在上一篇博客中,博主已经讲解了如何利用Uncertainty-minimal Query Selection选择出好的特征,接下来便要将这些特征输入到Decoder中进行解码,需要注意的是,在RT-DETR的Encoder中,使用的是标准的自注意力计算方法,而在其Decoder中,则使用的是可变形自注意力(deformable attention),可变形自注意力能够大幅的降低计算量,同时该部分还使用到了CUDA算子,能够加快运行速度,当然,这个可变形自注意力计算并非是RT-DETR的创新点,但其作用却是极大,在DINO,DN-Deformable-DETR中都有使用。
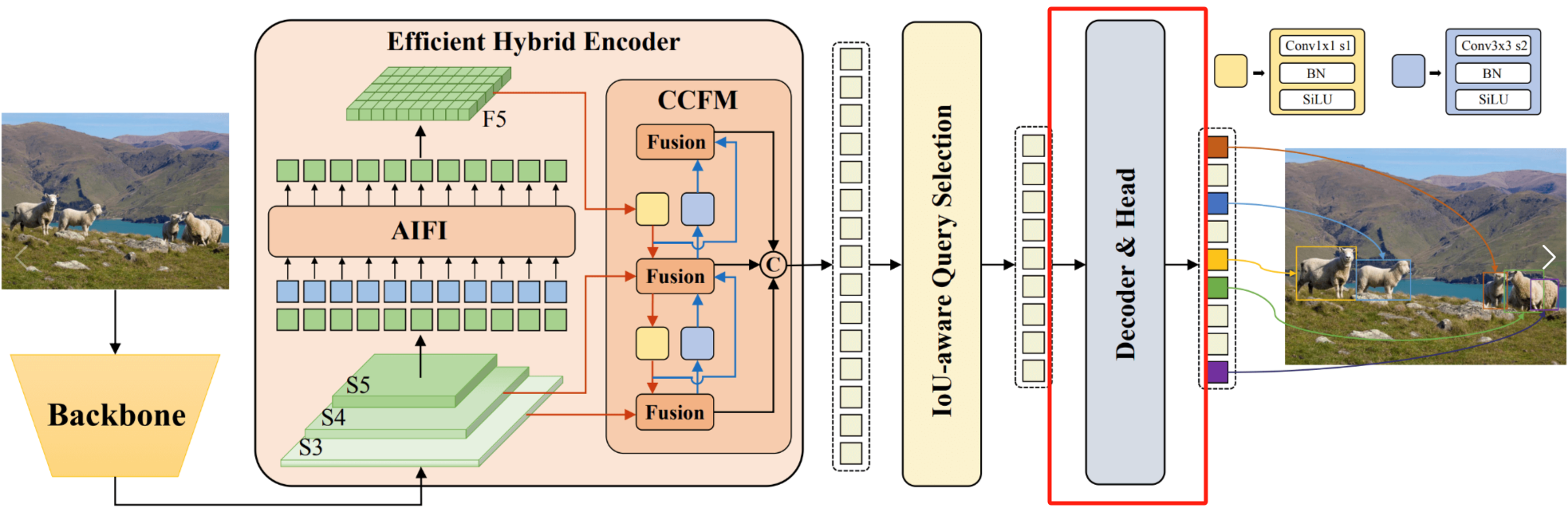
关于Deformable-DETR,博主曾经介绍过,大家如果有兴趣可以参考博主这篇博文:
Deformable DETR模型学习记录
Decoder参数
输入Decoder的参数如下:
out_bboxes, out_logits = self.decoder(
target,
init_ref_points_unact,
memory,
spatial_shapes,
level_start_index,
self.dec_bbox_head,
self.dec_score_head,
self.query_pos_head,
attn_mask=attn_mask)
target 是查询向量添加噪声以及查询向量筛选后的特征向量,即498=198+30

init_ref_point_unct 是参考点的xywh(Anchor)

memory 是Encoder输出的特征向量

spatial_shapes是Encoder输出的三个特征图的维度

记录每个特征图开始的索引(已将特征图展平)

