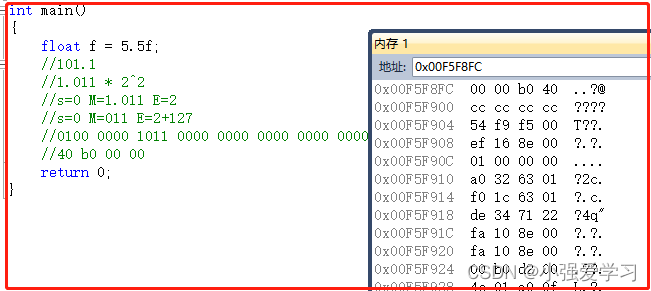
4.1 实时计算业务介绍
学习目标
- 目标
- 了解实时计算的业务需求
- 知道实时计算的作用
- 应用
- 无
4.1.1 实时计算业务需求
实时(在线)计算:
- 解决用户冷启动问题
- 实时计算能够根据用户的点击实时反馈,快速跟踪用户的喜好
4.1.2 实时计算业务图
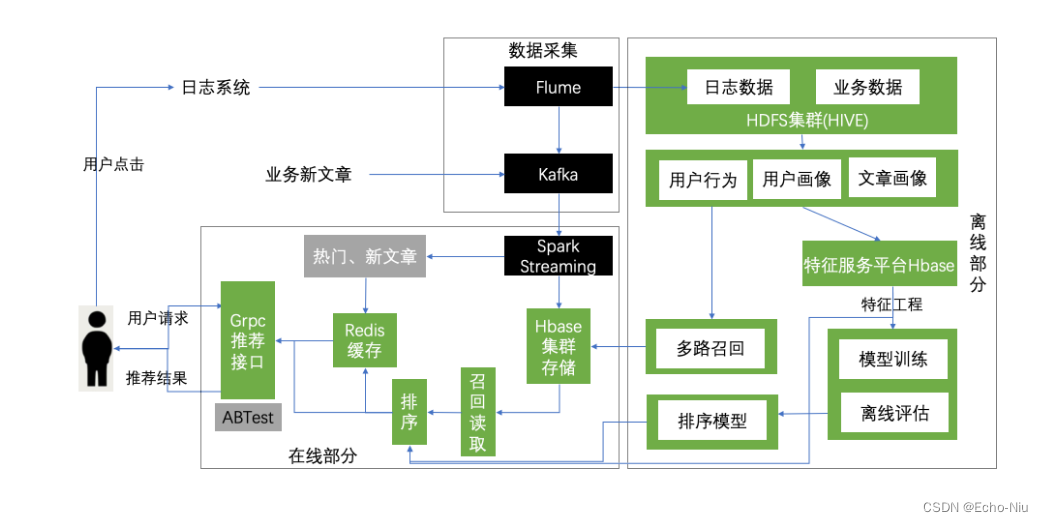
4.2 实时日志分析
学习目标
- 目标
- 了解实时计算的业务需求
- 知道实时计算的作用
- 应用
- 无
日志数据我们已经收集到hadoop中,但是做实时分析的时候,我们需要将每个时刻用户产生的点击行为收集到KAFKA当中,等待spark streaming程序去消费。
4.2.1 Flume收集日志到Kafka
- 目的:收集本地实时日志行为数据,到kafka
- 步骤:
- 1、开启zookeeper以及kafka测试
- 2、创建flume配置文件,开启flume
- 3、开启kafka进行日志写入测试
- 4、脚本添加以及supervisor管理
开启zookeeper,需要在一直在服务器端实时运行,以守护进程运行
/root/bigdata/kafka/bin/zookeeper-server-start.sh -daemon /root/bigdata/kafka/config/zookeeper.properties
以及kafka的测试:
/root/bigdata/kafka/bin/kafka-server-start.sh /root/bigdata/kafka/config/server.properties
测试
开启消息生产者
/root/bigdata/kafka/bin/kafka-console-producer.sh --broker-list 192.168.19.19092 --sync --topic click-trace
开启消费者
/root/bigdata/kafka/bin/kafka-console-consumer.sh --bootstrap-server 192.168.19.137:9092 --topic click-trace
2、修改原来收集日志的文件,添加flume收集日志行为到kafka的source, channel, sink
a1.sources = s1
a1.sinks = k1 k2
a1.channels = c1 c2
a1.sources.s1.channels= c1 c2
a1.sources.s1.type = exec
a1.sources.s1.command = tail -F /root/logs/userClick.log
a1.sources.s1.interceptors=i1 i2
a1.sources.s1.interceptors.i1.type=regex_filter
a1.sources.s1.interceptors.i1.regex=\\{.*\\}
a1.sources.s1.interceptors.i2.type=timestamp
# channel1
a1.channels.c1.type=memory
a1.channels.c1.capacity=30000
a1.channels.c1.transactionCapacity=1000
# channel2
a1.channels.c2.type=memory
a1.channels.c2.capacity=30000
a1.channels.c2.transactionCapacity=1000
# k1
a1.sinks.k1.type=hdfs
a1.sinks.k1.channel=c1
a1.sinks.k1.hdfs.path=hdfs://192.168.19.137:9000/user/hive/warehouse/profile.db/user_action/%Y-%m-%d
a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.sinks.k1.hdfs.fileType=DataStream
a1.sinks.k1.hdfs.writeFormat=Text
a1.sinks.k1.hdfs.rollInterval=0
a1.sinks.k1.hdfs.rollSize=10240
