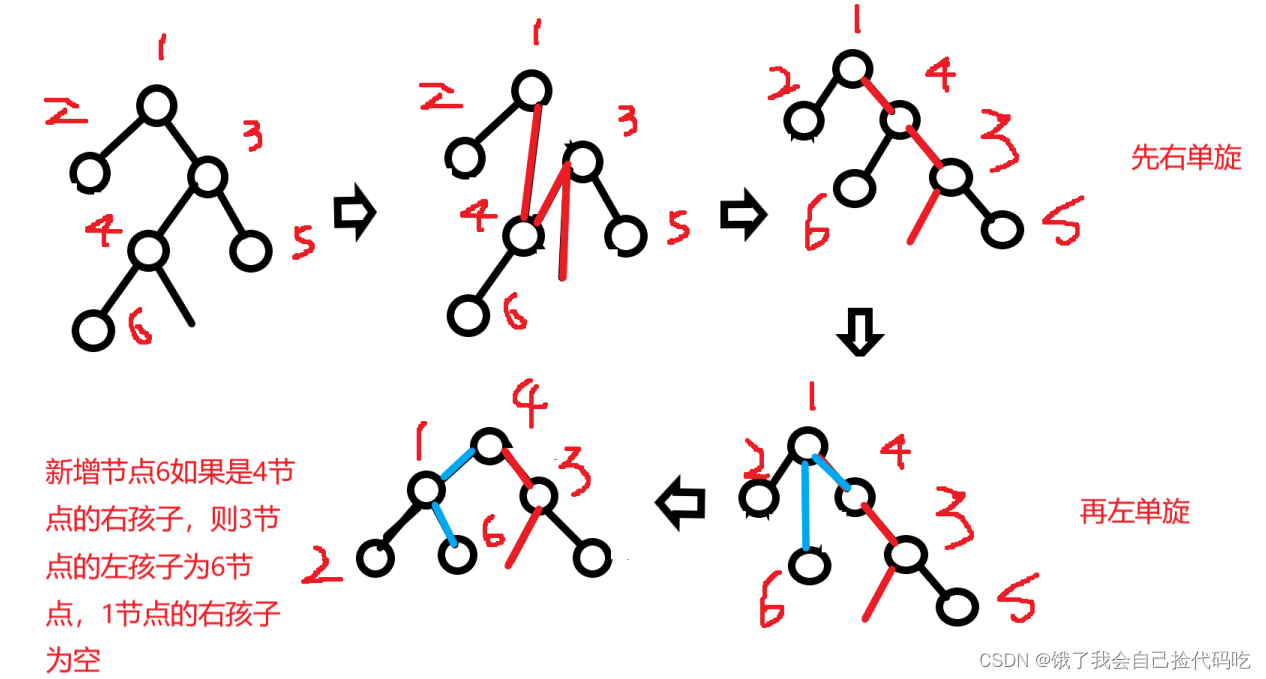
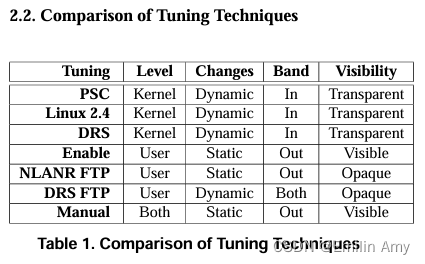
引言
本文将详细指导新手开发者如何将MySQL中的普通表转换为分区表。分区表在处理庞大数据集时展现出显著的性能优势,不仅能大幅提升查询速度,还能有效简化数据维护工作。通过掌握这一技巧能够更好地应对数据密集型应用带来的挑战,为系统的高效运行奠定坚实基础。
目录
- 引言
- 步骤 1: 备份原始数据
- 步骤 2: 修改表结构以包含分区键在主键中
- 步骤 3. 修改原始表以支持分区
- 步骤 4: 重建表以添加分区
- 步骤 5: 迁移数据到新表
- 步骤 6: 验证数据迁移的完整性和准确性
- 步骤 7: 重命名表(可选)
- 步骤 8: 测试和监控
- 步骤 9:创建分区管理存储过程
- 注意事项

步骤 1: 备份原始数据
在进行任何结构更改之前,请务必备份原始数据,dump或者sql请选中合适的方式即可。
mysqldump -u [username] -p[password] [database_name] new_table > new_table_backup.sql
CREATE TABLE backup_table_name AS SELECT * FROM original_table_name;
如果数据量不大,可以直接修改表结构即可,可以跳过 3到 7这几步。
步骤 2: 修改表结构以包含分区键在主键中
一般如果根据create_time作为分区建,由于create_time需要成为主键的一部分,我们可以创建一个复合主键,包含原有的id和create_time字段。
ALTER TABLE original_table_name DROP PRIMARY KEY
add original_table_name ADD PRIMARY KEY (id, create_time);
如果数据量较大,可以考虑新建表的方式来处理。
步骤 3. 修改原始表以支持分区
需要确定分区策略,比如基于范围、列表、哈希或键进行分区。以下以范围分区为例。
ALTER TABLE original_table_name
PARTITION BY RANGE (YEAR(create_time)) (
PARTITION p0 VALUES LESS THAN (2022),
PARTITION p1 VALUES LESS THAN (2023),
PARTITION p2 VALUES LESS THAN (2024),
...
