主页:114514的代码大冒险
qq:2188956112(欢迎小伙伴呀hi✿(。◕ᴗ◕。)✿ )
Gitee:庄嘉豪 (zhuang-jiahaoxxx) - Gitee.com
文章目录
目录
文章目录
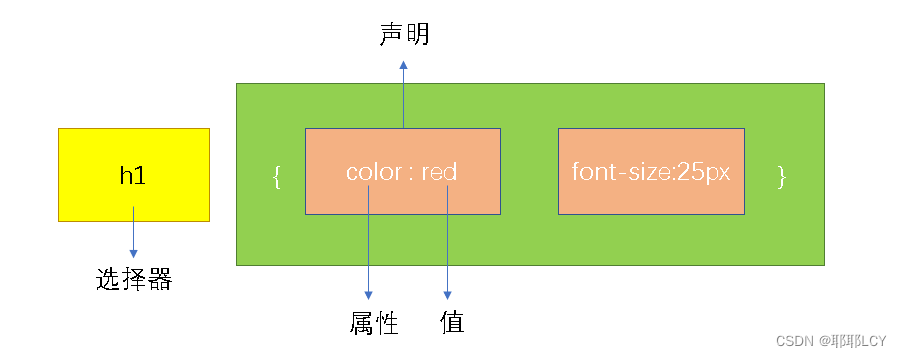
前言(链表的优势)
一、单链表是什么
二、单链表操作的具体代码实现
1.准备工作
2.打印链表
2.尾插(在链表末端添加数据)
3、头插(在链表首端添加数据)
4,创建新节点
5,尾删(在链表末端删除数据)
6,头删(在链表首部删除数据)
7,寻找目标数据
8,插入(在目标位置的前面插入)
9.插入(在目标位置的后面插入)
10.指定删除
11,销毁链表(释放内存)
总结

前言(链表的优势)
同样是线性存储结构(能用线串起来的结构),顺序表是连续的,而链表是离散的,
顺序表的内存申请是有多余消耗的,而链表是没有的(按需索取),
顺序表在插入与删除数据上的时间消耗是巨大的,而链表则是简易的
一、单链表是什么
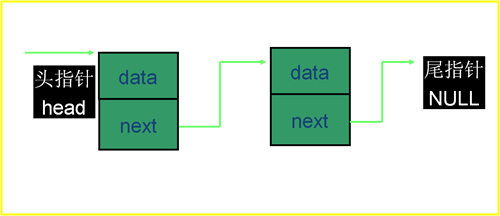
单链表:一种区别于顺序表的线性离散存储结构,节点的基本构成为数据和下一节点的地址,
首尾不相连,首节点没有前驱,尾节点没有后继,
概念图:

上图的箭头在实际中是不存在的,这只是为了方便我们去理解
物理图:
这里我们稍微分析一下这个结构,方便后续内容的理解,
图中的plist的意思是表头,它仅仅存储链表首节点的位置,于是我们就可以通过它得知首节点的地址,首节点存储了数据“1”和下一个节点的地址“0x0012FFB0”,第二第三节点以此类推
而尾节点的存储地址的位置存储了空指针,意味着链表的结束,这一个个节点地址的存储,使他们相互联系。
二、单链表操作的具体代码实现
1.准备工作
首先,依旧按照标准工程的标准,建立三个文件如下图所示: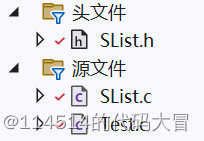 这里的“SLsit.h” 存放工程所用头文件以及接口函数的声明 “ SList.c” 调用接口进行功能测试 “Test.c ”进行接口的实现
这里的“SLsit.h” 存放工程所用头文件以及接口函数的声明 “ SList.c” 调用接口进行功能测试 “Test.c ”进行接口的实现
然后就是节点的实现(存储数据和下一节点的地址):
typedef int SLTDateType;
typedef struct SListNode
{
SLTDateType data;
struct SListNode* next;
}SLTNode;我们稍微分析一下,首先将数据类型定义成 SLTDateType 以至于可以以后便捷的改变数据类型
我们依旧是将这部分代码放于头文件中,
然后就是节点结构体的的创建,data存放数据,next被定义为与节点相同类型的指针(方便存储下一个节点的地址),用typedef将结构体的名字简化为:SLTNode
2.打印链表
我们先来点容易的,适应一下链表的结构:
void SListPrint(SLTNode* phead)
{
SLTNode* cur = phead;
while (cur != NULL)
{
printf("%d->", cur->data);
cur = cur->next;
}
printf("NULL\n");
}函数传参(Test.c 文件中):


