NLP原理系列1-说清楚transformer原理
来用思维导图和截图描述。
思维导图的本质是 变化(解决问题)-> 更好的, 或者复杂问题拆分为小问题 以及拆分的思路。
经典全图
0 transformer的前世今生
1 seq2seq
序列化数据 到 序列化数据, 只要能把 训练数据和label转为序列,就都可以用这个模型来训练
2 attention和self-attention
当输入为一个不定长的向量,就得使用attention机制。
可以是语句txt,每个词是一个向量, 每个句子就是一个vec set
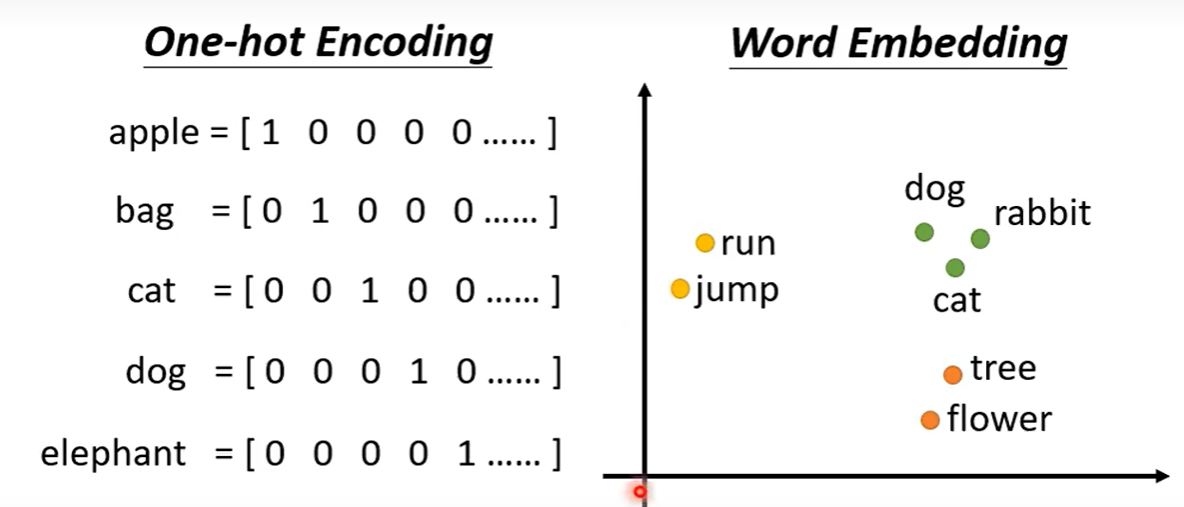
那么怎么把一个词转为向量呢?
3 输入和输出到底可以都是什么?
输入: 1 文本 2 语音 3 graph
输出: 对应的vec label,不对应的vec label数量。
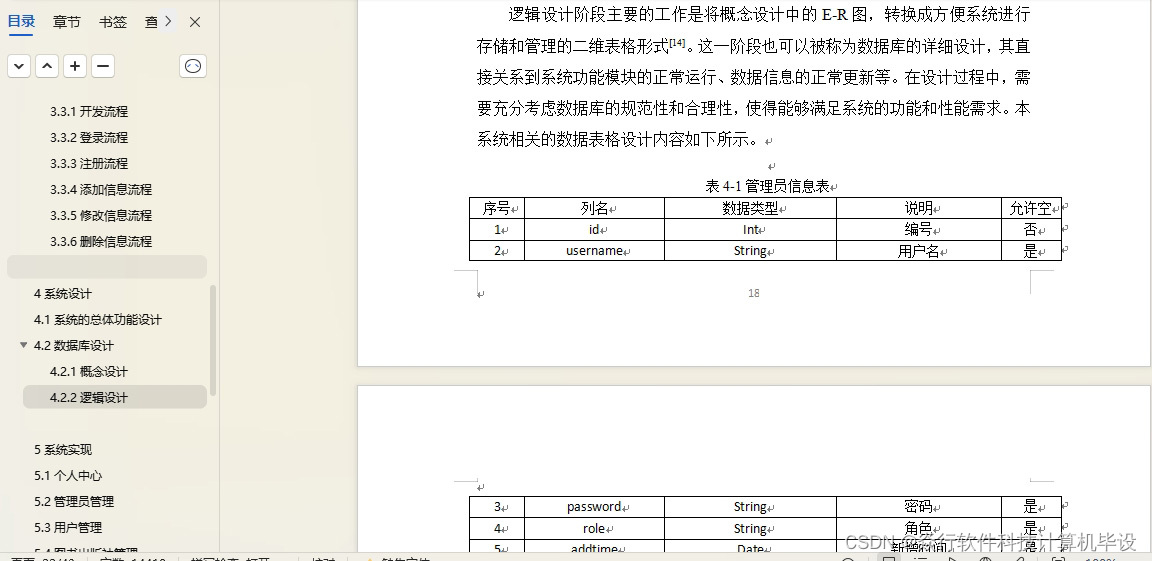
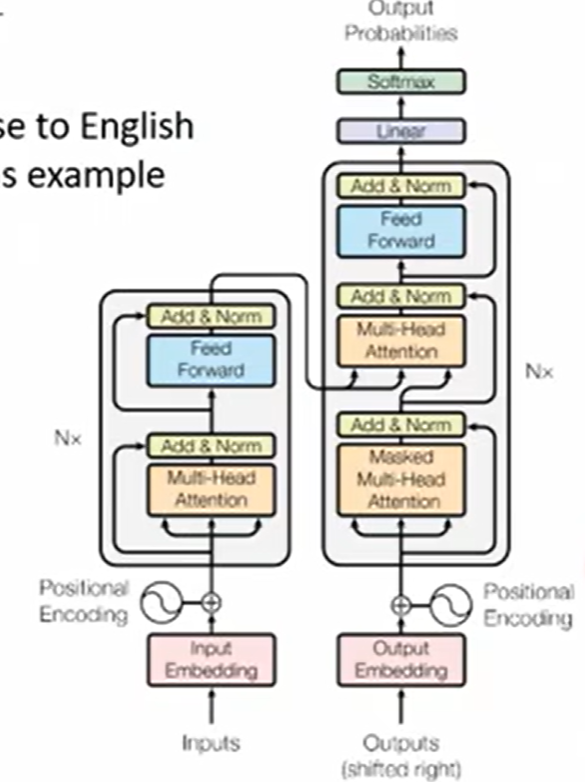
一 tansformer的推理及训练过程
1 tf 训练过程
红框部分是 训练得grandtruth,正确答案。
decoder的上面输出部分是 推理结果。 采用了一些teach model
2 tf 推理过程
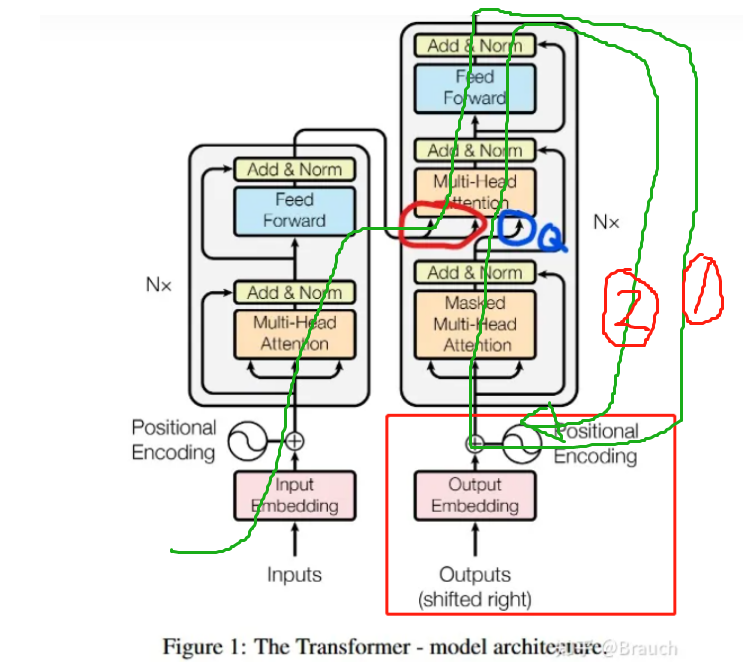
假如我们的场景是问答,问题是“中国的首都是哪里?”
