过去,领导、决策者或业务人员想要统计个数据、做个报告,总是绕不开技术人员的支持。领导需要将想法告诉技术人员,技术人员再将领导的想法转成技术语言(例如:sql),然后对数据进行统计分析,以满足领导的期望。整个过程非常低效!
随着大模型能力逐步强大、场景越来越丰富,从Text到sql或者从Chat到sql的方案也十分火热,这个方案主要是利用大模型将自然语言转化为可以执行的Sql语句,进行数据分析,并根据结果实现报告生成或者可视化展示。这种方案提高了领导们随时想要报告的效率,缓解了应对向上汇报的焦虑,在许多决策支持、大屏展示等场景中非常见效。
本文主要收集了几个比较优秀的Text2Sql相关的开源项目或者资源,供借鉴。
01
Chat2db
GitHub Star 14K
https://github.com/chat2db/chat2db
图片
图片
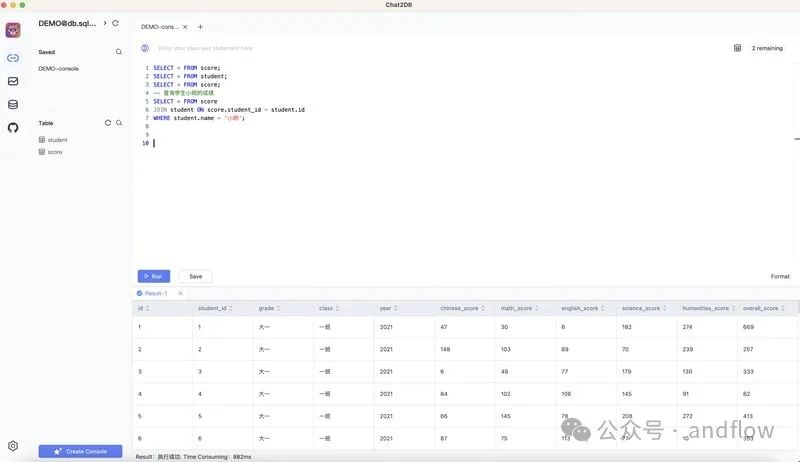
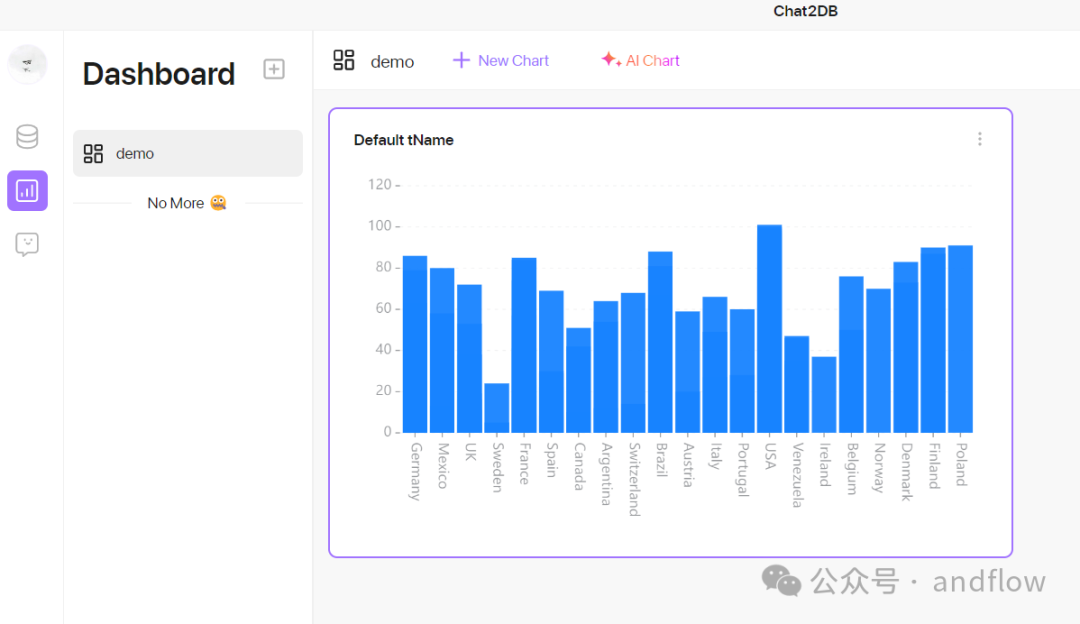
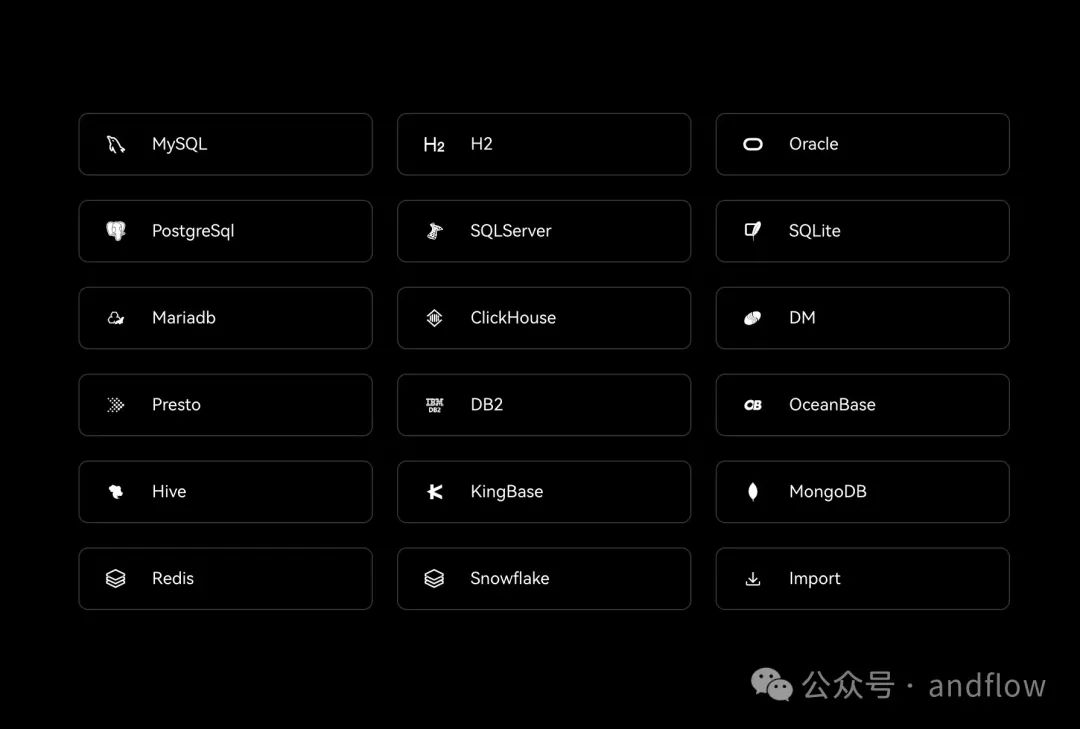
