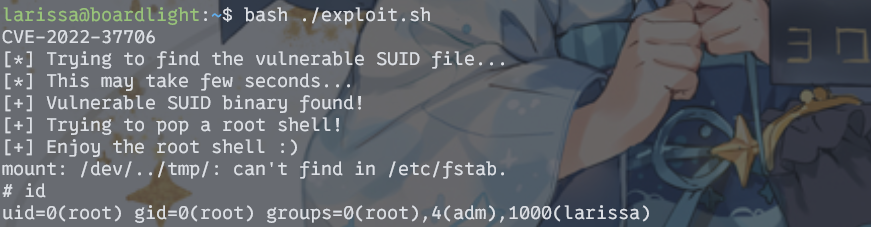
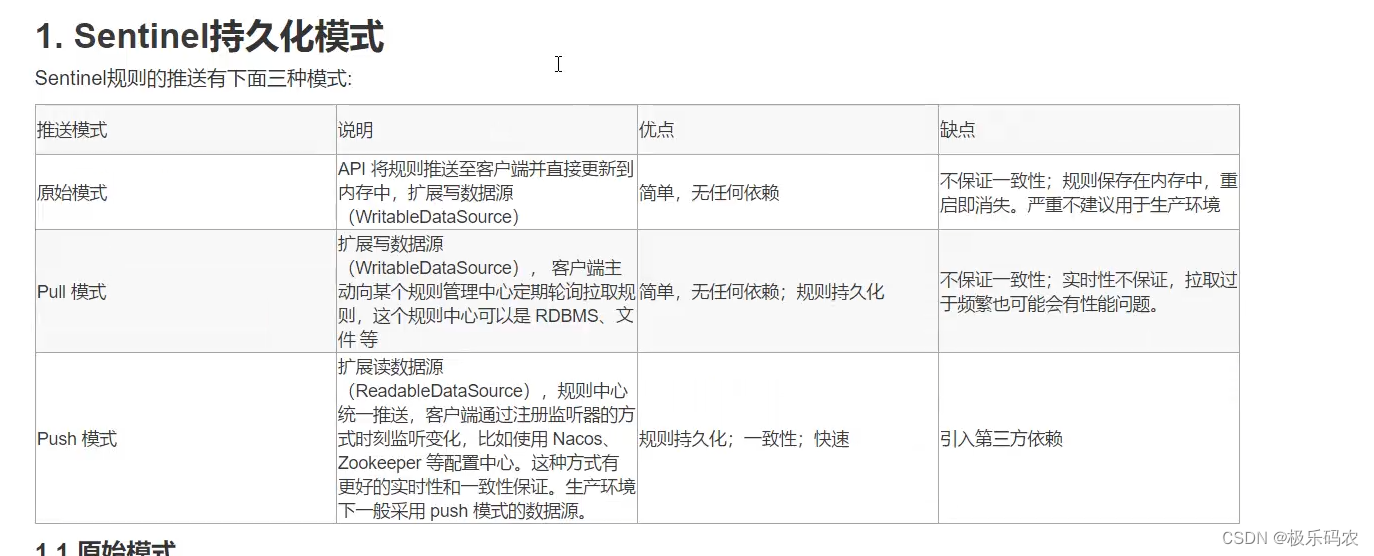
书接上回,mpTracker->GrabImageMonocular(im,timestamp)函数处理过程:
- 如果图像是彩色图,就转成灰度图
- 如果当前帧是初始化的帧,那么在构建Frame的时候,提取orb特征点数量为正常的两倍(目的就是能够在初始化的时候有更多匹配点对),如果是普通帧,就正常构建Frame。
- 接着就是调用tracking线程中的Track()函数。
- 返回当前图像帧的位姿估计结果。
上一篇文章已经讲完了构造Frame并且进行图像数据处理的过程,这篇主要解读tracking跟踪线程。
MonocularInitialization()单目初始化
step1
记录第一帧图像的关键点数量,只有关键点数量大于100才认为是有效的初始帧。
step2
记录第二帧图像的关键点数量,也是第二帧特征点数量大于100,就进行初始化。简而言之,要有连续两帧图像的特征点数量都大于100,才进行后续初始化操作
step3
构建一个ORBmatcher对象,很关键的一个对象,主要是用来搜索两帧图像之间的特征点匹配关系。
ORBmatcher matcher(
0.9, //最佳的和次佳特征点评分的比值阈值,这里是比较宽松的,跟踪时一般是0.7
true); //检查特征点的方向
然后就是通过matcher.SearchForInitialization函数找到两帧图像之间的特征点匹配关系
这个函数的步骤如下:
- 构建旋转直方图。就是通过大多数特征点的角度一致性来过滤外点。
- 遍历第一帧的所有特征点,然后根据半径窗口搜索在第二帧的所有候选匹配特征点,过程如下图所示:(图中红色的圆圈就是搜索半径)
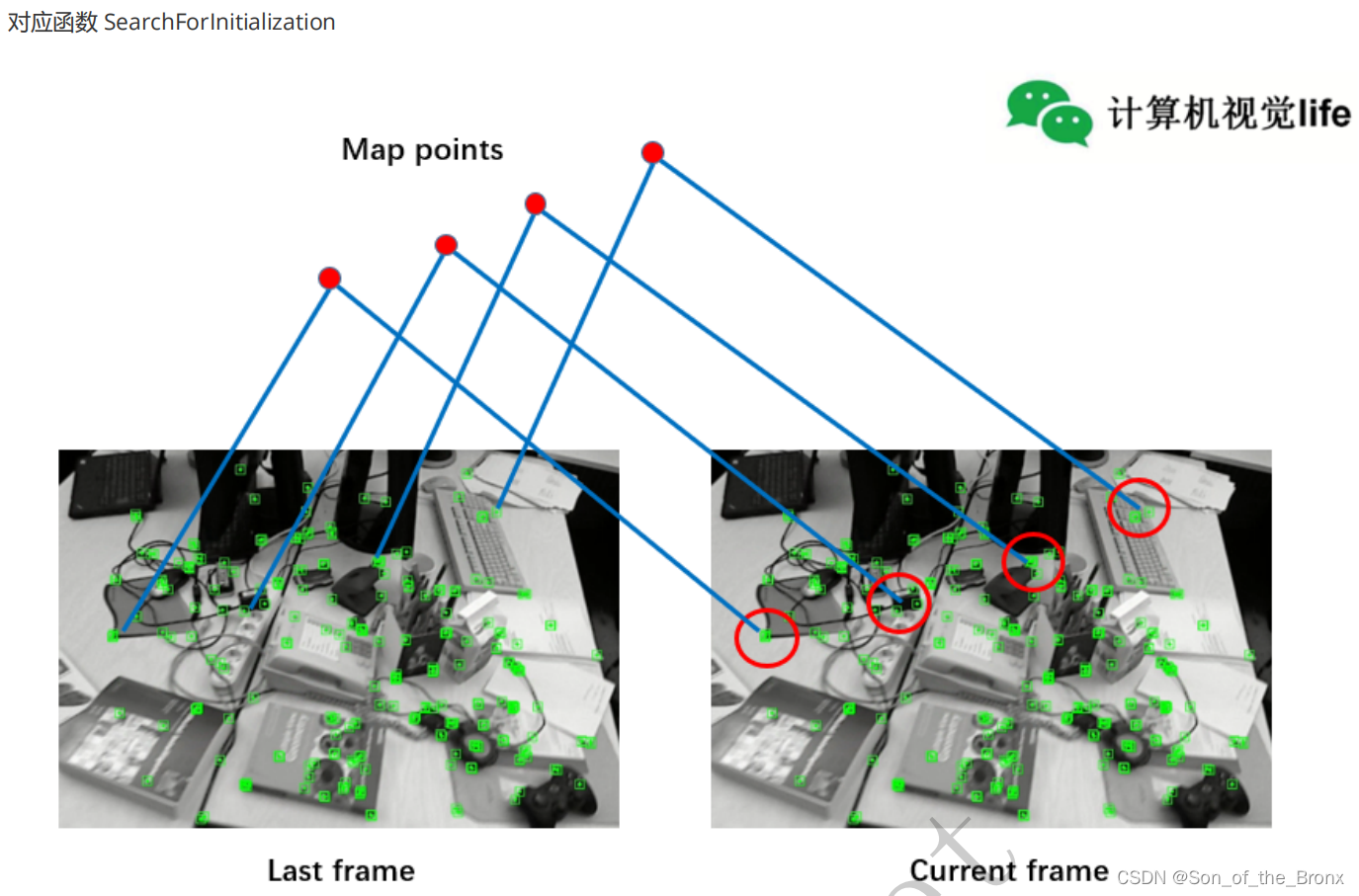
- 接着遍历步骤2中第二帧的所有候选匹配特征点,计算它们的描述子距离(因为是二进制存储,所以用的是汉明距离,即不同位数的个数),找到最优的和次优的。
- 对最优和次优的结果进行检查,当最优的距离小于阈值且最优距离小于次优距离的百分之90(比较宽松的阈值),这个是初始化ORBmatcher对象对象的参数。都通过检查后记录最佳的特征点匹配关系。
- 然后对这个特征点匹配的结果计算两个特征之间的角度差(这个角度是通过前面灰度质心法算出来的),加入到旋转直方图中。
- 结束遍历第一帧的所有特征点的大循环。筛选旋转直方图中不符合大多数旋转方向的特征点匹配关系(旋转直方图过滤)。
step4
如果第一帧和第二帧的匹配点对太少(代码中阈值是匹配点对小于100),那么就需要重新选初始化的图像帧
step5
通过本质矩阵F或者通过单应矩阵H来得到两帧图像的相对运动,得到相对运动后将平移t进行归一化(即将t的模取为1),通过这个R和t的关系,进行三角化恢复出三维地图点(这个时候单目slam系统的尺度就固定了,后续的slam尺度都是以初始化时侯的尺度为基准,尺度漂移也是在这个初始化尺度上去漂移)。
主要是通过mpInitializer->Initialize函数实现,步骤如下:
-
