前言:在信息爆炸的时代,我们每天都沉浸在海量的数据和信息中。随着互联网技术的飞速发展,如何从这些信息中准确、高效地提取出有用的知识,成为了当下研究的热点。其中,上下位关系(也称为层级关系或种属关系)是知识图谱、自然语言处理和语义网等领域中的一个核心概念。它描述的是实体之间的层级关系,比如“狗是动物的一种”,“橡树是树的一种”等。这种关系不仅有助于我们更好地理解和组织信息,还能为智能问答、推荐系统、语义搜索等应用提供强大的支持。
本文所涉及所有资源均在传知代码平台可获取
目录
概述
演示效果
核心代码
写在最后
概述
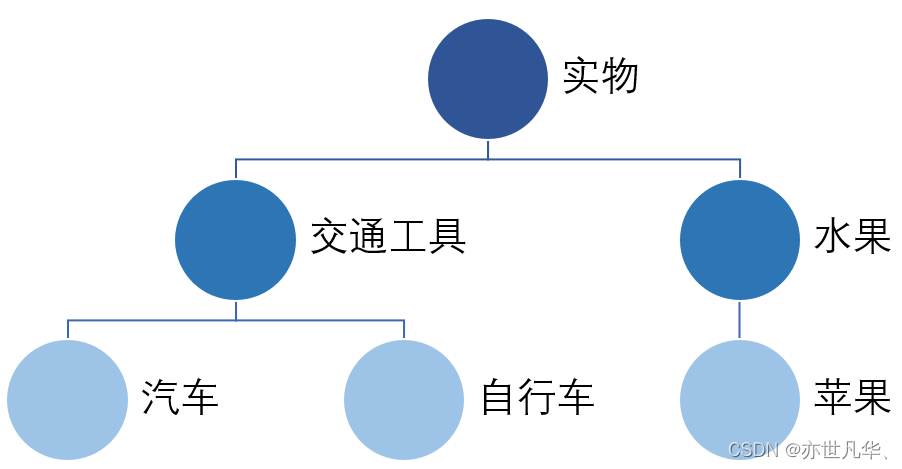
在自然语言的处理过程中,上下位关系(Is-a Relationship)是用来描述概念(也被称为术语)间的语义涵盖关系。在这里,上位词(Hypernym)代表了下位词(Hyponym)的抽象和泛化,而下位词则是对上位词的具体化和特定性。以“水果”为例,它与“苹果”、“香蕉”、“橙子”等词是同义的,而“汽车”、“电动车”、“自行车”等词则与“交通工具”相对应。在处理自然语言的任务时,深入理解概念间的层级关系对于执行如词义消歧、信息检索、自动问答和语义推理等任务都是至关重要的:
本文复现 论文,提出的文本中上位词检测方法,具体如下:
文本中上位词检测方法,即从文本中提取出互为上下位关系的概念。现有的无监督上位词检测方法大致可以分为两类——基于模式的方法和基于分布模型的方法:
1)基于模式的方法:
其主要思想是利用特定的词汇-句法模式来检测文本中的上下位关系。例如,我们可以通过检测文本中是否存在句式“【词汇1】是一种【词汇2】”或“【词汇1】,例如【词汇2】”来判断【词汇1】和【词汇2】间是否存在上下位关系。这些模式可以是预定义的,也可以是通过机器学习得到的。然而,基于模式的方法存在一个众所周知的问题——极端稀疏性,即词汇必须在有限的模式中共同出现,其上下位关系才能被检测到。
2)基于分布模型的方法:
基于大型文本语料库,词汇可以被学习并表示成向量的形式。利用特定的相似度度量,我们可以区分词汇间的不同关系。
在该论文中,作者研究了基于模式的方法和基于分布模型的方法在几个上下位关系检测任务中的表现,并发现简单的基于模式的方法在常见的数据集上始终优于基于分布模型的方法。作者认为这种差异产生的原因是:基于模式的方法提供了尚不能被分布模型准确捕捉到的重要上下文约束。
作者使用如下Hearst模式来捕捉文本中的上下位关系,通过对大型语料库使用模式捕捉候选上下位词对并统计频次,可以计算任意两个词汇之间存在上下位关系的概率:
| 模板 | 例子 |
|---|---|
| XX which is a (example|class|kind…) of YY | Coffee, which is a beverage, is enjoyed worldwide. |
| XX (and|or) (any|some) other YY | Coffee and some other hot beverages are popular in the morning. |
| XX which is called YY | Coffee, which is called “java”. |
| XX is JJS (most)? YY | Coffee is the most consumed beverage worldwide. |
| XX is a special case of YY | Espresso is a special case of coffee. |
| XX is an YY that | A latte is a coffee that includes steamed milk. |
| XX is a !(member|part|given) YY | A robot is a machine. |
| !(features|properties) YY such as X1X1, X2X2, … | Beverages such as coffee, tea, and soda have various properties such as caffeine content and flavor. |
| (Unlike|like) (most|all|any|other) YY, XX | Unlike most beverages, coffee is often consumed hot. |
| YY including X1X1, X2X2, … | Beverages including coffee, tea, and hot chocolate are served at the café. |
设 p(x,y)p(x,y)是词汇 xx 和 yy 分别作为下位词和上位词出现在预定义模式集合 PP 中的频率,p−(x)p−(x)是 xx 作为任意词汇的下位词出现在预定义模式中的频率,p+(y)p+(y)是 yy 作为任意词汇的上位词出现在预定义模式中的频率。作者定义正逐点互信息(Positive Point-wise Mutual Information)作为词汇间上下位关系得分的依据:

由于模式的稀疏性,部分存在上下位关系的词对并不会出现在特定的模式中。为了解决这一问题,作者利用PPMI得分矩阵的稀疏表示来预测任意未知词对的上下位关系得分。PPMI得分矩阵定义如下:
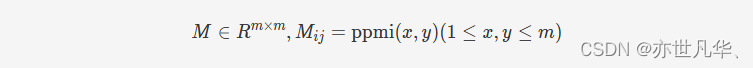
其中 m=|\{x|(x,y)\in P\or(y,x)\in P\}|,对矩阵 MM 做奇异值分解可得 M=UΣVTM=UΣVT,然后我们可以通过下式计算出上下位关系 spmi 得分,其中 uxux 和 vyvy 分别是矩阵 UU 和 VV 的第 xx 行和第 yy 行,ΣrΣr是对 ΣΣ 的 rr 截断(即除了最大的 rr 个元素其余全部置零):

演示效果
拿到代码解压附件压缩包并进入工作目录。如果是Linux系统,请使用如下命令:
unzip Revisit-Hearst-Pattern.zip
cd Revisit-Hearst-Pattern代码的运行环境可通过如下命令进行配置:
pip install -r requirements.txt
python -m spacy download en_core_web_sm
# 如果希望在本地运行程序,请运行如下命令:
python main.py
# 如果希望在线部署,请运行如下命令:
python main-flask.py如果希望添加新的模板,请修改文件data/patterns.json,
"_HYPONYM_"表示下位词占位符;
"_HYPERNYM_"表示上位词占位符;
其余格式请遵照 python.re 模块的正则表达式要求。
如果希望使用自己的文件路径或改动其他实验设置,请在文件config.json中修改对应参数。以下是参数含义对照表:
| 参数名 | 含义 |
|---|---|
| corpus_path | 文本语料库文件路径,默认为“data/corpus.txt”。 |
| patterns_path | 预定义模式库的路径。默认为“data/patterns.json”。 |
| pairs_path | 利用模式筛选出的上下位关系词对路径,默认为“data/pairs.json”。 |
| spmi_path | 上下位关系词对及其spmi得分路径,默认为“data/spmi.json”。 |
| clip | 用于对 ΣΣ 进行截断的参数 rr ,默认为10。 |
| threshold | spmi得分小于该值的词对将被舍去。默认为1。 |
| max_bytes | 输入文件大小上限(用于在线演示),默认为200kB。 |
运行脚本main.py,程序会自动检测语料库中存在的上下位关系。运行结果如下所示:
核心代码
下面这段代码实现了一个术语上下位关系提取的流程,包括文本清理、句子划分、术语抽取、共现关系抽取、SPMI 计算等步骤。
代码中的 clear_text 函数用于清理文本,例如删除交叉引用标识。split_sentences 函数用于将文本划分为句子。extract_noun_phrases 函数用于从句子中抽取名词性短语,作为候选术语。term_lemma 函数用于将术语中的名词还原为单数。find_co_occurrence 函数用于找出共现于模板的术语对。count_unique_tuple 函数用于统计列表中独特元组出现次数。find_rth_largest 函数用于找到数组中第 r 大的元素。find_pairs 函数用于读取文件并找出共现于模板的上下位关系术语对。spmi_calculate 函数用于基于对共现频率的统计,计算任意两个术语间的 spmi 得分。
在主函数中,代码首先读取配置文件和模板,然后读取语料库中共现于模板的术语对,并统计上下位关系的出现频次。接下来,代码计算任意两个术语间的 spmi 得分,并将结果输出到文件中:
import spacy
import json
from tqdm import tqdm
import re
from collections import Counter
import numpy as np
import math
nlp = spacy.load("en_core_web_sm")
def clear_text(text):
"""对文本进行清理"""
# 这里可以添加自己的清理步骤
# 删去交叉引用标识,例如"[1]"
pattern = r'\[\d+\]'
result = re.sub(pattern, '', text)
return result
def split_sentences(text):
"""将文本划分为句子"""
doc = nlp(text)
sentences = [sent.text.strip() for sent in doc.sents]
return sentences
def extract_noun_phrases(text):
"""从文本中抽取出术语"""
doc = nlp(text)
terms = []
# 遍历句子中的名词性短语(例如a type of robot)
for chunk in doc.noun_chunks:
term_parts = []