Chat2DB旨在成为一个通用的SQL客户端和报告工具,从一开始就包含AI功能。它支持几乎所有比较流行的数据库、缓存,包括:
MySQL
PostgreSQL
H2
Oracle
SQLServer
SQLite
MariaDB
ClickHouse
DM
Presto
DB2
OceanBase
Hive
KingBase
MongoDB
Redis
Snowflake
图片
此外,chat2DB还提供了它的7B开源模型:
GitHub:
https://github.com/chat2db/Chat2DB-GLM
Huggingface:
https://huggingface.co/Chat2DB/Chat2DB-SQL-7B
Modelscope:
https://modelscope.cn/models/Chat2DB/Chat2DB-SQL-7B
02
GitHub Star 4K
https://github.com/sqlchat/sqlchat
图片
图片
图片
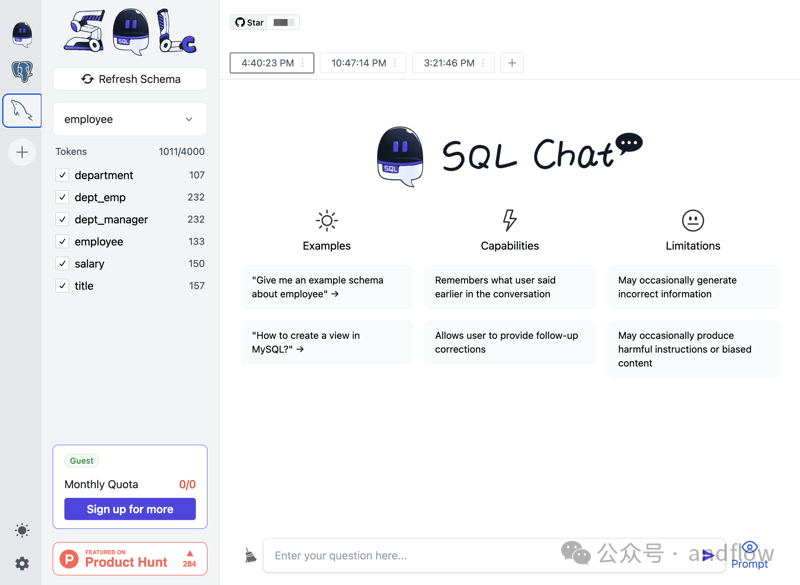
