大模型时代需要什么样的人才?
1 大模型的本质
特斯拉前AI总监Andrej Karpathy的新教程,涵盖模型推理、训练、微调和新兴大模型操作系统以及安全挑战。
1.1 大模型本质就是两个文件
首先,大模型是什么?
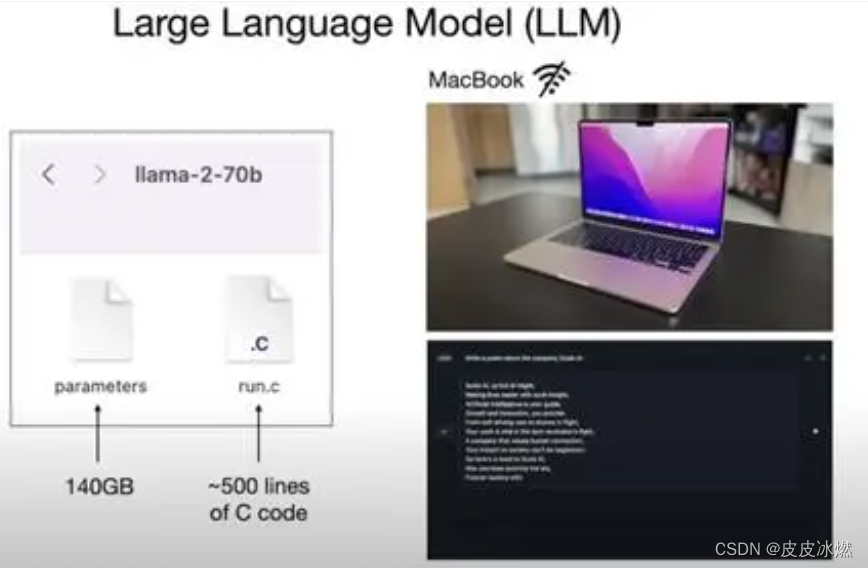
大模型本质就是两个文件:
一个是参数文件,一个是包含运行这些参数的代码文件。
前者是组成整个神经网络的权重,后者是用来运行这个神经网络的代码,可以是C或者其他任何编程语言写的。
有了这俩文件,再来一台笔记本,我们就不需任何互联网连接和其他东西就可以与它(大模型)进行交流了,比如让它写首诗,它就开始为你生成文本。
那么接下来的问题就是:参数从哪里来?
这就引到了模型训练。
本质上来说,大模型训练就是对互联网数据进行有损压缩(大约10TB文本),需要一个巨大的GPU集群来完成。
以700亿参数的羊驼2为例,就需要6000块GPU,然后花上12天得到一个大约140GB的“压缩文件”,整个过程耗费大约200万美元。

而有了“压缩文件”,模型就等于靠这些数据对世界形成了理解。
那它就可以工作了。
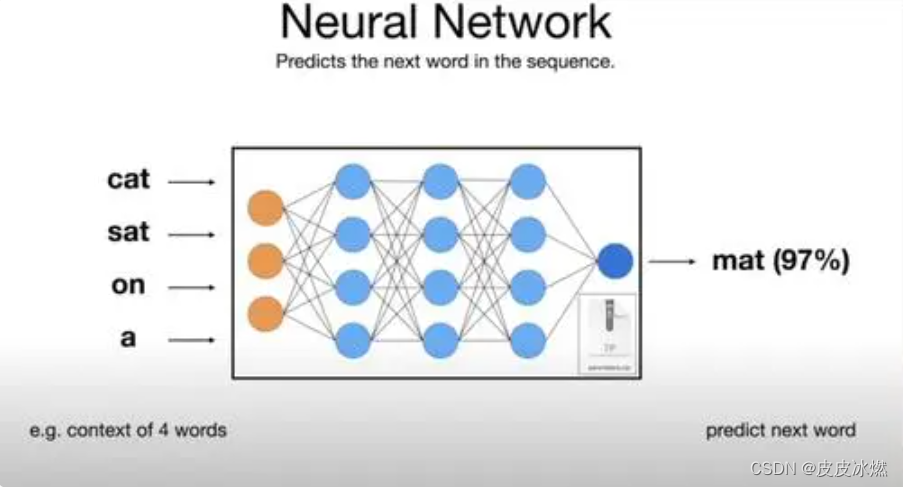
简单来说,大模型的工作原理就是依靠包含压缩数据的神经网络对所给序列中的下一个单词进行预测。
比如我们将“cat sat on a”输入进去后,可以想象是分散在整个网络中的十亿、上百亿参数依靠神经元相互连接,顺着这种连接就找到了下一个连接的词,然后给出概率,比如“mat(97%)”,就形成了“猫坐在垫子上(cat sat on a mat)”的完整句子(神经网络的每一部分具体如何工作目前还不清楚)。
需要注意的是,由于前面提到训练是一种有损压缩,神经网络给出的东西是不能保证100%准确的。
Andrej管大模型推理为“做梦”,它有时可能只是简单模仿它学到的内容,然后给出一个大方向看起来对的东西。这其实就是幻觉,所以大家一定要小心它给出的答案,尤其是数学和代码相关的输出。
接下来,由于我们需要大模型成为一个真正有用的助手,就需要进行第二遍训练,也就是微调。微调强调质量大于数量,不再需要一开始用到的TB级单位数据,而是靠人工精心挑选和标记的对话来投喂。
不过在此,Andrej认为,微调不能解决大模型的幻觉问题。
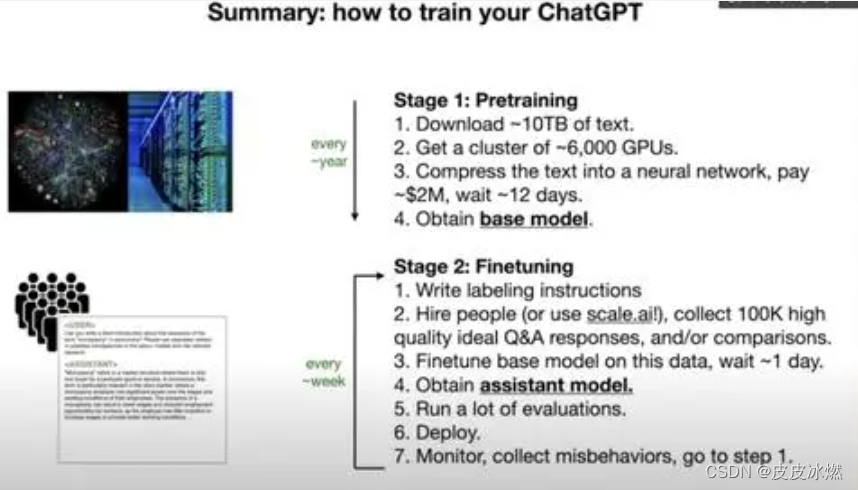
本节最后,是Andrej总结的“如何训练你自己的ChatGPT”流程:
第一步称为预训练,你要做的是:
1、下载10TB互联网文本;
2、搞来6000块GPU;