for token in list(chunk)[-1::]:
# 以非名词且非形容词,或是代词的词语为界,保留右半部分(例如robot)
if token.pos_ in ['NOUN', 'ADJ'] and token.dep_ != 'PRON':
term_parts.append(token.text)
else:
break
if term_parts != []:
term = ' '.join(term_parts)
terms.append(term)
return terms
def term_lemma(term):
"""将术语中的名词还原为单数"""
lemma = []
doc = nlp(term)
for token in doc:
if token.pos_ == 'NOUN':
lemma.append(token.lemma_)
else:
lemma.append(token.text)
return ' '.join(lemma)
def find_co_occurrence(sentence, terms, patterns):
"""找出共现于模板的术语对"""
pairs = []
# 两两之间匹配
for hyponym in terms:
for hypernym in terms:
if hyponym == hypernym:
continue
for pattern in patterns:
# 将模板中的占位符替换成候选上下位词
pattern = pattern.replace('__HYPONYM__', re.escape(hyponym))
pattern = pattern.replace('__HYPERNYM__', re.escape(hypernym))
# 在句子中匹配
if re.search(pattern, sentence) != None:
# 将名词复数还原为单数
pairs.append((term_lemma(hyponym), term_lemma(hypernym)))
return pairs
def count_unique_tuple(tuple_list):
"""统计列表中独特元组出现次数"""
counter = Counter(tuple_list)
result = [{"tuple": unique, "count": count} for unique, count in counter.items()]
return result
def find_rth_largest(arr, r):
"""找到第r大的元素"""
rth_largest_index = np.argpartition(arr, -r)[-r]
return arr[rth_largest_index]
def find_pairs(corpus_file, patterns, disable_tqdm=False):
"""读取文件并找出共现于模板的上下位关系术语对"""
pairs = []
# 按行读取语料库
lines = corpus_file.readlines()
for line in tqdm(lines, desc="Finding pairs", ascii=" 123456789#", disable=disable_tqdm):
# 删去首尾部分的空白字符
line = line.strip()
# 忽略空白行
if line == '':
continue
# 清理文本
line = clear_text(line)
# 按句处理
sentences = split_sentences(line)
for sentence in sentences:
# 抽取出句子中的名词性短语并分割成术语
candidates_terms = extract_noun_phrases(sentence)
# 找出共现于模板的术语对
pairs = pairs + find_co_occurrence(sentence, candidates_terms, patterns)
return pairs
def spmi_calculate(configs, unique_pairs):
"""基于对共现频率的统计,计算任意两个术语间的spmi得分"""
# 计算每个术语分别作为上下位词的出现频次
terms = list(set([pair["tuple"][0] for pair in unique_pairs] + [pair["tuple"][1] for pair in unique_pairs]))
term_count = {term: {'hyponym_count': 0, 'hypernym_count': 0} for term in terms}
all_count = 0
for pair in unique_pairs:
term_count[pair["tuple"][0]]['hyponym_count'] += pair["count"]
term_count[pair["tuple"][1]]['hypernym_count'] += pair["count"]