推理阶段最开始,左侧Input就是这个问题,右下Outputs就是起始符,Inputs和Outputs共同进行前向传播,它们会在中间蓝笔红笔那部分完成汇合,然后到右上侧推理出“北”(如果模型效果尚可,确实能正确推理出“北京”的话),“北”作为本步推理结果,就会被送入Outputs拼在起始符后方,然后Inputs和带有“北”的Outputs又共同前向传播,又再汇合推理出“京”…大抵是这么一个往复的过程
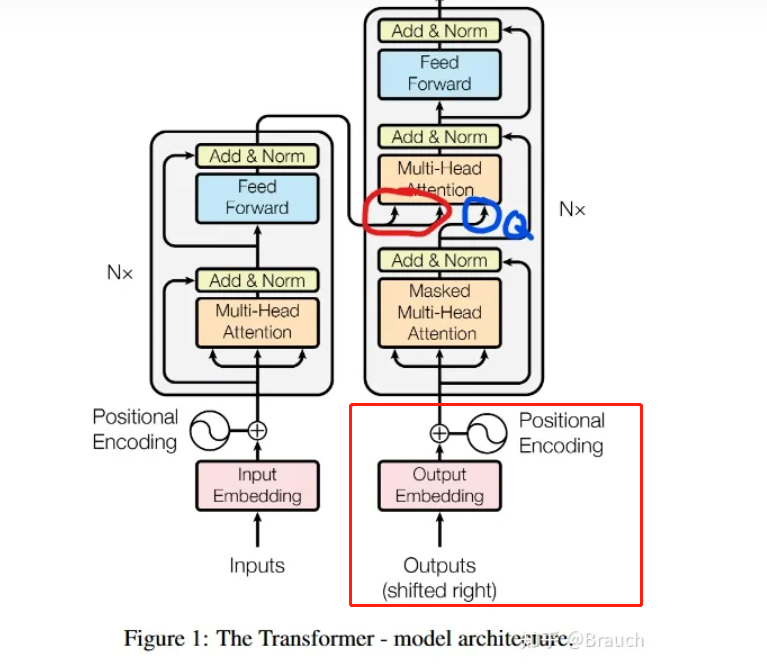
推理优化过程
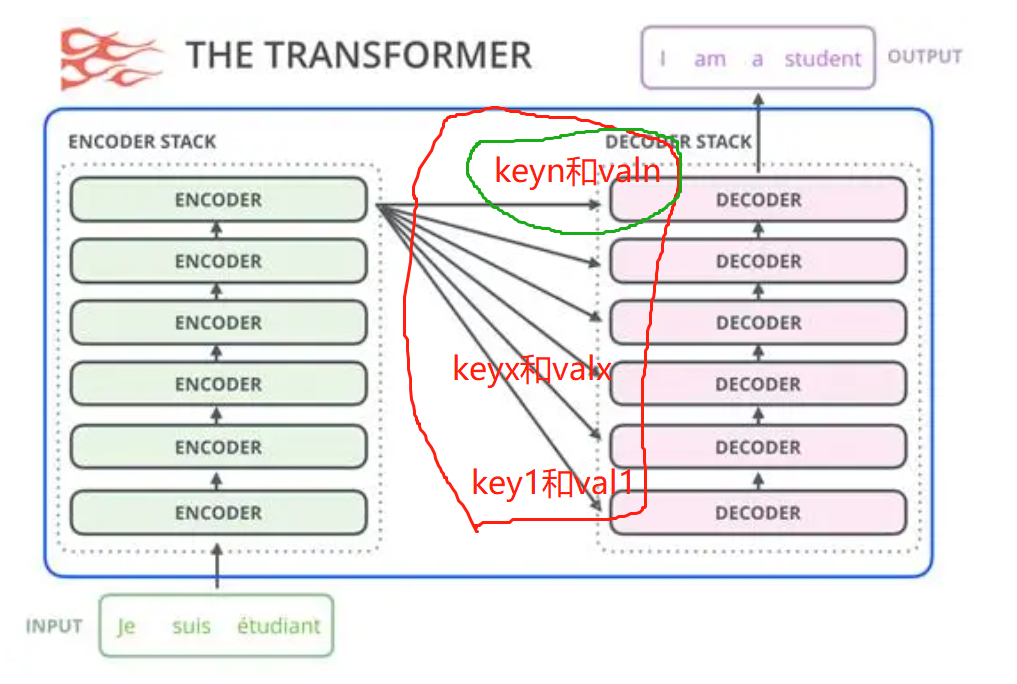
紫色部分只执行一次,如果计算出来的红圈部分保存的话。 红圈部分是 key 和value, 篮圈是query。
如描述的推理过程, 推理到 “北”字后,只有那个"北"的 logist 回来到红框 位置生成新的query,与原来的key和value汇合。
绿色部分是一个 decoder block块
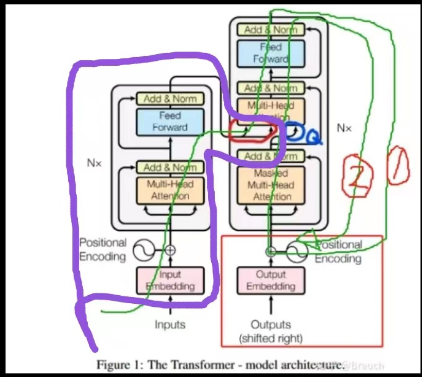
我们构造一个较复杂多层模型
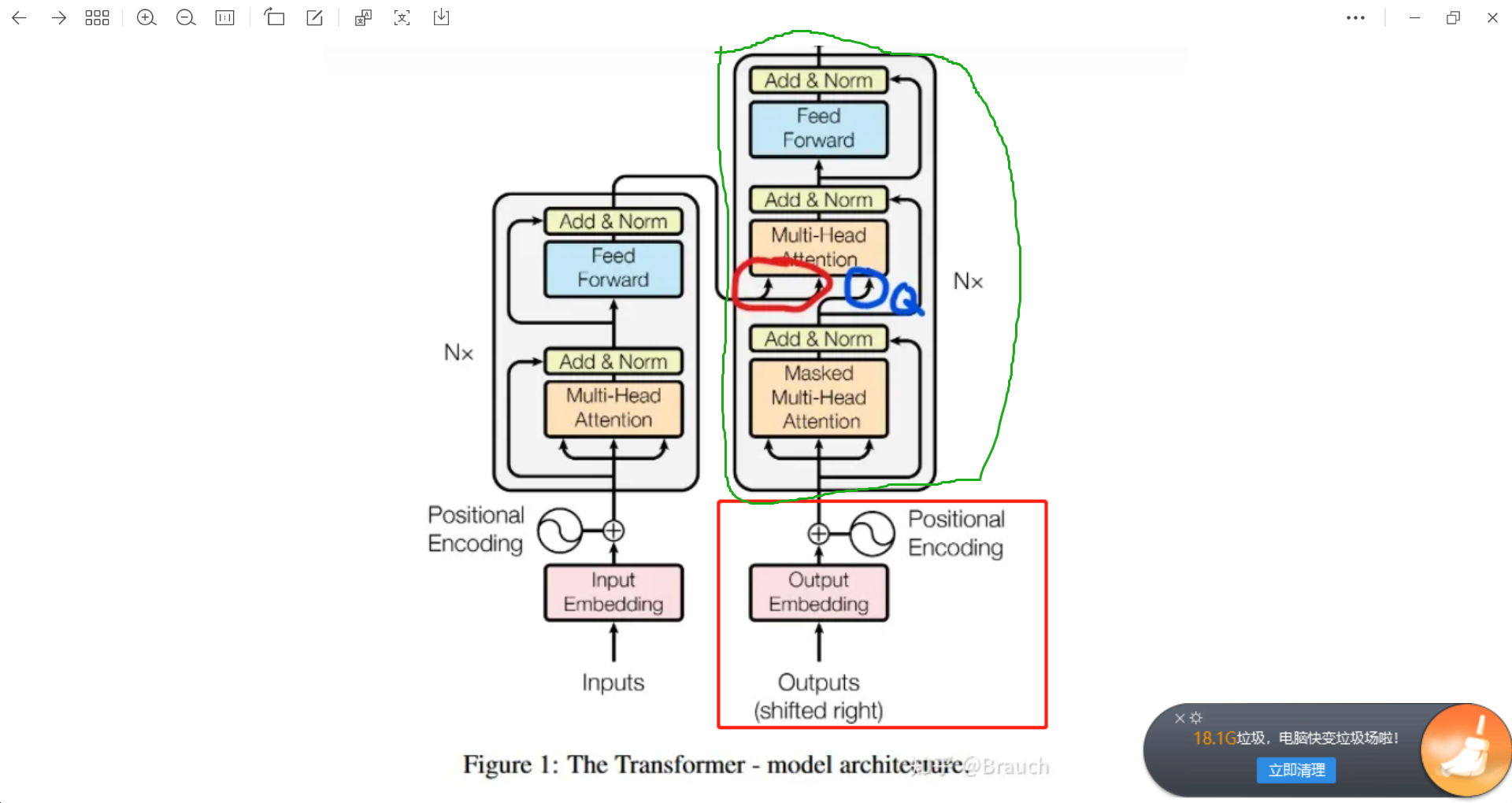
保存任何一组key和val即可。
二 更多细节transformer 数据如何运行
2.1 encoder前半部分
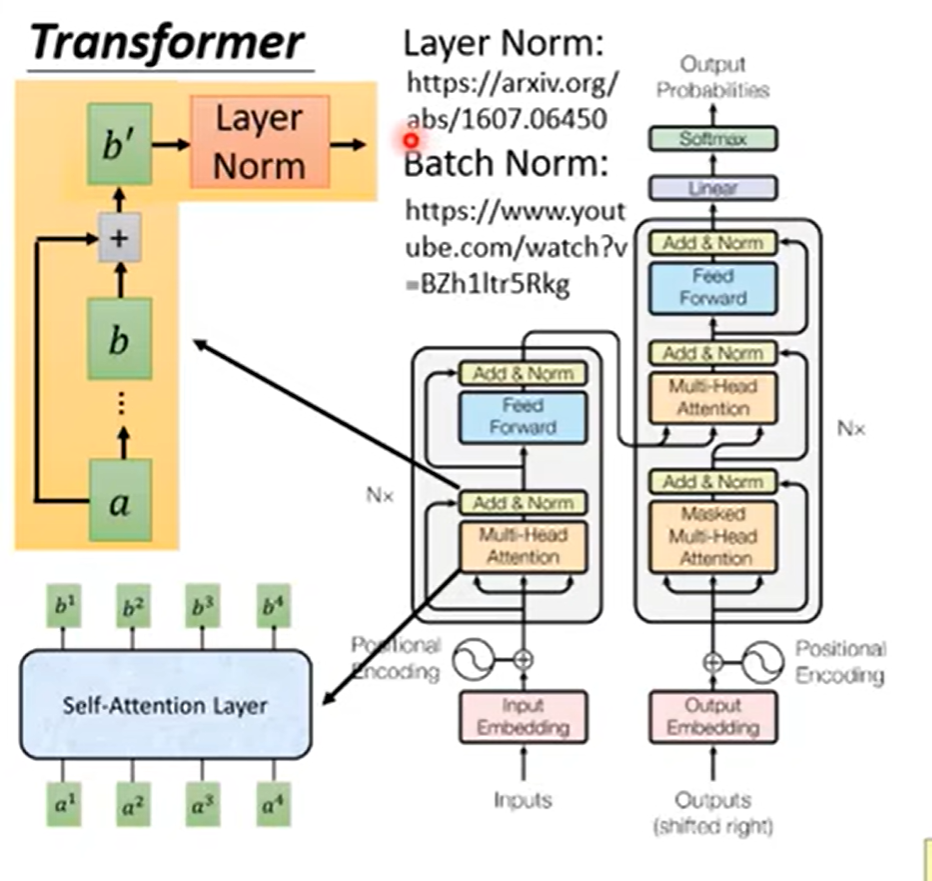
2.2 encoder后半部分
2.3 attention_mask如何起作用
1)在训练中的作用
2)在推理中的作用
3)在encoder还是在decoder中起作用?
