目录
官方文档
使用说明:
点击基本图表
可以点击你想要的图表
安装:
一些例图:
柱状图:
效果:
折线图:
效果:
环形图:
效果:
南丁格尔图(玫瑰图):
效果:
堆叠折线图:
效果:
堆叠柱状图:
编辑
拟合散点曲线图:
官方文档
使用说明:
点击基本图表

-
可以点击你想要的图表
- 可以点击Demo里面有例图以及代码,可以复制下来再根据需求来改
- 要查询图表的配置也可以到全局配置里面查找
安装:
pip install pyecharts -i https://pypi.tuna.tsinghua.edu.cn/simple some-package一些例图:
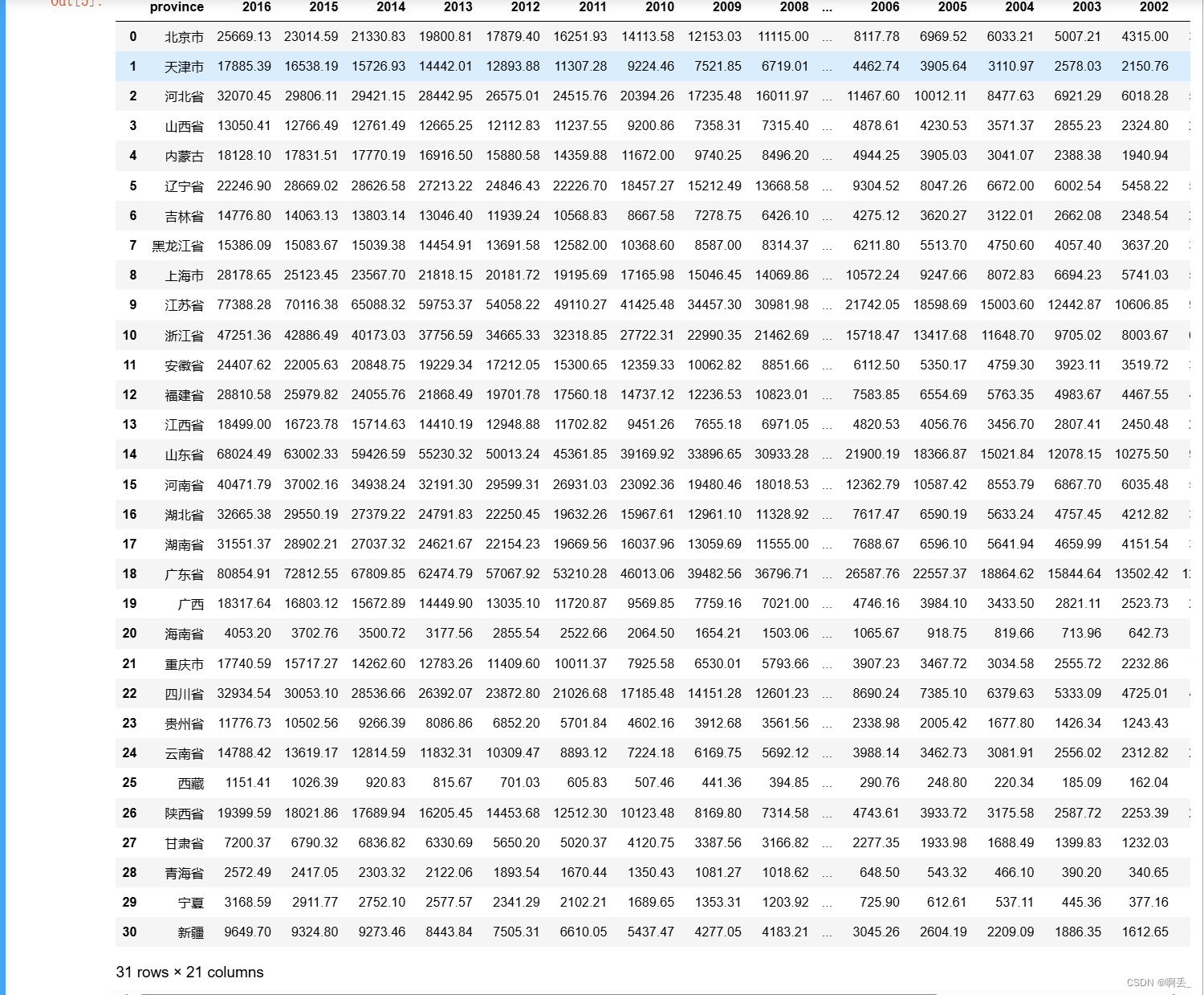
这里引用的是一个全国各省份的GDP数据(需要拿来练习的可以私我拿数据~)
柱状图:
import pandas as pd
from pyecharts import options as opts
from pyecharts.charts import Bar
from pyecharts.globals import ThemeType
# 加载数据集
data = pd.read_csv(r'D:\Dabby\Documents\数据可视化\gdp.csv',encoding='utf-8')
# 提取2016年的数据并按GDP降序排列取前10个省份
data_2016 = data[['province','2016']]
top_10_gdp = data_2016['2016'].sort_values(ascending=False).head(10)
top_10_province = data_2016.loc[top_10_gdp.index, 'province']
