目标检测算法之 YOLOv8 算法改进详细解析
1.YOLO的一些发展历史
-
YOLOv1:2015年Joseph Redmon和 Ali Farhadi等 人(华盛顿大学)
-
YOLOv2:2016年Joseph Redmon和**Ali Farhadi等人*(华盛顿大学)*
-
YOLOv3:2018年Joseph Redmon和**Ali Farhadi等人*(华盛顿大学)*
-
YOLOv4:2020年Alexey Bochkovskiy和Chien-Yao Wang等人
-
YOLOv5:2020年Ultralytics公司
-
YOLOv6:2022年美团公司
-
YOLOv7:2022年Alexey Bochkovskiy和Chien-Yao Wang等人
-
YOLOv8:2023年Ultralytics公司
上述简单罗列了 YOLOv数字系列 的发布时间和作者/单位机构,因为YOLO系列生态太猛了,比如还有知名的PP-YOLO系列、YOLOX等等工作。
YOLOv8是Ultralytics开发的 YOLO(You Only Look Once)物体检测和图像分割模型的最新版本,详细介绍可以参考Ultralytics发布的网址,可以通过ultralytics python 包获取代码,暂时还没有官方公布代码
安装ultralytics python包
pip install -i https://test.pypi.org/simple/ --extra-index-url https://pypi.org/simple/ ultralytics==0.0.59
pip install -e ultralytics
可以在 /usr/local/lib/pythonx.x/dist-packages/ultralytics (Ubuntu) 中找到代码
2. YOLOv8的相关资源
YOLOv8 Github: https://github.com/ultralytics/ultralytics
YOLOv8的权重:https://github.com/ultralytics/assets/releases
YOLOv8文档: https://v8docs.ultralytics.com/
YOLOv8 Python package源码库:https://test.pypi.org/simple/ultralytics/
3.YOLOv8改进详解
3.1 YOLOv5回顾
这里粗略回顾一下,这里直接提供YOLOv5的整理的结构图吧:
-
Backbone:CSPDarkNet结构,主要结构思想的体现在C3模块,这里也是梯度分流的主要思想所在的地方;
-
PAN-FPN:双流的FPN,必须香,也必须快,但是量化还是有些需要图优化才可以达到最优的性能,比如cat前后的scale优化等等,这里除了上采样、CBS卷积模块,最为主要的还有C3模块;
-
Head:Coupled Head+Anchor-base,毫无疑问,YOLOv3、YOLOv4、YOLOv5、YOLOv7都是Anchor-Base的;
-
Loss:分类用BEC Loss,回归用CIoU Loss。