2.4 推理过程
AT机制,先(程序输入decoder一个 BOS,), dec的输出返回来作为输入,逐个推理,最后推理到end。
attention_mask 遮挡未推理位置
推理过程中也是输出的一个字,作为下一个的输入。 -> 那么计算attention_mask不就是没有意义了吗??????????
如何解决 exposure bias-> scheduled sampling 一步错步步错的问题
2.5 训练过程
1 确定crossentypy为损失函数
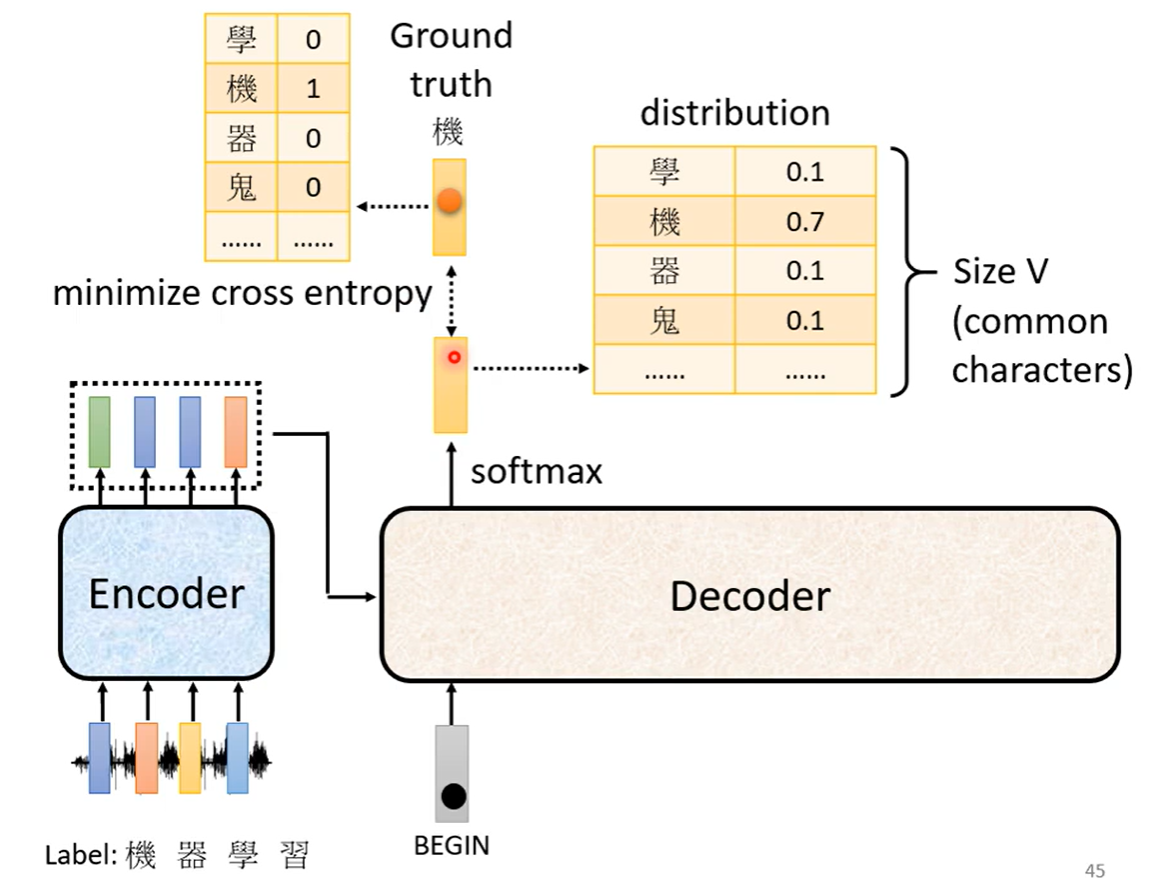
2 关于decoder的输入
使用正确数据 grandtruth ,使用teacher_forcing方法. 是否开attention_mask???????
3 对于optimization的口诀
比如metric 使用BELU,但是不太容易合入更新梯度中,就使用RL。
4 如何更新encoder参数???????
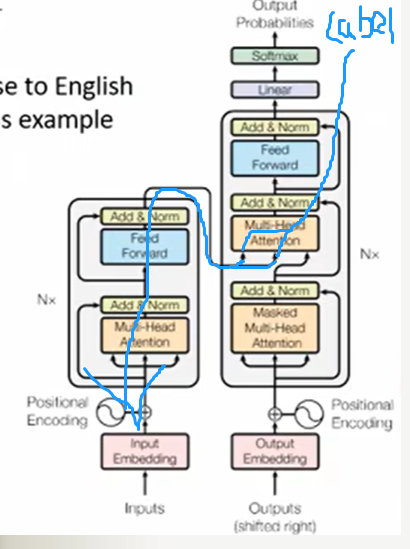 沿着蓝色线路反向更新