# 获取省份和GDP数据
provinces = top_10_province.tolist()
gdp_values = top_10_gdp.tolist()
# 使用Pyecharts绘制柱状图
init_opts=opts.InitOpts(width='1000px',height='450px',theme=ThemeType.LIGHT)
bar = (
Bar()
.add_xaxis(provinces)
.add_yaxis("GDP",gdp_values)
.set_global_opts(
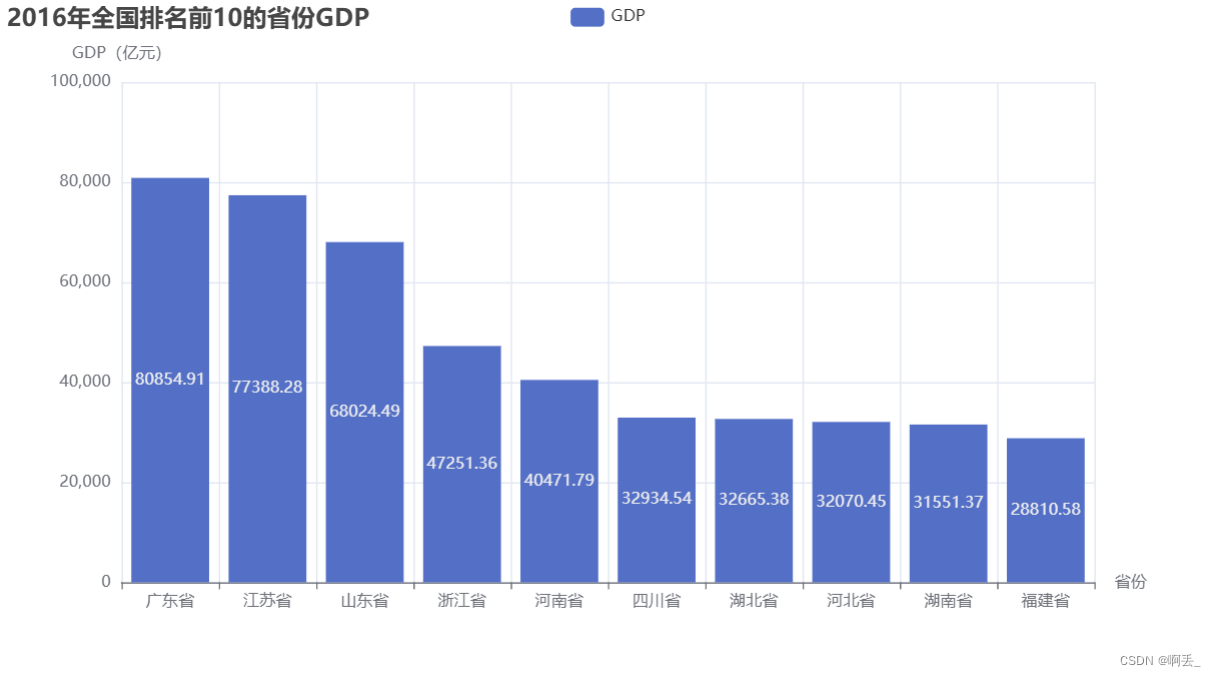
title_opts=opts.TitleOpts(title="2016年全国排名前10的省份GDP"),
xaxis_opts=opts.AxisOpts(name="省份"),
yaxis_opts=opts.AxisOpts(name="GDP(亿元)"),
)
)
bar.render_notebook() # 将图表保存为HTML文件效果:
折线图:
from pyecharts.charts import Line
from pyecharts import options as opts
data = pd.read_csv(r'D:\Dabby\Documents\数据可视化\gdp.csv',encoding='utf-8')
data_gx=data.loc[19]
data_gx
year_gx=data_gx.index.to_list()[1:][::-1]
gdp=list(data_gx.values)[1:][::-1]
years=year_gx[:10]
line = (
Line()
.add_xaxis(years)
.add_yaxis("广西GDP", gdp) # 设置曲线光滑
