1筛选限定昵称成就值活跃日期的用户

我的代码:答案不对
select uid,u.nick_name,u.achievement
from exam_record er join practice_record pr
using(uid)
join user_info u using(uid)
where u.nick_name like "牛客%号"
and u.achievement between 1200 and 2500
and date_format(er.start_time,'%Y%m')='202109'
or date_format(pr.submit_time,'%Y%m')='202109'
#以『牛客』开头『号』结尾
# where u.nick_name like "牛客%号"
#成就值在1200~2500之间
# and u.achievement between 1200 and 2500
#最近一次活跃(答题或作答试卷)在2021年9月
# and date_format(er.start_time,'%Y%m')='202109' or date_format(pr.submit_time,'%Y%m')='202109'改正代码:
select uid,u.nick_name,u.achievement
from exam_record er join practice_record pr
using(uid)
join user_info u using(uid)
where u.nick_name like '牛客%号'
group by u.uid
having u.achievement between 1200 and 2500
and date_format(max(er.start_time),'%Y%m')='202109'
or date_format(max(pr.submit_time),'%Y%m')='202109'但是最终结果还是不对:
 正确代码:下面这两个表要左连接。
正确代码:下面这两个表要左连接。
exam_record er left join practice_record pr
select uid,u.nick_name,u.achievement
from exam_record er left join practice_record pr
using(uid)
left join user_info u using(uid)
where u.nick_name like '牛客%号'
group by u.uid
having u.achievement between 1200 and 2500
and date_format(max(er.start_time),'%Y%m')='202109'
or date_format(max(pr.submit_time),'%Y%m')='202109'复盘:
(1)模糊查询标准语法
● select 字段名
● from 表名
● where 字段名 like '通配符+字符'
例:查询国家名中以C开头ia结尾的国家
where name like 'C%ia'
(2)最近的活动时间,用max:
date_format(max(pr.submit_time),'%Y%m')='202109'
(3)两个数据表的uid等数据:


left join:29条记录

如果是inner join:19条记录
(只两个表保留相同的)

复习:表连接
1)内连接:只两个表保留相同的

2)左连接:合并后左边的表所有行都保留,若左边的表有空值则删除(即删除右边没有匹配上的)

(4)这里where,group by,having的先后顺序很重要:

深入理解一下group by:
1)先看一下3个表连接后的总表:
发现相同的uid,对应的也是相同的nickname,
这种情况下如果先按照uid分组然后再where就会报错!
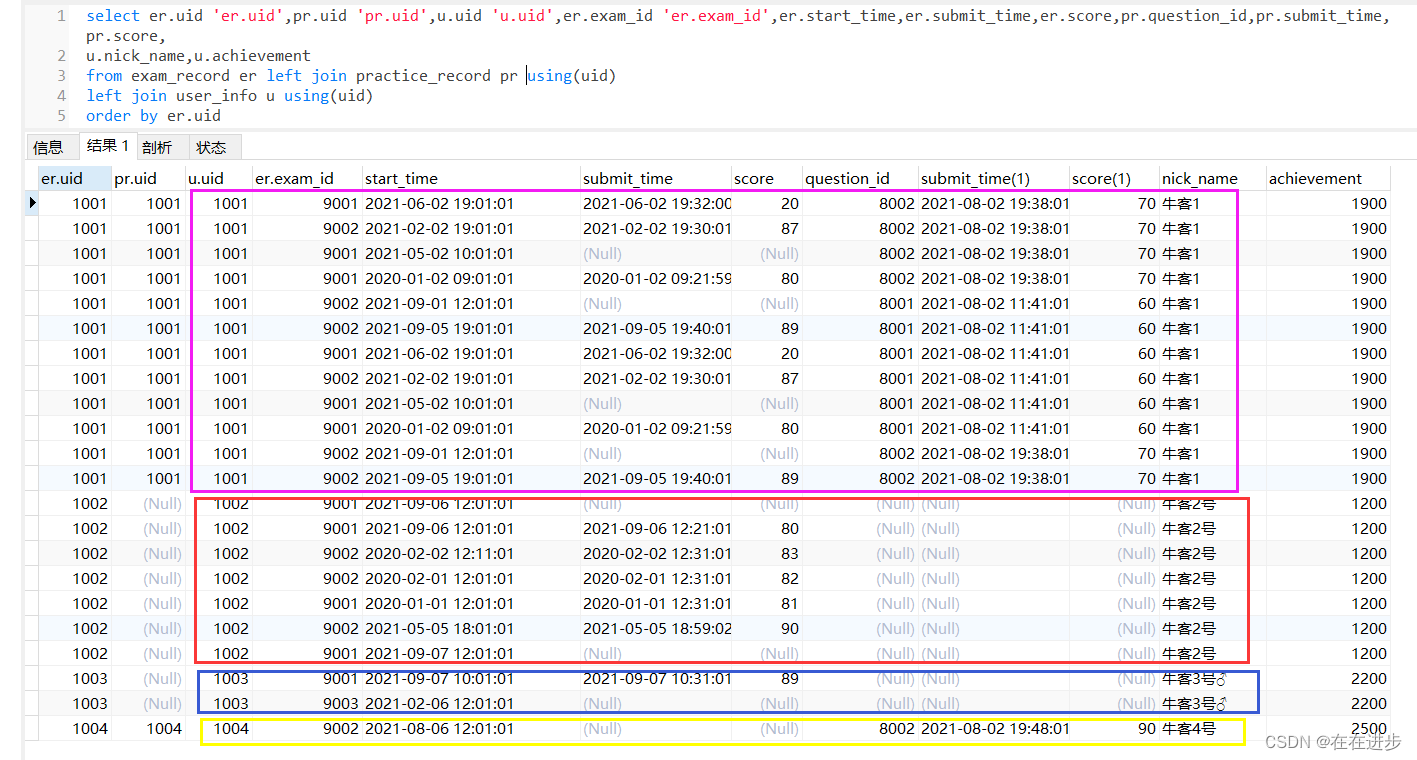
同理,u.achievement也是要在分组前进行的:
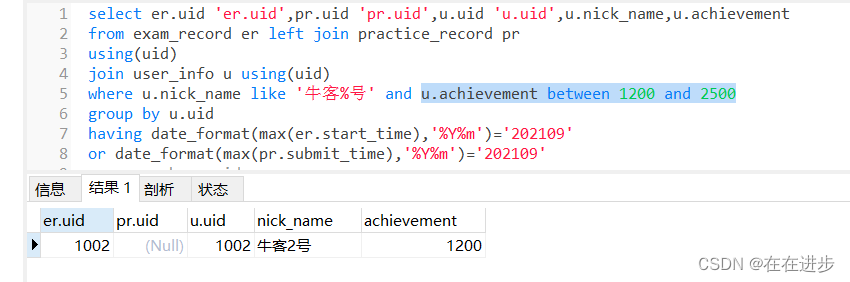
如果分组前直接筛选出 where u.nick_name like '牛客%号'