初始化一个用于RANSAC的二维数组,里面存的是有匹配关系的特征点索引。为了方便理解画了个简易表格去说明,最后就是在这个二维数组中用随机数去填充,类似随机选取8个点的过程。

-
为了并行计算F矩阵和H矩阵,代码中是分别开了两个线程去计算F矩阵和H矩阵。(F矩阵和H矩阵的秩和性质后续开独立的文章去说明)
计算H矩阵的过程如下步骤:
2.1.1 将当前帧和参考帧中的特征点坐标进行归一化,归一化的目的可以参考SLAM入门之视觉里程计(4):基础矩阵的估计,总的来说就是可以减少噪声的干扰,大大提升8点法的精度。(PS其实对这里的归一化没有深刻的认识,所以后续还需要学习这部分)
2.1.2 根据设定的RANSAC迭代次数(200),用对应的8个特征点计算H矩阵,其实计算H矩阵也是如视觉slam14讲上的类似,根据8对点构造出一个线性方程,然后就是用SVD分解来求解这个超定的齐次线性方程,求解的推导可以参考这篇文章:SVD在求解超定齐次线性方程组Ax=0中的应用。最优解就是 V T V^T VT的第9个奇异向量。
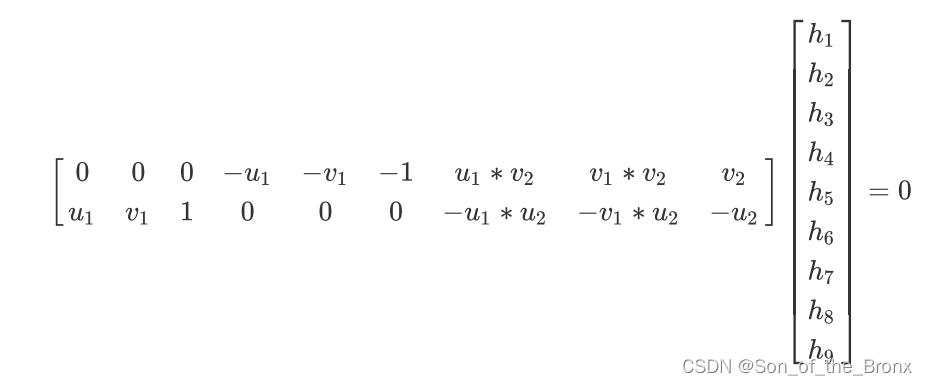
2.1.3 计算完H矩阵就利用重投影误差为当次RANSAC的结果评分,评分的规则其实就是卡方分布,因为重投影的形式与卡方分布检验的形式很像。得分的代码如下:// Step 2.3 用阈值标记离群点,内点的话累加得分 if(chiSquare1>th) bIn = false; else // 误差越大,得分越低 score += th - chiSquare1;th就是卡方分布的阈值。重投影误差有双向投影(第一帧图像往第二帧图像投影得到一个分数,第二帧图像往第一帧图像投影得到又一个分数),分数都加到score中,最终就得到这8个点构成H矩阵的得分(得分越高,误差越小)。
2.1.4 完成RANSAC迭代次数(200)后,选择得分最高的一组点计算出的H矩阵作为结果输出。
计算F矩阵的过程如下步骤:
2.2.1 一样需要将特征点归一化,跟上面计算H矩阵的一样。
2.2.2 根据设定的RANSAC迭代次数(200),用对应的8个特征点计算F矩阵。只是构建的线性方程有区别。但是求解方式都是一样的都是基于SVD分解来求解一个最优解。
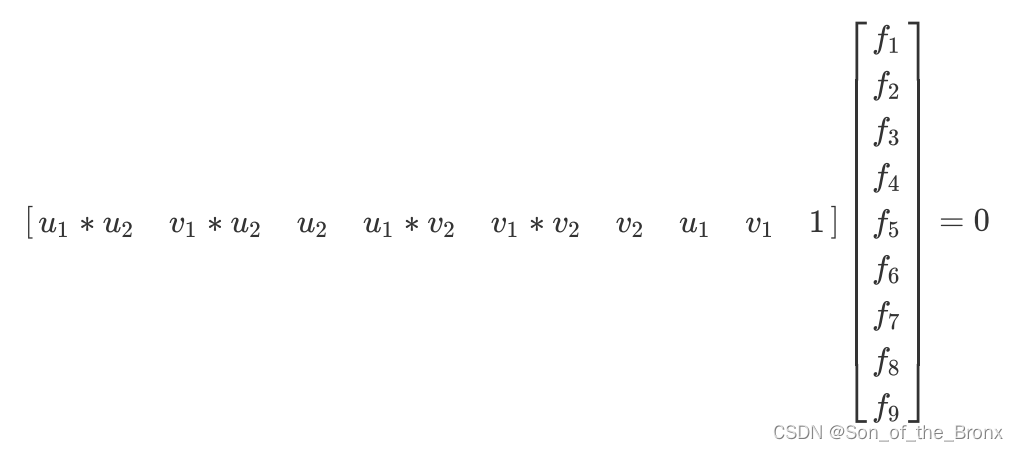
2.2.3 计算完F矩阵就利用点到直线距离(与重投影误差差不多)为当次RANSAC的结果评分,评分的规则其实就是卡方分布。
2.2.4 完成RANSAC迭代次数(200)后,选择得分最高的一组点计算出的F矩阵作为结果输出。 -
计算完H矩阵和F矩阵,根据得分情况,来选择H矩阵来恢复R,t和三角化的点。程序中更偏向用H矩阵来恢复。
通过H矩阵恢复R,t和三角化的点
程序参考的是Motion and structure from motion in a piecewise plannar environment这篇文章。
- 首先将H矩阵进行奇异值分解,得到H矩阵分解出来的8组解
- 对8组解进行验证,选择在相机前方最多3D点的解作为最优解。
- 最终最优解需要满足:
(1)最优解的3D点个数明显大于次优解的3D点
(2)视差角大于规定的阈值