沿着蓝色线路反向更新
5 一些技巧
1)copy机制
2)guide
3)对结果 beam search
三 详解self-attention
背景:
序列模型 -> 文字声音graph可以处理为vec序列 -》对于多vec输入情况不能输出
比如:词性标注,舆情分析。
1 词性标注
sequence:I saw a saw.
第一个saw为看见为 V动词, 第二个saw为锯子为N名词。
传统做法对于同一个词的不同词性标注,存在问题。
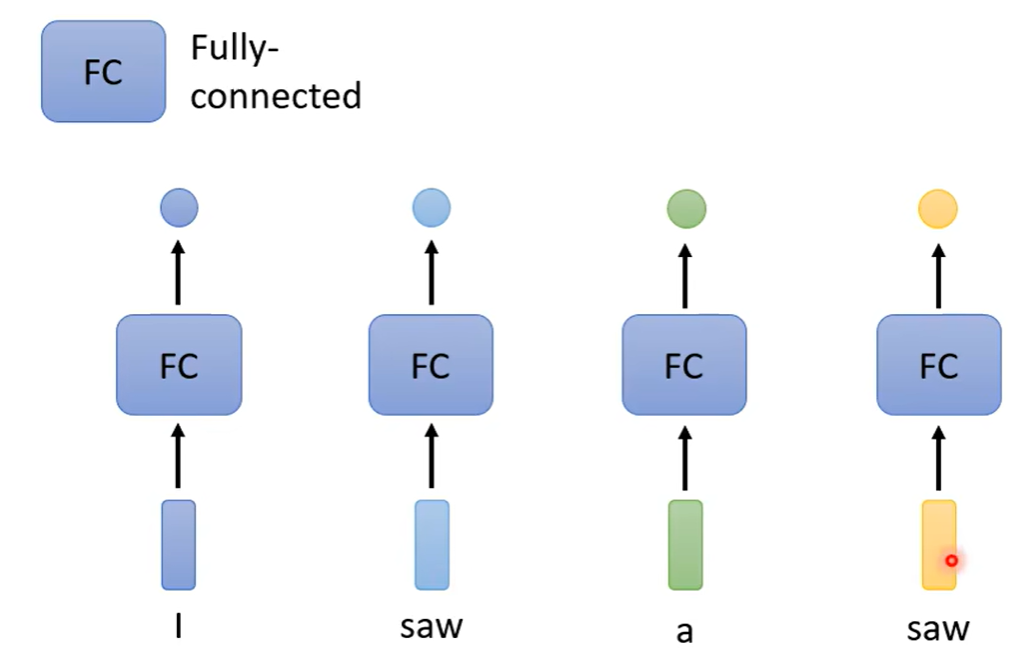
2 解决办法
2.1 使用窗口某一个词的前后各5个词,即可关联它的词性。
但是训练时每个语料序列的长度不等,只能选最长的序列,然后填充其余短的, 这样的训练不容易训练。
2.2 引出self-attention层
类似cnn层,有单层结构,同样可以组合若干层。
结构为
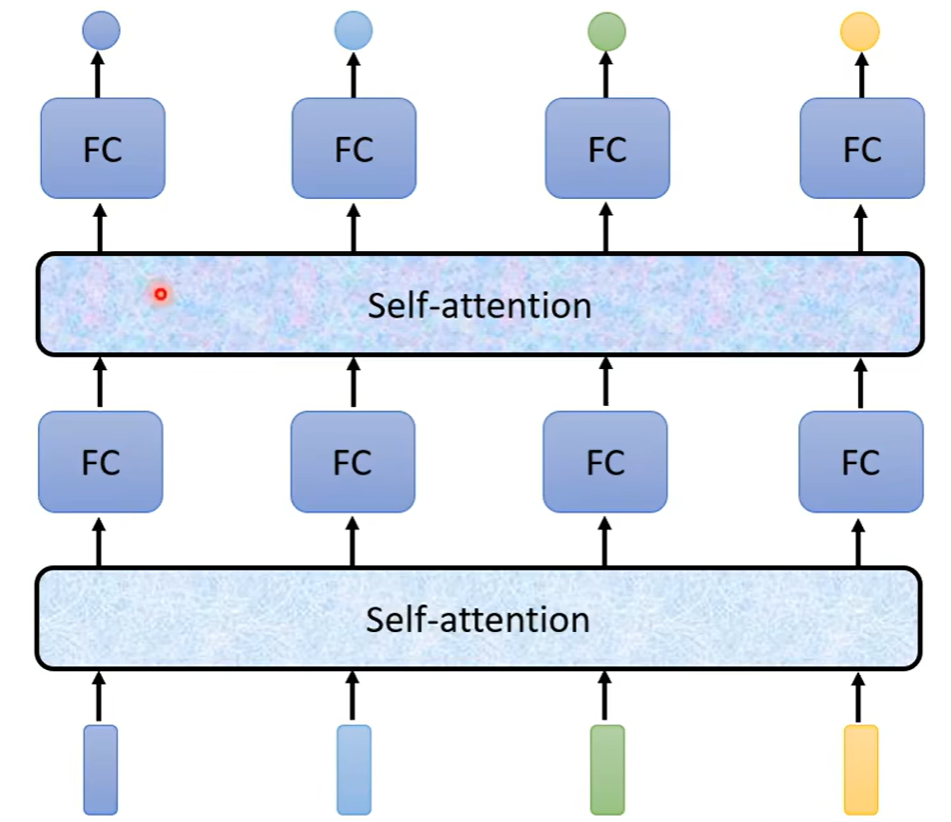
具体结构:
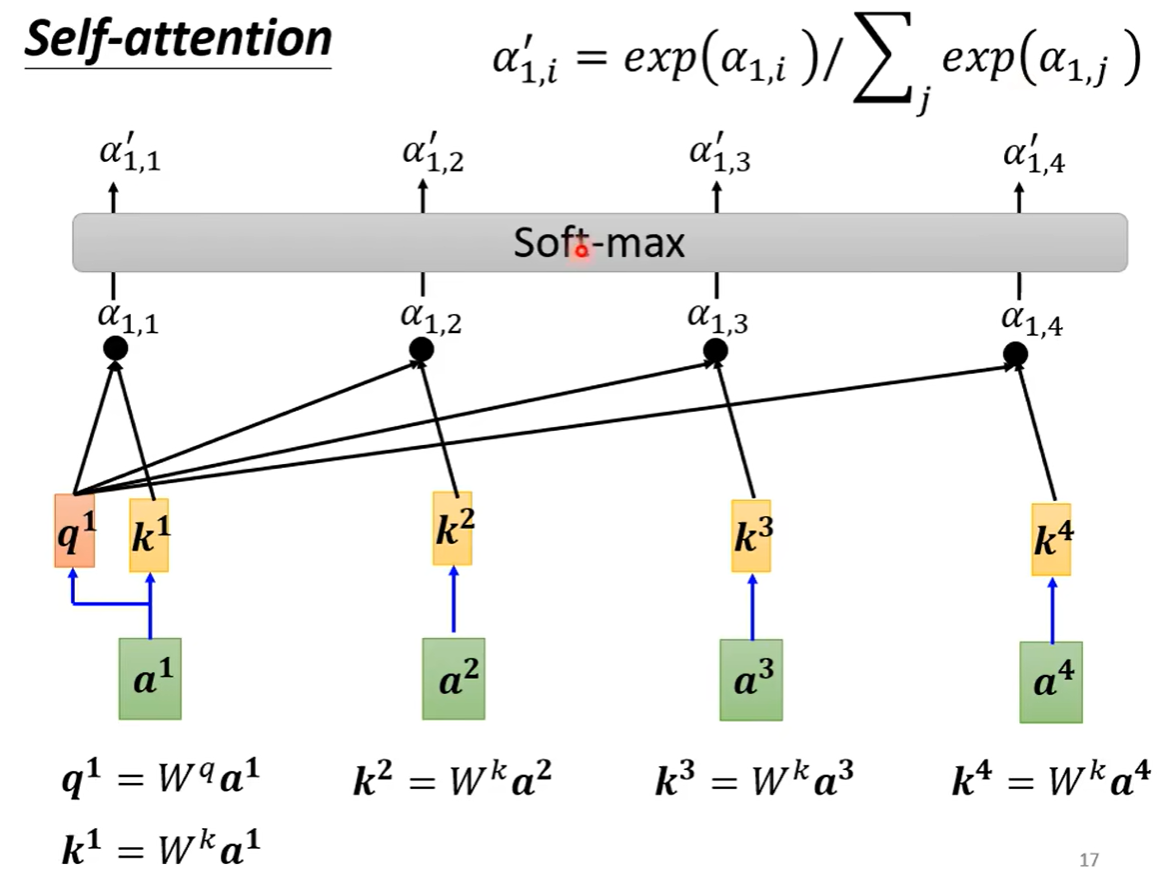