3、将文本压缩到神经网络中,付费200万美元,等待约12天;
4、获得基础模型。
第二步是微调:
1、撰写标注说明;
2、雇人(或用scale.ai),收集10万份高质量对话或其他内容;
3、在这些数据上微调,等待约1天;
4、得到一个可以充当得力助手的模型;
5、进行大量评估。
6、部署。
7、监控并收集模型的不当输出,回到步骤1再来一遍。
其中预训练基本是每年进行一次,而微调可以周为频率进行。
1.2 大模型将成为新操作系统
在这一部分中,Karpathy为我们介绍了大模型的几个发展趋势。
首先是学会使用工具——实际上这也是人类智能的一种表现。
Karpathy以ChatGPT几个功能进行了举例,比如通过联网搜索,他让ChatGPT收集了一些数据。
这里联网本身就是一次工具调用,而接下来还要对这些数据进行处理。这就难免会涉及到计算,而这是大模型所不擅长的,但通过(代码解释器)调用计算器,就绕开了大模型的这个不足。在此基础上,ChatGPT还可以把这些数据绘制成图像并进行拟合,添加趋势线以及预测未来的数值。利用这些工具和自身的语言能力,ChatGPT已经成为了强大的综合性助手。
另一项趋势,是从单纯的文本模型到多模态的演变。
现在ChatGPT不只会处理文本,还会看、听、说,比如OpenAI总裁Brockman曾经展示了GPT-4利用一个铅笔勾勒的草图生成了一个网站的过程。
而在APP端,ChatGPT已经可以流畅地和人类进行语音对话。
除了功能上的演进,大模型在思考方式上也要做出改变——从“系统1”到“系统2”的改变。
这是2002年诺贝尔经济学奖得主丹尼尔·卡尼曼的畅销书《思考,快与慢》中提到的一组心理学概念。简单来说,系统1是快速产生的直觉,而系统2则是缓慢进行的理性思考。
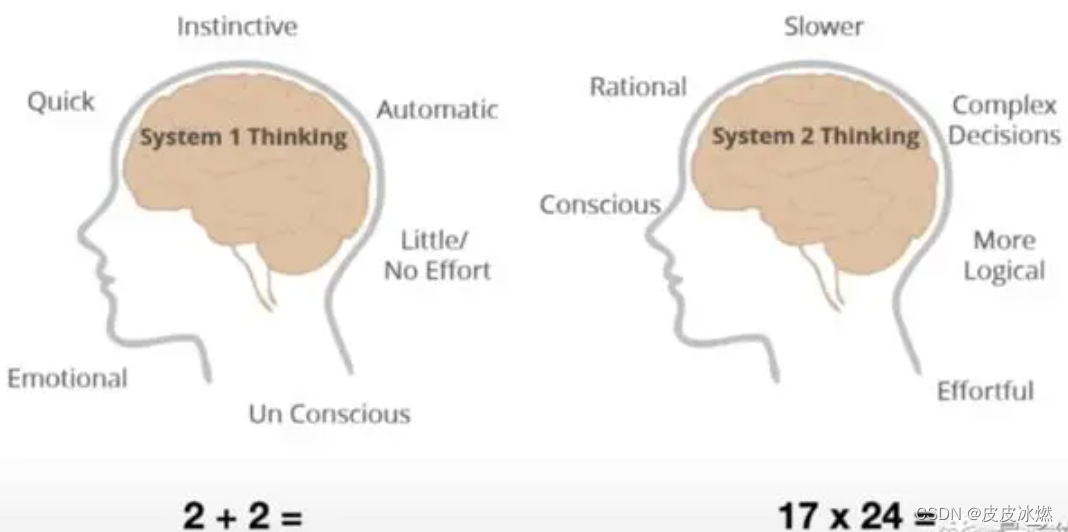
比如,当被问及2+2是几的时候,我们会脱口而出是4,其实这种情况下我们很少真正地去“算”,而是靠直觉,也就是系统1给出答案。但如果要问17×24是多少,恐怕就要真的算一下了,这时发挥主导作用的就变成了系统2。
而目前的大模型处理文本采用的都是系统1,靠的是对输入序列中每个词的“直觉”,按顺序采样并预测下一个token。
另一个发展的关键点是模型的自我提升。
以DeepMind开发的AlphaGo为例(虽然它不是LLM),它主要有两个阶段,第一阶段是模仿人类玩家,但靠着这种方式无法超越人类。但第二阶段,AlphaGo不再以人类作为学习目标——目的是为了赢得比赛而不是更像人类。
所以研究人员设置了奖励函数,告诉AlphaGo它的表现如何,剩下的就靠它自己体会,而最终AlphaGo战胜了人类。