attn_mask 特征图掩膜

query_pos_head的结构如下:
MLP(
(layers): ModuleList(
(0): Linear(in_features=4, out_features=512, bias=True)
(1): Linear(in_features=512, out_features=256, bias=True)
)
(act): ReLU(inplace=True)
)
TransformerDecoderLayer的结构如下:
ModuleList(
(0-2): 3 x TransformerDecoderLayer(
(self_attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=256, out_features=256, bias=True)
)
(dropout1): Dropout(p=0.0, inplace=False)
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(cross_attn): MSDeformableAttention(
(sampling_offsets): Linear(in_features=256, out_features=192, bias=True)
(attention_weights): Linear(in_features=256, out_features=96, bias=True)
(value_proj): Linear(in_features=256, out_features=256, bias=True)
(output_proj): Linear(in_features=256, out_features=256, bias=True)
)
(dropout2): Dropout(p=0.0, inplace=False)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(linear1): Linear(in_features=256, out_features=1024, bias=True)
(dropout3): Dropout(p=0.0, inplace=False)
(linear2): Linear(in_features=1024, out_features=256, bias=True)
(dropout4): Dropout(p=0.0, inplace=False)
(norm3): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
)
)
多层Decoder Layer(TransformerDecoder)
多层DecoderLayer的操作如下:
def forward(self,
tgt,
ref_points_unact,
memory,
memory_spatial_shapes,
memory_level_start_index,
bbox_head,
score_head,
query_pos_head,
attn_mask=None,
memory_mask=None):
output = tgt
dec_out_bboxes = []
dec_out_logits = []
ref_points_detach = F.sigmoid(ref_points_unact)
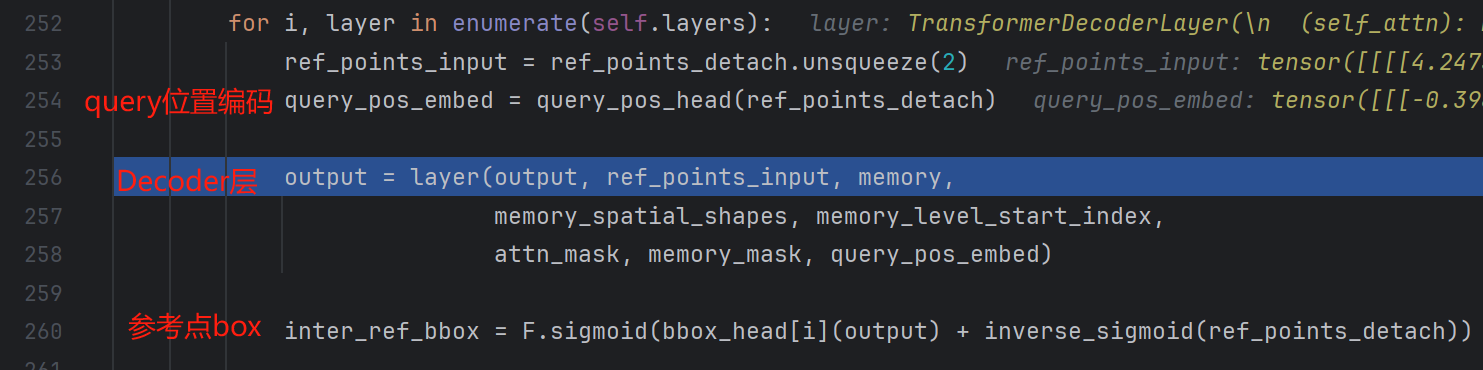
for i, layer in enumerate(self.layers):
ref_points_input = ref_points_detach.unsqueeze(2)
query_pos_embed = query_pos_head(ref_points_detach)
output = layer(output, ref_points_input, memory,
memory_spatial_shapes, memory_level_start_index,
attn_mask, memory_mask, query_pos_embed)
inter_ref_bbox = F.sigmoid(bbox_head[i](output) + inverse_sigmoid(ref_points_detach))
if self.training:
dec_out_logits.append(score_head[i](output))
if i == 0:
dec_out_bboxes.append(inter_ref_bbox)
else:
dec_out_bboxes.append(F.sigmoid(bbox_head[i](output) + inverse_sigmoid(ref_points)))
elif i == self.eval_idx:
dec_out_logits.append(score_head[i](output))
dec_out_bboxes.append(inter_ref_bbox)
break
ref_points = inter_ref_bbox
ref_points_detach = inter_ref_bbox.detach(
) if self.training else inter_ref_bbox
return torch.stack(dec_out_bboxes), torch.stack(dec_out_logits)
其中,核心代码如下:
单层DecoderLayer(TransformerDecoderLayer)
在该部分中,数据输入单层DecoderLayer后执行的操作如下:
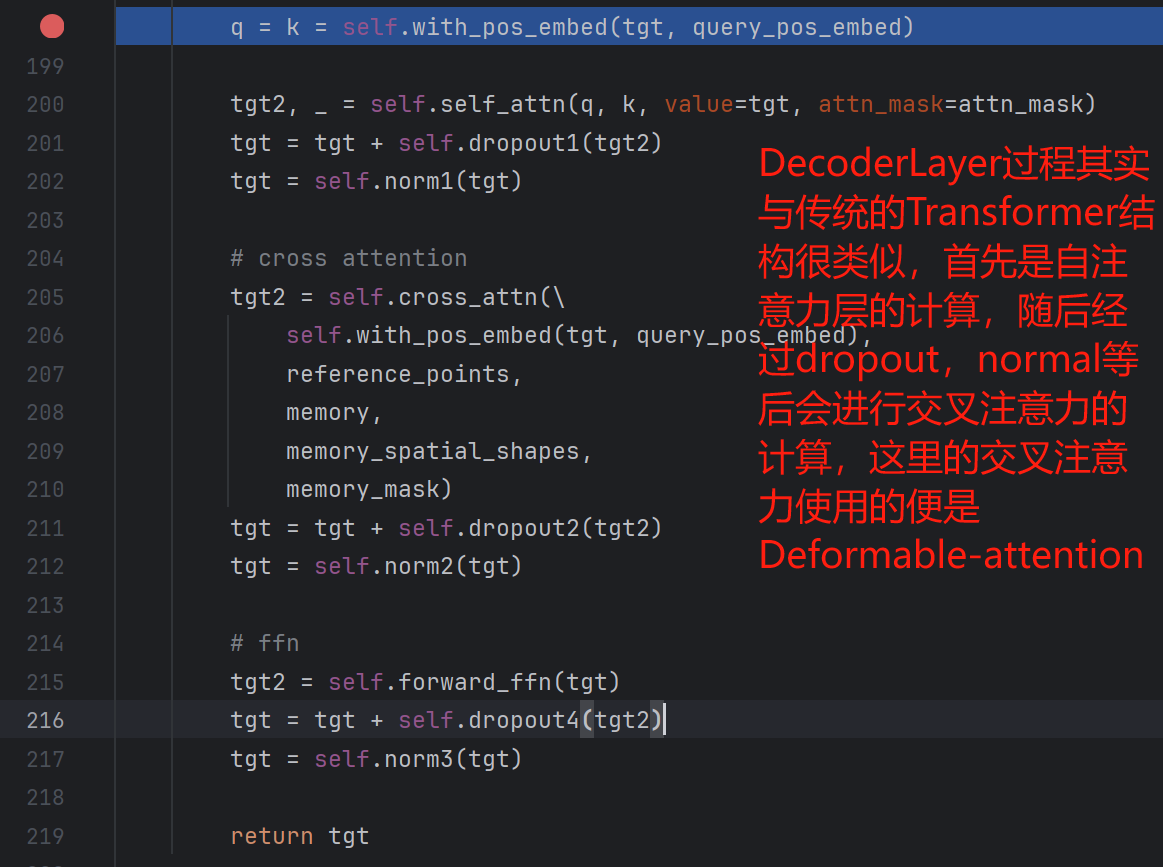
可变形注意力计算模型(MSDeformableAttention)
可变形注意力模块构造如下:
MSDeformableAttention(
(sampling_offsets): Linear(in_features=256, out_features=192, bias=True)
(attention_weights): Linear(in_features=256, out_features=96, bias=True)
(value_proj): Linear(in_features=256, out_features=256, bias=True)
(output_proj): Linear(in_features=256, out_features=256, bias=True)
)
我们对照着Deformable-DETR的结构图来观察一下输入参数,首先是Query Feature,其对应的参数是self.with_pos_embed(tgt, query_pos_embed),Reference Point 的维度为torch.Size([4, 498, 1, 4]),在计算时,我们只选用中心点坐标即可,Input Feature Maps对应的是memory,即Encoder输出的特征图。
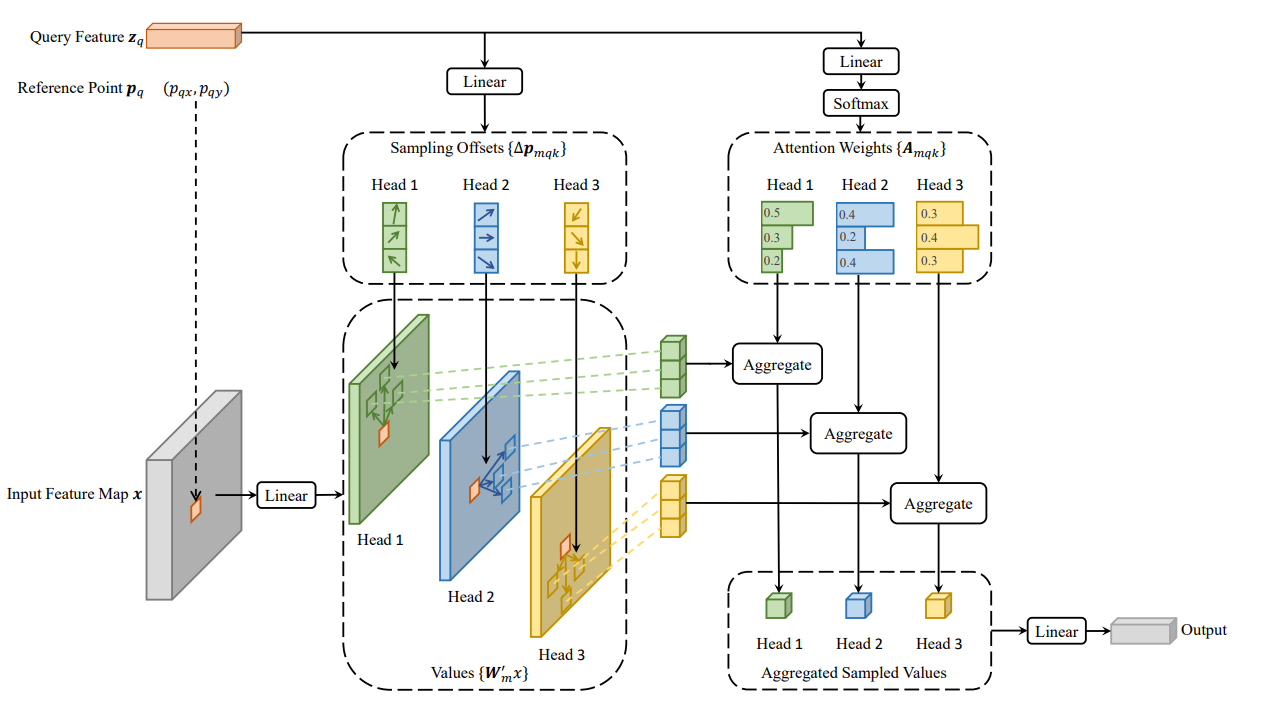
关于这个过程的代码,我就不在此一一赘述了,我们只需知道最终得到的结果即可。
最终得到可变形交叉注意力的计算结果如下:

单层DecoderLayer结果
将可变形自注意力计算结果拿到后,便是一系列normal等操作,最后返回单层DecoderLayer的结果:

这个结果会进行如下操作:

多层DecoderLayer结果
上述过程是在循环里,代码中有3层,经过多层DecodeLayer计算后,最终得到输出的分类结果与回归结果,将其返回,该部分完整代码如下:
out_bboxes, out_logits = self.decoder(
target,
init_ref_points_unact,
memory,
spatial_shapes,
level_start_index,
self.dec_bbox_head,
self.dec_score_head,
self.query_pos_head,
attn_mask=attn_mask)

最终 Decoder 模块的输出结果如下:
pred_logits:300个特征向量产生的分类结果
pred_boxes:300个特征向量产生的Anchor
aux_outputs,每个Decoder层的结果,因为Decoder中有3层,因此其采用 list 形式存储,每个list中的结果如下:
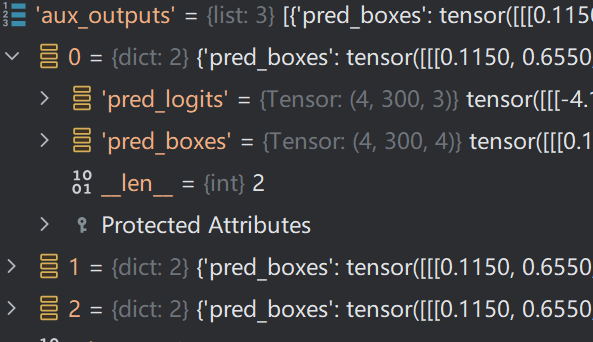
dn_aux_outputs为每层Decoder加噪查询向量输出结果
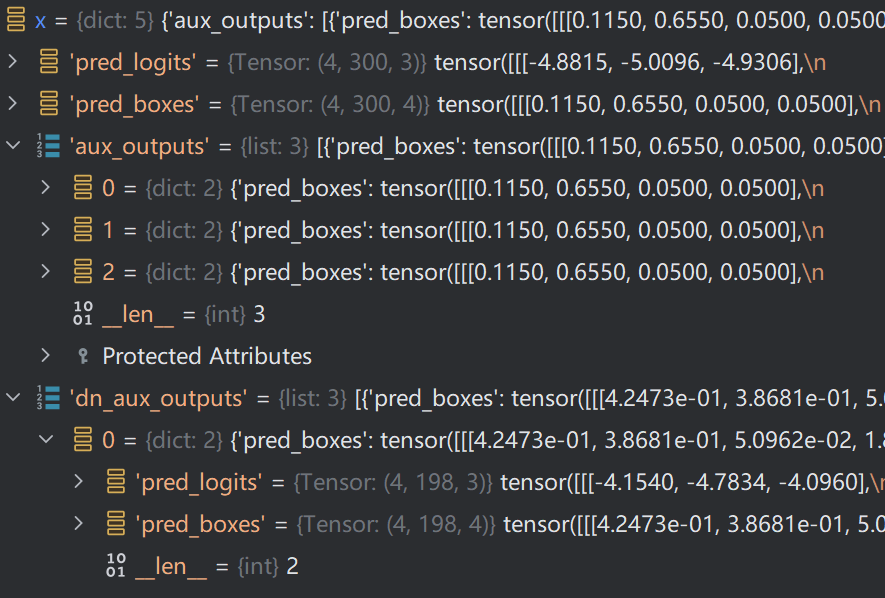
此外,还有加噪向量
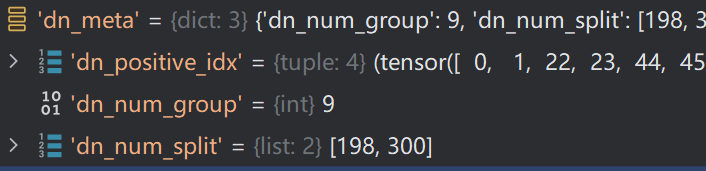
最终完成了Decoder的计算,接下来便是通过匈牙利匹配方法来匹配预测结果与目标了,同时进行损失计算。
可变形注意力分值计算方法如下:
def deformable_attention_core_func(value, value_spatial_shapes, sampling_locations, attention_weights):
"""
Args:
value (Tensor): [bs, value_length, n_head, c]
value_spatial_shapes (Tensor|List): [n_levels, 2]
value_level_start_index (Tensor|List): [n_levels]
sampling_locations (Tensor): [bs, query_length, n_head, n_levels, n_points, 2]
attention_weights (Tensor): [bs, query_length, n_head, n_levels, n_points]
Returns:
output (Tensor): [bs, Length_{query}, C]
"""
bs, _, n_head, c = value.shape
_, Len_q, _, n_levels, n_points, _ = sampling_locations.shape
split_shape = [h * w for h, w in value_spatial_shapes]
value_list = value.split(split_shape, dim=1)
sampling_grids = 2 * sampling_locations - 1
sampling_value_list = []
for level, (h, w) in enumerate(value_spatial_shapes):
# N_, H_*W_, M_, D_ -> N_, H_*W_, M_*D_ -> N_, M_*D_, H_*W_ -> N_*M_, D_, H_, W_
value_l_ = value_list[level].flatten(2).permute(
0, 2, 1).reshape(bs * n_head, c, h, w)
# N_, Lq_, M_, P_, 2 -> N_, M_, Lq_, P_, 2 -> N_*M_, Lq_, P_, 2
sampling_grid_l_ = sampling_grids[:, :, :, level].permute(
0, 2, 1, 3, 4).flatten(0, 1)
# N_*M_, D_, Lq_, P_
sampling_value_l_ = F.grid_sample(
value_l_,
sampling_grid_l_,
mode='bilinear',
padding_mode='zeros',
align_corners=False)
sampling_value_list.append(sampling_value_l_)
# (N_, Lq_, M_, L_, P_) -> (N_, M_, Lq_, L_, P_) -> (N_*M_, 1, Lq_, L_*P_)
attention_weights = attention_weights.permute(0, 2, 1, 3, 4).reshape(
bs * n_head, 1, Len_q, n_levels * n_points)
output = (torch.stack(
sampling_value_list, dim=-2).flatten(-2) *
attention_weights).sum(-1).reshape(bs, n_head * c, Len_q)
return output.permute(0, 2, 1)