a1.sinks.k1.hdfs.rollCount=0
a1.sinks.k1.hdfs.idleTimeout=60
# k2
a1.sinks.k2.channel=c2
a1.sinks.k2.type=org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k2.kafka.bootstrap.servers=192.168.19.137:9092
a1.sinks.k2.kafka.topic=click-trace
a1.sinks.k2.kafka.batchSize=20
a1.sinks.k2.kafka.producer.requiredAcks=1
3、开启flume新的配置进行测试, 开启之前关闭之前的flume程序
#!/usr/bin/env bash
export JAVA_HOME=/root/bigdata/jdk
export HADOOP_HOME=/root/bigdata/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
/root/bigdata/flume/bin/flume-ng agent -c /root/bigdata/flume/conf -f /root/bigdata/flume/conf/collect_click.conf -Dflume.root.logger=INFO,console -name a1
开启kafka脚本进行测试,把zookeeper也放入脚本中,关闭之前的zookeeper
#!/usr/bin/env bash
# /root/bigdata/kafka/bin/zookeeper-server-start.sh -daemon /root/bigdata/kafka/config/zookeeper.properties
/root/bigdata/kafka/bin/kafka-server-start.sh /root/bigdata/kafka/config/server.properties
/root/bigdata/kafka/bin/kafka-topics.sh --zookeeper 192.168.19.137:2181 --create --replication-factor 1 --topic click-trace --partitions 1
4.2.2 super添加脚本
[program:kafka]
command=/bin/bash /root/toutiao_project/scripts/start_kafka.sh
user=root
autorestart=true
redirect_stderr=true
stdout_logfile=/root/logs/kafka.log
loglevel=info
stopsignal=KILL
stopasgroup=true
killasgroup=true
supervisor进行update
4.2.3 测试
开启Kafka消费者
/root/bigdata/kafka/bin/kafka-console-consumer.sh --bootstrap-server 192.168.19.137:9092 --topic click-trace
写入一次点击数据:
echo {\"actionTime\":\"2019-04-10 21:04:39\",\"readTime\":\"\",\"channelId\":18,\"param\":{\"action\": \"click\", \"userId\": \"2\", \"articleId\": \"14299\", \"algorithmCombine\": \"C2\"}} >> userClick.log
观察消费者结果
[root@hadoop-master ~]# /root/bigdata/kafka/bin/kafka-console-consumer.sh --bootstrap-server 192.168.19.137:9092 --topic click-trace
{"actionTime":"2019-04-10 21:04:39","readTime":"","channelId":18,"param":{"action": "click", "userId": "2", "articleId": "14299