.set_global_opts(
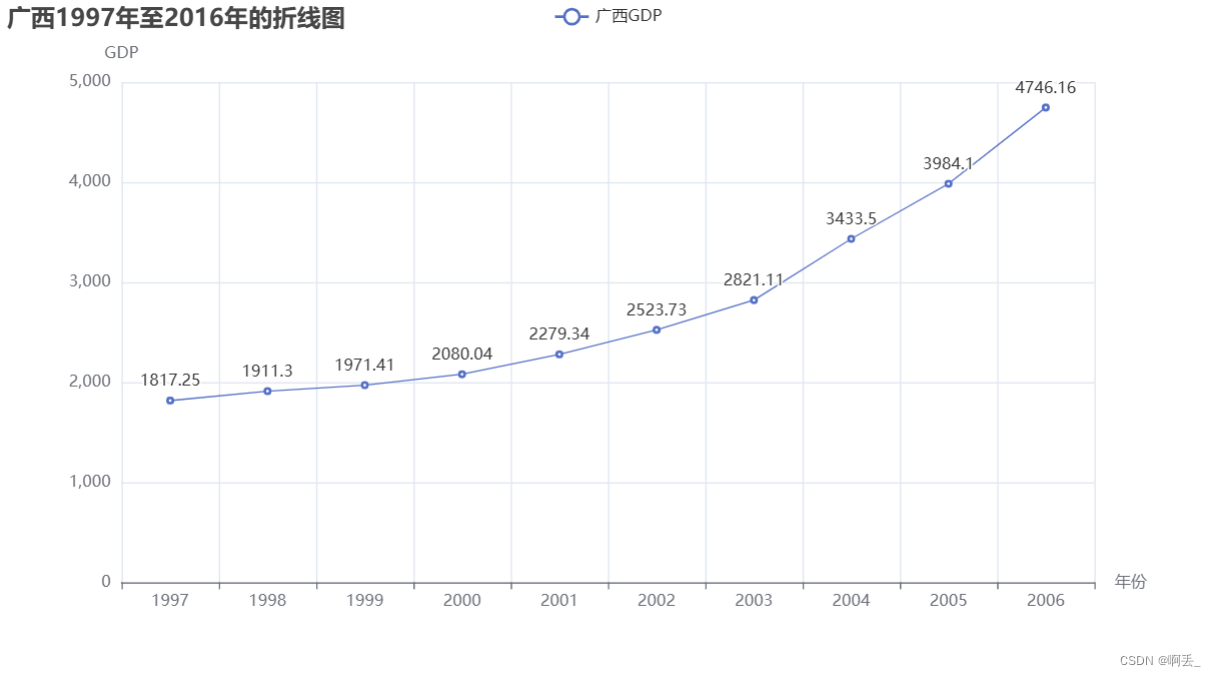
title_opts=opts.TitleOpts(title="广西1997年至2016年的折线图"),
xaxis_opts=opts.AxisOpts(name="年份"),
yaxis_opts=opts.AxisOpts(name="GDP") # 在这里添加逗号
)
)
line.render_notebook()效果:
环形图:
import matplotlib.pyplot as plt
from pyecharts import options as opts
from pyecharts.charts import Pie # 导入 Pie 类
data = pd.read_csv(r'D:\Dabby\Documents\数据可视化\gdp.csv',encoding='utf-8')
data_2014 = data[['province', '2014']]
top_10_gdp = data_2014['2014'].sort_values(ascending=False).head(10)
top_10_province = data_2014.loc[top_10_gdp.index, 'province']
gdp = top_10_gdp.tolist()
provinces = top_10_province.tolist()
pie=Pie()
pie.add('',[list(z)for z in zip(provinces,gdp)],radius=[70, 150])
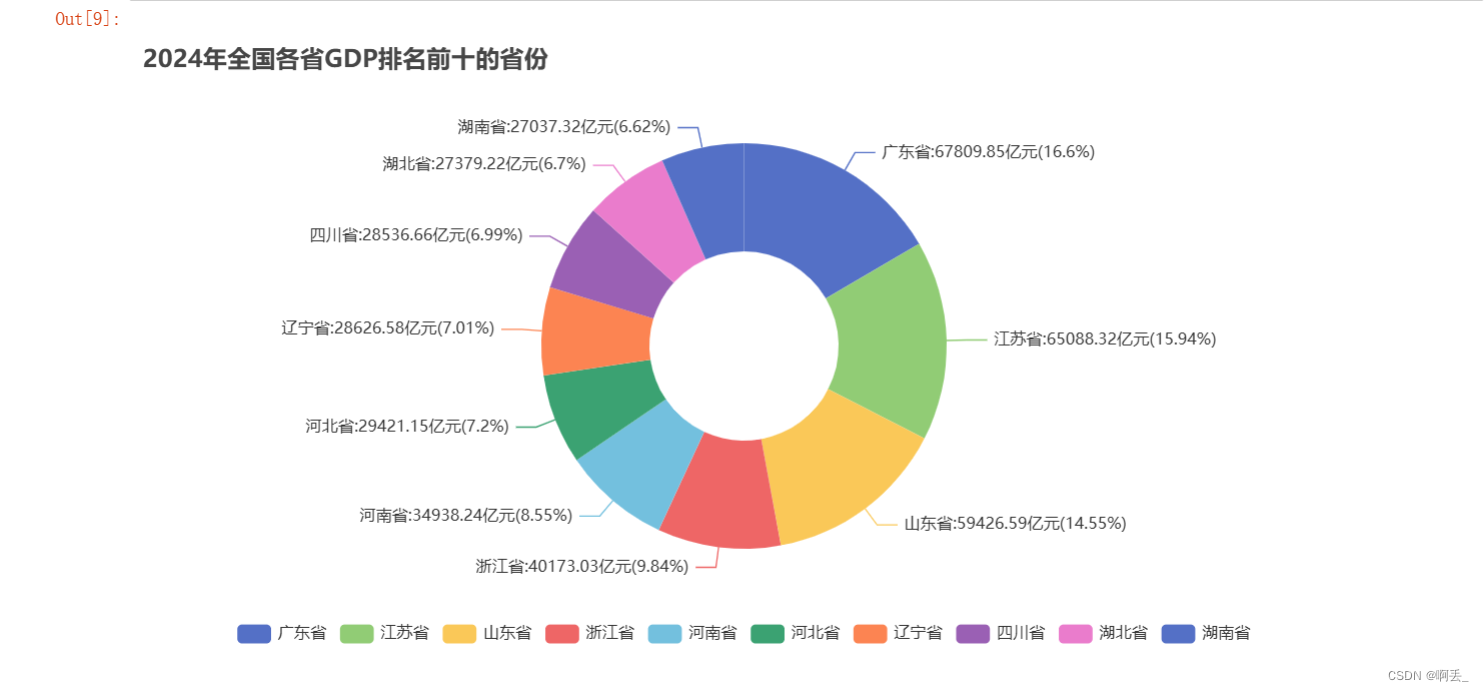
