大模型BLIP-2的多模态训练
- 一、引言
- 二、BLIP-2模型概述
- 三、多模态训练成本问题
- 四、冻结预训练好的视觉语言模型参数的优势
- 五、冻结预训练好的视觉语言模型参数的方法
一、引言
随着人工智能技术的飞速发展,大型多模态模型如BLIP-2在多个领域取得了显著的成果。然而,其高昂的训练成本成为了制约其广泛应用的一大难题。为了降低训练成本,本文提出了冻结预训练好的视觉语言模型参数的策略,并详细探讨了其优势和实施方法。

二、BLIP-2模型概述
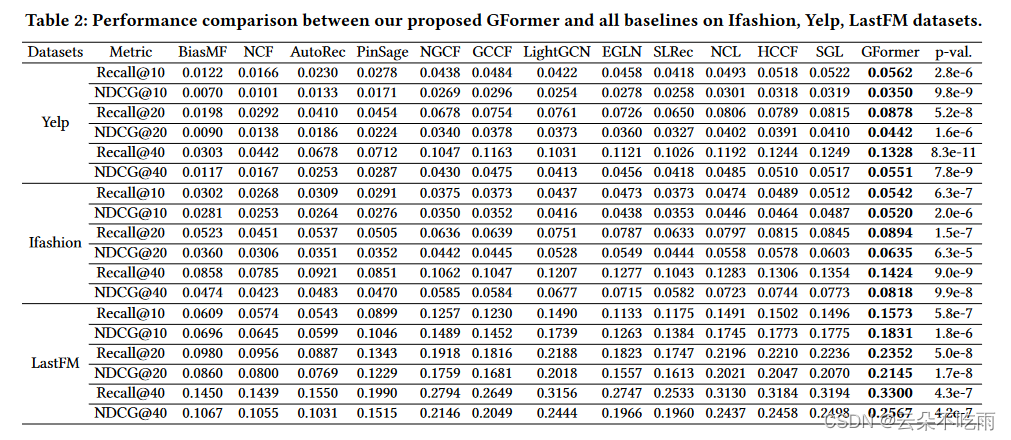
BLIP-2是一种新型的大型多模态模型,它通过融合视觉和语言信息,实现了跨模态的理解和生成。该模型在多个数据集上取得了优异的性能,包括图像描述生成、视觉问答等任务。然而,由于其庞大的模型规模和复杂的训练过程,BLIP-2的训练成本极高,这限制了其在更多场景下的应用。
三、多模态训练成本问题
多模态训练的成本主要来自于以下几个方面:
1.数据收集和处理:多模态训练需要大量的跨模态数据,包括图像、文本等。这些数据需要进行预处理和标注,成本较高。
2.计算资源:大型多模态模型需要强大的计算资源来支持训练过程,包括高性能计算机、GPU等。这些设备的购置和维护成本较高。
3.训练时间:由于模型规模庞大,训练时间往往较长,这增加了人力和时间成本。
四、冻结预训练好的视觉语言模型参数的优势
为了降低多模态训练的成本,我们提出了冻结预训练好的视觉语言模型参数的策略。该策略具有以下优势:
1.节省计算资源:通过冻结预训练好的参数,可以减少训练过程中的计算量,从而降低对计算资源的需求。
2.缩短训练时间:由于部分参数已经被固定,模型在训练时只需要更新部分参数,从而缩短训练时间。
3.提高模型稳定性:预训练好的参数通常具有较高的稳定性和泛化能力,通过冻结这些参数,可以提高整个模型的稳定性和性能。
五、冻结预训练好的视觉语言模型参数的方法
在实施冻结预训练好的视觉语言模型参数的策略时,我们可以采用以下方法:
1.选择合适的预训练模型:首先,我们需要选择一个性能优异的预训练模型作为基础模型。该模型应该具有较高的跨模态理解和生成能力,并且在大规模数据集上进行了充分的训练。
2.冻结部分参数:在基础模型的基础上,我们可以选择冻结部分参数。这些参数通常包括视觉编码器、语言编码器等关键组件的参数。通过冻结这些参数,我们可以保留其在预训练阶段学到的知识和经验,同时减少训练过程中的计算量。
3.微调剩余参数:在冻结部分参数后,我们只需要对剩余参数进行微调。这些参数通常包括跨模态融合层、输出层等组件的参数。通过微调这些参数,我们可以使模型适应新的任务和数据集,同时保持其在预训练阶段学到的知识和经验。