all_count += pair["count"]
# 计算PPMI矩阵
ppmi_matrix = np.zeros((len(terms), len(terms)), dtype=np.float32)
for pair in unique_pairs:
hyponym = pair["tuple"][0]
hyponym_id = terms.index(hyponym)
hypernym = pair["tuple"][1]
hypernym_id = terms.index(hypernym)
ppmi = (pair["count"] * all_count) / (term_count[hyponym]['hyponym_count'] * term_count[hypernym]['hypernym_count'])
ppmi = max(0, math.log(ppmi))
ppmi_matrix[hyponym_id, hypernym_id] = ppmi
# 对PPMI进行奇异值分解并截断
r = configs['clip']
U, S, Vt = np.linalg.svd(ppmi_matrix)
S[S < find_rth_largest(S, r)] = 0
S_r = np.diag(S)
# 计算任意两个术语间的spmi
paris2spmi = []
for hyponym_id in range(len(terms)):
for hypernym_id in range(len(terms)):
# 同一个术语间不计算得分
if hyponym_id == hypernym_id:
continue
spmi = np.dot(np.dot(U[hyponym_id , :], S_r), Vt[:, hypernym_id]).item()
# 保留得分大于阈值的术语对
if spmi > configs["threshold"]:
hyponym = terms[hyponym_id]
hypernym = terms[hypernym_id]
paris2spmi.append({"hyponym": hyponym, "hypernym": hypernym, "spmi": spmi})
# 按spmi从大到小排序
paris2spmi = sorted(paris2spmi, key=lambda x: x["spmi"], reverse=True)
return paris2spmi
if __name__ == "__main__":
# 读取配置文件
with open('config.json', 'r') as config_file:
configs = json.load(config_file)
# 读取模板
with open(configs['patterns_path'], 'r') as patterns_file:
patterns = json.load(patterns_file)
# 语料库中共现于模板的术语对
with open(configs['corpus_path'], 'r', encoding='utf-8') as corpus_file:
pairs = find_pairs(corpus_file, patterns)
# 统计上下位关系的出现频次
unique_pairs = count_unique_tuple(pairs)
with open(configs["pairs_path"], 'w') as pairs_file:
json.dump(unique_pairs, pairs_file, indent=6, ensure_ascii=True)
# 计算任意两个术语间的spmi得分
paris2spmi = spmi_calculate(configs, unique_pairs)
with open(configs['spmi_path'], 'w') as spmi_file:
json.dump(paris2spmi, spmi_file, indent=6, ensure_ascii=True)写在最后
回顾我们所探讨的上下位关系自动检测方法,我们不难发现,这一领域的研究正逐步走向成熟。从最初的基于规则的方法,到如今的深度学习和神经网络模型,我们见证了技术的飞速进步和无限可能。这些方法不仅提高了检测的准确性和效率,更拓宽了我们的知识视野,让我们能够更加深入地理解世界的复杂性和多样性。
然而,正如所有科学探索一样,上下位关系自动检测也面临着诸多挑战和机遇。随着数据量的不断增长和模型复杂度的提高,我们需要更加高效和准确的算法来处理这些海量的信息。同时,我们也需要关注模型的泛化能力和鲁棒性,确保它们能够在不同的场景和领域中都能发挥出优秀的性能,随着技术的不断发展和应用场景的不断拓展,我们有理由相信,上下位关系自动检测将会迎来更加广阔的发展前景。它将不仅仅局限于自然语言处理和知识图谱等领域,更将深入到智能问答、推荐系统、语义搜索等更多领域,为我们的生活带来更加便捷和智能的体验。
详细复现过程的项目源码、数据和预训练好的模型可从该文章下方附件获取。