一、前言
iOS应用的包体积大小是衡量得物性能的重要指标,过大包体积会降低用户对应用的下载意愿,还会增加用户的下载等待时间以及用户手机的存储空间,本文重点介绍在包体积治理中的新思路以及原理与实践。
二、原理介绍
Macho产物测试
我们拿测试工程单独依赖一个组件,比如DemoModule,进行编译MarchO得出整合前的大小:58929120Byte。同时为了方便分析,我们也导出Linkmap.txt文件。
Linkmap文件中记录MachO文件中每个符号所占用的体积大小,因此通过分析Linkmap可以分析MachO具体符号占用变化,由于Linmap介绍不是本文重点,不多做赘述,更多详情可参考网上文章https://juejin.cn/post/6844904168096792583。
随后将组件工程中的文件编码整合10~20个,得出整合后MachO的大小:58894688Byte。(下图为编码前和编码后的MarchO占用磁盘大小)


LinkMap分析
整合后的文件变小了34K,我们继续分析产物导出的Linkmap,具体查看是哪里变小了。
- 通过对比Linkmap.txt发现:Text段减小10.6K、en_frame段减小了2K。
Linkmap.txt文件第一列展示的是符号的起始地址,第二列展示的是大小,16进制,将16进制转换为10进制,即是大小。相减得出变化大小。
__text段存储的机器编译后的代码。
en_frame存储了函数调用入口帧信息。具体查看https://refspecs.linuxfoundation.org/LSB_3.0.0/LSB-Core-generic/LSB-Core-generic/ehframechpt.html。
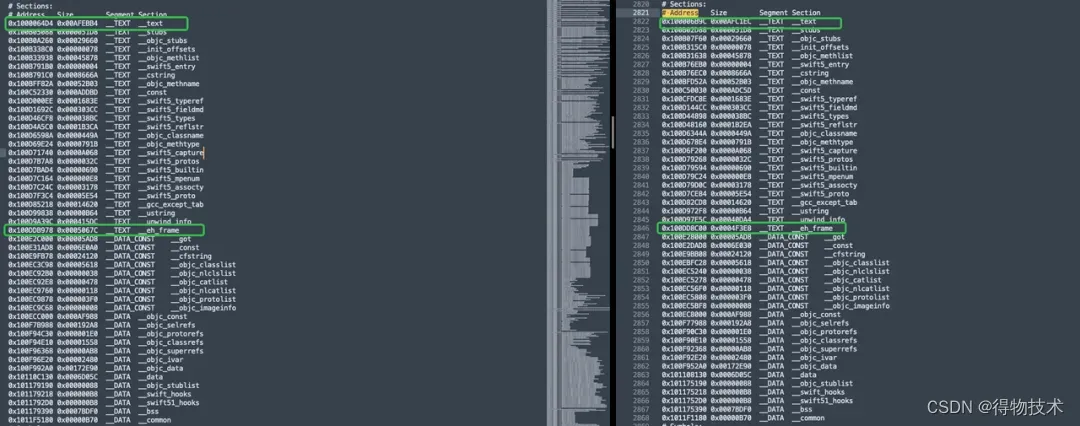
Linkmap符号变化
继续解析Linkmap每个组件的变化,我们发现,DemoModule组件减小15K、连接器自动生成符号的变化减小2K。