PARTITION pn VALUES LESS THAN MAXVALUE
);
步骤 4: 重建表以添加分区
接下来,我们需要创建一个新的分区表,并将数据从旧表迁移到新表。由于无法直接在当前表上添加分区,我们将创建一个新表,其结构与原表相似,但包含分区定义。
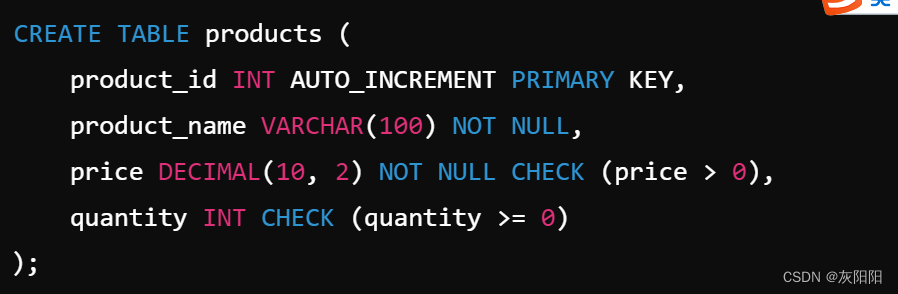
CREATE TABLE new_partitioned_table (
id INT NOT NULL,
name VARCHAR(50),
create_time TIMESTAMP NOT NULL,
PRIMARY KEY (id, create_time)
) ENGINE=InnoDB
PARTITION BY RANGE COLUMNS(create_time) (
PARTITION p0 VALUES LESS THAN ('2023-01-01'),
PARTITION p1 VALUES LESS THAN ('2023-02-01'),
PARTITION p2 VALUES LESS THAN ('2023-03-01'),
PARTITION future VALUES LESS THAN MAXVALUE
);
步骤 5: 迁移数据到新表
将数据从原始表迁移到新的分区表。
INSERT INTO new_partitioned_table (id, name, create_time) SELECT * FROM original_table_name ;
步骤 6: 验证数据迁移的完整性和准确性
确保所有数据都已正确迁移到新的分区表中,并且没有数据丢失或损坏。
SELECT COUNT(*) FROM original_table_name ; -- 记下这个数量
SELECT COUNT(*) FROM new_partitioned_table; -- 应该与前一个查询的结果相同
步骤 7: 重命名表(可选)
如果希望新的分区表替代原来的表,可以先删除原表,然后将新表重命名为原表的名称。
DROP TABLE original_table_name ;
RENAME TABLE new_partitioned_table TO original_table_name ;
步骤 8: 测试和监控
在应用程序中测试新的分区表以确保其正常工作。监控性能以确保分区提高了查询效率,并定期检查分区的使用情况,以便根据需要调整分区策略。
步骤 9:创建分区管理存储过程
DELIMITER //
CREATE PROCEDURE CreateNextMonthPartition()
BEGIN
DECLARE v_next_month DATE;
DECLARE v_partition_name VARCHAR(255);
DECLARE v_alter_sql TEXT;
DECLARE v_last_partition_name VARCHAR(255);
DECLARE v_last_partition_values VARCHAR(255);
-- 获取下个月的第一天
SET v_next_month = DATE_FORMAT(DATE_ADD(NOW(), INTERVAL 1 MONTH), '%Y-%m-01');
-- 生成新分区的名称
SET v_partition_name = CONCAT('p', DATE_FORMAT(v_next_month, '%Y%m'));
-- 获取最后一个分区的名称和值,以便在ALTER TABLE语句中使用
SELECT
PARTITION_NAME,
PARTITION_DESCRIPTION
INTO
v_last_partition_name,
v_last_partition_values
FROM
INFORMATION_SCHEMA.PARTITIONS
WHERE
TABLE_NAME = 'new_table' AND
TABLE_SCHEMA = DATABASE()
ORDER BY
PARTITION_ORDINAL_POSITION DESC
LIMIT 1;
-- 构建ALTER TABLE语句来添加新分区
SET v_alter_sql = CONCAT(
'ALTER TABLE new_partitioned_table REORGANIZE PARTITION ', v_last_partition_name,
' INTO (',
'PARTITION ', v_last_partition_name, ' VALUES LESS THAN (', v_last_partition_values, '),',
'PARTITION ', v_partition_name, ' VALUES LESS THAN (',
QUOTE(DATE_FORMAT(DATE_ADD(v_next_month, INTERVAL 1 MONTH), '%Y-%m-01')), ')',
'PARTITION future VALUES LESS THAN MAXVALUE)',
';'
);
-- 执行ALTER TABLE语句
PREPARE stmt FROM v_alter_sql;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
END //
DELIMITER ;
这个存储过程做了以下几件事情:
- 计算下一个月的第一天。
- 生成新分区的名称。
- 查询当前表的最后一个分区信息。
- 构建并执行一个
ALTER TABLE语句来重新组织最后一个分区,并添加新的分区。
假设new_partitioned_table已经有一个名为future的分区,其值是VALUES LESS THAN MAXVALUE。
注意事项
- 备份:在进行任何结构更改之前,请确保你已经备份了原始数据。
- 性能测试:在更改表结构后,建议进行性能测试以确保新的分区策略确实提高了性能。
- 兼容性:不是所有的MySQL存储引擎都支持分区。例如,MyISAM和InnoDB支持分区,但MEMORY和ARCHIVE等引擎可能不支持。确保你的存储引擎支持分区功能。
- 分区键选择:选择合适的分区键非常重要。通常,你应该选择一个经常用于查询条件、且数据分布均匀的字段作为分区键。
- 分区数量:分区数量不宜过多,否则可能会影响性能。同时,也不宜过少,否则可能达不到预期的性能提升效果。你需要根据实际情况进行权衡和调整。

![SpringMVC[从零开始]](https://img-blog.csdnimg.cn/direct/22aa08872ce84232a73fea506c7201b9.png)