3.2 YOLOv8核心介绍
直接上YOLOv8的结构图吧,小伙伴们可以直接和YOLOv5进行对比,看看能找到或者猜到有什么不同的地方?
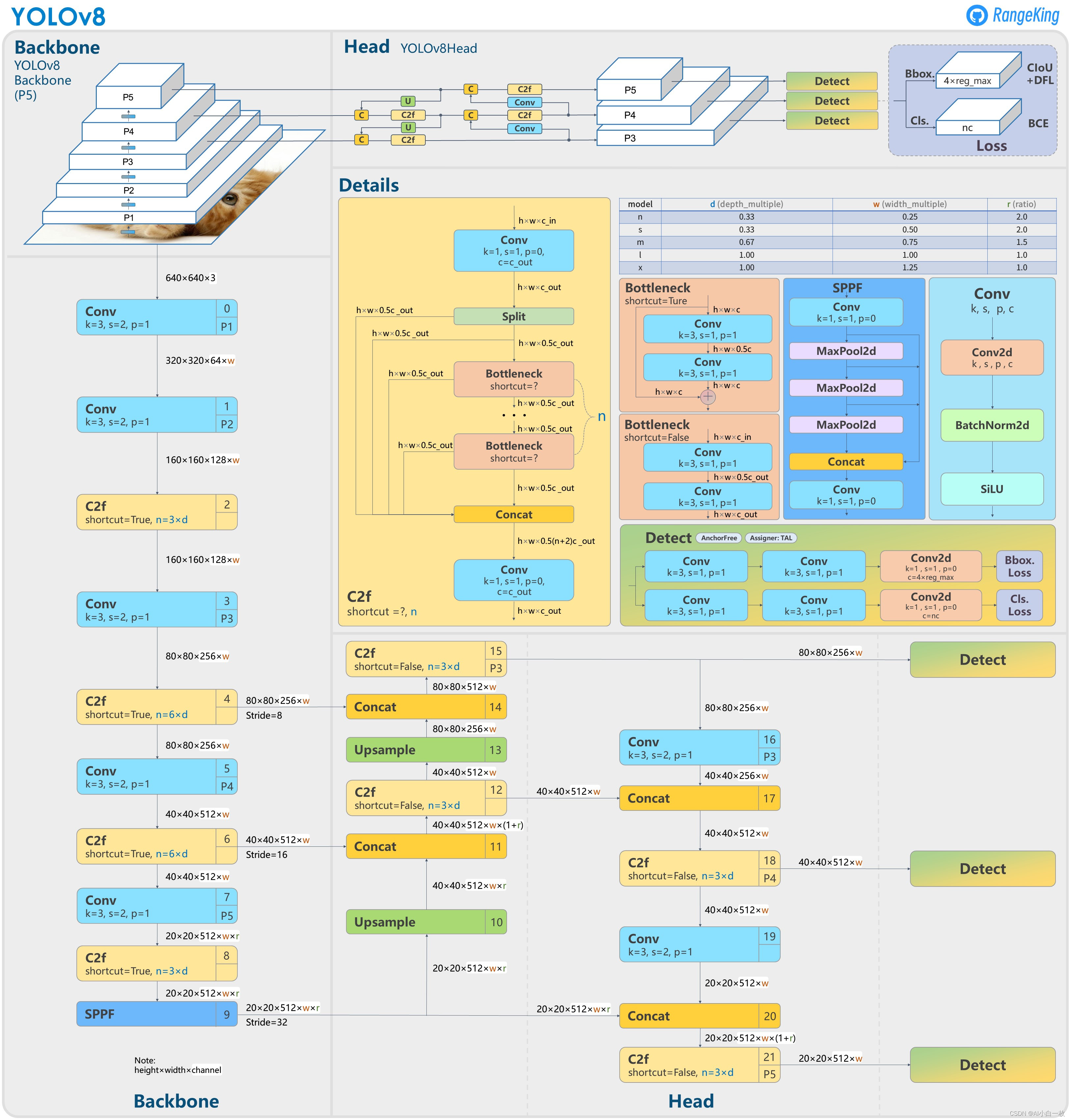
下面就直接揭晓答案吧,具体改进如下:
-
Backbone:使用的依旧是CSP的思想,不过YOLOv5中的C3模块被替换成了C2f模块,实现了进一步的轻量化,同时YOLOv8依旧使用了YOLOv5等架构中使用的SPPF模块;
-
PAN-FPN:毫无疑问YOLOv8依旧使用了PAN的思想,不过通过对比YOLOv5与YOLOv8的结构图可以看到,YOLOv8将YOLOv5中PAN-FPN上采样阶段中的卷积结构删除了,同时也将C3模块替换为了C2f模块;
-
Decoupled-Head:是不是嗅到了不一样的味道?是的,YOLOv8走向了Decoupled-Head;
-
Anchor-Free:YOLOv8抛弃了以往的Anchor-Base,使用了Anchor-Free的思想;
-
损失函数:YOLOv8使用VFL Loss作为分类损失,使用DFL Loss+CIOU Loss作为分类损失;
-
样本匹配:YOLOv8抛弃了以往的IOU匹配或者单边比例的分配方式,而是使用了Task-Aligned Assigner匹配方式。
3.3 C2f模块
我们不着急,先看一下C3模块的结构图,然后再对比与C2f的具体的区别。针对C3模块,其主要是借助CSPNet提取分流的思想,同时结合残差结构的思想,设计了所谓的C3 Block,这里的CSP主分支梯度模块为BottleNeck模块,也就是所谓的残差模块。同时堆叠的个数由参数n来进行控制,也就是说不同规模的模型,n的值是有变化的。

其实这里的梯度流主分支,可以是任何之前你学习过的模块,比如,美团提出的YOLOv6中就是用来重参模块RepVGGBlock来替换BottleNeck Block来作为主要的梯度流分支,而百度提出的PP-YOLOE则是使用了RepResNet-Block来替换BottleNeck Block来作为主要的梯度流分支。而YOLOv7则是使用了ELAN Block来替换BottleNeck Block来作为主要的梯度流分支。
C3模块的Pytorch的实现如下:
class BottleneckC2f(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5): # ch_in, ch_out, shortcut, kernels, groups, expand
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, k[0], 1)
self.cv2 = Conv(c_, c2, k[1], 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class C2f(nn.Module):
# CSP Bottleneck with 2 convolutions
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)
self.m = nn.ModuleList(BottleneckC2f(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))
def forward(self, x):
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
下面就简单说一下C2f模块,通过C3模块的代码以及结构图可以看到,C3模块和名字思路一致,在模块中使用了3个卷积模块(Conv+BN+SiLU),以及n个BottleNeck。
通过C3代码可以看出,对于cv1卷积和cv2卷积的通道数是一致的,而cv3的输入通道数是前者的2倍,因为cv3的输入是由主梯度流分支(BottleNeck分支)依旧次梯度流分支(CBS,cv2分支)cat得到的,因此是2倍的通道数,而输出则是一样的。
不妨我们再看一下YOLOv7中的模块:

YOLOv7通过并行更多的梯度流分支,放ELAN模块可以获得更丰富的梯度信息,进而或者更高的精度和更合理的延迟。
C2f模块的结构图如下:
我们可以很容易的看出,C2f模块就是参考了C3模块以及ELAN的思想进行的设计,让YOLOv8可以在保证轻量化的同时获得更加丰富的梯度流信息。

C2f模块对应的Pytorch实现如下:
class C2f(nn.Module):
# CSP Bottleneck with 2 convolutions
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)
self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))
def forward(self, x):
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
3.4 SPPF改进了什么?
SPP结构又被称为空间金字塔池化,能将任意大小的特征图转换成固定大小的特征向量。
接下来我们来详述一下SPP是怎么处理滴~
输入层:首先我们现在有一张任意大小的图片,其大小为w * h。
输出层:21个神经元 -- 即我们待会希望提取到21个特征。
分析如下图所示:分别对1 * 1分块,2 * 2分块和4 * 4子图里分别取每一个框内的max值(即取蓝框框内的最大值),这一步就是作最大池化,这样最后提取出来的特征值(即取出来的最大值)一共有1 * 1 + 2 * 2 + 4 * 4 = 21个。得出的特征再concat在一起。

而在YOLOv5中SPP的结构图如下图所示:

在YOLOv56.0版本中SPPF替换SPP,二者效果一致,但前者较后者的执行时间减少至1/2。

3.5 PAN-FPN改进了什么?
我们先看一下YOLOv5以及YOLOv6的PAN-FPN部分的结构图:
YOLOv5的Neck部分的结构图如下:
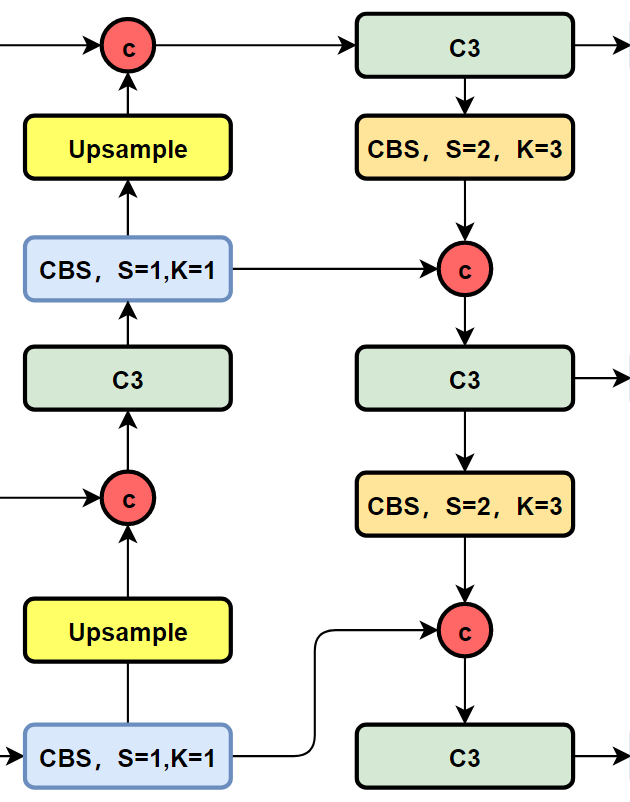
YOLOv6的Neck部分的结构图如下:

我们再看YOLOv8的结构图:
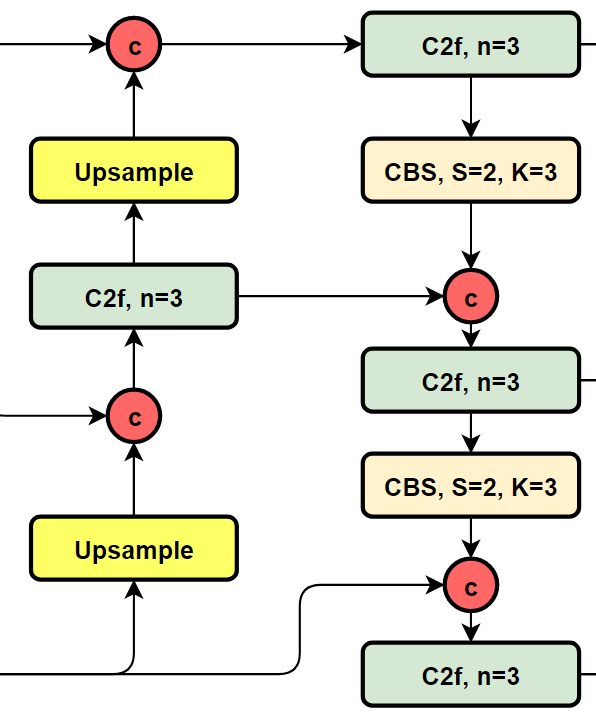
可以看到,相对于YOLOv5或者YOLOv6,YOLOv8将C3模块以及RepBlock替换为了C2f,同时细心可以发现,相对于YOLOv5和YOLOv6,YOLOv8选择将上采样之前的1×1卷积去除了,将Backbone不同阶段输出的特征直接送入了上采样操作。
3.6 Head部分都变了什么呢?
先看一下YOLOv5本身的Head(Coupled-Head):
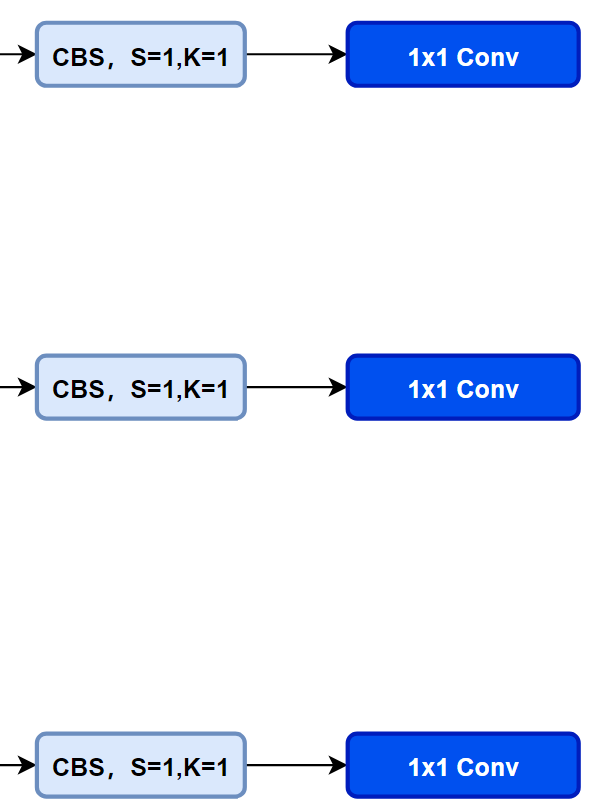
而YOLOv8则是使用了Decoupled-Head,同时由于使用了DFL 的思想,因此回归头的通道数也变成了4*reg_max的形式:
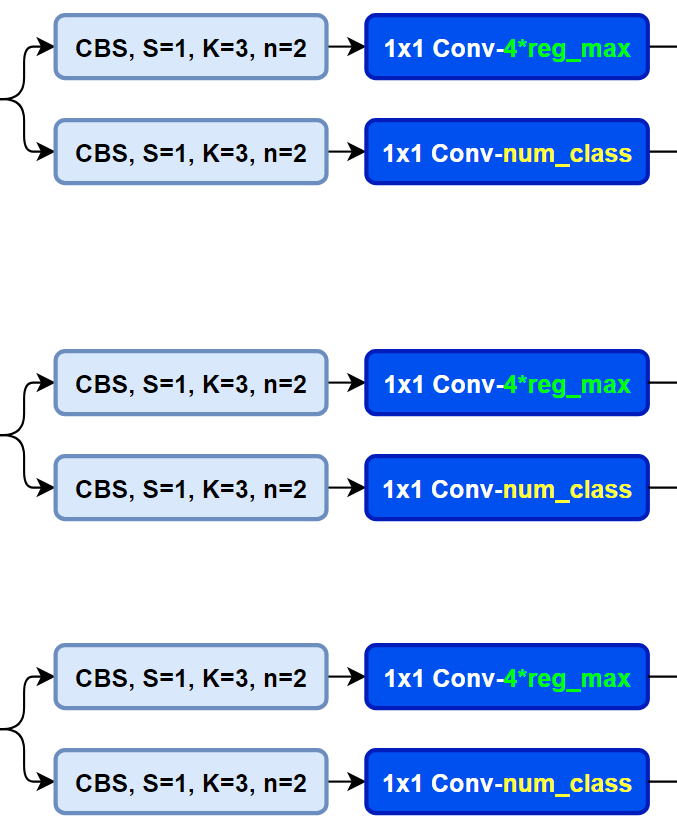
对比一下YOLOv5与YOLOv8的YAML