组建变化

链接符号变化
通过对Linkmap的分析,确实存储代码段和函数入口帧信息减小使得编译后的.o文件变小了,那么.o文件编码整合为DemoModule.a文件也随之变小了,那么到底是哪块代码变小了呢?我们继续往下分析。
Mach-o代码内容分析
通过上面Linkmap的分析,我们知道了是代码段以及函数调用符号占用的体积变小了,我们通过objcdump将MarchO符号进行导出。
objdump --macho -d --start-address=0x10025FDD0 --stop-address=0x100257668 ~/Desktop/IPATestProj > ~/Desktop/result.txt
objdump --macho -d --start-address=0x10025FDD0 --stop-address=0x100257668 ~/Desktop/IPATestProj-after > ~/Desktop/result-after.txt对比发现
针对s13DemoModule0A29TSearchHotRecommendDemoModuleCACycfC优化了28Byte。
allocWithZone以及objc的init方法。调用了DemoModule0A21FollowBrandDemoModuleCACycfC, DemoModule0A21FollowBrandDemoModuleCACycfC 调用了s13DemoModule0A17PaySendDemoModuleCACycfC,s13DemoModule0A17PaySendDemoModuleCACycfC里实现了alloc with zone和init方法。也就是说编译器优化了经过编码的alloc with zone方法,只会有一个alloc with zone 的实现。
针对s13DemoModule0A29TSearchHotRecommendDemoModuleCMr
DemoModule.ExampleModule.__deallocating_deinit优化了32Byte
优化了meta的deinit与寻找metaclass的过程。s13DemoModule0A29DemoModuleCMa调用了s13DemoModule0A31tDemoModuleCMaTm - ,而 和SearchDemoModule同时继承了CustomRequestDemoModule。
Alloc with zone前后对比
- 整合编码之前的逆向机器码
_$s13DemoModule0A29TSearchHotRecommendDemoModuleCACycfC:
1002fe8c8: fd 7b bf a9 stp x29, x30, [sp, #-16]!
1002fe8cc: fd 03 00 91 mov x29, sp
1002fe8d0: e0 03 14 aa mov x0, x20
1002fe8d4: 3d 2a 20 94 bl 0x100b091c8 ; symbol stub for: _objc_allocWithZone
1002fe8d8: 28 64 00 b0 adrp x8, 3205 ; 0x100f83000
1002fe8dc: 01 79 44 f9 ldr x1, [x8, #2288] ; Objc selector ref: init
1002fe8e0: fd 7b c1 a8 ldp x29, x30, [sp], #16
1002fe8e4: 7b 2a 20 14 b 0x100b092d0 ; Objc message: -[x0 init]
_$s13DemoModule0A29TSearchHotRecommendDemoModuleCACycfc- 整合编码之后的逆向机器码
1002577a0: b2 ff ff 97 bl _$s13DemoModule0A29TSearchHotRecommendDemoModuleCACycfc
1002577a4: fd 7b 41 a9 ldp x29, x30, [sp, #16]
1002577a8: f4 4f c2 a8 ldp x20, x19, [sp], #32
1002577ac: c0 03 5f d6 ret
_$s13DemoModule0A29TSearchHotRecommendDemoModuleCfD:
1002577b0: 60 fe ff 10 adr x0, #-52
1002577b4: 1f 20 03 d5 nop
1002577b8: f2 fd ff 17 b _$s13DemoModule0A31IdentComTrendDelLightDemoModuleCfDTm
_$s13DemoModule0A26TMeasureRecordAiUpdateSkinCACycfc:- Deinit前后对比-整合编码之前
_$s13DemoModule0A29TSearchHotRecommendDemoModuleCMa:
1002fe9fc: fd 7b bf a9 stp x29, x30, [sp, #-16]!
1002fea00: e8 03 00 aa mov x8, x0
1002fea04: 89 71 00 b0 adrp x9, 3633 ; 0x10112f000
1002fea08: 20 7d 40 f9 ldr x0, [x9, #248]
1002fea0c: 80 00 00 b4 cbz x0, 0x1002fea1c
1002fea10: 01 00 80 d2 mov x1, #0
1002fea14: fd 7b c1 a8 ldp x29, x30, [sp], #16
1002fea18: c0 03 5f d6 ret
1002fea1c: 41 4c 00 90 adrp x1, 2440 ; 0x100c86000
1002fea20: 21 80 24 91 add x1, x1, #2336
1002fea24: e0 03 08 aa mov x0, x8
1002fea28: f7 2c 20 94 bl 0x100b09e04 ; symbol stub for: _swift_getSingletonMetadata
1002fea2c: fd 7b c1 a8 ldp x29, x30, [sp], #16
1002fea30: c0 03 5f d6 ret- Deinit前后对比-整合编码之后
0x10025777C 0x00000014 [583] _$s13DemoModule0A29TSearchHotRecommendDemoModuleCMa由此可以得出结论。
- 编译器针对不同的Class,经过编码整合后,编译时会触发编译优化,alloc with zone、deinit寻找metaclass方法。将文件编码后整合会优化为一个。
- 同时相关的寻址和寄存器的addr,以及mov、内存地址的存储已随之删除,具体对比结果可以看上面的产物对比。
三、落地实践
经过上文的原理探究,整合一个组件有34K的收益,得物全工程是一个由1100+组件组成的Swift工程,那么我们基于组件的维度,将1100+组件做整合,那么就能拿到收益了,为了做到文件编码整合,拿到收益,我们需要在稳定性的基础上做到如下的目标。
- 需要满足线上包、灰度包、测试包等所有CI流程出的包都是文件编码整合后的包,并且需要保证相同的版本,文件编码整合的一致性。
- 得物工程的组件化CI是使用Cocoapods来实现的,因此需要改造Cocoapods 的download流程,将文件编码整合嵌入到所有的发版与打包的CI中。
- 为了满足大家的正常使用,需要为pod定制命令,比如--megre-file --clean-sanbox,正常开发默认命令不生效,为打包机等CI任务配置命令,做到开发无感知,发版无缝整合。
- 需要判断整个工程盘点出可能存在的风险点,并在整合前做改造,盘点出主要的改造点:
-
- 项目中存在同名的public或者open声明的extension方法,之前存在于不同的文件编码中,不会造成编译报错,经过编码后之后会出现大量的编译报错,整合后通过编译器去识别项目中同名的方法,在改造发版,每次改造编译源码都需要大量的时间,这显然是不现实的,因此我们需要通过indexstore-db与 SwiftSytax将项目中所有的同名extension方法做识别统一改造,并一次性的编译
- 项目中存在已#fileID、#file、#line方法与业务耦合,做调用位置判断,由于文件编码整合行号与,打包时的文件名都发生的变化,因此我们也需要通过SwiftSytax将所有方法导出,并做甄别改造。
- 需要分节奏,分版本,做好充分的灰度测试,灰度上线逐步拿到收益。
-
- 为了做到组件分版本灰度,需要为cocoapod bin pod命令增加版本的概念,为每个上线的组件配置好版本号,满足配置的组件在执行整合,不满足的组件走原有download流程。
如何满足上述3项目标,下面为大家逐一介绍。
Cocoapods原理与实践
介绍流程:当我们执行pod install时,会在你的电脑发生如下步骤。
1. 执行pod install时会进入到本机电脑的/usr/local/bin/pod我们发现是一个快捷方式。