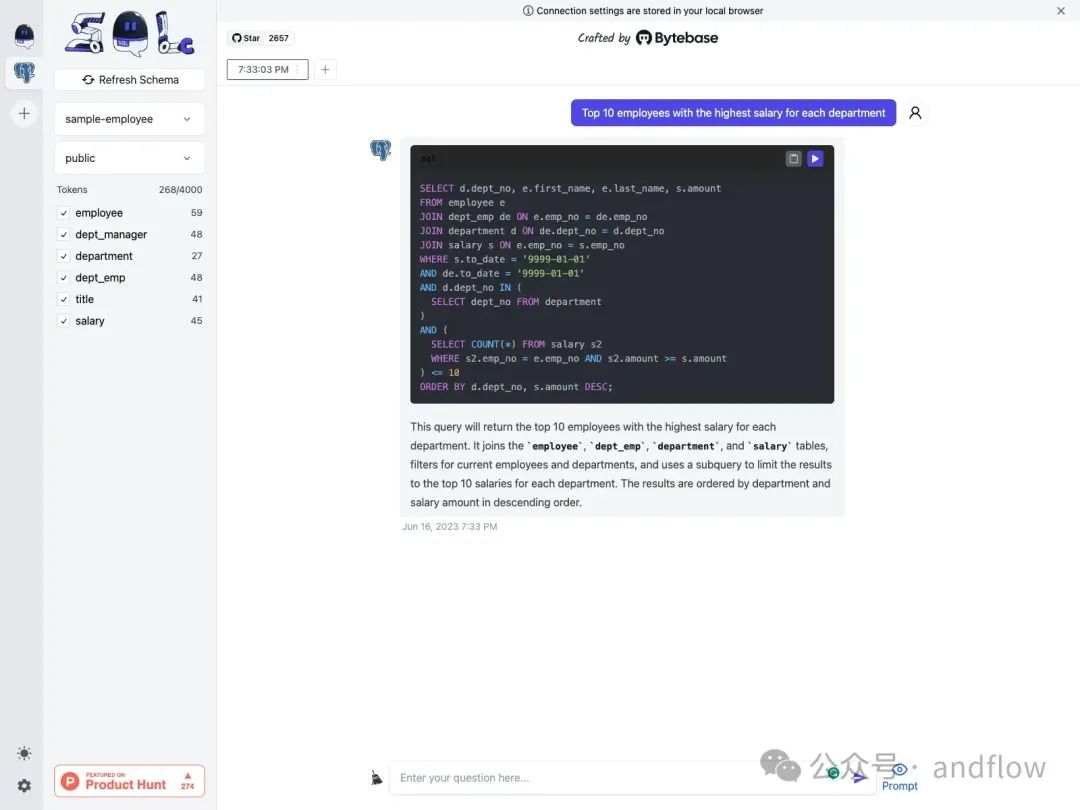
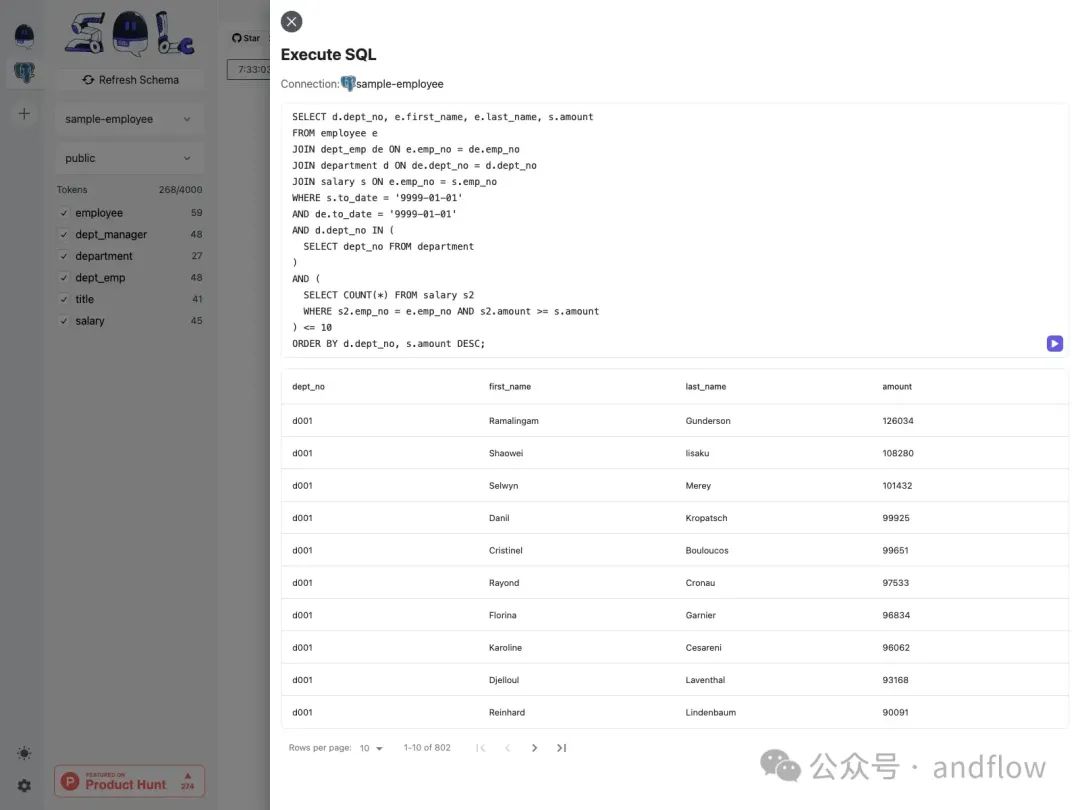
SQL Chat是一个基于聊天的SQL客户端,您可以使用自然语言与数据库进行通信,以实现查询、修改、添加和删除等操作。
它目前支持MySQL,Postgres,SQL Server和TiDB无服务器。
03
GitHub Star 7.7K
https://github.com/vanna-ai/vanna
图片
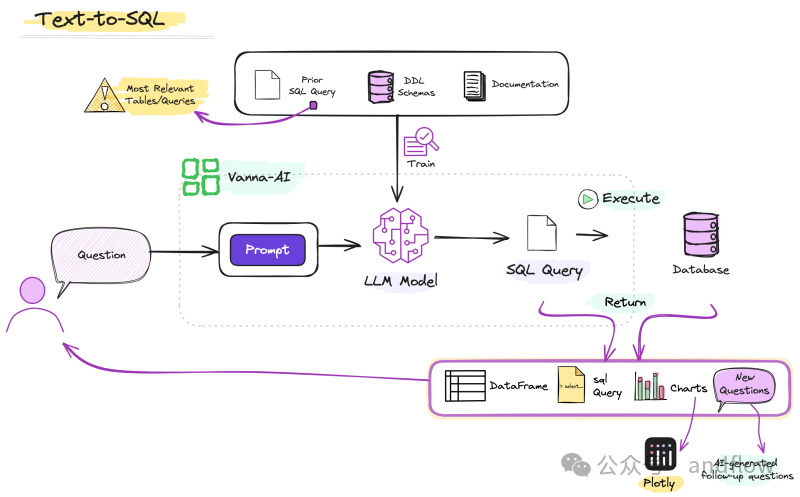
Vanna是一个开源的开源Python RAG(检索增强生成)框架。Vanna通过整合上下文(元数据、定义、查询等)以及领域知识文档来训练RAG模型。在Vanna框架的基础上可以使用现有工具(例如Streamlit、Slack)构建自定义可视化UI,实现对话结果的可视化。
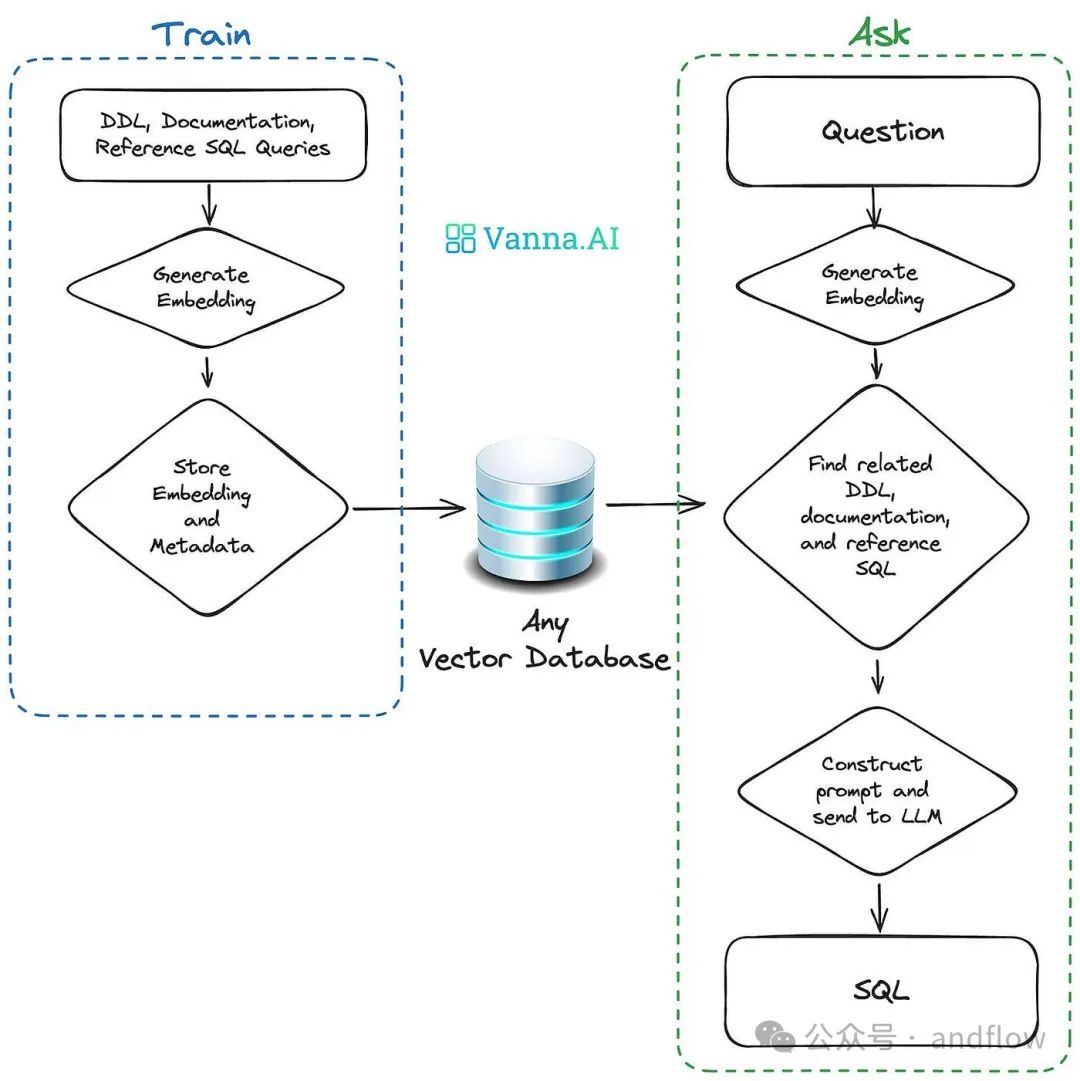
Vanna通过两个简单的步骤进行操作:
(1)基于数据训练RAG“模型”。
