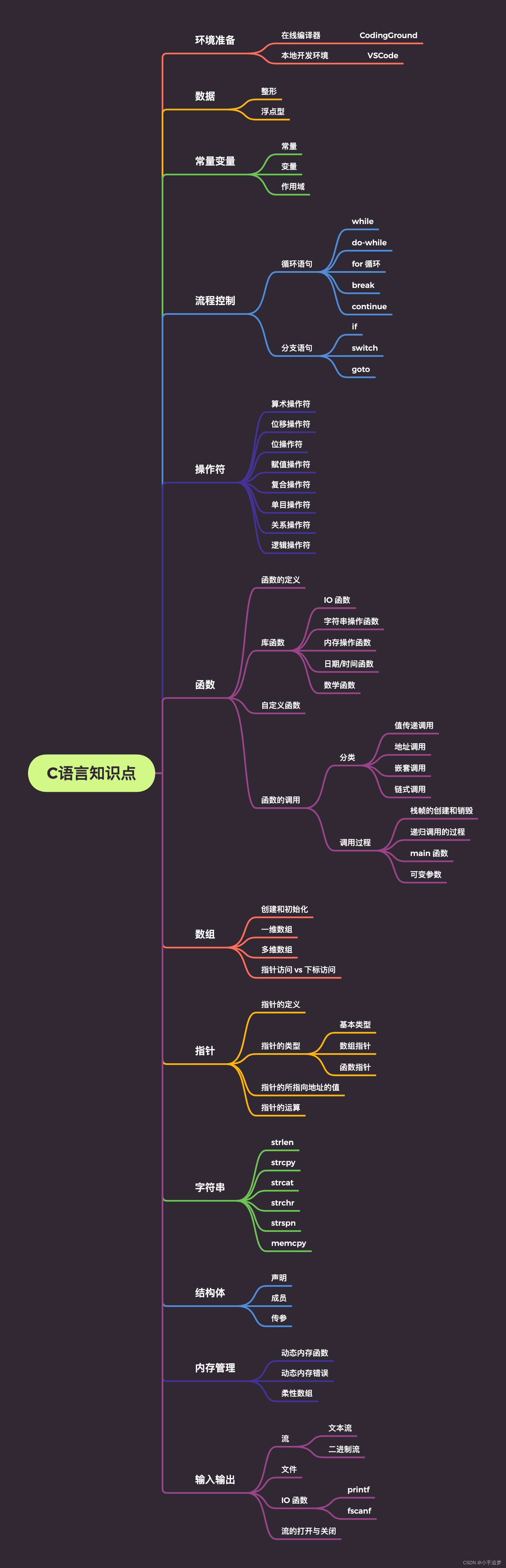
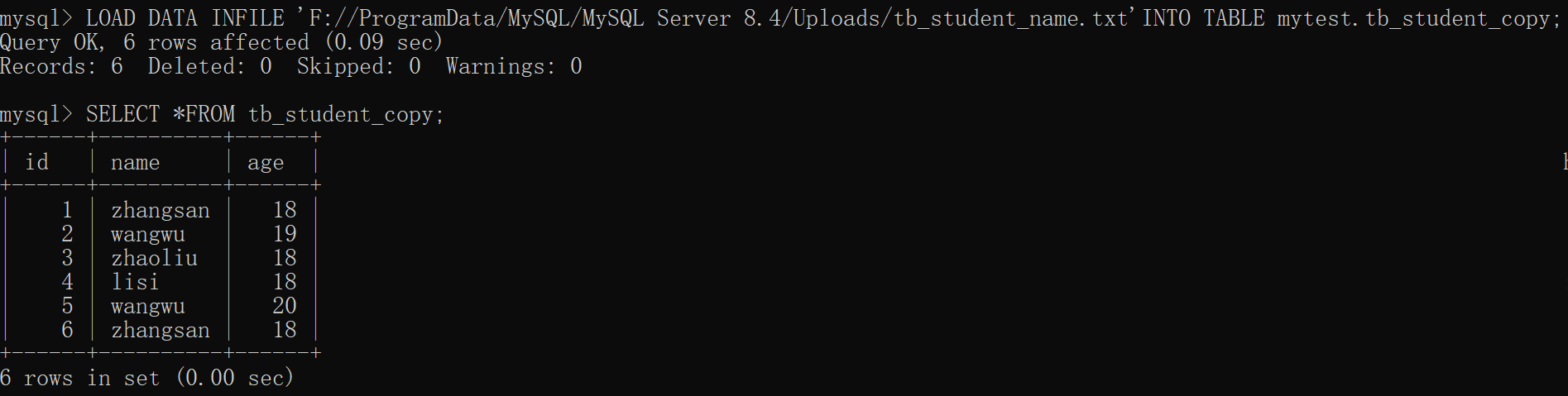
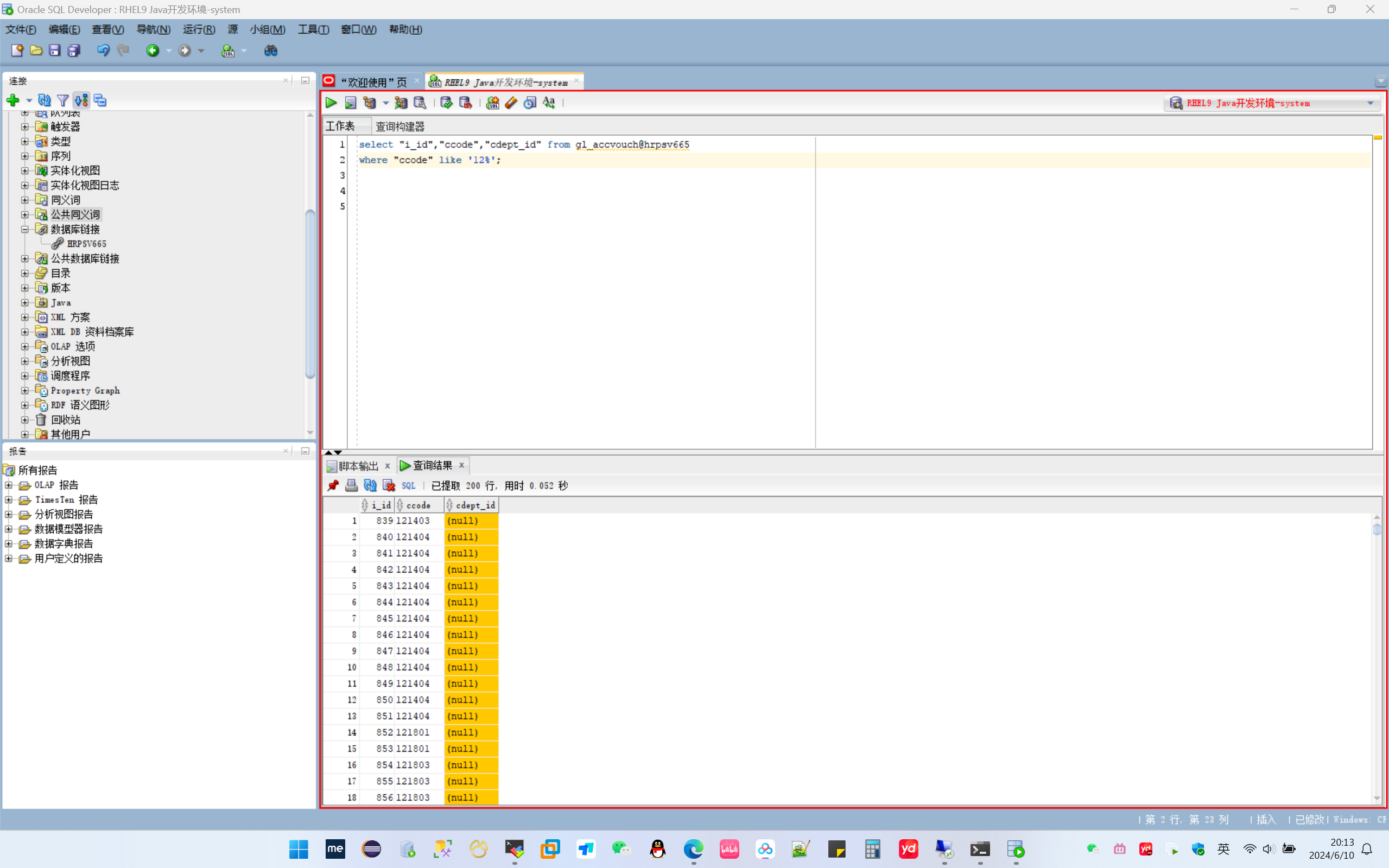
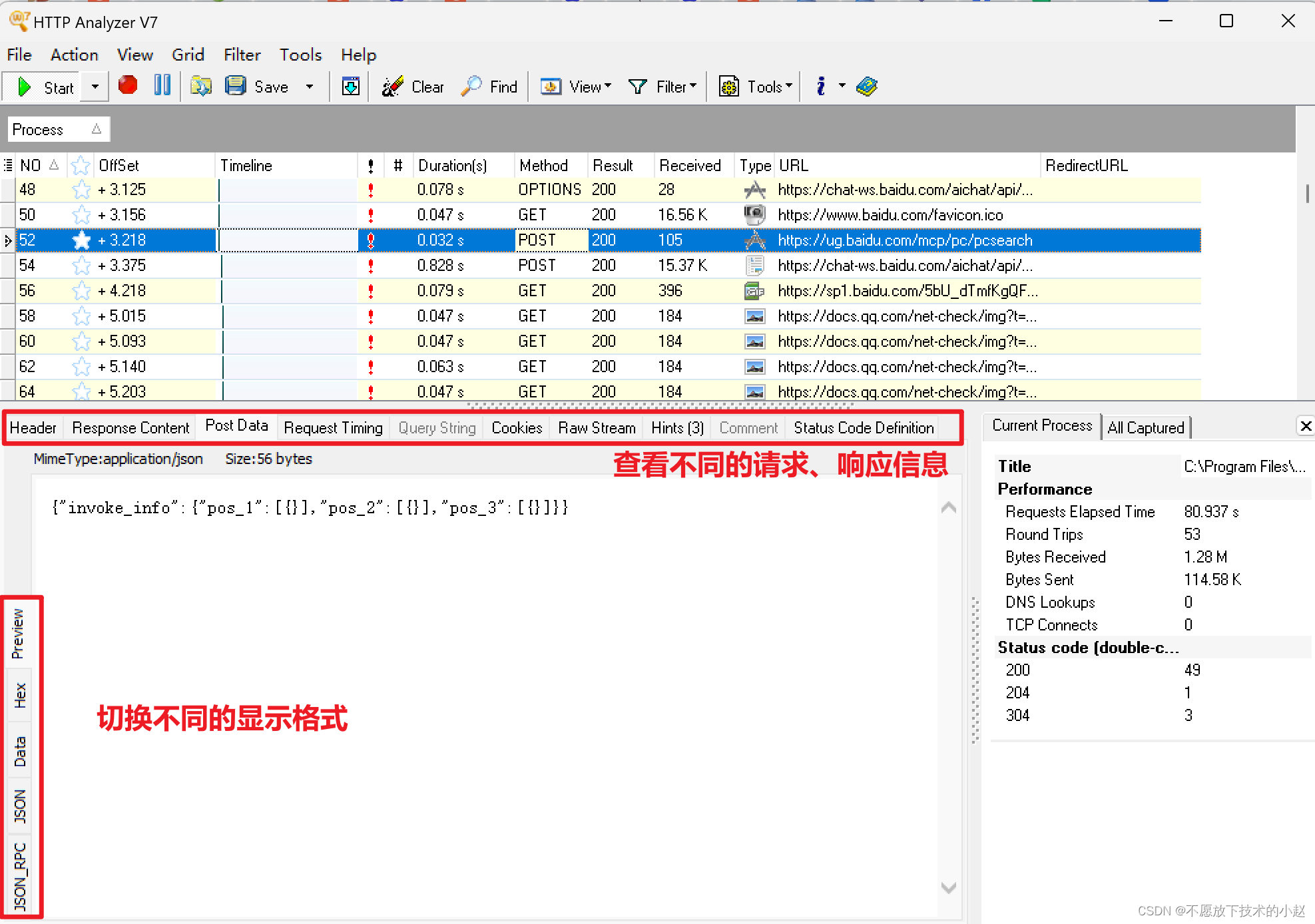
之前提到过Discount Return:
Action-value Function :
State-value Function:
(这里将action A积分掉)这里如果策略函数
很好,
就会很大;反之策略函数不好,
就会很小。
对于离散类型:
用神经网络近似策略
,
即 学习参数,使得
越来越大。这里使用梯度上升的方法,对于一个可观测状态s,更新
这里称为策略梯度(Policy Gradient)
之前提到过Discount Return:
Action-value Function :
State-value Function:
(这里将action A积分掉)这里如果策略函数
很好,
就会很大;反之策略函数不好,
就会很小。
对于离散类型:
用神经网络近似策略
,
即 学习参数,使得
越来越大。这里使用梯度上升的方法,对于一个可观测状态s,更新
这里称为策略梯度(Policy Gradient)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/1809133.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!