pie.set_global_opts(title_opts=opts.TitleOpts(title='2024年全国各省GDP排名前十的省份', pos_top="5%"),
legend_opts=opts.LegendOpts(pos_bottom="5%")
)
pie.set_series_opts(label_opts=opts.LabelOpts(formatter='{b}:{c}亿元({d}%)'))
pie.render_notebook()效果:
南丁格尔图(玫瑰图):
import matplotlib.pyplot as plt
from pyecharts import options as opts
from pyecharts.charts import Page, Pie
data = pd.read_csv(r'D:\Dabby\Documents\数据可视化\gdp.csv',encoding='utf-8')
data_gx=data.loc[19]
#获取广西近八年GDP数据
year_gx=data_gx.index.to_list()[1:]
year_gx=year_gx[:8]
gdp_gx=list(data_gx.values)[1:][:8]
#获取江苏近八年GDP数据
data_js=data.loc[9]
year_js=data_js.index.to_list()[1:][:8]
gdp_js=list(data_js.values)[1:][:8]
# 绘制广西南丁格尔玫瑰图(area型)
guangxi_pie = (
Pie()
.add(
series_name="广西近8年的GDP", # 系列名称
data_pair=[list(z) for z in zip(year_gx, gdp_gx)], # 数据对,形如 [('2014', 100), ('2015', 120), ...]