(2)提出问题返回SQL查询,并且可以将查询配置为在数据库上自动运行。
图片
04
Dataherald
GitHub Star 3.1K
https://github.com/Dataherald/dataherald

图片
Dataherald是一个自然语言到SQL引擎,为在关系数据库上的企业级问答而构建。它允许您从数据库中设置一个API,可以用简单的对话进行问答。
他的功能包括:
允许业务用户从数据仓库中获得结果,而无需通过数据分析师
在SaaS应用程序中启用来自生产数据库的Q+A
从您的专有数据创建ChatGPT插件
Dataherald开源代码库包含四大模块:引擎、管理控制台、企业后端和Slackbot。其中,核心引擎模块包含了LLM代理、向量存储和数据库连接器等关键组件。Dataherald 代码的亮点之一是模块化设计,将不同的功能模块封装成独立的类和方法,便于代码维护和扩展,也使得 Dataherald 可以轻松地集成新的工具和功能。
05
GitHub Star 1K
https://github.com/Canner/WrenAI
图片
图片
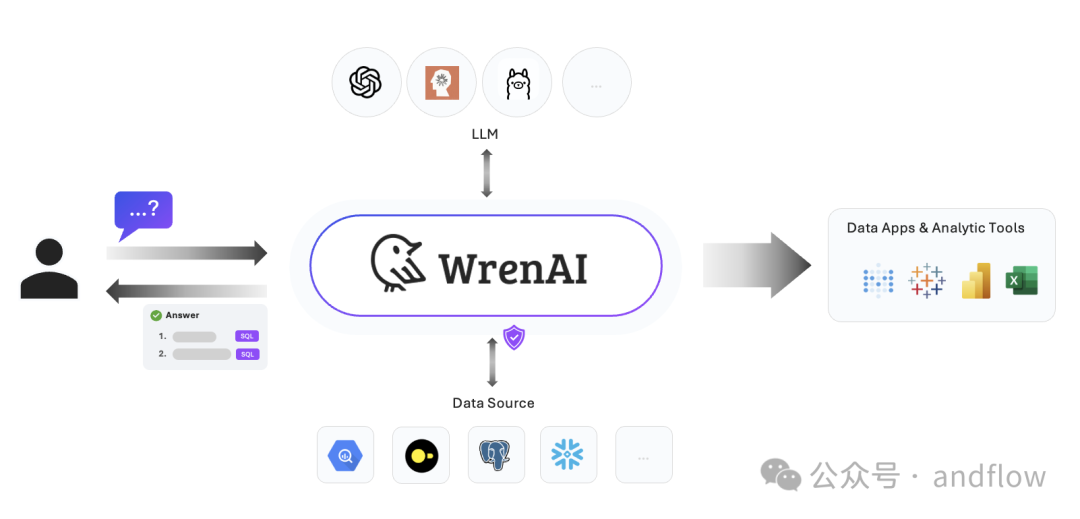