3.7 损失函数
对于YOLOv8,其分类损失为VFL Loss,其回归损失为CIOU Loss+DFL的形式,这里Reg_max默认为16。
VFL主要改进是提出了非对称的加权操作,FL和QFL都是对称的。而非对称加权的思想来源于论文PISA,该论文指出首先正负样本有不平衡问题,即使在正样本中也存在不等权问题,因为mAP的计算是主正样本。

q是label,正样本时候q为bbox和gt的IoU,负样本时候q=0,当为正样本时候其实没有采用FL,而是普通的BCE,只不过多了一个自适应IoU加权,用于突出主样本。而为负样本时候就是标准的FL了。可以明显发现VFL比QFL更加简单,主要特点是正负样本非对称加权、突出正样本为主样本。
针对这里的DFL(Distribution Focal Loss),其主要是将框的位置建模成一个 general distribution,让网络快速的聚焦于和目标位置距离近的位置的分布。

DFL 能够让网络更快地聚焦于目标 y 附近的值,增大它们的概率;
DFL的含义是以交叉熵的形式去优化与标签y最接近的一左一右2个位置的概率,从而让网络更快的聚焦到目标位置的邻近区域的分布;也就是说学出来的分布理论上是在真实浮点坐标的附近,并且以线性插值的模式得到距离左右整数坐标的权重。
3.8 样本的匹配
标签分配是目标检测非常重要的一环,在YOLOv5的早期版本中使用了MaxIOU作为标签分配方法。然而,在实践中发现直接使用边长比也可以达到一阿姨你的效果。而YOLOv8则是抛弃了Anchor-Base方法使用Anchor-Free方法,找到了一个替代边长比例的匹配方法,TaskAligned。
为与NMS搭配,训练样例的Anchor分配需要满足以下两个规则:
-
正常对齐的Anchor应当可以预测高分类得分,同时具有精确定位;
-
不对齐的Anchor应当具有低分类得分,并在NMS阶段被抑制。基于上述两个目标,TaskAligned设计了一个新的Anchor alignment metric 来在Anchor level 衡量Task-Alignment的水平。并且,Alignment metric 被集成在了 sample 分配和 loss function里来动态的优化每个 Anchor 的预测。
Anchor alignment metric:
分类得分和 IoU表示了这两个任务的预测效果,所以,TaskAligned使用分类得分和IoU的高阶组合来衡量Task-Alignment的程度。使用下列的方式来对每个实例计算Anchor-level 的对齐程度:
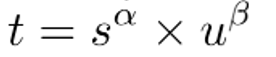
s 和 u 分别为分类得分和 IoU 值,α 和 β 为权重超参。从上边的公式可以看出来,t 可以同时控制分类得分和IoU 的优化来实现 Task-Alignment,可以引导网络动态的关注于高质量的Anchor。
Training sample Assignment:
为提升两个任务的对齐性,TOOD聚焦于Task-Alignment Anchor,采用一种简单的分配规则选择训练样本:对每个实例,选择m个具有最大t值的Anchor作为正样本,选择其余的Anchor作为负样本。然后,通过损失函数(针对分类与定位的对齐而设计的损失函数)进行训练。
4.YOLOv8环境安装
在这之前,需要先准备主机的环境,环境如下:
Ubuntu18.04 or win10\11
cuda11.3
pytorch:1.11.0
torchvision:0.12.0
创建虚拟环境并配置pytorch,torch安装可参考:https://blog.csdn.net/yohnyang/article/details/123199854
#创建:
conda create -n yolov8 python=3.8
#进入虚拟环境
conda activate yolov8
pip install ultralytics
5.模型训练
5.1 构建自己的训练集
-
YOLOv8可以进行分类,检测和分割类任务的学习,我们以检测类任务为例,并训练YOLOv8s,其数据集的准备完全和YOLOv5,YOLOv6,YOLOv7的一致。
在yolov8/data目录下新建Annotations, images, ImageSets, labels 四个文件夹
- images目录下存放数据集的图片文件
- Annotations目录下存放图片的xml文件(labelImg标注)
目录结构如下所示
.
├── ./data
│ ├── ./data/Annotations
│ │ ├── ./data/Annotations/fall_0.xml
│ │ ├── ./data/Annotations/fall_1000.xml
│ │ ├── ./data/Annotations/fall_1001.xml
│ │ ├── ./data/Annotations/fall_1002.xml
│ │ ├── ./data/Annotations/fall_1003.xml
│ │ ├── ./data/Annotations/fall_1004.xml
│ │ ├── ...
│ ├── ./data/images
│ │ ├── ./data/images/fall_0.jpg
│ │ ├── ./data/images/fall_1000.jpg
│ │ ├── ./data/images/fall_1001.jpg
│ │ ├── ./data/images/fall_1002.jpg
│ │ ├── ./data/images/fall_1003.jpg
│ │ ├── ./data/images/fall_1004.jpg
│ │ ├── ...
│ ├── ./data/ImageSets
│ └── ./data/labels
-
按比例划分数据集
- 在yolov8根目录下新建一个文件splitDataset.py,运行,随机分配训练/验证/测试集图片,代码如下所示:
import os
import random
trainval_percent = 0.9
train_percent = 0.9
xmlfilepath = 'data/Annotations'
txtsavepath = 'data/ImageSets'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('data/ImageSets/trainval.txt', 'w')
ftest = open('data/ImageSets/test.txt', 'w')
ftrain = open('data/ImageSets/train.txt', 'w')
fval = open('data/ImageSets/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
-
将xml文件转换成YOLO系列标准读取的txt文件
- 在同级目录下再新建一个文件XML2TXT.py