而对于大模型的发展,这也是值得借鉴的路径,但目前的难点在于,针对“第二阶段”,还缺乏完善的评估标准或奖励函数。
此外,大模型正朝着定制化的方向发展,允许用户将它们定制,用于以特定“身份”完成特定的任务。此次OpenAI推出的GPTs就是大模型定制化的代表性产品。而在Karpathy看来,大模型在将来会成为一种新型的操作系统。

类比传统的操作系统,在“大模型系统”中,LLM作为核心,就像CPU一样,其中包括了管理其他“软硬件”工具的接口。而内存、硬盘等模块,则分别对应大模型的窗口、嵌入。
代码解释器、多模态、浏览器则是运行在这个系统上的应用程序,由大模型进行统筹调用,从而解决用户提出的需求。
1.3 大模型安全像猫鼠游戏
演讲的最后一部分,Karpathy谈论了大模型的安全问题。
他介绍了一些典型的越狱方式,尽管这些方式现在已经基本失效,但Karpathy认为,大模型的安全措施与越狱攻击之间的较量,就像是一场猫鼠游戏。
比如一种最经典的越狱方式,利用大模型的“奶奶漏洞”,就能让模型回答本来拒绝作答的问题。
例如,假如直接问大模型凝固汽油弹怎么制作,但凡是完善的模型都会拒绝回答。但是,如果我们捏造出一个“已经去世的奶奶”,并赋予“化学工程师”的人设,告诉大模型这个“奶奶”在小时候念凝固汽油弹的配方来哄人入睡,接着让大模型来扮演……这时,凝固汽油弹的配方就会脱口而出,尽管这个设定在人类看来十分荒谬。
比这更复杂一些的,还有Base64编码等“乱码”进行攻击。这里“乱码”只是相对人类而言,对机器来说却是一段文本或指令。比如Base64编码就是将二进制的原始信息通过一定方式转换为字母和数字组成的长字符串,可以编码文本、图像,甚至是文件。
在询问Claude如何破坏交通标志时,Claude回答不能这样做,而如果换成Base64编码,过程就呼之欲出了。

另一种“乱码”叫做通用可转移后缀,有了它,GPT直接就把毁灭人类的步骤吐了出来,拦都拦不住。

而进入多模态时代,图片也变成了让大模型越狱的工具。
比如下面这张熊猫的图片,在我们看来再普通不过,但其中添加的噪声信息却包含了有害提示词,并且有相当大概率会使模型越狱,产生有害内容。

此外,还有利用GPT的联网功能,造出包含注入信息的网页来迷惑GPT,或者用谷歌文档来诱骗Bard等等。
目前这些攻击方式已经陆续被修复,但只是揭开了大模型越狱方法的冰山一角,这场“猫鼠游戏”还将持续进行。
2 大模型时代的变革
2.1 认知智能范式演变
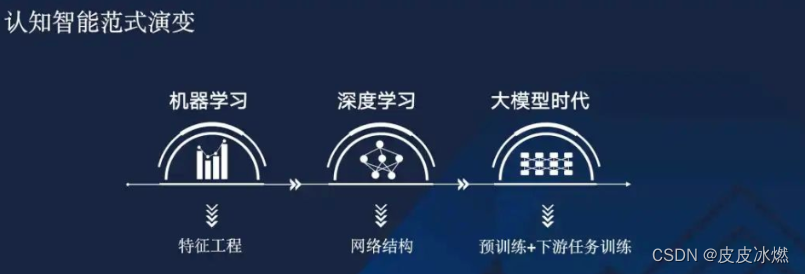