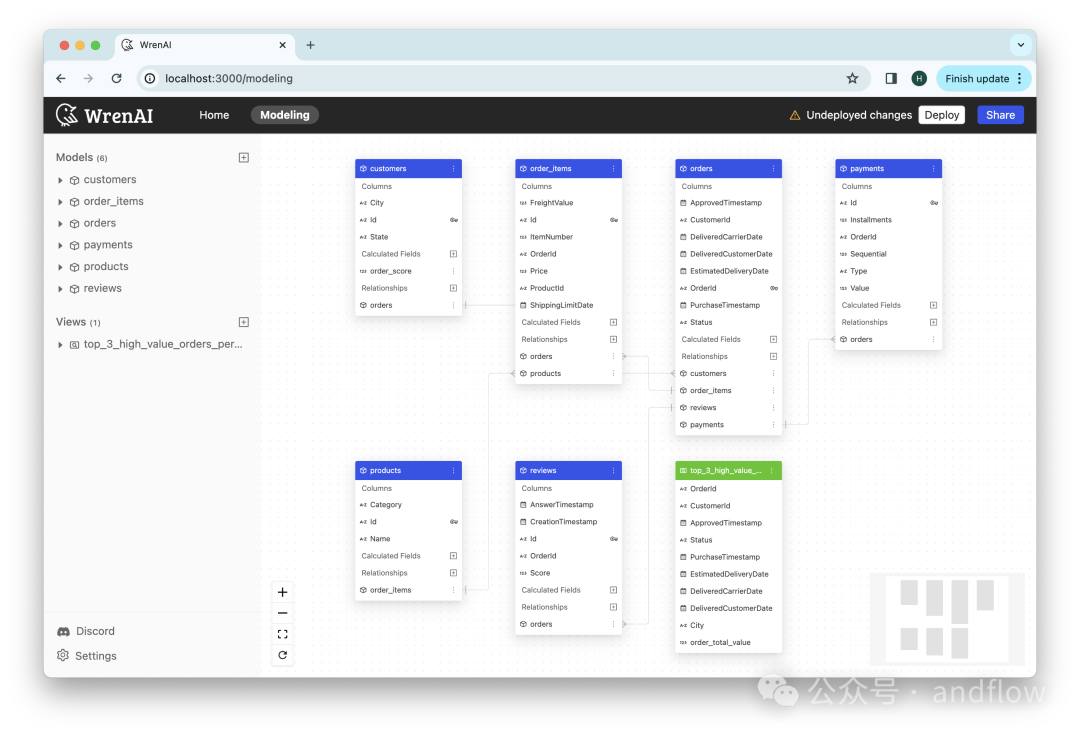
WrenAI是一个文本到SQL的解决方案,数据团队可以通过询问业务问题而无需编写SQL,可更快地获得分析结果。
其核心理念是利用 LLMs 和 RAG 技术的优势,将自然语言转换为 SQL 查询,并从数据库中检索数据。用户只需用自然语言提出问题,例如“上个月哪个产品的销量最高?”,WrenAI 就能自动将其转换为相应的 SQL 查询,并返回准确的结果。
WrenAI 的核心功能和优势:
开源免费: 用户可以根据自己的需求自由部署和使用 WrenAI。开源的力量,让 WrenAI 更加强大!
06
https://github.com/tencentmusic/supersonic
图片
图片
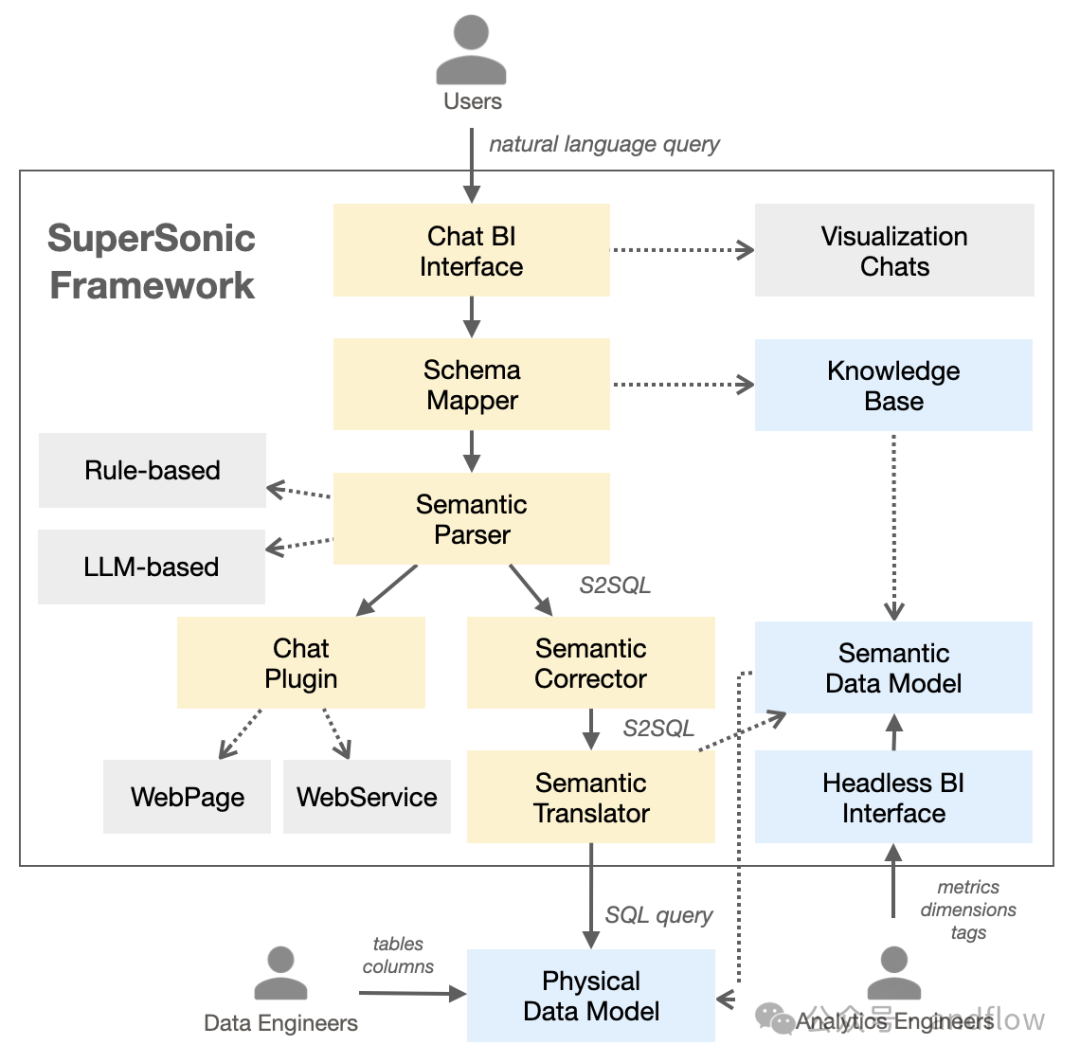
模型知识库(Knowledge Base): 定期从语义模型中提取相关的模式信息,构建词典和索引,以便后续的模式映射。
模式映射器(Schema Mapper): 将自然语言文本在知识库中进行匹配,为后续的语义解析提供相关信息。
