HBase高可用
考虑关于HBase集群的一个问题,在当前的HBase集群中,只有一个Master,一旦Master出现故障,将会导致HBase不再可用。所以,在实际的生产环境中,是非常有必要搭建一个高可用的HBase集群的。
HBase高可用简介
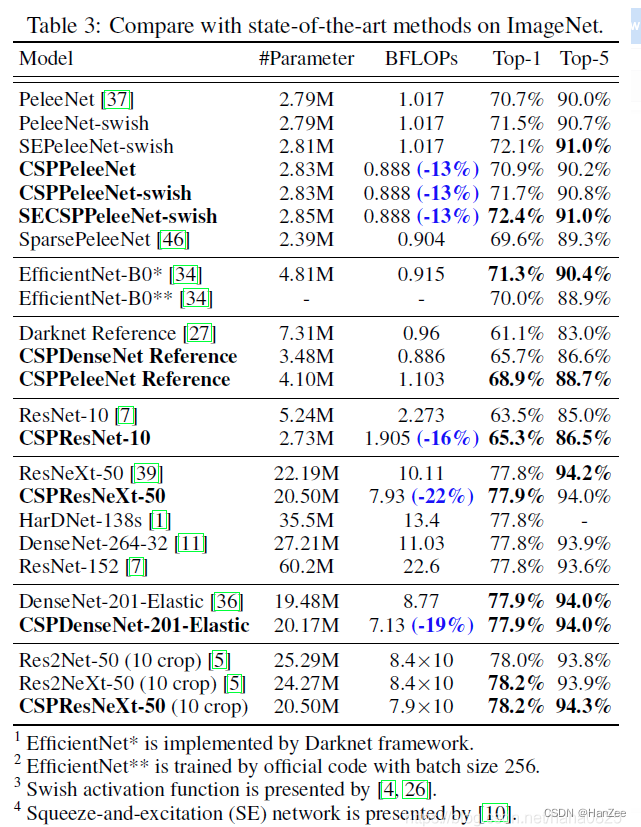
HBase的高可用配置其实就是HMaster的高可用。要搭建HBase的高可用,只需要再选择一个节点作为HMaster,在HBase的conf目录下创建文件backup-masters,然后再backup-masters添加备份Master的记录。一条记录代表一个backup master,可以在文件配置多个记录。
搭建HBase高可用
- 在hbase的conf文件夹中创建 backup-masters 文件
cd /export/server/hbase-2.1.0/conf
touch backup-masters
- 将node2.itcast.cn和node3.itcast.cn添加到该文件中
vim backup-masters
node2.itcast.cn
node3.itcast.cn
- 将backup-masters文件分发到所有的服务器节点中
scp backup-masters node2.itcast.cn:$PWD
scp backup-masters node3.itcast.cn:$PWD
- 重新启动hbase
stop-hbase.sh
start-hbase.sh
-
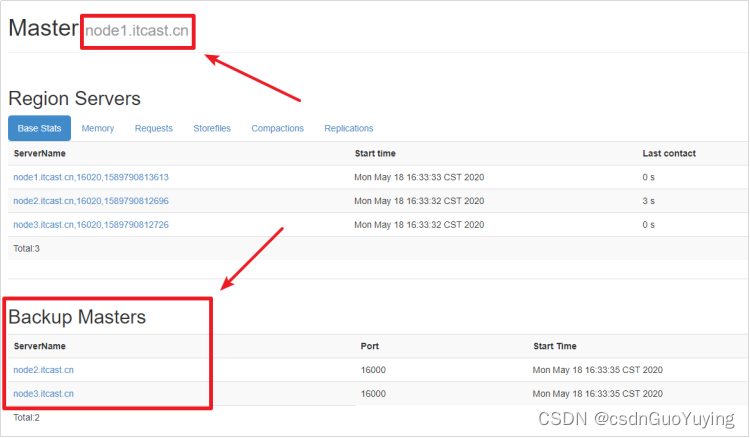
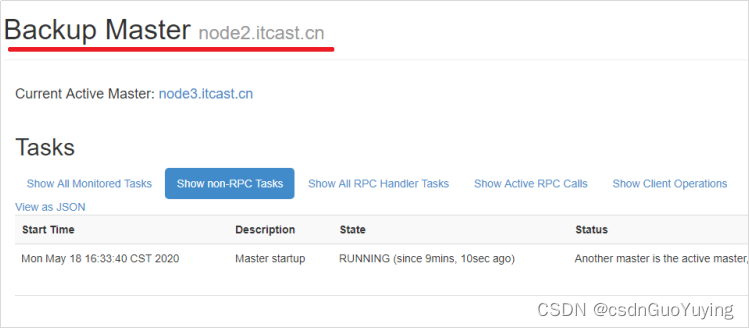
查看webui,检查Backup Masters中是否有node2.itcast.cn、node3.itcast.cn
http://node1.itcast.cn:16010/master-status
-
尝试杀掉node1.itcast.cn节点上的master
kill -9 HMaster进程id -
访问http://node2.itcast.cn:16010和http://node3.itcast.cn:16010,观察是否选举了新的Master
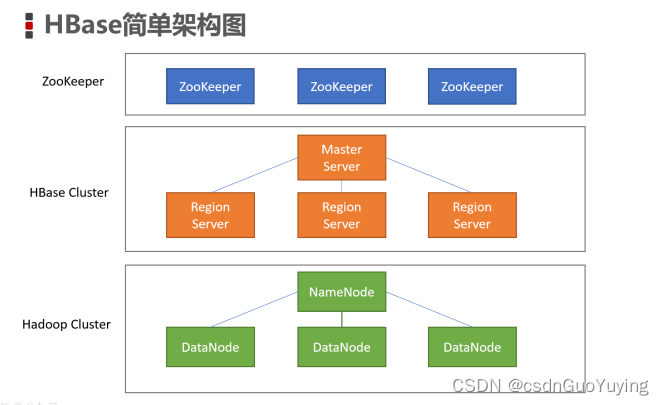
HBase架构
系统架构
-
Client
客户端,例如:发出HBase操作的请求。例如:之前我们编写的Java API代码、以及HBase shell,都是CLient -
Master Server
在HBase的Web UI中,可以查看到Master的位置。

