论文:Communication-Efficient Learning of Deep Networks
from Decentralized Data
原code
Reproducing
通过阅读帖子进行的了解。
联邦平均算法就是最典型的平均算法之一。将每个客户端上的本地随机梯度下降和执行模型的平均服务器结合在一起。
联邦优化问题
-
数据非独立同分布
-
数据分布的不平衡性
-
用户规模大
-
通信有限
联邦平均算法
客户端与服务器之间的通信代价比较大,文中提出两种方法降低通信成本:
-
增加并行性
-
增加每个客户端计算量
首先提出FedSGD算法,本地执行多次FedSGD,得到FedAvg算法。
-
选择一定比例客户端参与训练,而不是全部,因为全部的会比客户端的收敛速度慢,模型精度低
-
该算法将计算量放在了本地客户端,服务器只用于聚合平均,可在平均步骤之前进行多次局部模型的更新,过多的本地迭代轮次会造成过拟合
代码复现
IID、Non-IID的含义:
-
数据独立同分布,IID,Independent Identically Distribution,数据之间不相互影响,满足同一个分布。
独立同分布数据,说明训练的样本点具有较好的总体代表性。
-
非独立同分布,Non-IID,Non-Independent Identically Distribution,实际场景数据很难满足IID的前提假设。
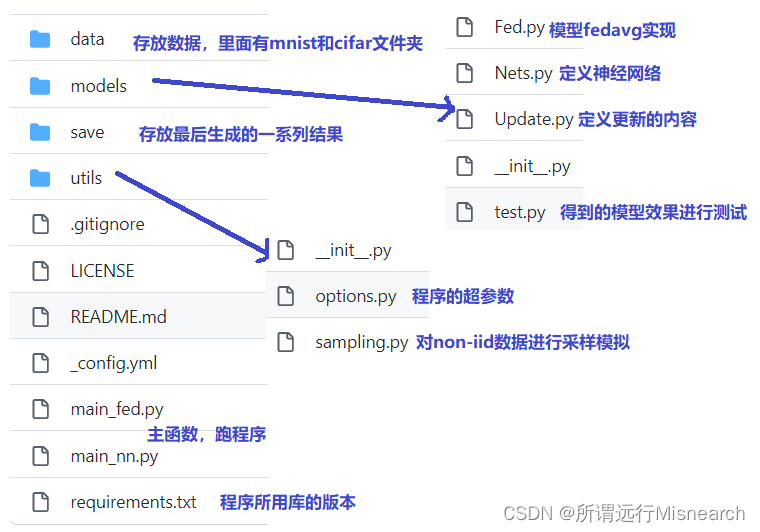
依照帖子对代码文件的介绍,如下图所示:
我的本地电脑:如下图所示:
Fed.py
关键原理:Fed.py中的权重平均聚合算法,
def FedAvg(w):
'''
:param w: 权重吗?是的,是包含多个用户端模型权重的列表,每个权重相当于一个字典,带有键值
:return:
'''
w_avg = copy.deepcopy(w[0]) # 利用深拷贝获取初始w[0]
for k in w_avg.keys(): # 遍历每个权重键
for i in range(1, len(w)):
w_avg[k] += w[i][k] # 累加
w_avg[k] = torch.div(w_avg[k], len(w)) # 平均
return w_avg
参考
【FedAvg论文笔记】&【代码复现】