语义解析器(Semantic Parser): 理解用户查询并抽取语义信息,生成语义查询语句S2SQL。
语义修正器(Semantic Corrector): 检查语义查询语句的合法性,对不合法的信息做修正和优化处理。
语义翻译器(Semantic Translator): 将语义查询语句翻译成可在物理数据模型上执行的SQL语句。
问答插件(Chat Plugin): 通过第三方工具扩展功能。给定所有配置的插件及其功能描述和示例问题,大语言模型将选择最合适的插件。
图片
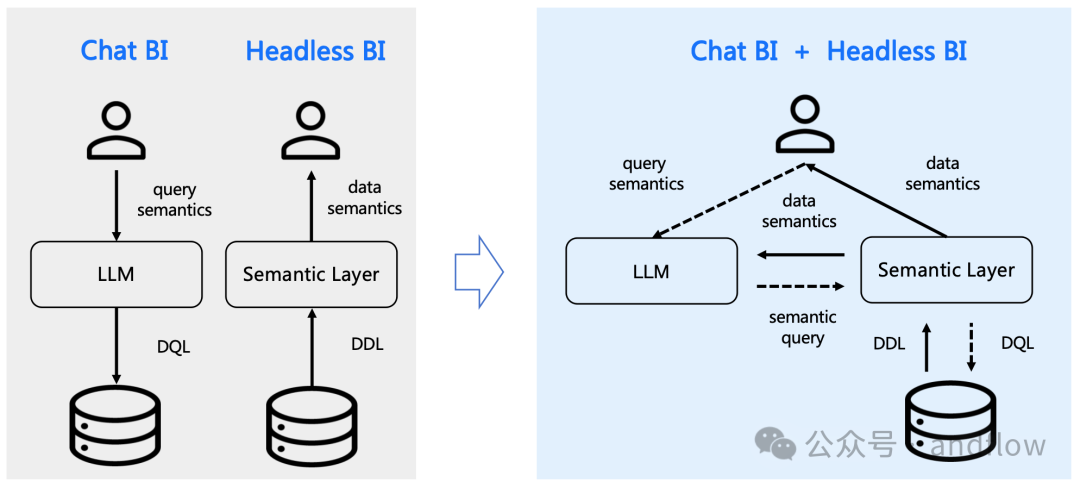
SuperSonic融合Chat BI(powered by LLM)和Headless BI(powered by 语义层)打造新一代的BI平台。这种融合确保了Chat BI能够与传统BI一样访问统一化治理的语义数据模型。此外,两种BI新范式都从中获得收益:
Chat BI的Text2SQL生成通过检索语义数据模型得到增强。
Headless BI的查询接口通过支持自然语言API得到拓展。