(3)最优解的3D点个数大于规定的最小的被三角化的点数量
(4)最优解的3D点个数要足够多,达到总数的90%以上
通过F矩阵恢复R,t和三角化的点
过程序上面差不多,只是F矩阵恢复出来的只有四组解,所以只需要对4组解进行验证。
step6
初始化成功了,就把初始化的参考帧设置为第一个关键帧,第二帧设置为第二个关键帧。这两个关键帧都分别计算Bow(词袋后续讲解)。最后将三角化得到的三维点加入到全局地图中,为了后续pnp求解两帧图像运动。
StereoInitialization()双目或者RGBD的初始化
这个过程很简单,因为在前面预处理的时候都得到了当前图像的3D点了,只要特征点的数量大于500个,直接就以当前帧作为原点,直接把特征点对应的3D点加入到全局地图中即可。
TrackReferenceKeyFrame()。跟踪参考关键帧
这个函数的使用时机:
- 当运动模型为空,即刚刚完成初始化开始时的几帧,并没办法得到运动模型,所以只能选最近的参考关键帧来跟踪。
- 当刚刚完成重定位,也是需要依靠参考关键帧来跟踪。
step1
将当前帧的描述子转化为BoW向量。这里详细展开说一下词袋模型。
视觉词袋模型
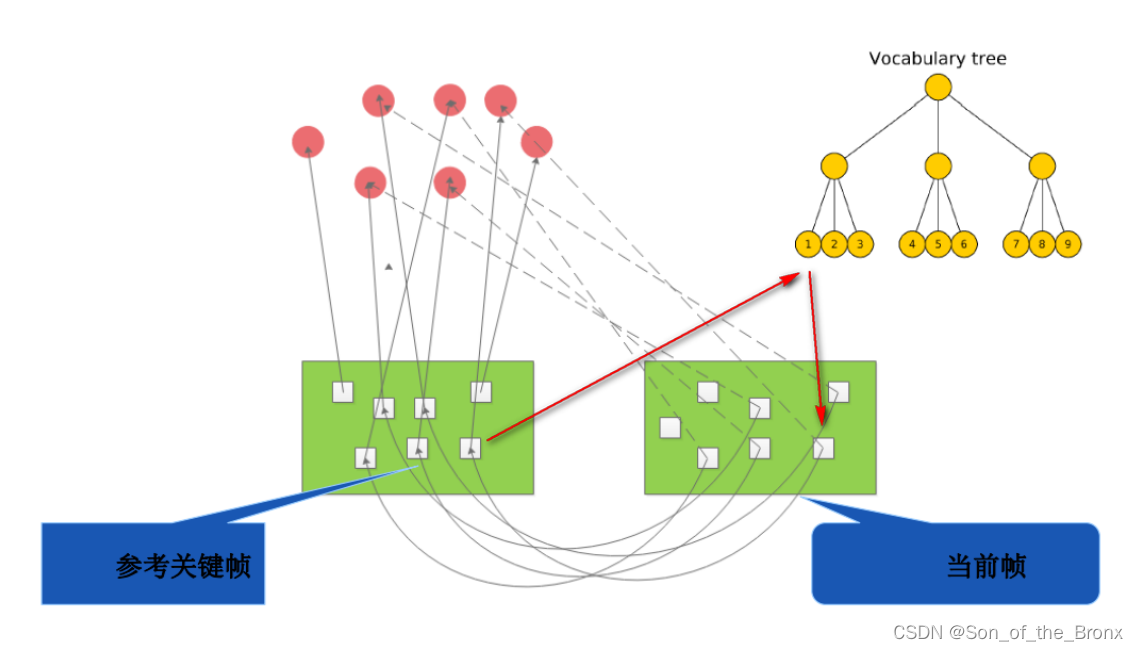
本质上词袋模型(bag of words),指的就是用“图像上有哪几种特征”来描述一幅图像。在图像上words代表着已经提取了的特征点,然后把这些words组成一个bag就可以通过这个词袋去搜索相似的图像从而构成回环。
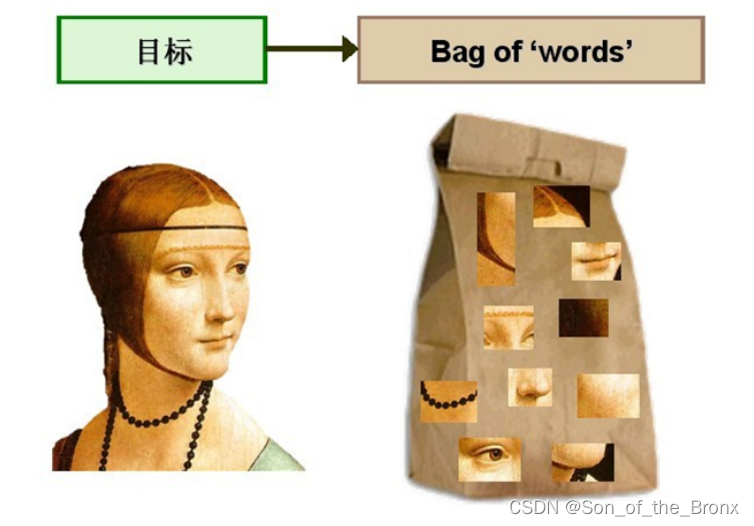
词袋模型的使用分为两个过程:
- 我们通过某种方式得到了一本字典(orbslam2通过离线训练的方式,用了很多图像,都提取了ORB特征点,将描述子通过k-means进行聚类,根据设定的树分支数和深度,从叶子节点开始聚类,一直到根节点,最后得到一个非常大的vocabulary tree)。
- 在线图像生成BoW向量。当我们在线跑SLAM的时候,就是根据当前帧的图像中提取的ORB特征点,遍历每个ORB特征点,从离线创建好的vocabulary tree中开始找自己的位置,从根节点开始,用该描述子和每个节点的描述子计算汉明距离,选择汉明距离最小的作为自己所在的节点,一直遍历到叶子节点。
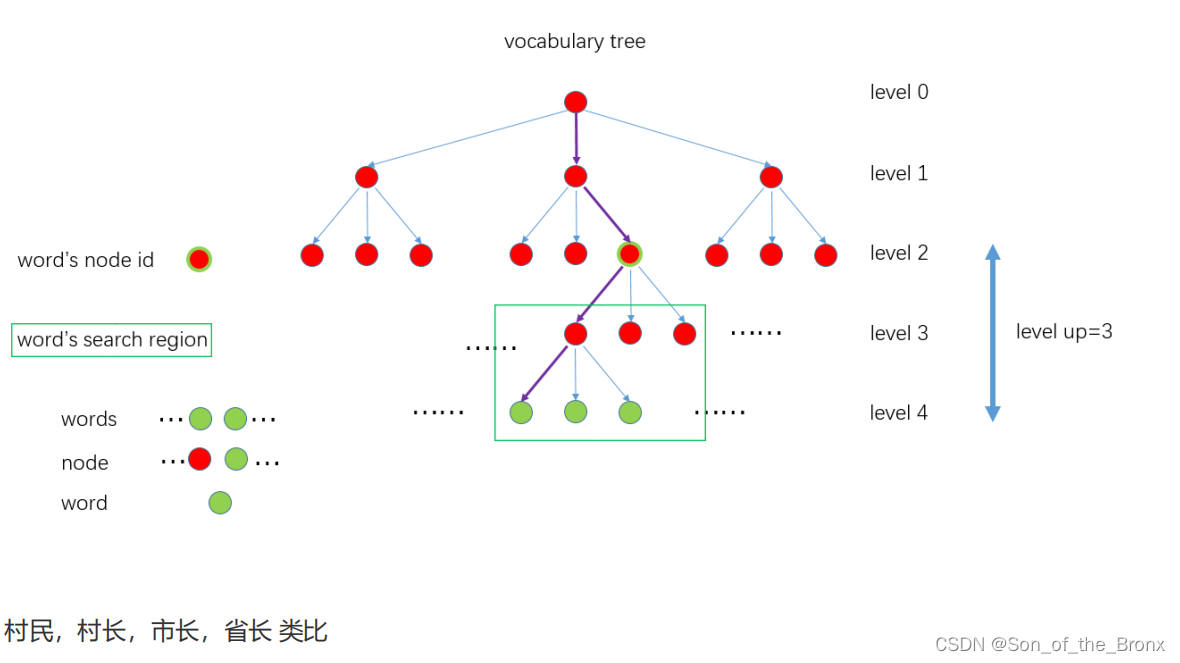
理解词袋向量BowVector
它内部实际存储的是这个std::map<WordId, WordValue>,其中 WordId 和 WordValue 表示Word在所有叶子中距离最近的叶子的id 和权重(后面解释)。同一个Word id 的权重是累加更新的。
理解特征向量FeatureVector
内部实际是个std::map<NodeId, std::vector<unsigned int>>。