radius=[50, 200], # 设置半径,形成南丁格尔玫瑰图
rosetype="area", # 设置玫瑰图类型为 area
)
.set_global_opts(
title_opts=opts.TitleOpts(title="广西近8年 GDP 变化"), # 设置标题
legend_opts=opts.LegendOpts(orient="vertical", pos_top="15%", pos_right="2%")
)
.set_series_opts(label_opts=opts.LabelOpts(formatter='{b}:{c}(亿元)({d}%)'))
)
# 绘制江苏南丁格尔玫瑰图(radius型)
jiangsu_pie = (
Pie()
.add(
series_name="江苏 GDP 变化", # 系列名称
data_pair=[list(z) for z in zip(year_js, gdp_js)], # 数据对,形如 [('2014', 200), ('2015', 220), ...]
radius=[50, 200], # 设置半径,形成南丁格尔玫瑰图
rosetype="radius", # 设置玫瑰图类型为 radius
)
.set_global_opts(
title_opts=opts.TitleOpts(title="江苏近8年 GDP 变化"), # 设置标题
legend_opts=opts.LegendOpts(orient="vertical", pos_top="15%", pos_right="2%")
)
.set_series_opts(label_opts=opts.LabelOpts(formatter='{b}:{c}(亿元)({d}%)'))
)
# 创建一个页面,并将两个图添加到页面中
page = Page()
page.add(guangxi_pie)
page.add(jiangsu_pie)
# 渲染并保存 HTML 文件
page.render_notebook()效果:
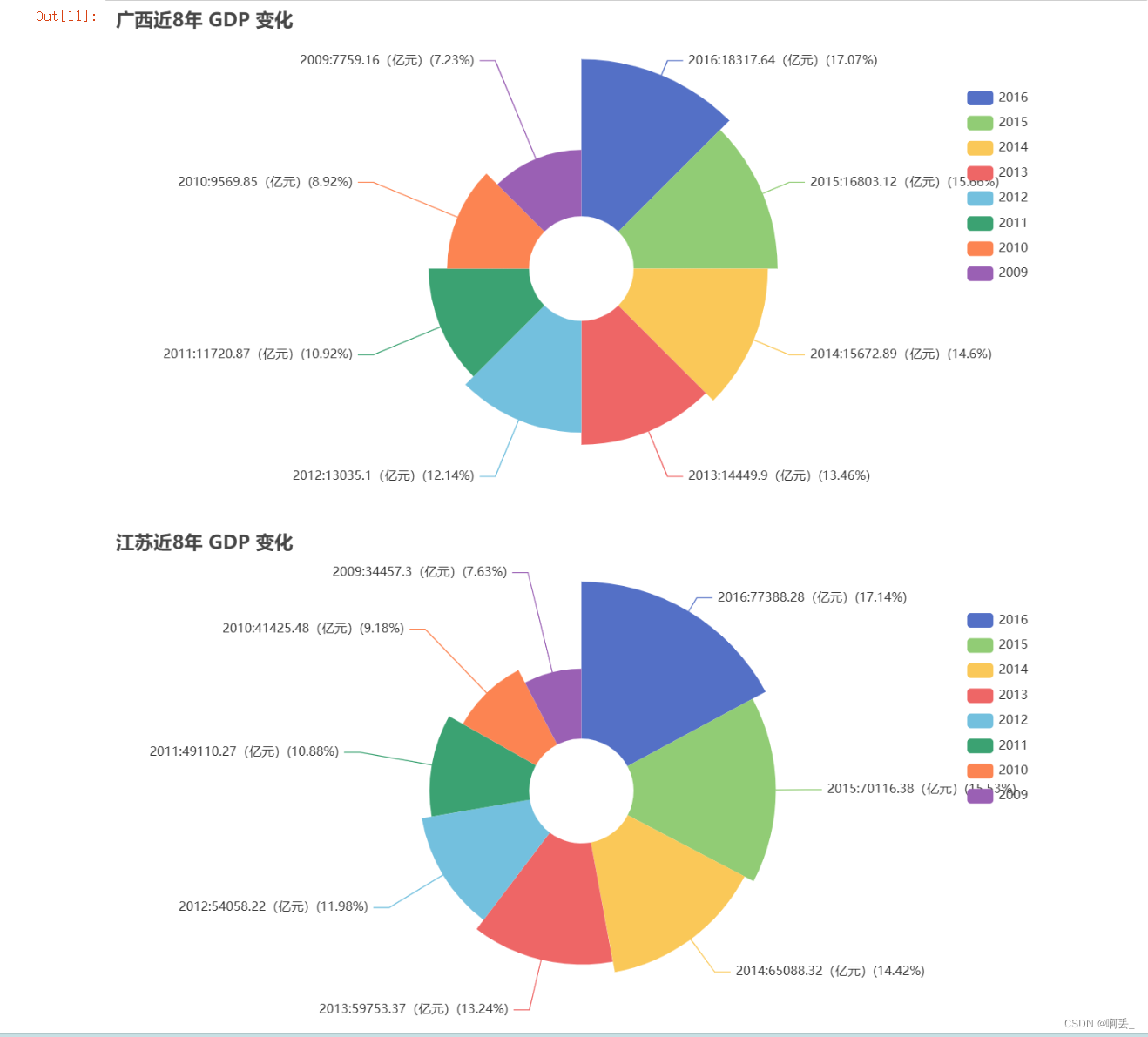
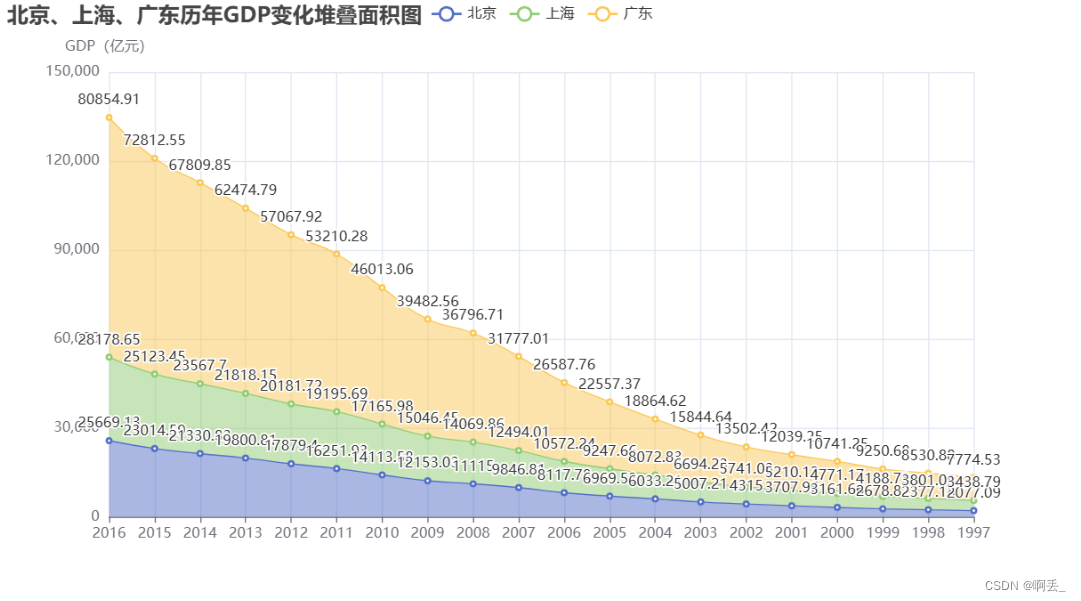
堆叠折线图:
import pandas as pd
from pyecharts import options as opts