- 注意classes = [“…”]一定需要填写自己数据集的类别,在这里我是一个类别"fall",此classes = [“fall”],代码如下所示:
# -*- coding: utf-8 -*-
# xml解析包
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets = ['train', 'test', 'val']
classes = ['fall']
# 进行归一化操作
def convert(size, box): # size:(原图w,原图h) , box:(xmin,xmax,ymin,ymax)
dw = 1./size[0] # 1/w
dh = 1./size[1] # 1/h
x = (box[0] + box[1])/2.0 # 物体在图中的中心点x坐标
y = (box[2] + box[3])/2.0 # 物体在图中的中心点y坐标
w = box[1] - box[0] # 物体实际像素宽度
h = box[3] - box[2] # 物体实际像素高度
x = x*dw # 物体中心点x的坐标比(相当于 x/原图w)
w = w*dw # 物体宽度的宽度比(相当于 w/原图w)
y = y*dh # 物体中心点y的坐标比(相当于 y/原图h)
h = h*dh # 物体宽度的宽度比(相当于 h/原图h)
return (x, y, w, h) # 返回 相对于原图的物体中心点的x坐标比,y坐标比,宽度比,高度比,取值范围[0-1]
# year ='2012', 对应图片的id(文件名)
def convert_annotation(image_id):
'''
将对应文件名的xml文件转化为label文件,xml文件包含了对应的bunding框以及图片长款大小等信息,
通过对其解析,然后进行归一化最终读到label文件中去,也就是说
一张图片文件对应一个xml文件,然后通过解析和归一化,能够将对应的信息保存到唯一一个label文件中去
labal文件中的格式:calss x y w h 同时,一张图片对应的类别有多个,所以对应的bunding的信息也有多个
'''
# 对应的通过year 找到相应的文件夹,并且打开相应image_id的xml文件,其对应bund文件
in_file = open('data/Annotations/%s.xml' % (image_id), encoding='utf-8')
# 准备在对应的image_id 中写入对应的label,分别为
# <object-class> <x> <y> <width> <height>
out_file = open('data/labels/%s.txt' % (image_id), 'w', encoding='utf-8')
# 解析xml文件
tree = ET.parse(in_file)
# 获得对应的键值对
root = tree.getroot()
# 获得图片的尺寸大小
size = root.find('size')
# 如果xml内的标记为空,增加判断条件
if size != None:
# 获得宽
w = int(size.find('width').text)
# 获得高
h = int(size.find('height').text)
# 遍历目标obj
for obj in root.iter('object'):
# 获得difficult ??
difficult = obj.find('difficult').text
# 获得类别 =string 类型
cls = obj.find('name').text
# 如果类别不是对应在我们预定好的class文件中,或difficult==1则跳过
if cls not in classes or int(difficult) == 1:
continue
# 通过类别名称找到id
cls_id = classes.index(cls)
# 找到bndbox 对象
xmlbox = obj.find('bndbox')
# 获取对应的bndbox的数组 = ['xmin','xmax','ymin','ymax']
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
print(image_id, cls, b)
# 带入进行归一化操作
# w = 宽, h = 高, b= bndbox的数组 = ['xmin','xmax','ymin','ymax']
bb = convert((w, h), b)
# bb 对应的是归一化后的(x,y,w,h)
# 生成 calss x y w h 在label文件中
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
# 返回当前工作目录
wd = getcwd()
print(wd)
for image_set in sets:
'''
对所有的文件数据集进行遍历
做了两个工作:
1.将所有图片文件都遍历一遍,并且将其所有的全路径都写在对应的txt文件中去,方便定位
2.同时对所有的图片文件进行解析和转化,将其对应的bundingbox 以及类别的信息全部解析写到label 文件中去
最后再通过直接读取文件,就能找到对应的label 信息
'''
# 先找labels文件夹如果不存在则创建
if not os.path.exists('data/labels/'):
os.makedirs('data/labels/')
# 读取在ImageSets/Main 中的train、test..等文件的内容
# 包含对应的文件名称
image_ids = open('data/ImageSets/%s.txt' % (image_set)).read().strip().split()
# 打开对应的2012_train.txt 文件对其进行写入准备
list_file = open('data/%s.txt' % (image_set), 'w')
# 将对应的文件_id以及全路径写进去并换行
for image_id in image_ids:
list_file.write('data/images/%s.jpg\n' % (image_id))
# 调用 year = 年份 image_id = 对应的文件名_id
convert_annotation(image_id)
# 关闭文件
list_file.close()
-
查看自定义数据集标签类别及数量
- 在yolov8目录下再新建一个文件ViewCategory.py,将代码复制进去
import os
from unicodedata import name
import xml.etree.ElementTree as ET
import glob
def count_num(indir):
label_list = []
# 提取xml文件列表
os.chdir(indir)
annotations = os.listdir('.')
annotations = glob.glob(str(annotations) + '*.xml')