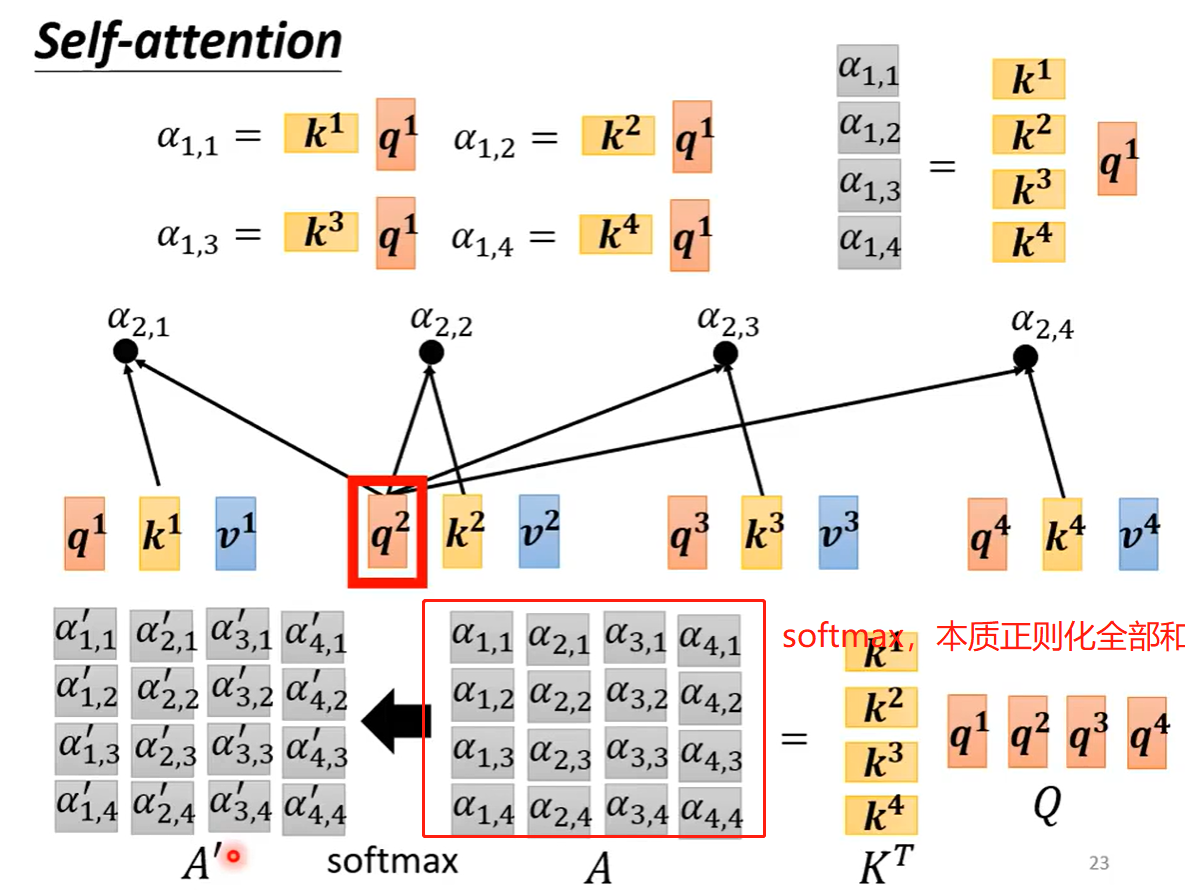
其中q1与k1,qn与qn相乘后,有些公式会除以根号d(维度),相当于正则。
α1,1 撇,是qn与qn相乘结果的softmax值。
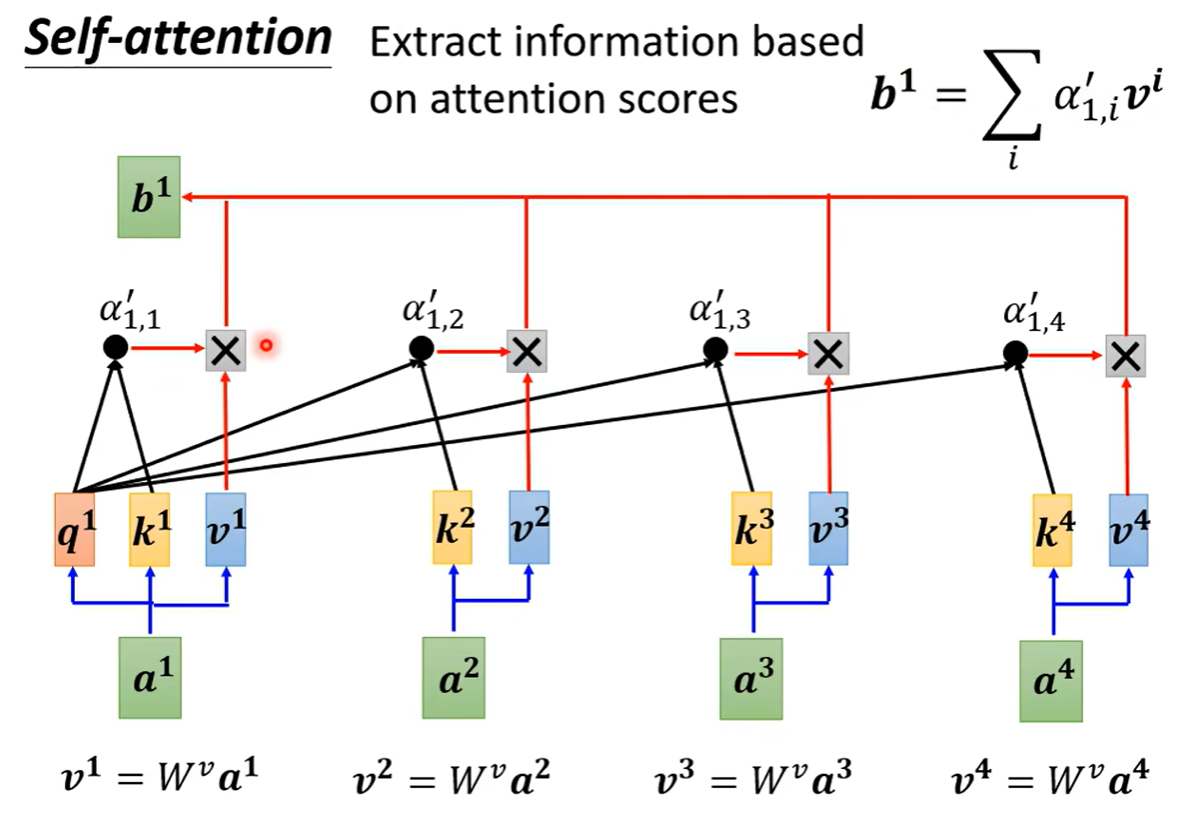
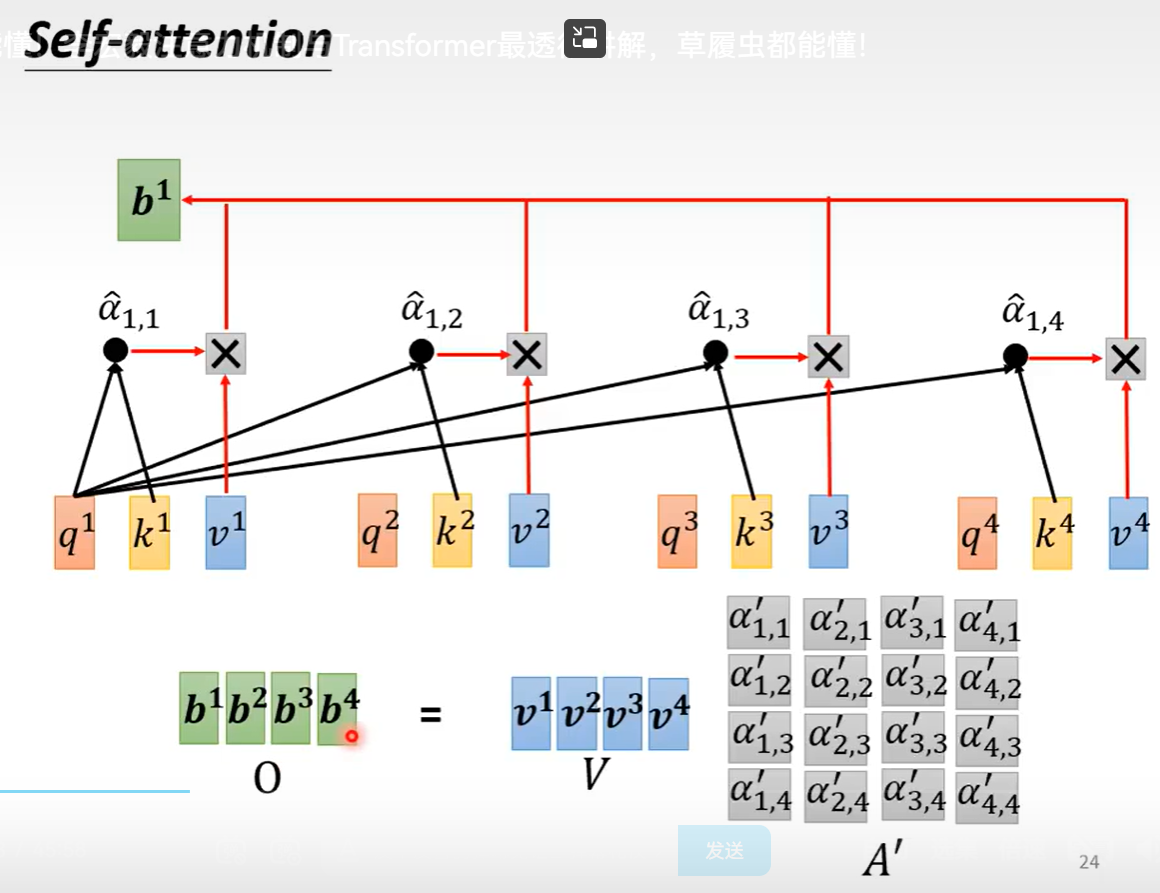
最后训练的结果b1 会最接近a1 与an的相关度与价值。
而且可以并行计算出b1,bn
数学公式为:

3 代码
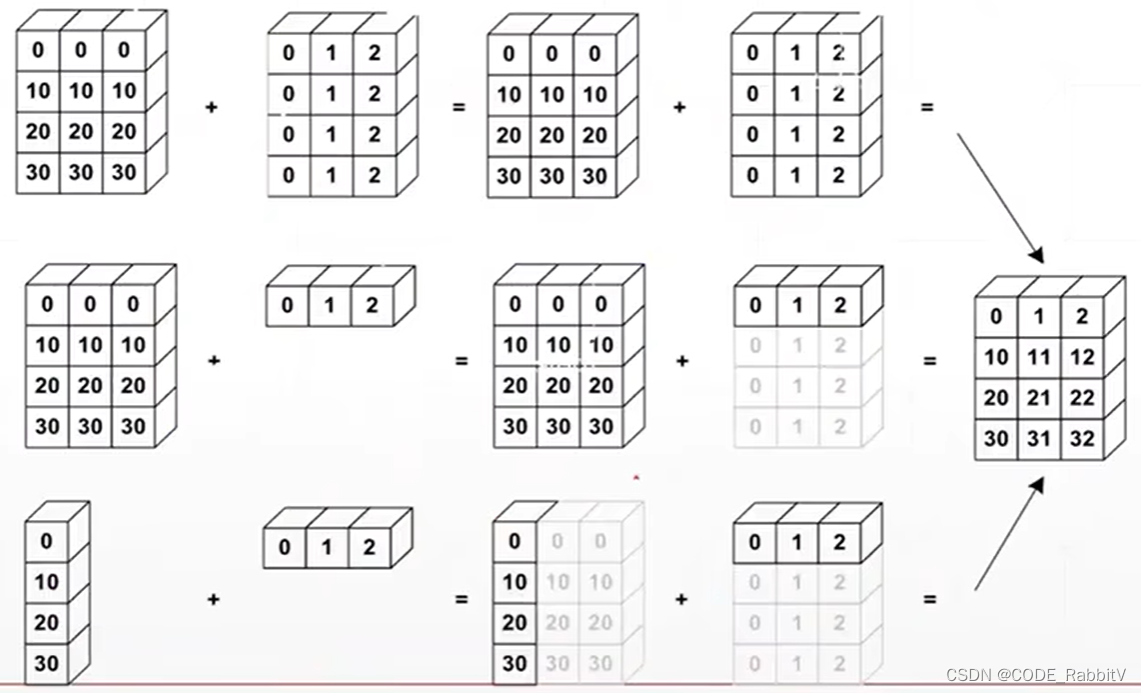
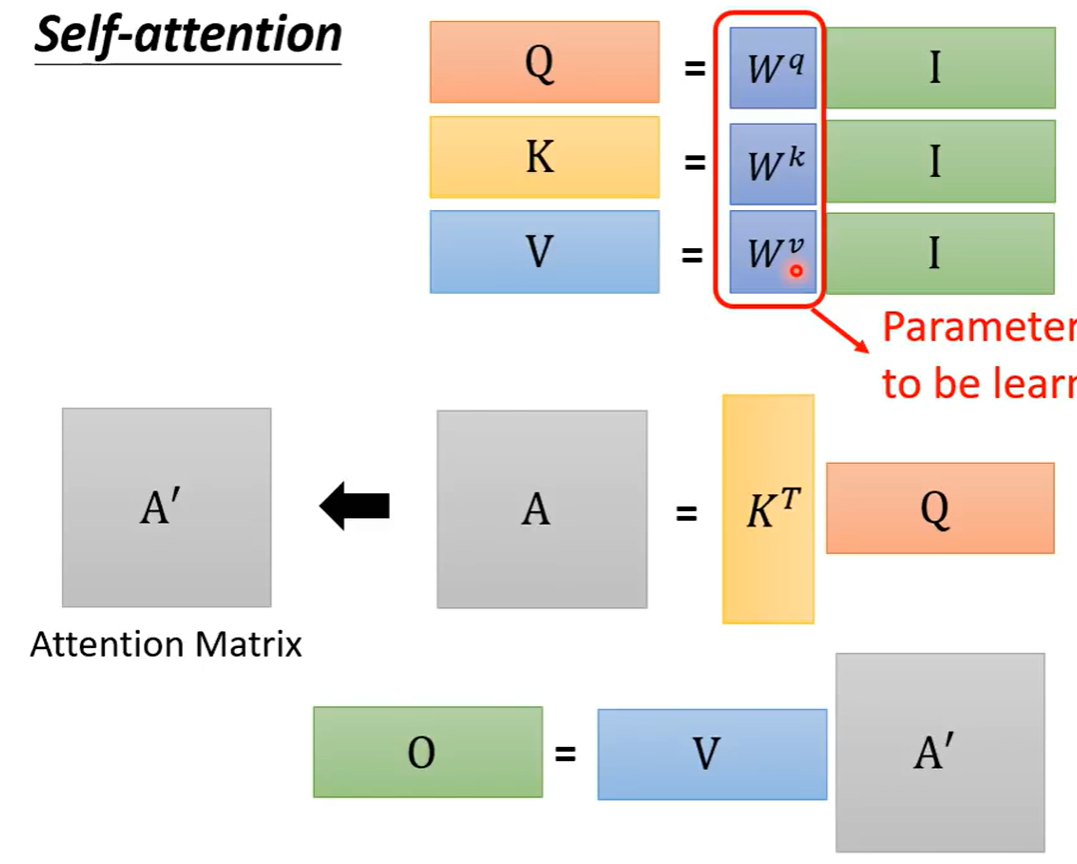
4 矩阵的计算过程
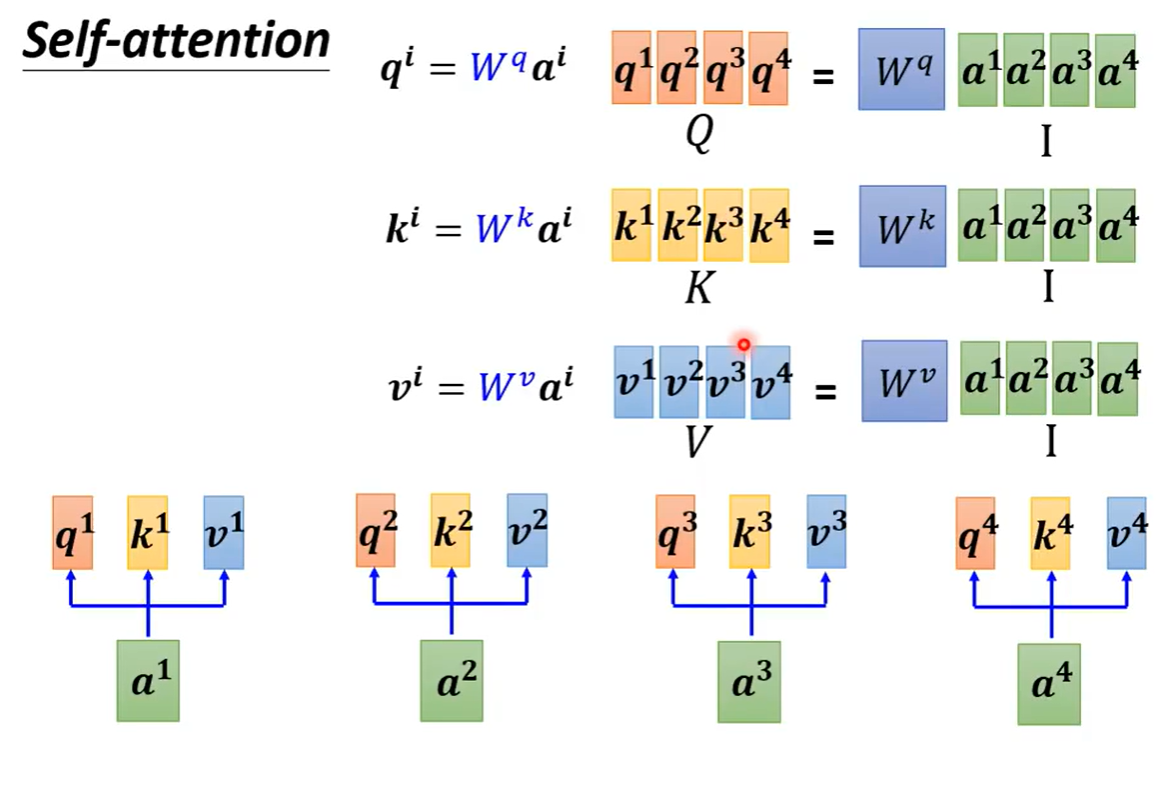
5 多头注意力机制
即每个向量,对应多个qkv
抽取多个不同维度的相关性。
6 小结
self-attention中学到什么?
Wq,Wk,Wv,
学的好,即当前layer层能生成的sequnce表征更多词关系,及含义的,及语义理解上的特征。