from pyecharts.charts import Line
from pyecharts.globals import ThemeType
from pyecharts import options as opts
data = pd.read_csv(r'D:\Dabby\Documents\数据可视化\gdp.csv')
# 截取北京的数据
data_bj = data.loc[0]
year_bj = data_bj.index.to_list()[1:]
gdp_bj = list(data_bj.values)[1:]
# 截取上海数据
data_sh = data.loc[8]
year_sh = data_sh.index.to_list()[1:]
gdp_sh = list(data_sh.values)[1:]
# 截取广东数据
data_gd = data.loc[18]
year_gd = data_gd.index.to_list()[1:]
gdp_gd = list(data_gd.values)[1:]
# 创建堆叠面积图对象
line = Line()
# 添加数据并设置堆叠属性
line.add_xaxis(year_bj)
line.add_yaxis("北京", gdp_bj, is_smooth=True, stack="stack1", areastyle_opts=opts.AreaStyleOpts(opacity=0.5))
line.add_yaxis("上海", gdp_sh, is_smooth=True, stack="stack1", areastyle_opts=opts.AreaStyleOpts(opacity=0.5))
line.add_yaxis("广东", gdp_gd, is_smooth=True, stack="stack1", areastyle_opts=opts.AreaStyleOpts(opacity=0.5))
# 设置全局配置项
line.set_global_opts(
title_opts=opts.TitleOpts(title="北京、上海、广东历年GDP变化堆叠面积图"),
xaxis_opts=opts.AxisOpts(type_="category", boundary_gap=False),