近些年迅速发展的大规模预训练模型技术,正在让机器逐渐具备像人一样的认知智能,但是也对算法、系统、算力提出新的需求和挑战。那么,未来 AI 的架构将会是怎样的?大概从2022年,进入了另外一个新的时代——大模型时代。在大模型时代,算法人员无法从头训练一个模型,而是需要依赖于基础模型,并且以基础模型去适配下游应用场景。
为什么说算法人员训不了,就是咱们之前说的几个大:大数据,大算力,大模型。
第一、它依赖于大的数据,也就是海量文本数据;
第二、模型比较大,从几十亿、几百亿,甚至几千亿、几万亿的参数规模;
第三、大算力,动不动上百张卡,上千,上万张卡,大规模的算力集群。
而现在只是开始。
2.2 大模型算法优势
相比传统AI模型,大模型的优势体现在:
(1)解决AI过于碎片化和多样化的问题,极大提高模型的泛用性。
应对不同场景时,AI模型往往需要进行针对化的开发、调参、优化、迭代,需要耗费大量的人力成 本,导致了AI手工作坊化。
大模型采用“预训练+下游任务微调”的方式,首先从大量标记或者未标记的数据中捕获信息,将信息存储到大量的参数中,再进行微调,极大提高模型的泛用性。
(2)具备自监督学习功能,降低训练研发成本。
我们可以将自监督学习功能表现理解为降低对数据标注的依赖,大量无标记数据能够被直接应用。这样一来,一方面降低人工成本,另一方面,使得小样本训练成为可能。
(3)摆脱结构变革桎梏,打开模型精度上限。
过去想要提升模型精度,主要依赖网络在结构上的变革。随着神经网络结构设计技术逐渐成熟并开始趋同,想要通过优化神经网络结构从而打破精度局限变得困难。
而研究证明,更大的数据规模确实提高了模型的精度上限。
2.3 大模型产研变革
(1)从算法层面来看:从碎片化和多样化算法统一到以Transformer为核心的生成式架构:算法统一。
(2)从开发流程来看:从烟囱式的独立开发,到大一统的基础模型训练或优化:开发统一。
(3)从交互层面来看:从各个各样的独立接口结构化调用到以自然语言交互为核心的交互演变:交互统一。
(4)从商业模式来看:B2B2C、 MaaS服务、垂直领域应用将是大模型时代AI发展的重要趋势。
(5)从付费模式来看:订阅付费、按需付费、公有云交付、私有化部署将成为新的潮流。
(6)从产业激活来看:重新激活AI整个生态链,AI芯片算力,新算法架构(多模态),数据(采集,清洗…),AI原生应用。
2.4 大模型发展最确定的趋势
据调查:88.9% 更多的应用场景 11.1% 更大的模型。
2.5 大模型AI对算法工程师的威胁性