- 其中NodeId 并不是该叶子节点直接的父节点id,而是距离叶子节点深度为level up对应的node 的id,对应上面 vocabulary tree 图示里的 Word’s node id。为什么不直接设置为父节点?因为后面搜索该Word 的匹配点的时候是在和它具有同样node id下面所有子节点中的Word 进行匹配,搜索区域见图示中的 Word’s search region。所以搜索范围大小是根据level up来确定的,level up 值越大,搜索范围越广,速度越慢;level up 值越小,搜索范围越小,速度越快,但能够匹配的特征就越少。
- 另外 std::vector 中实际存的是NodeId 下所有特征点在图像中的索引。FeatureVector主要用于不同图像特征点快速匹配,加速几何关系验证,比如ORBmatcher::SearchByBoW 中就是通过NodeId 来进行快速匹配。
词袋模型相似度计算
这个部分我主要参考视觉slam14将来描述。正如前面介绍的词袋向量和特征向量,我们可以清楚特征向量主要是用于两个图像之间快速找到特征点匹配关系的,而相似度计算是通过词袋向量。
因为不一定每个单词重要性都是一样的(很多常出现的单词往往不是很重要),为了对单词的重要性或区分性加以评估,一般给单词不同的权值来得到更好的效果。
TF的意思是某单词在一幅图像上经常出现,它的区分度就高,而IDF的思想,是某个单词在字典中出现的频率越低,分类图像时,区分度越高。
IDF在建立字典的时候就计算:统计某个叶子节点
w
i
w_i
wi中特征数量相对于所有特征数量的比例,作为IDF的值。假设所有特征数量为n,
w
i
w_i
wi数量为
n
i
n_i
ni,那么这个单词的IDF就是:
I
D
F
i
=
l
o
g
(
n
/
n
i
)
{IDF}_i=log(n/n_i)
IDFi=log(n/ni)
TF就是指某个特征出现在一张图像中出现频率。假设图像A中单词
w
i
w_i
wi出现了
n
i
n_i
ni次,而一共出现的单词次数是n,那么TF的值为:
T
F
i
=
n
i
/
n
TF_i = n_i/n
TFi=ni/n
所以最终叶子节点
w
i
w_i
wi的权重就是
I
D
F
i
{IDF}_i
IDFi与
T
F
i
TF_i
TFi的积。
η
i
=
T
F
i
×
I
D
F
i
\eta_i=TF_i × {IDF}_i
ηi=TFi×IDFi
所以这时候每个叶子节点都会有一个权重,如果这时候给出两个图像A、B,它们的词袋向量可以表示为:
A
=
{
(
w
1
,
η
1
)
,
(
w
2
,
η
2
)
,
…
,
(
w
N
,
η
N
)
}
=
def
v
A
A=\left\{\left(w_1, \eta_1\right),\left(w_2, \eta_2\right), \ldots,\left(w_N, \eta_N\right)\right\} \stackrel{\text { def }}{=} \boldsymbol{v}_A
A={(w1,η1),(w2,η2),…,(wN,ηN)}= def vA
B
=
{
(
w
1
,
η
1
)
,
(
w
2
,
η
2
)
,
…
,
(
w
N
,
η
N
)
}
=
def
v
B
B=\left\{\left(w_1, \eta_1\right),\left(w_2, \eta_2\right), \ldots,\left(w_N, \eta_N\right)\right\} \stackrel{\text { def }}{=} \boldsymbol{v}_B