7 position embed
位置编码,为了让注意力抽取特征的同时,也关注每个词的位置信息。
这里值得研究, 有很多种位置编码。
8 attention对比CNN与RNN
对比CNN, 更全面感知野的CNN
对比RNN, 1 不会信息消失, 每个词的相关性都会在attention中计算 2 可以并行计算效率更高
9 加速transformers 更多变种
因为attention机制可以加速,所以出现了很多transformer的变种。
值得去研究
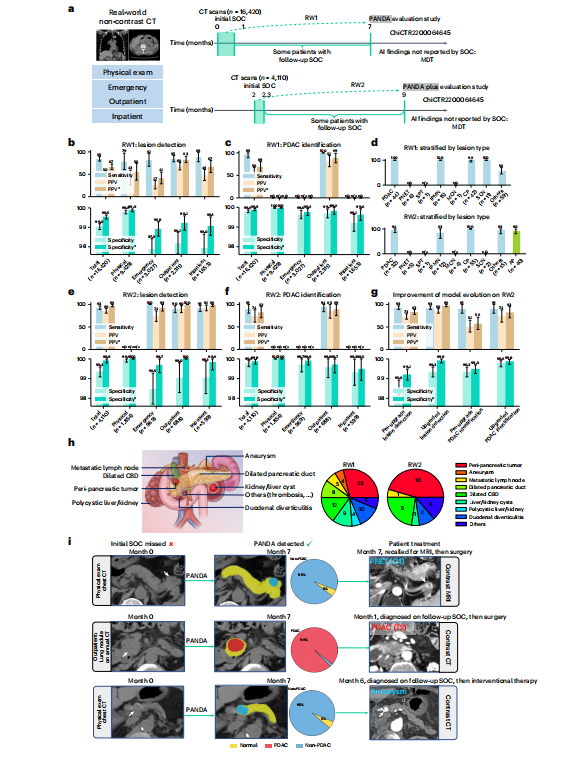
四 GPT 仅用decoder
1 past-key_val=true 保存过程
截图为decoder的单层结构图,也是GPT的简化图。 12x即重复12层block。
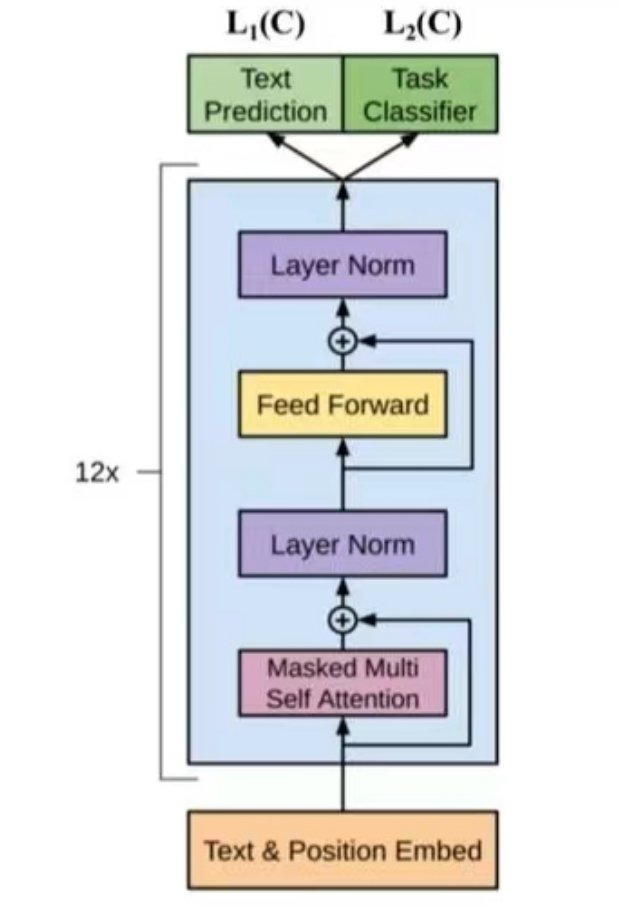
GPT全部是decoder block 也是会计算key val所以也可以保存起来, 那么每一层得 key-val都是新的,所以实际是保存了12组 key-val。 (从代码中读到, 可以再次确认):已确认实际 是保存了12组