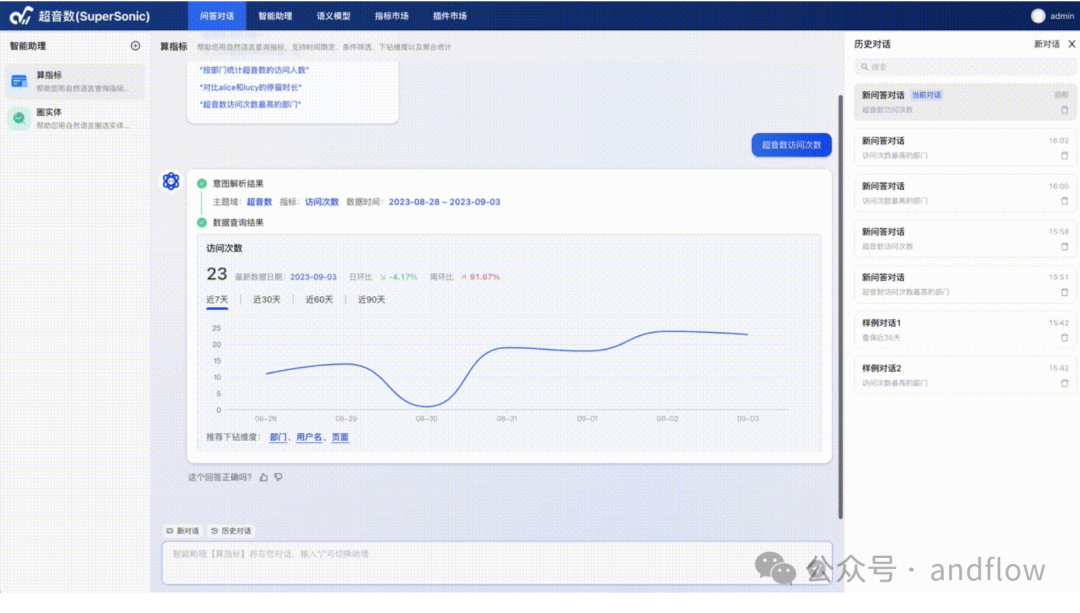
通过SuperSonic的问答对话界面,用户能够使用自然语言查询数据,系统会选择合适的可视化图表呈现结果。SuperSonic不需要修改或复制数据,只需要在物理数据模型之上构建逻辑语义模型(定义指标/维度/实体/标签,以及它们的业务含义、相互关系等),即可开启数据问答体验。与此同时,SuperSonic被设计为可插拔的框架,采用Java SPI机制来扩展定制功能。
07
https://github.com/eosphoros-ai/Awesome-Text2SQL
图片
08
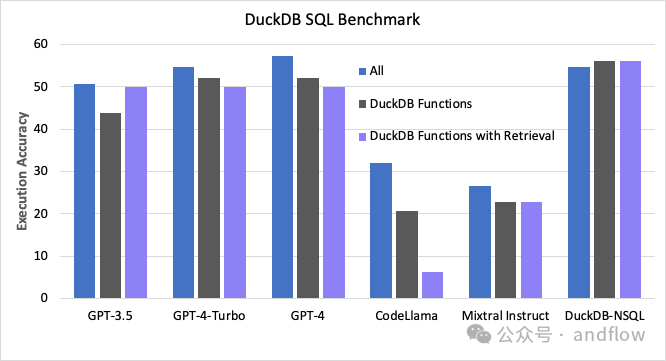
https://github.com/NumbersStationAI/DuckDB-NSQL
图片
DuckDB-NSQL是一个由MontherDuck和Numbers Station为DuckDB SQL分析任务构建的Text 2SQL LLM。可以帮助用户利用DuckDB的全部功能及其分析潜力,而不需要在DuckDB文档和SQL shell之间来回切换。
09
文档:
https://python.langchain.com/v0.1/docs/use_cases/sql/
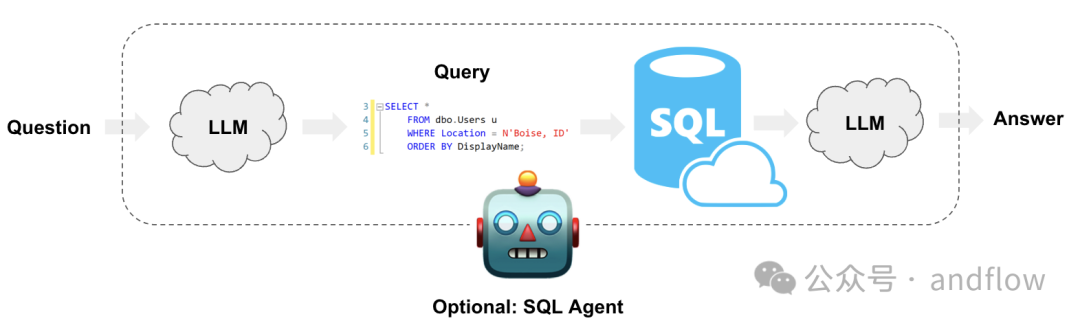
图片
Langchain是一个比较知名的大模型应用框架,但其实,Langchain也可以让我们在自己在SQL数据库上构建一个问答链代理。
可以将LangChain的SQL代理添加到链上。它不仅可以根据数据库的模式和内容回答问题,还可以通过运行生成的查询、捕获回溯,并从错误中恢复,重新生成。
最后
由于大模型的发展是一个逐步增强的过程,在这个过程中,许多大模型还存在不确定、不稳定。在使用基于大模型的Text2Sql方案所生成的SQL查询还需要格外小心验证,以最小化应用风险。
尽量做到:清楚描述数据库上下文、限制数据查询输出的大小、在执行之前验证和检查生成的SQL语句。






![[Spring Boot实战] 如何快速地创建spring boot项目](https://img-blog.csdnimg.cn/direct/7b8127d8e68e434ca84dc49c48e55dd5.png)