B={(w1,η1),(w2,η2),…,(wN,ηN)}= def vB
slam14讲中,给出的一种计算得分的公式:
s
(
v
A
−
v
B
)
=
2
∑
i
=
1
N
∣
v
A
i
∣
+
∣
v
B
i
∣
−
∣
v
A
i
−
v
B
i
∣
s\left(\boldsymbol{v}_A-\boldsymbol{v}_B\right)=2 \sum_{i=1}^N\left|\boldsymbol{v}_{A i}\right|+\left|\boldsymbol{v}_{B i}\right|-\left|\boldsymbol{v}_{A i}-\boldsymbol{v}_{B i}\right|
s(vA−vB)=2∑i=1N∣vAi∣+∣vBi∣−∣vAi−vBi∣
在orbslam的代码中,当两个图像之间某个 WordId 相同时,那么就将它们的权重进行运算,在orbslam中实现了很多的得分形式,有L1,L2和卡方得分等等。反正都是得分越高,那么这两帧图像的相似度越高,越容易构建回环。
orbslam中的直接索引表和倒排索引表
直接索引表是以图像为对象,存储图像中的特征点与字典中某个节点(node)的关联关系。直接索引表的作用就是给定了两个Frame对象或者KeyFrame对象,直接根据这个特征向量FeatureVector,找到属于同一个节点(node)下的特征点,然后遍历这些特征点计算描述子的相似得分即可快速找到匹配点对,而不是直接去遍历所有的特征点。
倒排索引表是以单词(word)为对象,存的是word的权重和这个word在哪个图像出现。倒排索引表的作用就是检测回环的时候使用,能够方便对比哪些图像有共同的word。
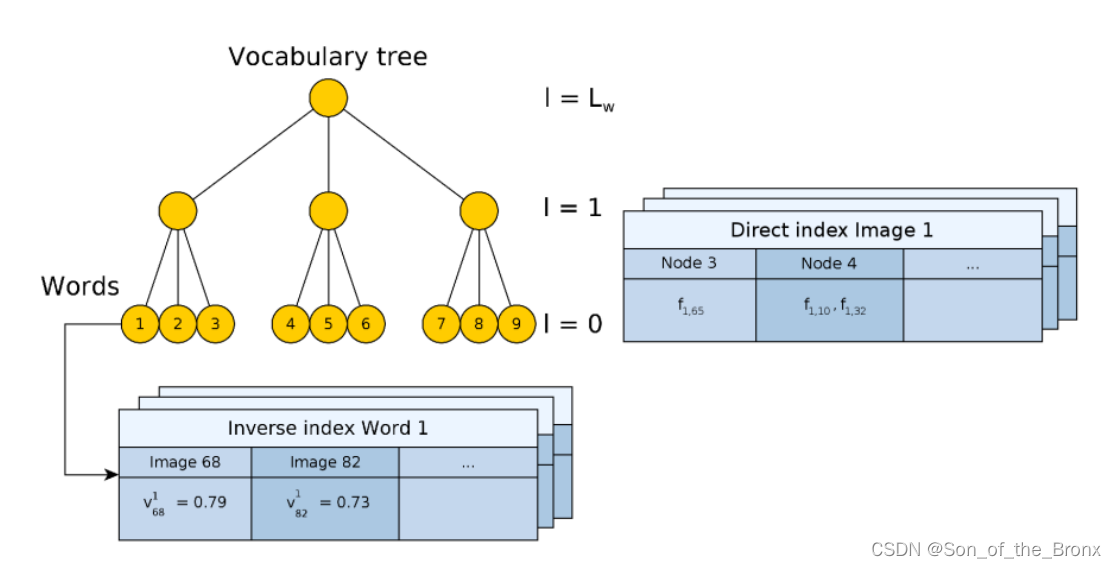
step2
通过词袋BoW加速当前帧与参考帧之间的特征点匹配。所以上面讲词袋模型的时候,特征向量FeatureVector就是用来快速得到匹配点对的。记录特征匹配成功后当前帧每个特征点对饮的MapPoint(来自参考帧),最后通过旋转直方图取出误匹配的点对。
step3
用上一帧位姿当作当前帧位姿的初始值。这样做的目的:因为根据参考关键帧跟踪的情况只在刚刚完成初始化或者重定位,没有匀速运动模型,所以就用上一帧位姿来当作这一帧预测位姿的初始值。
step4
通过3D-2D的重投影误差(pnp)来求解当前帧到参考帧之间的位姿。代码中就是通过g2o图优化的方式来实现(只优化位姿):
- 定义顶点g2o::VertexSE3Expmap,只有一个顶点就是当前帧的 T c w T_{cw} Tcw
- 定义边,如果是单目就是g2o::EdgeSE3ProjectXYZOnlyPose,如果是双目或者rgbd就是g2o::EdgeStereoSE3ProjectXYZOnlyPose,都是一元边。后续就是把边的各种属性:空间点位置,相机内参,观测,鲁棒核等信息
- 最后就是迭代优化,分四次迭代,每次迭代10次。期间需要根据卡方分布来去除外点,最终优化出当前帧的位姿。
step5
