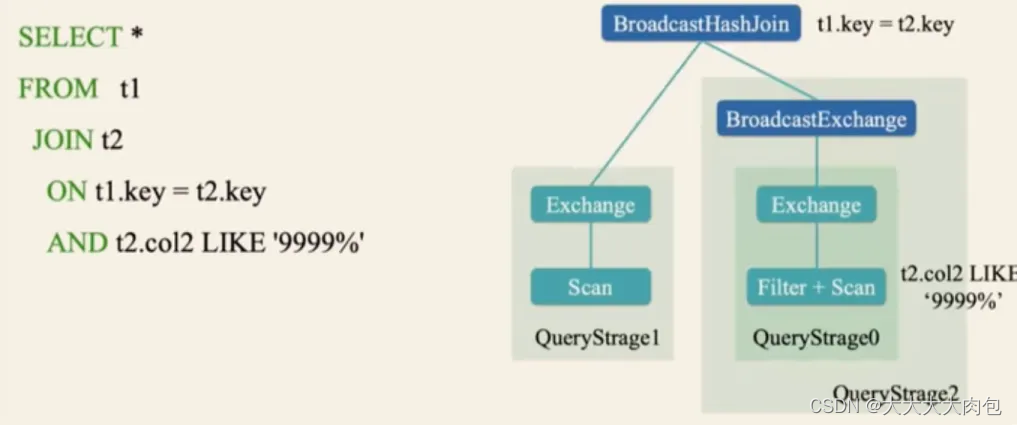
加速器感知调度
即Accelerator-aware Scheduling,在Spark3.0版本,支持在Standalone、YARN以及Kubernetes资源管理器下支持GPU,并且对现有正常的作业基本没影响。后续将支持TPU
Spark 3.0 在 Kubernetes 上有更多的功能:
- 支持使用 pod 模板来定制化 driver 和 executor 对应的 pods
- 支持动态资源申请,资源空闲的时候,减少 executor 数量,资源紧张的时候,动态的加入一些 executor
- 支持外置的 shuffle 服务,将 shuffle 服务放在独立的 pod 里,能够解耦成一个架构
谈谈你对RDD 的理解
它翻译过来就叫做弹性分布式数据集,是一种数据结构,可以理解成是一个集合。在代码中的话,RDD 是一个抽象类。还有一个非常重要的特点: RDD是不保存数据的,仅仅封装了计算逻辑,也就是你直接打印 RDD 是看不见具体值的。












![[CUDA编程] cuda graph优化心得](https://img-blog.csdnimg.cn/direct/2eb5fbeec2ff4c5ea3920a1a03e4cb0d.png)