动画:encoder+decoder
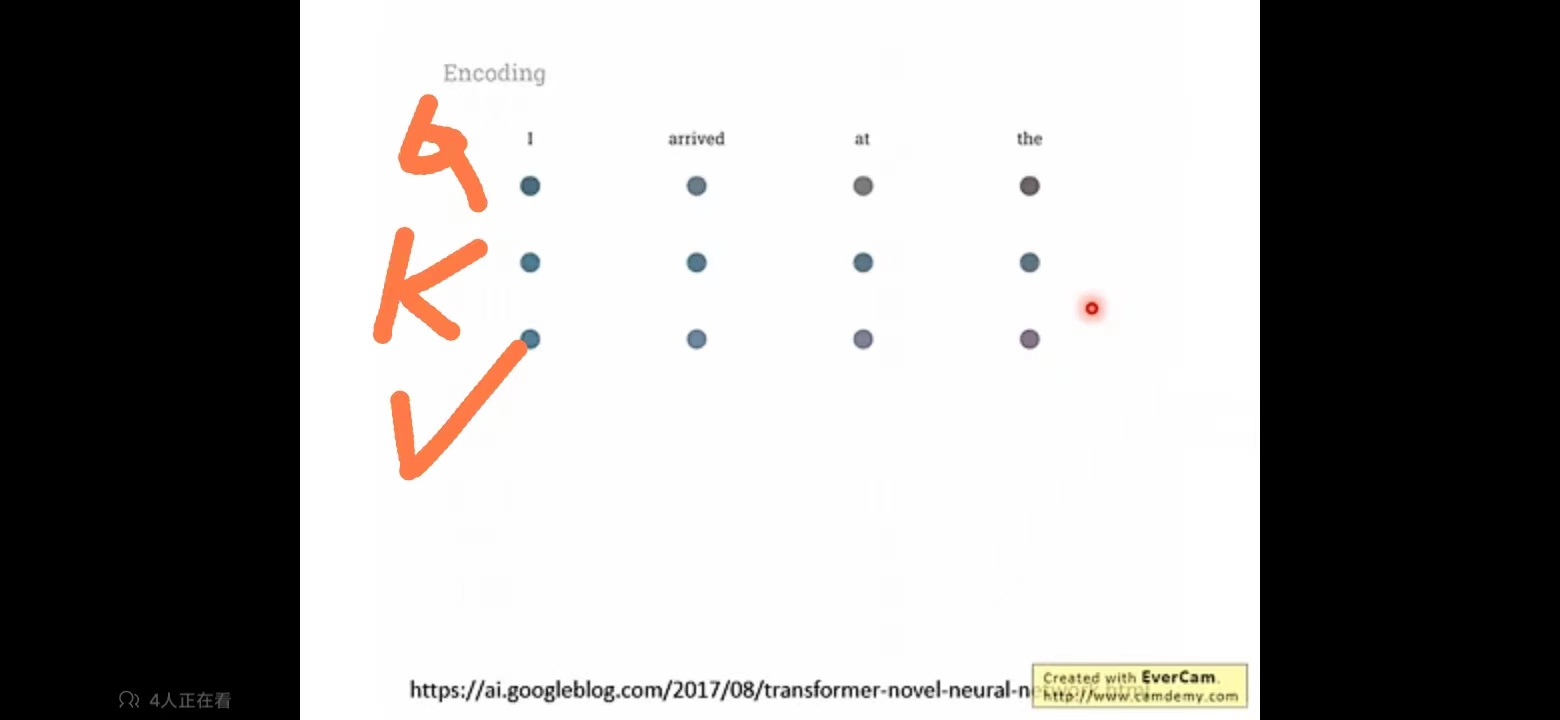
实际这三个为一层encoder。 qkv如图,三行在同一层里。
2 为什么 decoder可以自己计算key和val呢?
FAQ:
1 BOS在推理和训练时
都是谁给的输入, 是自动的吗?
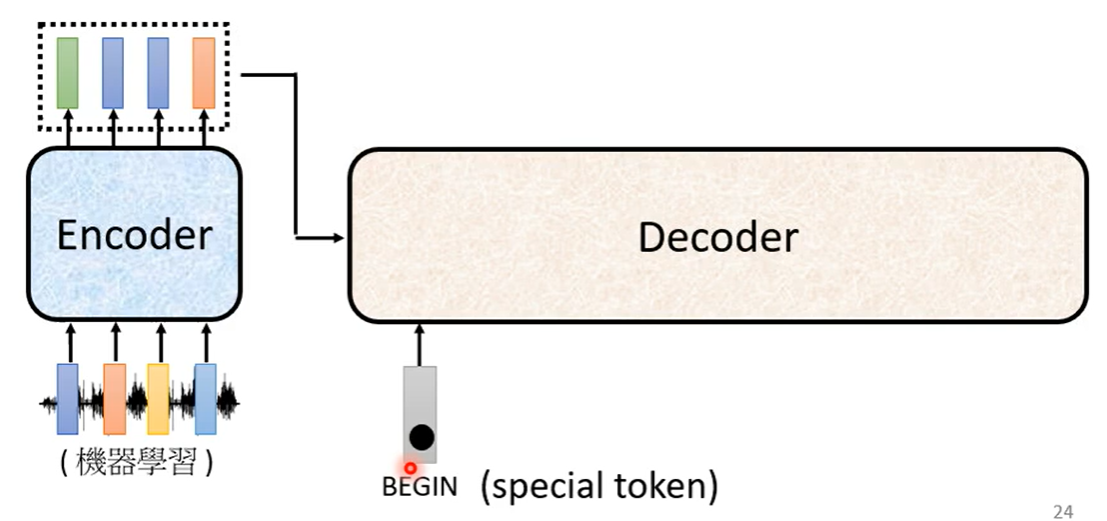
2 在GPT2中没有encoder部分,那么怎么计算的key和val呢,
训练GPT2的时候, 怎么把输入数据传给 decoder呢
经过embedding 得到词向量-> decoder, 那么teacherforcing的 grandtruth 还传入吗?
3 attention_mask
训练时候也是遮挡未推理部分吗?
-是的
程序中怎么设定attention_mask逐个遮掩?
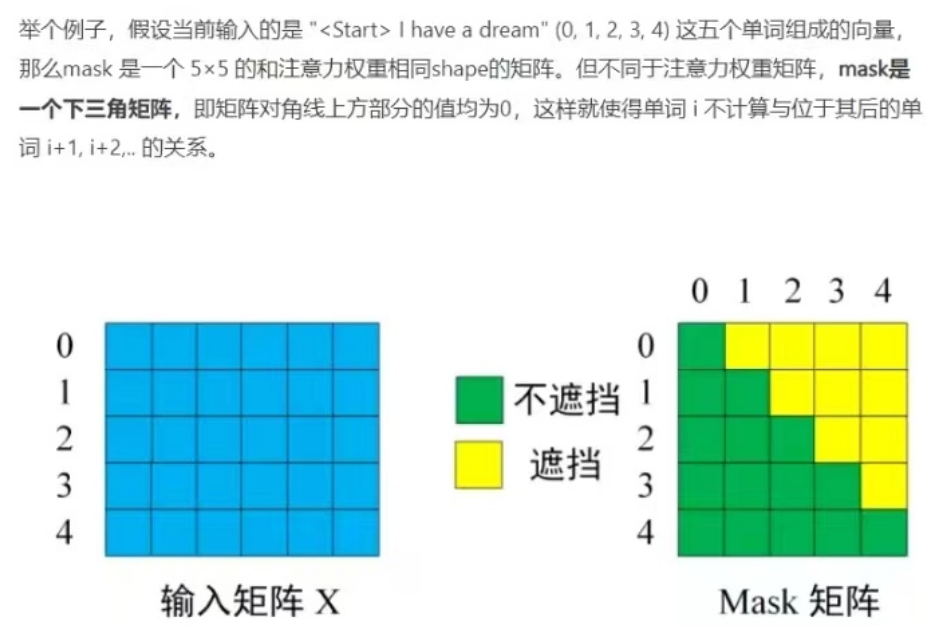
训练时前向推理,每次输入就是一个token了吧 为什么还需要attention_mask呢?