根据优化期间得到的外点标记,去除当前帧的地图点mCurrentFrame.mvpMapPoints中的外点。
TrackWithMotionModel()。匀速模型跟踪
这个函数是跟踪线程使用最频繁的函数,因为这个函数是用于两个普通帧之间跟踪,输出当前帧的位姿。
step1
更新上一帧的位姿,就是将上一帧在世界坐标系下的位姿计算出来:
l
a
s
t
T
w
o
r
l
d
=
l
a
s
t
T
r
e
f
∗
r
e
f
T
w
o
r
l
d
^{last}T_{world} = ^{last}T_{ref} * ^{ref}T_{world}
lastTworld=lastTref∗refTworld
如果是双目或者rgbd的情况,会根据上一帧有深度的特征点创建临时的地图点,这些地图点只是用来跟踪,不会加入到全局地图中,所以跟踪成功后会删除。
step2
根据上一帧估计的速度,用恒速运动模型,预测当前帧的位姿。本质上就是假设相邻的位姿变化率相同。
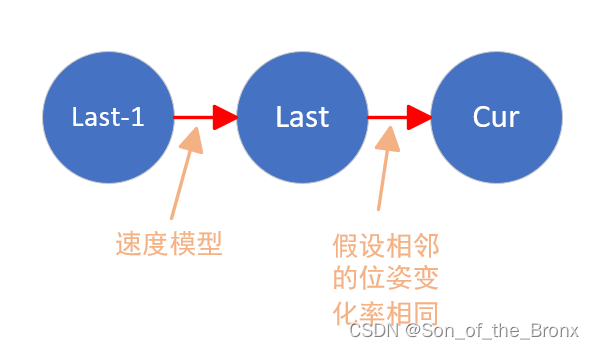
step3
用上一帧的地图点进行投影匹配。将上一帧的地图点根据预测的当前帧位姿,投影到当前帧的图像上,根据设定的搜索半径去搜索匹配点对。
通过matcher.SearchByProjection函数来找匹配关系
这个函数的步骤如下:
- 构建旋转直方图。就是通过大多数特征点的角度一致性来过滤外点。
- 遍历第一帧的所有特征点,然后根据半径窗口搜索在第二帧的所有候选匹配特征点,过程如下图所示:(图中红色的圆圈就是搜索半径)
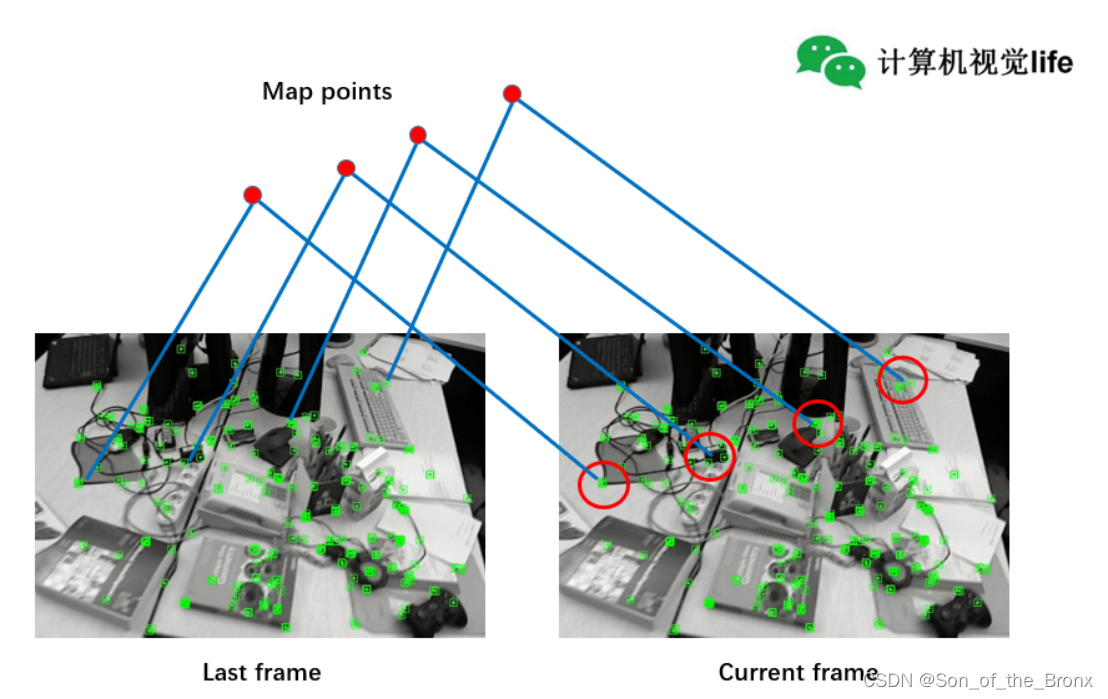
- 接着遍历步骤2中第二帧的所有候选匹配特征点,计算它们的描述子距离(因为是二进制存储,所以用的是汉明距离,即不同位数的个数),找到最优的和次优的。
- 对最优和次优的结果进行检查,当最优的距离小于阈值且最优距离小于次优距离的百分之90(比较宽松的阈值),这个是初始化ORBmatcher对象对象的参数。都通过检查后记录最佳的特征点匹配关系。
- 然后对这个特征点匹配的结果计算两个特征之间的角度差(这个角度是通过前面灰度质心法算出来的),加入到旋转直方图中。
- 结束遍历第一帧的所有特征点的大循环。筛选旋转直方图中不符合大多数旋转方向的特征点匹配关系(旋转直方图过滤)。
大部分的过程都跟单目初始化的时候很相似。都是通过半径搜索的方式去找匹配点对。如果匹配点太少,orbslam中的程序还会加大半径范围去搜索匹配点对。
step4
通过3D-2D的重投影误差(pnp)来求解当前帧到参考帧之间的位姿。代码中就是通过g2o图优化的方式来实现(只优化位姿)。过程是跟TrackReferenceKeyFrame()跟踪参考关键帧的step4是一样的,因为都是调用同一个函数且只优化当前帧位姿,这里不再赘述。
step5
根据g20优化过程中知道的外点关系,直接剔除mCurrentFrame.mvpMapPoints中的外点。
Relocalization()。重定位
这个函数主要是当跟踪跟丢了的时候,能够让当前帧重新与之前的地图重新连接上的方法。也可以在基于先建地图定位时,初始化定位信息的时候用。
step1