这里的plist与phead指向同一个意思
这里需要好好说明的一点为“cur = cur->next”,我们直接上图,
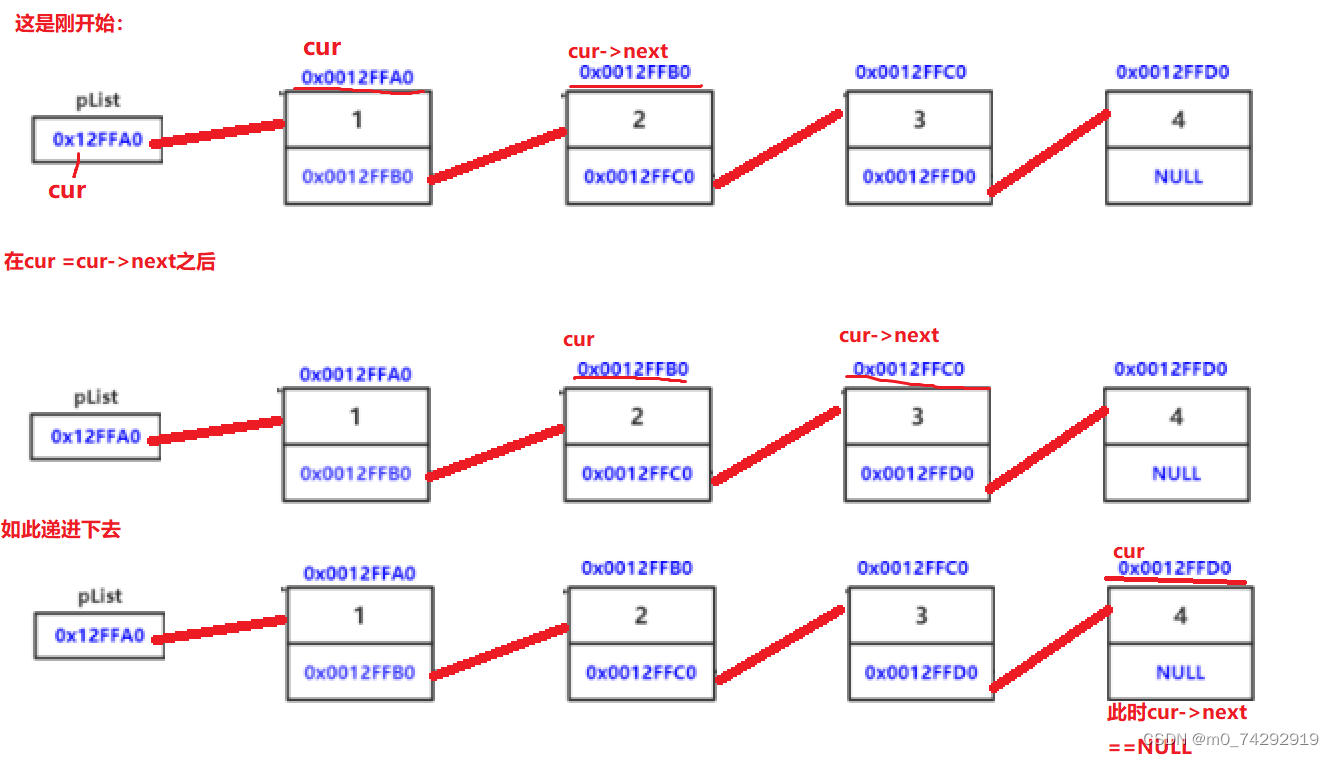
这个就是一个顺着头节点地址向下延伸的过程,这个图中cur与cur->next都分别代表着哪个地址
我也用了下划线(红)标明,相信同志们一定能看懂
2.尾插(在链表末端添加数据)
先在申请一节点大小的动态内存,然后分链表为空(头指针指向空指针)和链表不为空两种情况
我们下面来看一段代码:
void SListPushBack(SLTNode* phead, SLTDateType x)//尾插
{
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));
newnode->data = x;
newnode->next = NULL;
if (phead == NULL)
{
phead = newnode;
}
SLTNode* tail = phead;
while (tail->next != NULL)
{
tail = tail->next;
}
tail->next = newnode;
}这个就是我们的一个大概思维实现,emmmm,但是这个接口其实是有问题的
这里我们要提到形参的改变不影响实参,