截图是推理任务时的运转图
4 NAT
no autoregression train
对比autoregression
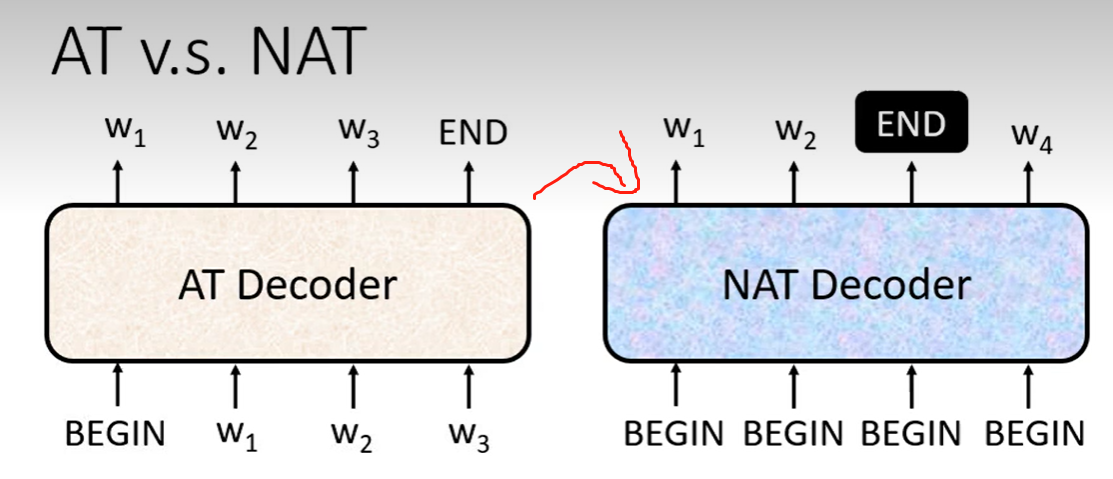
1)可以并行推理 2)长度可控
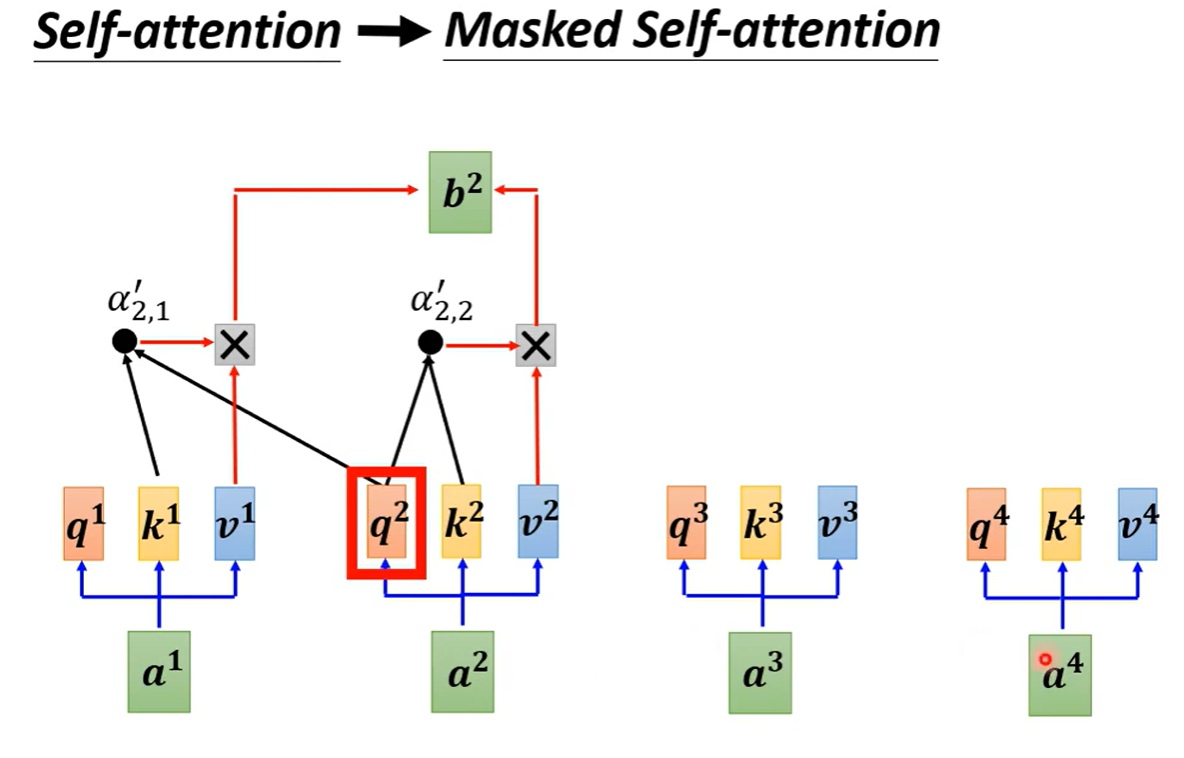
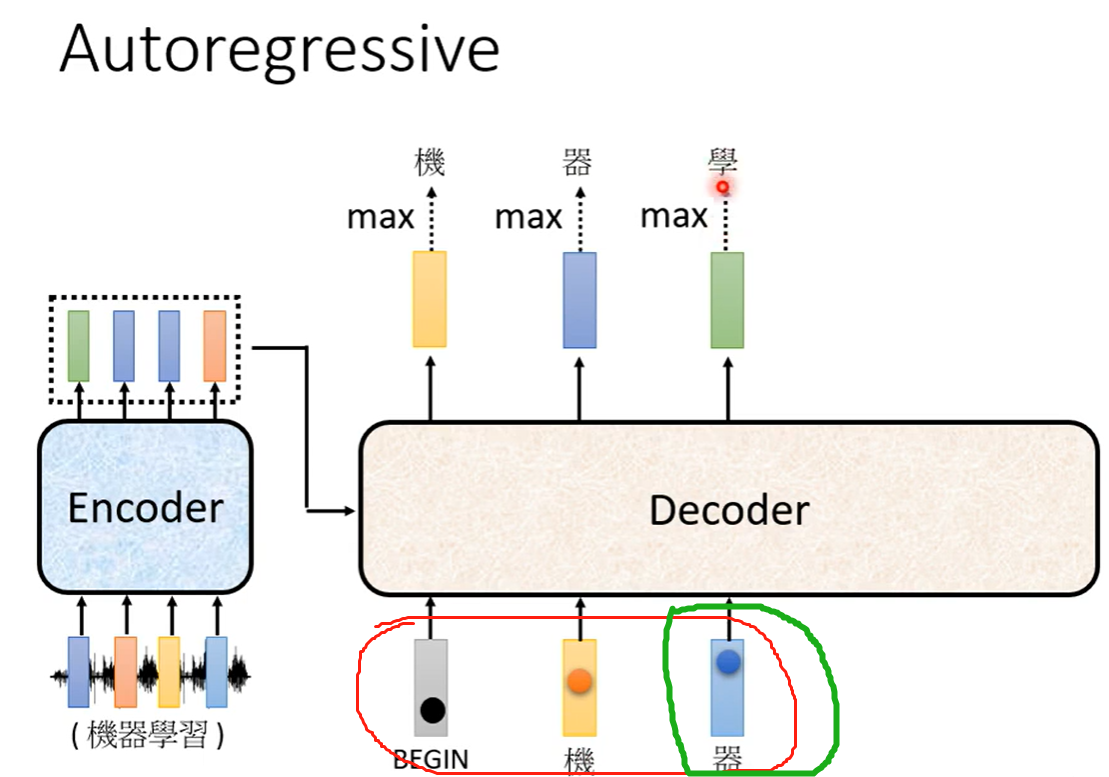
5 训练时候decoder的输入是带有推理历史还是只有当前的一个token?

推理出来 学 的时候,需要接收的输入是 红圈的所有内容还是只是 绿圈的内容?
6 推理任务时候decoder的输入 是带有推理历史还是只有当前的一个token?
7 什么时候只要输入绿色圈的一个token内容?
即 past_key_val?, 那么输入一个token时候,还需要attention_mask吗?
8 对于定长的输入,比如定长50,我得query只有5个token,比如 你多大了?,程序会填充45个padding。
相比于我的query是 50个token全占满, 请问老师哪个forward计算性能更快。,还是差不多。
我的理解是 填充45个padding,的向量,走到attention_mask的时候, 被变为0000-45个0,5个1,最后计算就是那5个数值,是否forward计算会更快。
老师也不确定, 但是可以确定,添加pad的,参与0计算,应该会快一点。
这可以走读代码了解到。
9 输入不定长的原理是什么?
为什么不限定长度 query,都能被embed层接收?
从代码可以看到
比如ChatGLM,你可以看下这里:https://github.com/THUDM/ChatGLM-6B/blob/c26a7de24de1cad5512a50611f39a9cea7eb436f/ptuning/main.py#L176
未能解决问题。 尝试自己读源码实现。
C:\\Users\\xialiu05\\AppData\\Local\\Programs\\Python\\Python310\\Lib\\site-packages\\transformers\\generation\\utils.py
此时的输入还是 tensor(\[\[ 1, 2214, 2172, 4381, 12253, 1518, 2, 2\]\])
def sample(
{'input\_ids': tensor(\[\[ 1, 2214, 2172, 4381, 12253, 1518, 2, 2\]\]), 'past\_key\_values': None, 'use\_cache': True, 'attention\_mask': tensor(\[\[1, 1, 1, 1, 1, 1, 1, 1\]\])}
outputs = self(
C:\\Users\\xialiu05\\AppData\\Local\\Programs\\Python\\Python310\\Lib\\site-packages\\transformers\\models\\bloom\\modeling\_bloom.py
transformer\_outputs = self.transformer(
state: tensor(\[\[ 1, 2214, 2172, 4381, 12253, 1518, 2, 2\]\])
C:\\Users\\xialiu05\\AppData\\Local\\Programs\\Python\\Python310\\Lib\\site-packages\\transformers\\models\\bloom\\modeling\_bloom.py
class BloomModel(BloomPreTrainedModel):
forward -input\_ids (1,8)
inputs\_embeds
self.word\_embeddings = nn.Embedding(config.vocab\_size, self.embed\_dim) - vob num, dim = (46145, 2048)
hidden\_states = self.word\_embeddings\_layernorm(inputs\_embeds) (inputs\_embeds) = (1,8,2048)
原理为C:\Users\xialiu05\AppData\Local\Programs\Python\Python310\Lib\site-packages\torch\nn\modules\sparse.py
class Embedding:
介绍描述
1 no padinx
inputs =1,8 其中数值均为索引
embed = (46145, 2048)第一个数值为词表大小, 2048为 词向量的维度。
1)先对应词表查到 索引的向量
2)变为1 8 2048, 即每个向量都是2048维
3)后面网络结构输入为2048维, 这样就可以矩阵计算。
padding 为50维 在这一步基本计算性能差异不大,因为都是索引。
在后面的矩阵计算 是否因为attention 原因会有差异, 有待验证。
2 padinx
最后的最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

五、面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】