dict = {} # 新建字典,用于存放各类标签名及其对应的数目
for i, file in enumerate(annotations): # 遍历xml文件
# actual parsing
in_file = open(file, encoding='utf-8')
tree = ET.parse(in_file)
root = tree.getroot()
# 遍历文件的所有标签
for obj in root.iter('object'):
name = obj.find('name').text
if (name in dict.keys()):
dict[name] += 1 # 如果标签不是第一次出现,则+1
else:
dict[name] = 1 # 如果标签是第一次出现,则将该标签名对应的value初始化为1
# 打印结果
print("各类标签的数量分别为:")
for key in dict.keys():
print(key + ': ' + str(dict[key]))
label_list.append(key)
print("标签类别如下:")
print(label_list)
if __name__ == '__main__':
# xml文件所在的目录,修改此处
indir = 'data/Annotations'
count_num(indir) # 调用函数统计各类标签数目
5.2构建自己训练集的配置文件和模型配置文件
模型配置文件:
#yolov8s.yaml
# Parameters
nc: 4 # number of classes
depth_multiple: 0.33 # scales module repeats
width_multiple: 0.50 # scales convolution channels
# YOLOv8.0s backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0s head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 13
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 17 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 20 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 23 (P5/32-large)
- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
- 数据集配置文件
#score_data.yaml
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
train: ./dataset/score/images/train # train images
val: ./dataset/score/images/val # val images
#test: ./dataset/score/images/test # test images (optional)
# Classes
names:
0: person
1: cat
2: dog
3: horse
训练超参数配置文件
我们对训练的超参数进行了简单的修改,通过命令行参数传入,也可以通过配置文件进行配置。
task: "detect" # choices=['detect', 'segment', 'classify', 'init'] # init is a special case. Specify task to run.
mode: "train" # choices=['train', 'val', 'predict'] # mode to run task in.
# Train settings -------------------------------------------------------------------------------------------------------
model: null # i.e. yolov8n.pt, yolov8n.yaml. Path to model file
data: null # i.e. coco128.yaml. Path to data file
epochs: 100 # number of epochs to train for
patience: 50 # TODO: epochs to wait for no observable improvement for early stopping of training
batch: 16 # number of images per batch
imgsz: 640 # size of input images
save: True # save checkpoints
cache: False # True/ram, disk or False. Use cache for data loading
device: '' # cuda device, i.e. 0 or 0,1,2,3 or cpu. Device to run on
workers: 8 # number of worker threads for data loading
project: null # project name
name: null # experiment name
exist_ok: False # whether to overwrite existing experiment
pretrained: False # whether to use a pretrained model
optimizer: 'SGD' # optimizer to use, choices=['SGD', 'Adam', 'AdamW', 'RMSProp']
...
5.3 目标检测任务训练
- 单卡训练:打开终端(或者pycharm等IDE),进入虚拟环境,随后进入yolov8文件夹,在终端中输入下面命令,即可开始训练。
yolo task=detect mode=train model=yolov8n.pt data=data/fall.yaml batch=32 epochs=100 imgsz=640 workers=16 device=0
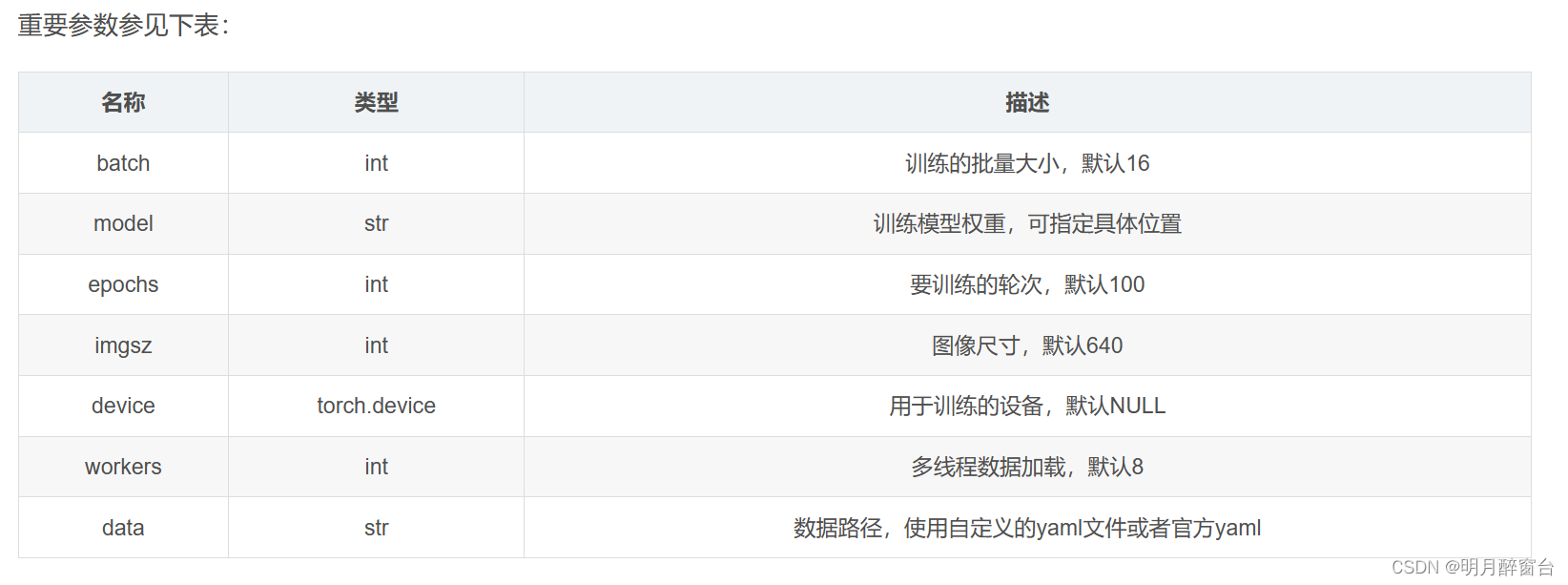
- 多卡训练:yolov8的多卡训练其实很简单,不需要使用繁琐的命令行指令,仅需把device='0,1,2,3’即可,注意一定要加\和引号
yolo task=detect mode=train model=yolov8n.pt data=data/fall.yaml batch=32 epochs=100 imgsz=640 workers=16 device=\'0,1,2,3\'