yaxis_opts=opts.AxisOpts(type_="value", name="GDP(亿元)"),
tooltip_opts=opts.TooltipOpts(trigger="axis", axis_pointer_type="cross")
)
# 渲染图像
line.render_notebook()效果:
堆叠柱状图:
from pyecharts.charts import Bar
import pandas as pd
from pyecharts import options as opts
from pyecharts.globals import ThemeType
#截取广西数据
data = pd.read_csv(r'D:\Dabby\Documents\数据可视化\gdp.csv')
data_gx=data.loc[19]
year_gx=data_gx.index.to_list()[1:][::-1]
gdp_gx=list(data_gx.values)[1:][::-1]
#截取广东数据
data_gd=data.loc[18]
year_gd=data_gd.index.to_list()[1:][::-1]
gdp_gd=list(data_gd.values)[1:][::-1]
# 绘制堆叠柱状图
bar = Bar() # 注意:这里你可能需要导入InitOpts,但在某些版本的Pyecharts中可能不是必需的
bar.add_xaxis(year_gx)
# 注意:添加stack参数并将值设置为相同的字符串(例如'gdp'),以使序列堆叠
bar.add_yaxis("广西", gdp_gx, stack="gdp")
bar.add_yaxis("广东", gdp_gd, stack="gdp")
bar.set_global_opts(
title_opts=opts.TitleOpts(title="近年来广西和广东的GDP趋势"),
xaxis_opts=opts.AxisOpts(type_="category"),
yaxis_opts=opts.AxisOpts(type_="value", name="GDP (亿元)"),
legend_opts=opts.LegendOpts(pos_left="center", pos_top="top")
)
