认识Map集合
Map集合称为双列集合,格式:{key1=value,key2=value2,key3=value3,…},一次需要存一对数据作为一个元素。
Map集合的每个元素“Key=value” 称为一个键值对/键值对对象/一个Entry对象,Map集合也被叫做“键值对集合”
Map集合的所有键是不允许重复的,但值可以重复,键和值是一 一对应的,每一个键只能找到自己的对应值(Map集合的键不能重复,Map集合可以重复 )
Map集合体系
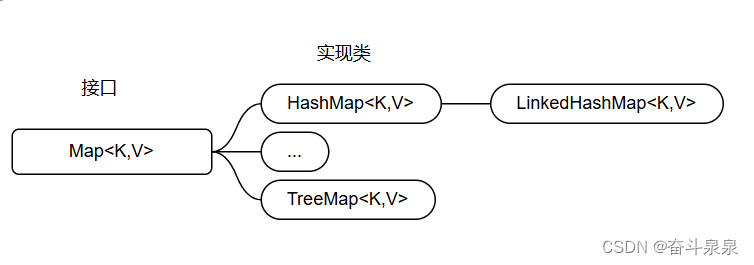
Map集合体系的特点
注意:Map系列集合的特点都是由键决定的,值只是一个附属品,值是不做要求的
HashMap(由键决定特点):无序、不重复、无索引(用的最多)
LinkedHashMap(由键决定特点):由键决定的特点:有序、不重复、无索引。
TreeMap(由键决定特点):按照大小默认升序排序、不重复、无索引。
public static void main(String []args)
{
Map<String ,Integer> map = new LinkedHashMap<>();
map.put("手表",100);
map.put("手表",200);
map.put("手机",2);
map.put("Java",2);
map.put(null,null);
System.out.println(map);
Map<Integer,String> map1 = new TreeMap(); //可排序、不重复、无索引
map1.put(23,"Java");
map1.put(23,"MySQL");
map1.put(19,"李四");
map1.put(20,"王五");
System.out.println(map1);
}
为什么要先学习Map的常用方法?
Map 是双列集合的祖宗,它的功能是全部双列集合都可以继承过来使用的。
public class MapTest2{
public static void main(String[] args)
{
//1、添加元素:无序、无重复、无索引
Map<String,Integer> map = new HashMap();
map.put("手表",100);
map.put("手表",220);
map.put("手机",2);
map.put(null,null);
System.out.println(map);
//map = {null=null,手表=220,Java=2,手机=2}
//2、public int size():获取集合的大小
System.out.println(map.size());
//3、public void clear();清空集合
map.clear();
System.out.println(map);
//4、public boolean isEmpty():判断集合是否为空,为空返回True,反之。
System.out.println(map.isEmpty());
//5、public V get(Object key) 根据键获取对应值
int v1 = map.get("手表");
System.out.println(v1);
System.out.println(map.get("手机"));
System.out.println(map.get("张三"));
//6、public V remove(Obejct key):根据键删除整个元素(删除键会返回的值)
System.out.println(map.remove("手表"));
System.out.println(map);
//7、public boolean containsKey(Object key):判断是否包含某个键,包含返回Ture,反之false
System.out.println(map.containsKey("手表"));
System.out.println(map.containsKey("手机"));
//8、public boolean containsValue(Object value):判断是否包含某个信息
System.out.println(map.containsValue(2));//true
System.out.println(map.containsValue("2"));//false
//9、public Set<k> keySet(): 获取Map集合的全部键
Set<String> keys = map.keySet();
System.out.println(keys);
//10、public Collection <V> values();获取Map集合的全部值
Collection<Integer> values = map.values();
System.out.println(values);
//11、把其它的Map集合的数据倒入到自己的集合中来
Map<String,Integer> map1 = new HashMap<>();
map1.put("java1",10);
map1.put("java2",20);
Map<String,Integer> map2 = new HashMap<>();
map2.put("java3",10);
map2.put("java2",222);
map1.putAll(map2);//putAll: 把Map2集合中的元素全部倒入一份到map集合
System.out.println(map1);
System.out.println(map2);
}
}
| 方法名称 | 说明 |
|---|---|
| public V put(K key,V value) | 添加元素 |
| public int size() | 获取集合大小 |