对照上文接口,我们要知道的是, 如果我们希望函数改变我们所传变量,那么就需要传它的地址
这里我们想改变的是头地址,它本身就是个地址,所以我们传参时,要传地址的地址

具体正确代码
如下图所示:
void SListPushBack(SLTNode** pphead, SLTDateType x)//尾插
{
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));
newnode->data = x;
newnode->next = NULL;//新节点的创建
//分情况
if (pphead == NULL)
{
*pphead = newnode;
}
SLTNode* tail = *pphead;
while (tail->next != NULL)
{
tail = tail->next;
}
tail->next = newnode;
}
3、头插(在链表首端添加数据)
代码:
void SListPushFront(SLTNode** pphead, SLTDateType x)
{
SLTNode* newnode = BuyListNode(x);//这是个创建新节点的函数
//为空指针时解释一下
newnode->next = *pphead;
*pphead = newnode;
}解释:

4,创建新节点
SLTNode* BuyListNode(SLTDateType x)
{
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));
//一兆合一百万字节
if (newnode == NULL)
{
printf("malloc fail\n");
exit(-1);
}
newnode->data = x;
newnode->next = NULL;
return newnode;
}这里因为插入数据都需要新节点,所以,我们将这一功能独立出来,这里没什么特别的,我们接着往下走。
5,尾删(在链表末端删除数据)
代码:
void SListPopBack(SLTNode** pphead, SLTDateType x)
{
//第一种办法
//SLTNode* prev = NULL;
//SLTNode* tail = *pphead;
//while (tail->next)
//{
// prev = tail;
// tail = tail->next;
//}
//free(tail);
//tail = NULL;
//prev->next = NULL;
//第二种办法
SLTNode* tail = *pphead;
while (tail->next->next)
{
tail = tail->next;
}
free(tail->next);
tail->next = NULL;
}两种办法,思路差不多,第一种办法prev代表上一节点,而第二种办法则省去了这种变量的创建
为什么要保留上一节点:
说道尾删,我们很容易想到就是把尾节点的内容置为空,但是这个时候倒数第二个节点的next
仍然指向尾节点,而尾节点已不存在,于是next就成了野指针,所以我们要保留倒数第二个节点,
将其next置为空
但是,这个代码仍然不是完善的,它没有考虑空链表和只用一个节点的链表(需单独处理)
以下为正确代码:
void SListPopBack(SLTNode** pphead, SLTDateType x)
{
if (*pphead == NULL)
{
return;
}
//assert(*pphead != NULL);
if ((*pphead)->next == NULL)
{
free(*pphead);
*pphead = NULL;
}
else
{
SLTNode* prev = NULL;
SLTNode* tail = *pphead;
while (tail->next)
{
prev = tail;
tail = tail->next;
}
free(tail);
tail = NULL;
prev->next = NULL;
}
//第二种办法
SLTNode* tail = *pphead;
while (tail->next->next)
{
tail = tail->next;
}
free(tail->next);
tail->next = NULL;
}6,头删(在链表首部删除数据)
代码:
void SListPopFront(SLTNode** pphead)
{
assert(*pphead != NULL);
SLTNode* next = (*pphead)->next;
free(*pphead);
*pphead = next;
}
图解:
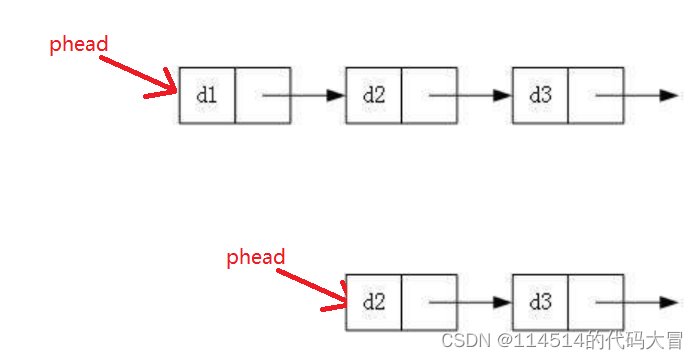