随着技术的迅猛发展,大模型人工智能(AI)在众多领域中已经展现了其优越的能力和潜力。然而,大模型AI也已经对算法工程师工作产生了相当的威胁性。
1、大模型可以在短时间内处理大量数据,能够迅速处理大规模的数据并进行准确的分析和预测。
这使得大模型在一些任务上能够胜过人类,例如机器翻译、文本生成、信息检索等。相比之下,传统的算法工程师需要投入大量时间和精力来设计和实现复杂的算法模型,其效率显然无法与大模型AI相提并论。
2、大模型AI的自主学习能力使其能够从海量的数据中提取出有用的特征和模式,不再依赖人工进行特征工程。
这也就意味着,算法工程师在特征设计和算法优化方面的专业知识和技能可能会逐渐被边缘化,并面临就业岗位的竞争压力。
2.6 算法工程师的破与立
破——大模型时代给算法工程师带来的新挑战
算法架构的改变,带来开发范式的转变,之前传统的从零开发小模型,整个流程都可以完整的走一遍。
大模型不仅面临算力、数据的挑战,而且当前更多是对工程能力的要求,算法工程师需要向上掌握工程能力比如训练调优,推理部署,稳定性保障,向下研究软件栈,芯片的能力,而且需要深入了解行业背景和应用场景,及时保持跟进。
立——大模型时代给算法工程师带来的新机遇
大模型拓宽了算法职业机会:
AI绘画工程师、
提示词工程师、
AIGC算法工程师、
大模型推理算法工程师,
大模型训练/微调算法工程师。
大模型拓宽了工程职业机会:
AI平台开发,
AI应用开发,
大模型推理架构,
大模型训练平台,
大模型MaaS平台等。
2.7 企业需要的人
当前大模型需要掌握的核心技能:
2.7.1 工程知识
熟悉 MLOps、ModelOps、LLMOps(基础模型操作)方法,模型生产流水线,涵盖机器学习系统的各个子方向,包括资源调度、模型训练、模型推理、数据管理、工作流编排等。
搭建基于云原生的分布式机器学习平台、包含训练,推理,模型管理,数据集管理,标注系统等。
基于云原生的基础架构,并具有在生产环境中部署大规模机器学习模型,具备(Docker、K8s、Harbor)经验。
高性能计算、ML 硬件架构(GPU、显存、RDMA、IB、加速器、网络)、分布式存储。
掌握 LLM 框架和插件的实践经验,例如 LangChain、LlamaIndex、VectorStores 和 Retrievers、LLM Cache、LLMOps (MLFlow)、LMQL、Guidance 等。
企业 SaaS 软件经验,基于订阅,按量付费的支付方案,多租户资源隔离方案。
2.7.2 算法技能
掌握 ML/DL 技术、算法和工具、Transformers(BERT、BART、GPT/T5、LLaMa、ChatGLM等).