计算当前帧特征点的词袋向量(BoW)
step2
用词袋模型找到与当前帧相似的候选关键帧。通过mpKeyFrameDB->DetectRelocalizationCandidates函数来找到与当前帧相似的候选关键帧,这个过程跟找回环关键帧是类似的。
这个函数的步骤如下:
- 根据前面介绍的orbslam2中的倒排索引表,就是找出和当前帧有公共word的所有关键帧。
- 统计上述关键帧中与当前帧具有单词最多的单词数,用来设定阈值1筛选(最小公共单词数为最大公共单词数的0.8倍)
- 再次遍历上述关键帧,并且挑出符合阈值的关键帧并且计算它们与当前帧的相似得分(通过词袋向量来计算)
- 单单计算当前帧和某一关键帧的相似性是不够的,这里将与关键帧共视程度最高的前十个关键帧归为一组,计算组的累计得分,并且用于设定阈值2来筛选关键帧。(最高得分的0.75倍)
- 再次遍历候选关键帧,找到最终符合要求的候选关键帧。
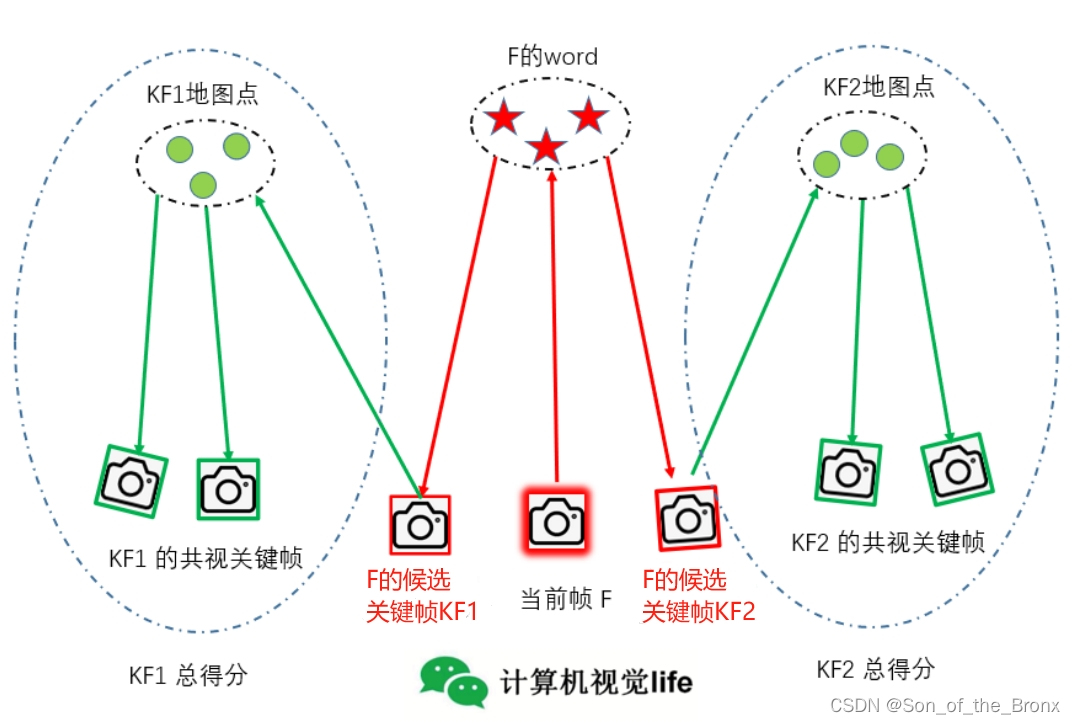
step3
遍历从上面过程得到的候选关键帧,通过词袋模型进行快速搜索匹配点对,如果匹配点对数量足够就初始化EPnP求解器。如果EPnP没有超过迭代次数上限,那么说明能够得到一个比较好的初值,再继续用g2o优化当前帧的位姿,内点数如果也满足要求那么就证明重定位成功,把优化后位姿设置为当前帧位姿,并且将当前帧的地图点进行外点去除。
除了这个重定位成功的过程,程序还有很长的代码是面对一些不理想的情景,比如内点数不符合要求,那么就用投影的方式找新的匹配点对再去做位姿优化,尽最大努力完成初始化的过程,这个过程大致都说过,所以这里就不赘述了。
TrackLocalMap()。局部地图跟踪
局部地图跟踪是跟踪过程的最后一步了,本质上这个过程就是根据关键帧的共视关系,进一步提高当前帧的定位精度,其实跟激光SLAM的局部地图匹配是一样的,激光SLAM中帧与帧之间的匹配精度有限(因为一帧激光点云的不完整性),而帧与局部地图的匹配的精度是更高的(局部地图更加完整)。而orbslam2是通过关键帧的共视关系来构建局部地图
step1
更新局部关键帧mvpLocalKeyFrames和局部地图点mvpLocalMapPoints。
更新局部关键帧的过程:
- 遍历当前帧的地图点,记录所有能观测到当前帧地图点的关键帧。
- 更新局部关键帧,添加的局部关键帧有三种类型:
2.1能观测到当前帧地图点的关键帧,称为一级共视关键帧
2.2一级共视关键帧的共视关键帧,成为二级共视关键帧
2.3一级共视关键帧的子关键帧、父关键帧 - 更新当前帧的参考关键帧,选择与自己共视程度最高的关键帧作为参考关键帧
- 先清空局部地图点,然后根据局部关键帧中的地图点添加到局部地图点中。
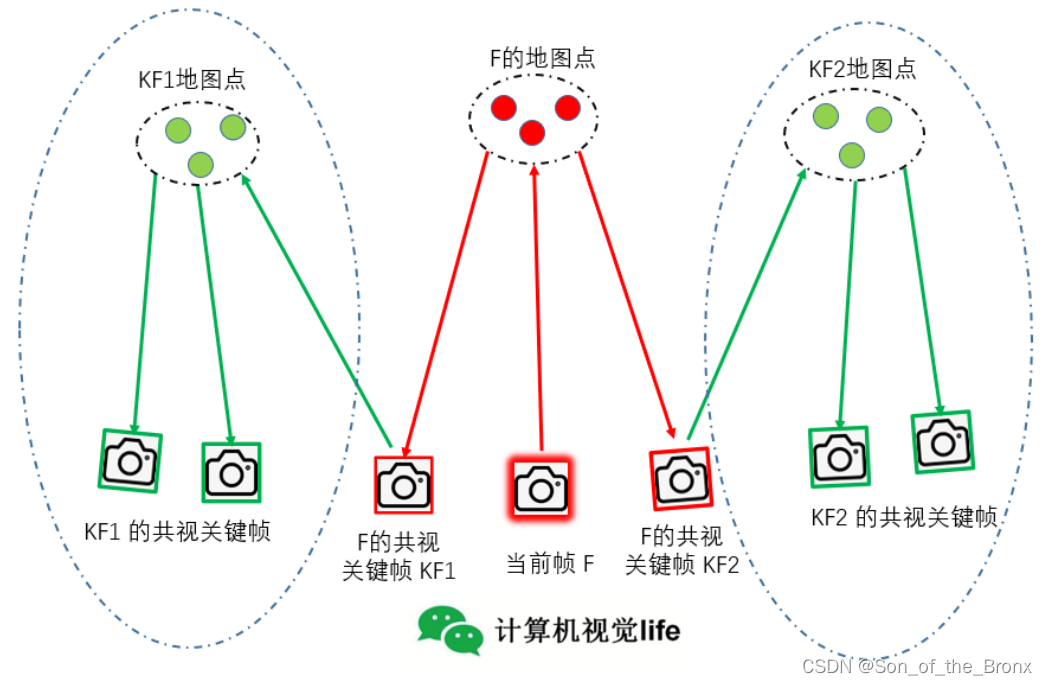
step2
筛选局部地图中新增的在视野范围内的地图点,投影到当前帧搜索匹配,得到更多的匹配关系。其实就是把局部地图点根据前面跟踪出来的位姿,转换到当前帧的相机坐标系上(并且会筛选这些局部地图点确保是在当前帧的视野内,比如z值为负的地图点肯定需要去除)。最后就是经典的matcher.SearchByProjection通过投影再用半径搜索去找匹配点对。
