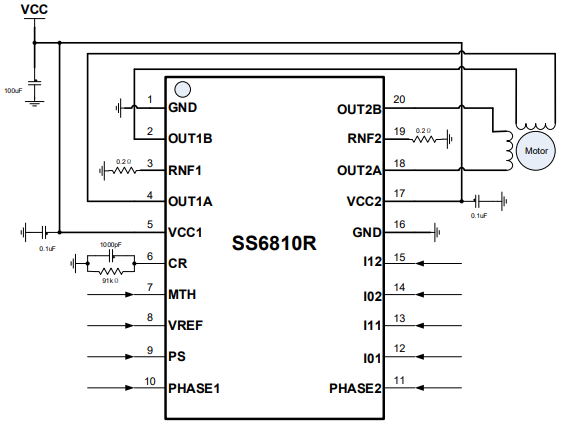
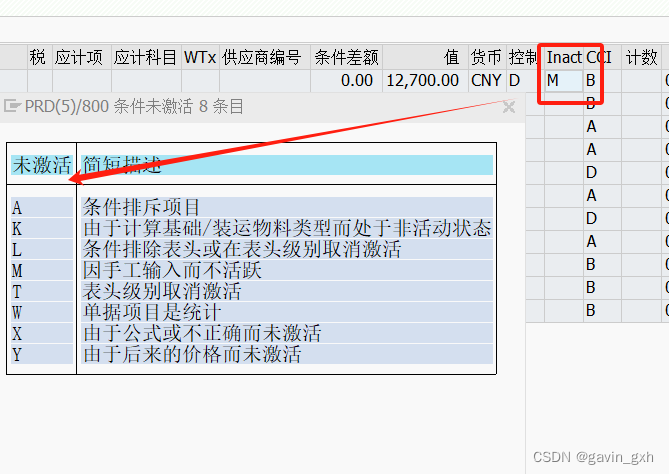
// Start capture
capture_stream.capture_start();// Y update
wtsneUpdateYKernel<real_t><<<block_count, block_size,0, capture_stream.stream()>>>(
device_ptrs.rng,get_node_table(),get_edge_table(), device_ptrs.Y,
device_ptrs.I, device_ptrs.J, device_ptrs.Eq, device_ptrs.qsum,
device_ptrs.qcount, device_ptrs.nn, device_ptrs.ne, eta0, nRepuSamp,
device_ptrs.nsq, bInit, iter_d.data(), maxIter,
device_ptrs.n_workers, n_clashes_d.data());// s (Eq) update
cub::DeviceReduce::Sum(qsum_tmp_storage_.data(), qsum_tmp_storage_bytes_,
qsum_.data(), qsum_total_device_.data(),
qsum_.size(), capture_stream.stream());
cub::DeviceReduce::Sum(
qcount_tmp_storage_.data(), qcount_tmp_storage_bytes_, qcount_.data(),
qcount_total_device_.data(), qcount_.size(), capture_stream.stream());
update_eq<real_t><<<1,1,0, capture_stream.stream()>>>(
device_ptrs.Eq, device_ptrs.nsq, qsum_total_device_.data(),
qcount_total_device_.data(), iter_d.data());
capture_stream.capture_end(graph.graph());// End capture// Main SCE loop - run captured graph maxIter times// NB: Here I have written the code so the kernel launch parameters (and all// CUDA API calls) are able to use the same parameters each loop, mainly by// using pointers to device memory, and two iter counters.// The alternative would be to use cudaGraphExecKernelNodeSetParams to// change the kernel launch parameters. See// 0c369b209ef69d91016bedd41ea8d0775879f153constauto start = std::chrono::steady_clock::now();for(iter_h =0; iter_h < maxIter;++iter_h){
graph.launch(graph_stream.stream());if(iter_h %MAX(1, maxIter /1000)==0){// Update progress meter
Eq_device_.get_value_async(&Eq_host_, graph_stream.stream());// 只是更改kernel参数指针中的值
n_clashes_d.get_value_async(&n_clashes_h, graph_stream.stream());real_t eta = eta0 *(1- static_cast<real_t>(iter_h)/(maxIter -1));// Check for interrupts while copyingcheck_interrupts();// Make sure copies have finished
graph_stream.sync();update_progress(iter_h, maxIter, eta, Eq_host_, write_per_worker,
n_clashes_h);}if(results->is_sample_frame(iter_h)){
Eq_device_.get_value_async(&Eq_host_, copy_stream.stream());update_frames(results, graph_stream, copy_stream, curr_iter, curr_Eq,
iter_h, Eq_host_);}}
flutter报错Could not run phased build action using connection to Gradle distribution ‘https://services.gradle.org/distributions/gradle-7.6.3-all.zip’.\r\norg.gradle.api.ProjectConfigurationException: A problem occurred configuring root project ‘android’…



![[Shell编程学习路线]——编制第一个shell脚本入门篇](https://img-blog.csdnimg.cn/direct/bc930fa9a10841dcad9309ad9ee9bd0b.png)