6. 模型推理demo
# 自己实现的推断程序
python3 inference.py
推理结果如下:

|

|

|

|
7. 模型部署
下边主要介绍通过TensorRT为模型加速!
pth模型转onnx
#CLI
yolo task=detect mode=export model=./runs/detect/train/weights/last.pt format=onnx simplify=True opset=13
# python
from ultralytics import YOLO
model = YOLO("./runs/detect/train/weights/last.pt ") # load a pretrained YOLOv8n model
model.export(format="onnx") # export the model to ONNX format
增加NMS Plugin
执行tensorrt/下的如下代码,添加NMS到YOLOv8模型
添加后处理
python3 yolov8_add_postprocess.py
添加NMS plugin
python3 yolov8_add_nms.py
生成last_1_nms.onnx,打开该文件对比和原onnx文件的区别,发现增加了如下节点(完成了将NMS添加到onnx的目的):

onnx转trt engine
trtexec --onnx=last_1_nms.onnx --saveEngine=yolov8s.plan --workspace=3000 --verbose

出现上述界面,onnx正常序列化为TRT engine.
TRT C++推理
在win 10下基于RTX 1060 TensorRT 8.2.1进行测试,我们的开发环境是VS2017,所有C++代码已经存放在tensorrt/文件夹下。其推断结果如下图所示(可以发现我们实现了YOLOv8的TensorRT端到端的推断,其推断结果与原训练框架保持一致):

|

|

|

|
主要参考:
1.YOLOv8来啦 | 详细解读YOLOv8的改进模块!YOLOv5官方出品YOLOv8!
2.YOLOv8的改进
3.YOLOv8教程系列:使用自定义数据集训练YOLOv8模型(详细版教程),包含环境搭建/数据准备/模型训练/预测/验证/导出等