注意:
这里仍然要考虑链表为空的情况
处理办法有assert警告和if语句限制
//assert(*pphead != NULL);
if ((*pphead)->next == NULL)7,寻找目标数据
代码:
SLTNode* SListFind(SLTNode* phead, SLTDateType x)
{
SLTNode* cur = phead;
while (cur)
{
if (cur->data == x)
{
return cur;
}
else
{
cur = cur->next;
}
}
return NULL;
}
解释:
找到就返回地址,没找到就用“cur = cur->next”进行推进,直到走到链尾的空指针
8,插入(在目标位置的前面插入)
//在pos前面插入
//单链表不适合在pos前面插入
void SListInsert(SLTNode** pphead, SLTNode* pos, SLTDateType x)
{
SLTNode* newnode = BuyListNode(x);
// 找到pos的前一个位置
if (*pphead == pos)
{
newnode->next = *pphead;
*pphead = newnode;
}
else
{
SLTNode* posPrev = *pphead;
while (posPrev->next != pos)
{
posPrev = posPrev->next;
}
posPrev->next = newnode;
newnode->next = pos;
}
}
解释:
分为首节点即目标,和其他情况
但都是在找pos的前一个位置
找到后进行插入
图:
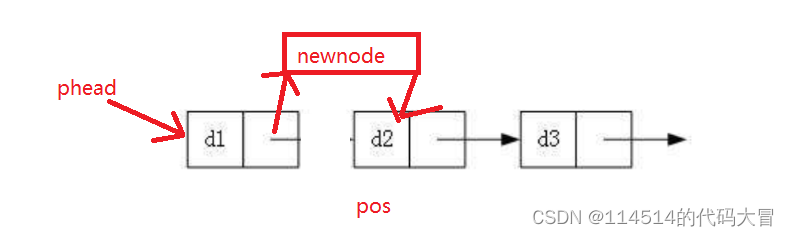
9.插入(在目标位置的后面插入)
代码:
void SListInsertAfter(SLTNode** pphead, SLTNode* pos, SLTDateType x)
{
SLTNode* newnode = BuyListNode(x);
newnode->next = pos->next;
pos->next = newnode;
}图解:
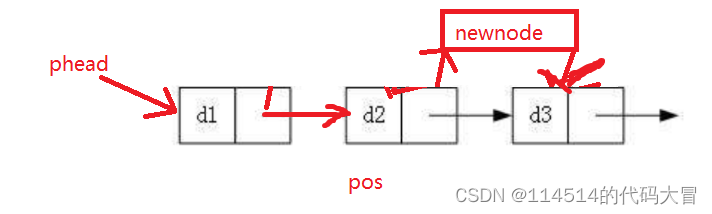 这个就比在pos前面插入要来的简单,时间复杂度更是从O(N)降到了O(1)
这个就比在pos前面插入要来的简单,时间复杂度更是从O(N)降到了O(1)
10.指定删除
删除指定位置的数据:
void SListEase(SLTNode** pphead, SLTNode* pos)
{
if (*pphead == pos)
{
/**pphead = pos->next;
free(pos);*/
SListPopFront(pphead);
}
else
{
SLTNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
prev->next = pos->next;
free(pos);
pos = NULL;
}
}
思路:
找到指定位置的前一个节点,然后进行删除操作,承继上文中的思想、、
删除指定节点的后一个节点
代码实现:
void SListEaseAfter(SLTNode* pos)
{
SLTNode* next = pos->next;
pos->next = next->next;//前一个next指的是节点,后一个next是节点内存储下一个节点的地址
free(next);
}
11,销毁链表(释放内存)
代码;
void SListDestory(SLTNode** pphead)
{
assert(pphead);
SLTNode* cur = *pphead;
while (cur)
{
SLTNode* next = cur->next;
free(cur);
cur = next;
}
*pphead = NULL;
}思路:

用cur保存当前位置,用next保存下一个位置 ,并利用它向下一个位置推进
而cur则用于 进行当前节点的内存释放
总结
这就是本次单链表的全部内容了,接下来就是双链表的学习,结束之后我们就正式进入数据结构初阶的内容学习了,这段内容还是要多多做题,多多画图,多多思考,不怕浪费时间的,我在单链表
上卡了很长一段时间,卡到怀疑自己是否应该放弃,


我也是看了很多老师的,很多个版本才慢慢有些理解这到底是怎么回事,当我明白时,真的犹如拨云见日,hhh, 当时真的是高兴,所以想着好好写一写,
希望能够帮助到和我同样陷入困境的小伙伴,hhh,如果这次的文章能够帮到你,
便是某人莫大的福分啦,冲冲冲
花在这一部分内容的时间会成为我们在IT行业扎根的巨大支撑。,冲啊!!