| public void clear() | 清空集合 |
| public void boolean isEmpty() | 判断集合是否为空,为空返回true,反之false |
| public V get(Object key) | 根据键获取对应值 |
| public V remove(Object key) | 根据键删除整个元素 |
| public boolean containsKey(Object key) | 判断是否包含某个键 |
| public boolean containsValue(Object value) | 判断是否包含某个值 |
| public Set keySet() | 全部键的集合 |
| public Collection values | 获取Map集合的全部值 |
Map集合的遍历方式
键值对
| Map提供的方法 | 说明 |
|---|---|
| Set<Map.Entry<K,V> entrySet() | 获取所有“键值对”的集合 |
public class MapTest2{
public static void main(String [] args)
{
Map<String,Double> map = new HashMap<>();
map.put("蜘蛛精",169.8);
map.put("紫霞",165.8);
map.put("至尊宝",169.5);
map.put("牛魔王",184.5);
System.out.println(map);
//1、调用Map集合提供的entrySet方法,把Map集合转换成键值对象类型的Set集合
Set<Map.Entry<String,Double>> entries = map.entrySet();
for(Map.Entry<String,Double> entry :entries)
{
String key = entry.getKey();
double valuel = entry.getValue();
System.out.println(key+"--=----->"+value);
}
}
}
Map 集合的遍历方式三:Lambda
需要用到Map的如下方法
| 方法名称 | 说明 |
|---|---|
| default void forEach(BiConsumer<? super k, ? super v> action) | 结合lambda遍历Map集合 |
public class MapTest2{
public static void main(String [] args)
{
Map<String,Double> map = new HashMap<>();
map.put("蜘蛛精",169.8);
map.put("紫霞",165.8);
map.put("至尊宝",169.5);
map.put("牛魔王",184.5);
System.out.println(map);
//map = {蜘蛛精=169.8,牛魔王=183.9,至尊宝=169.5,紫霞=165.8}
map.forEach(K,V)->{
System.out.println(k+"--->>"+v);
});
map.forEach(new BiConsumer<String,Double>(){
@Override
public void accept(String k ,Double v)
{
System.out.println(k+"----"+v);
}
});
HashMap集合的底层原理
HashMap跟HashSet的底层原理是一摸一样的,都是基于哈希表实现的。
实际上:原来学的Set系列集合的底层就是基于Map实现的,只是Set集合中的元素只要键数据,不要值数据
public HashSet()
{
map = new HashMap<>();
}
哈希表
JDK 8之前,哈希表 = 数组+链表
JDK 8开始,哈希表 = 数组+链表+红黑树
哈希表是一种增删改查数据,性能都较好的数据结构.
HashMap底层是基于哈希表实现的
HashMap集合是一种增删改查的数据,性能都比较好的集合
但是它无序,不能重复,没有索引支持的(由键决定特点)
HashMap的键依赖hashCode方法和equals方法保证键的唯一
如果键存储的是自定义类型对象,可以通过重写hashCode和equals方法,这样可以保证多个对象内容一样时,HashMap集合就能认为是重复的。
public class Test1HashMap{
public static void main(String[] args)
{
Map<Student,String> map = new HashMap();
map.put(new Student("蜘蛛精",25,168.5),"蚕丝洞");
map.put(new Student("蜘蛛精",25,168.5),"水帘洞");
map.put(new Student("至尊宝",23,163.5),"水帘洞");
map.put(new Student("牛魔王",28,183.5),"牛头山");
System.out.println(map);
}
}
LinkedHashMap 集合的原理
底层数据结构依然是基于哈希实现的,只是每个键值对元素又额外的多了一个双链表机制记录元素顺序(保证有序)
实际上:原来学习LinkedHashSet集合的底层原理就是LinkedHashMap
TreeMap
特点:不重复、无索引、可排序(按照键的大小默认升序排序,只能对键排序)
原理:TreeMap跟TreeSet集合的底层原理是一样的,都是基于红黑树实现的排序。
TreeMap集合也同样支持两种方式来指定排序规则
让类实现Comparable 接口,重写比较规则。
TreeMap集合也有一个参数构造器,支持创建Comparator比较器对象,以便用来指定比较规则。