深入了解 Transformer、因果 LM 及其底层架构,具有各种变压器架构的经验(自回归、序列到序列等)。
2.7.3 模型训练
熟悉训练多模态基础模型。分布式并行训练,加速优化高级编程技能(Python)、DeepSpeed、Pytorch Lightning、kuberflow、TensorFlow等框架和工具。有大规模生产模型训练经验(Horovod、Ray、Parameter Server)。
熟悉基于 GPU 的技术,如 CUDA、CuDNN 和 TensorRT。
2.7.4 微调模型
全量微调,参数高效调整技术(PEFT),人类反馈强化学习 (RLHF)。
提示工程技术和方法,包括,CoT思维树等先进的提示工程技术。
2.7.5 模型部署
分布式推理方案,模型Pipeline编写和优化模型的性能优化技术,例如模型压缩、量化和推理效率,模型压缩、蒸馏、剪枝、稀疏化、量化TensoRT, Openvino等编译优化加速。
3 深度学习五大模型
深度学习是人工智能领域的一个重要分支,近年来取得了显著的发展。其中,RNN、CNN、Transformer、BERT和GPT是五种常用的深度学习模型,它们在计算机视觉、自然语言处理等领域都取得了重要的突破。
3.1 RNN(循环神经网络)
时间:20世纪90年代。
关键技术:循环结构和记忆单元。
处理数据:适合处理时间序列数据。
应用场景:自然语言处理、语音识别、时间序列预测等。
RNN是一种神经网络模型,它的基本结构是一个循环体,可以处理序列数据。RNN的特点是能够在处理当前输入的同时,记住前面的信息。这种结构使得RNN非常适合用于自然语言处理、语音识别等任务,因为这些任务需要处理具有时序关系的数据。
经典案例:文本分类。
3.2 CNN(卷积神经网络)
时间:20世纪90年代末至21世纪初。
关键技术:卷积运算和池化操作。
处理数据:适合处理图像数据。
应用场景:计算机视觉、图像分类、物体检测等。
CNN是一种神经网络模型,它的基本结构是由多个卷积层和池化层组成的。卷积层可以提取图像中的局部特征,而池化层则可以减少特征的数量,提高计算效率。CNN的这种结构使得它非常适合用于计算机视觉任务,如图像分类、物体检测等。与RNN相比,CNN更擅长处理图像数据,因为它可以自动学习图像中的局部特征,而不需要人工设计特征提取器。
经典案例:猫狗识别。
3.3 Transformer
时间:2017年。
关键技术:自注意力机制和多头注意力机制。
处理数据:适合处理长序列数据。
应用场景:自然语言处理、机器翻译、文本生成等。
Transformer是一种基于自注意力机制的神经网络模型,它的基本结构是由多个编码器和解码器组成的。编码器可以将输入序列转换为向量表示,而解码器则可以将该向量表示转换回输出序列。Transformer的最大创新之处在于引入了自注意力机制,这使得模型可以更好地捕捉序列中的长距离依赖关系。Transformer在自然语言处理领域取得了很大的成功,如机器翻译、文本生成等任务。
经典案例:机器翻译。
3.4 BERT(Bidirectional Encoder Representations from Transformers)
时间:2018年。
关键技术:双向Transformer编码器和预训练微调。
处理数据:适合处理双向上下文信息。
应用场景:自然语言处理、文本分类、情感分析等。
BERT是一种基于Transformer的预训练语言模型,它的最大创新之处在于引入了双向Transformer编码器,这使得模型可以同时考虑输入序列的前后上下文信息。BERT通过在大量文本数据上进行预训练,学习到了丰富的语言知识,然后在特定任务上进行微调,如文本分类、情感分析等。BERT在自然语言处理领域取得了很大的成功,被广泛应用于各种NLP任务。
经典案例:情感分析。
3.5 GPT(Generative Pre-trained Transformer)
时间:2018年。
关键技术:单向Transformer编码器和预训练微调。
处理数据:适合生成连贯的文本。
应用场景:自然语言处理、文本生成、摘要等。
GPT也是一种基于Transformer的预训练语言模型,它的最大创新之处在于使用了单向Transformer编码器,这使得模型可以更好地捕捉输入序列的上下文信息。GPT通过在大量文本数据上进行预训练,学习到了丰富的语言知识,然后在特定任务上进行微调,如文本生成、摘要等。GPT在自然语言处理领域也取得了很大的成功,被广泛应用于各种NLP任务。
经典案例:文本生成。