监控RegionServer
处理RegionServer故障转移
处理元数据的变更
处理region的分配或移除
在空闲时间进行数据的负载均衡
通过Zookeeper发布自己的位置给客户端 -
Region Server

处理分配给它的Region
负责存储HBase的实际数据
刷新缓存到HDFS
维护HLog
执行压缩
负责处理Region分片RegionServer中包含了大量丰富的组件,如:Write-Ahead logs、HFile(StoreFile)、Store、MemStore、Region。
逻辑结构模型

-
Region
在HBASE中,表被划分为很多「Region」,并由Region Server提供服务

-
Store
Region按列蔟垂直划分为「Store」,存储在HDFS在文件中 -
MemStore
- MemStore与缓存内存类似
- 当往HBase中写入数据时,首先是写入到MemStore
- 每个列蔟将有一个MemStore
- 当MemStore存储快满的时候,整个数据将写入到HDFS中的HFile中
-
StoreFile
- 每当任何数据被写入HBASE时,首先要写入MemStore
- 当MemStore快满时,整个排序的key-value数据将被写入HDFS中的一个新的HFile中
- 写入HFile的操作是连续的,速度非常快
- 物理上存储的是HFile
-
WAL
WAL全称为Write Ahead Log,它最大的作用就是 故障恢复
WAL是HBase中提供的一种高并发、持久化的日志保存与回放机制
每个业务数据的写入操作(PUT/DELETE/INCR),都会保存在WAL中
一旦服务器崩溃,通过回放WAL,就可以实现恢复崩溃之前的数据
物理上存储是Hadoop的Sequence File
常见问题
Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster
- 找到
$HADOOP_HOME/etc/mapred-site.xml,增加以下配置
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
- 将配置文件分发到各个节点
- 重新启动YARN集群
Caused by: java.net.ConnectException: Call to node2.itcast.cn/192.168.88.101:16020 failed on connection exception: org.apache.hbase.thirdparty.io.netty.channel.ConnectTimeoutException: connection timed out: node2.itcast.cn/192.168.88.101:16020
无法连接到HBase,请检查HBase的Master是否正常启动
Starting namenodes on [localhost] ERROR: Attempting to launch hdfs namenode as root ,ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting launch.
解决办法:
是因为缺少用户定义造成的,所以分别编辑开始和关闭脚本
$ vim sbin/start-dfs.sh
$ vim sbin/stop-dfs.sh
在顶部空白处添加内容:
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
Starting resourcemanager ERROR: Attempting to launch yarn resourcemanager as root ERROR: but there is no YARN_RESOURCEMANAGER_USER defined. Aborting launch. Starting nodemanagers ERROR: Attempting to launch yarn nodemanager as root ERROR: but there is no YARN_NODEMANAGER_USER defined. Aborting launch.
vim sbin/start-yarn.sh
vim sbin/stop-yarn.sh
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
Exception in thread “main” java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$POSIX.stat
解决方案:
将 hadoop.dll 放到c:/windows/system32文件夹中,重启IDEA,重新运行程序