其实仔细分析题目也能看出:
请找到昵称以『牛客』开头『号』结尾、成就值在1200~2500之间,(group by 之前)
且最近一次活跃(答题或作答试卷)在2021年9月的用户信息。(按照用户进行group by )
2筛选昵称规则和试卷规则的作答记录

我的代码:不出意外就要出意外了
# # 找到昵称以"牛客"+纯数字+"号"或者纯数字组成的用户
# select uid,nick_name
# from user_info u
# where nick_name like '牛客%号' or nick_name like '[0-9]'
# # 对于字母c开头的试卷类别(如C,C++,c#等)的,已完成的
# select exam_id,*
# from examination_info ei
# where tag like 'c%' or tag like 'C%'
# and submit_time is not NULL
select uid,exam_id,
avg(score)avg_score
from exam_record
where submit_time is not NULL
and uid in (select uid,nick_name
from user_info u
where nick_name like '牛客%号' or nick_name like '[0-9]')
and exam_id in (select exam_id,*
from examination_info
where tag like 'c%' or tag like 'C%'
and submit_time is not NULL)
group by uid正确代码:
select uid,exam_id,round(sum(score)/count(exam_id),0) as avg_score
from exam_record
left join user_info using(uid)
left join examination_info using(exam_id)
where nick_name regexp '^牛客[0-9]+号$|^[0-9]+$'
and tag regexp '^[Cc]'
and submit_time is not NULL
group by uid,exam_id
order by 1,3复盘:
(1)'牛客%号',中间的%不只是数字,所以正确应该是'^牛客[0-9]+号$',
纯数字也不是'[0-9]',而是'^[0-9]+$'。
(2)正则表达式函数用 RLIKE 或者 REGEXP;
学习链接:Mysql正则表达式查询(含完整例子)_查询name字段包含字母的数据-CSDN博客

由于"牛客"+纯数字+"号"和纯数字是并集,所以要用()括起来
“^牛客[0-9]+号$ ”:意思是以牛客开头“^牛客”,匹配0-9任意字符一次“[0-9]+”,号结尾“号$”,
“^[0-9]+$”:以任意数字开头结尾的用户。
(3)like 和 rlike 的区别
1). like
1. sql语法的 模糊匹配
2. 通配符
1. % 代表零个或任意字符
2. _ 代表1个字符
2). like
1. hive 扩展功能, 通过 Java 正则表达式 来匹配条件

(4)还有一种方法是 regexp:
where nick_name regexp '^牛客[0-9]+号$|^[0-9]+$'
and tag regexp '^[Cc]'
(5)重要区别
like 整个字段匹配表达式成功才返回regexp 部分字符匹配表达式成功即可返回