bar.render_notebook()
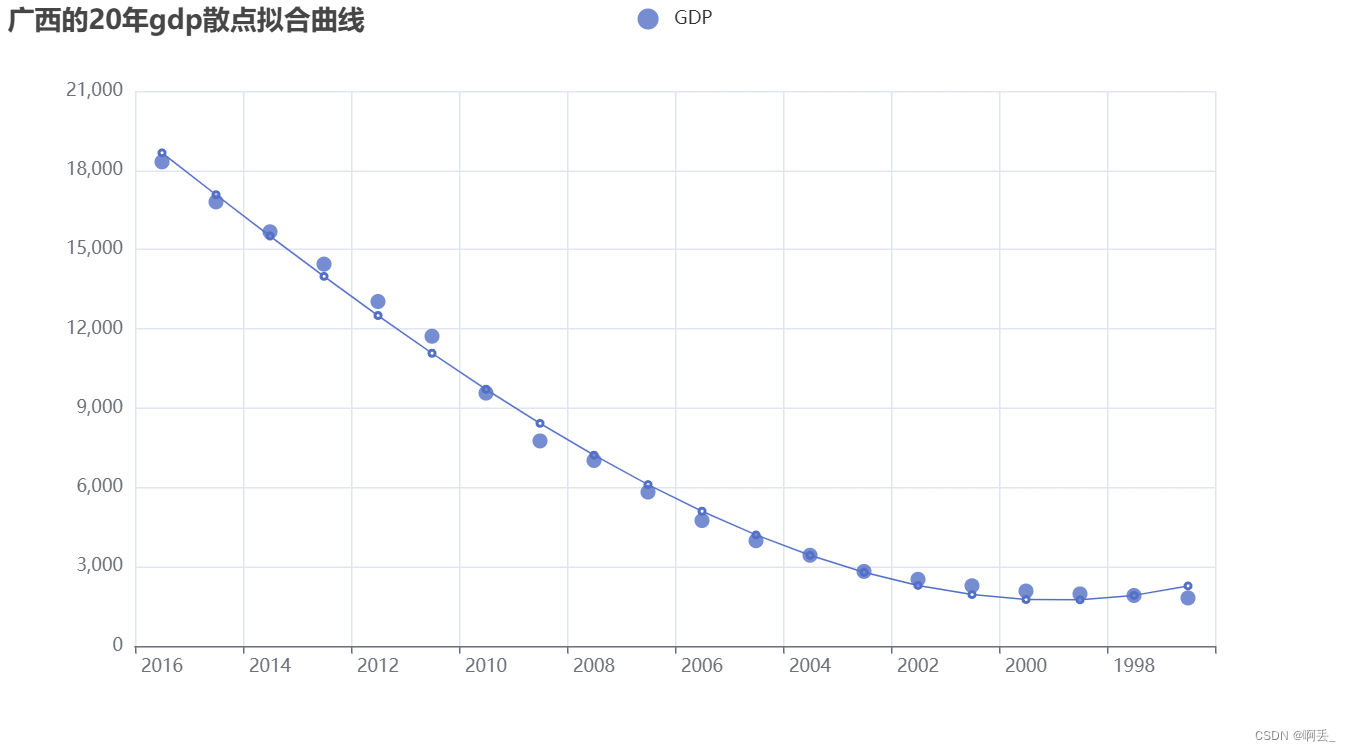
拟合散点曲线图:
mport pandas as pd
import numpy as np
from pyecharts import options as opts
from pyecharts.charts import Line
from pyecharts.charts import Scatter
from pyecharts.globals import ThemeType
data=pd.read_csv(r"D:\Dabby\Documents\数据可视化\gdp.csv",encoding='utf-8')
#截取广西数据
data_gx=data.loc[19]
year_gx=data_gx.index.to_list()[1:]
gdp_gx=list(data_gx.values)[1:]
#先绘制散点图
scatter=Scatter()
scatter.add_xaxis(year_gx)
scatter.add_yaxis("GDP",gdp_gx)
scatter.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
scatter.set_global_opts(title_opts=opts.TitleOpts(title='广西的20年gdp散点拟合曲线'))
scatter.render_notebook()
#计算拟合三次多项式的x,y,z
year_gx_float = np.array(year_gx, dtype=float)
gdp_gx_float = np.array(gdp_gx, dtype=float)
poly=np.polyfit(year_gx_float,gdp_gx_float,deg=3)
#绘制拟合曲线散点图
line=Line()
line.add_xaxis(list(year_gx))
line.add_yaxis('GDP', np.polyval(poly, year_gx_float))
line.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
scatter.overlap(line)
scatter.render_notebook()