未来几年,同样的性能,推理功耗降低为现在的几万分之一,有可能吗
- 一.数据
- 二.抓取LLM排行榜,相同的MMLU精度,模型参数量缩减倍数
- 三.其它
有人说未来几年,推理功耗能降低为现在的几万分之一,好奇怎么能做到呢
一.数据
二.抓取LLM排行榜,相同的MMLU精度,模型参数量缩减倍数
import json
import numpy as np
import re
'''
数据下载地址:
https://open-llm-leaderboard-open-llm-leaderboard.hf.space/queue/data?session_hash=ejwnqwt0c3u
'''
with open("llm.json","r") as f:
data=json.load(f)
headers=data["output"]["data"][0]["headers"]
print(headers)
MMLU_index=headers.index("MMLU")
Params_index=headers.index("#Params (B)")
records=data["output"]["data"][0]["data"]
#过滤MMLU精度超过某个阈值的模型
mmlu_thresold=60.0
Params=[]
for idx,d in enumerate(records):
if d[MMLU_index]>=mmlu_thresold and d[Params_index]!=0:
Params.append((idx,d[Params_index],d[MMLU_index]))
#按参数量排序
Params.sort(key=lambda x: x[1])
href_pattern = re.compile(r'href="(.+?)"')
#提取参数量最小的模型链接
href = href_pattern.findall(records[Params[0][0]][1])[0]
print(Params[0],href)
#提取参数量最大的模型链接
href = href_pattern.findall(records[Params[-1][0]][1])[0]
print(Params[-1],href)
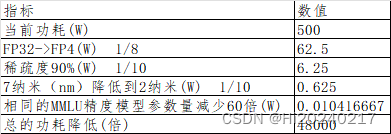
'''
输出
(1581, 3, 69.24) https://huggingface.co/MaziyarPanahi/Phi-3-mini-4k-instruct-v0.3 1个月前
(2587, 180, 64.6) https://huggingface.co/OpenBuddy/openbuddy-falcon-180b-v13-preview0 8个月前
相当于约半年模型参数量减少了60倍
'''
三.其它