step3
通过3D-2D的重投影误差(pnp)来求解当前帧到参考帧之间的位姿。又是经典的g2o优化(仅优化当前帧位姿)。不赘述
step4
更新当前帧的地图点被观测程度。注意:地图点的被观测状态有两种:
- 一个
IncreaseVisible,这个其实是指这个地图点在构建局部地图的时候,在当前帧视野范围内(通过Frame::isInFrustum()函数判断是否在视野内)。 - 另一个
IncreaseFound,这个就是指这个地图点与当前帧特征点匹配上的意思。意义比IncreaseVisible更强,因为在视野范围内也有可能因为一些遮挡而导致没有特征点与之匹配。
并统计跟踪局部地图后匹配数目,如果匹配数目大于等于30就说明这个局部地图跟踪是成功的。
CreateNewKeyFrame()。产生新的关键帧
跟踪线程中的跟踪函数基本上都讲完了,实际SLAM的过程就是根据当前的跟踪的质量来选择不同的跟踪函数。最后再通过局部地图的跟踪,我们已经得到一个比较好的当前帧位姿了,所以我们就需要判断需不需要创建新的关键帧。
常见的关键帧生成方式:
- 根据运动距离或者转动角度的阈值来产生关键帧。
- 根据时间来产生关键帧。比如每10个雷达帧为一个关键帧
- orbslam2则是通过前面跟踪的状态来决定是否应该产生关键帧
orbslam2产生关键帧的判断条件
- 在参考关键帧中,统计观测次数大于3的地图点数量
nRefMatches。单目的情况下,如果当前帧的内点数小于nRefMatches的0.9倍就要加新的关键帧(因为单目的跟踪依赖关键帧之间三角化的地图点来通过pnp求解相机运动,所以插入关键帧的频率要高),如果是双目或rgbd的话,就是当前帧的内点数小于nRefMatches的0.75倍就要加新的关键帧(因为在跟踪的过程中,双目或rgbd会加入一些距离可信的点来提高跟踪效果)。 - 除了根据跟踪状态来,orbslam2还会设置
mMaxFrames和mMinFrames参数来根据时间且结合跟踪效果决定是否产生关键帧。
创建新的关键帧
- 将当前帧构造成关键帧。
- 将当前关键帧设置为当前帧的参考关键帧
- 如果相机是双目或rgbd相机,则为当前帧生成新的地图点,单目不需要。(就是直接把当前帧深度可信的3d点分别加入到当前关键帧中和全局地图中)。
- 插入关键帧,就是把新创建的关键帧插入到
mpLocalMapper这个线程的mlNewKeyFrames容器中。 - 将
tracking线程中新的关键帧mpLastKeyFrame设置为新创建的关键帧。
总结
这篇文章主要就是整理了tracking跟踪线程中的主要函数:
- 单目初始化
- 双目或rgbd初始化
- 参考关键帧的跟踪
- 匀速模型跟踪
- 重定位(与回环有点像,主要是跟丢后重新找到在地图中的定位)
- 局部地图跟踪(提高定位信息在局部的准确性)
- 判断产生关键帧的时机
其实整个Tracking::Track()函数很大,逻辑也很多,但是本质上通过一系列逻辑将上述函数组合,而实现跟踪的效果。我们学习的目的应该是聚焦在函数实现上,过度关注这些逻辑有点浪费时间,因为我认为这些逻辑可能每个人的思考都不同,在需要的时候参考参考即可。