2. 右键点击显示原项目,我们就进入到了真正的执行指令的入口目录。

由于笔者的pod是使用homebrew装的,因此pod可执行文件在homebrew的安装目录: /opt/homebrew/Cellar,这个pod文件本质是个bash sh文件,咱们将文件已编辑器打开有如下的内容。
GEM_HOME="/opt/homebrew/Cellar/ruby环境根目录" exec "/opt/homebrew/Cellar/真实的cocoapods目录/bin/pod" "$@"继续打开后面的执行文件,发现这个pod文件就是cocoapods安装文件下的pod,pod是一个ruby文件,也就是cocoapods最终的命令入口,内容如下:
#!/usr/bin/env ruby
require 'rubygems'
if Gem.respond_to?(:activate_bin_path)
load Gem.activate_bin_path('cocoapods', 'pod', version)
else
gem "cocoapods", version
load Gem.bin_path("cocoapods", "pod", version)
end3. 随后就进入到了cocoapods的cocoapods/cocoapods.rb,cocoapods.rb引入了 核心类,比如:
Xcodeproj::PlainInformative.send(:include, CLAide::InformativeError)
autoload :Command, 'cocoapods/command' # 命令行入口
autoload :ExternalSources, 'cocoapods/external_sources' # git 依赖,本地依赖处理类
autoload :Installer, 'cocoapods/installer' # pod install核心 类cocoapods/command是一个基类,每个命令pod install、pod update、pod repo add都会有相应command重写。可查看下面的截图:

4. 我们单纯拿pod install看文件里的内容。就知道我们如何给pod命令传递参数了。
- 从文件内容可以看到class Install继承了 Command,def initialize中定义需要传递的参数其中clean_install就是我们常用pod install --clean-install命令。
- def run函数进入了install的流程,下面也为大家简单注释了每个函数的作用。
def initialize(argv)
super
@deployment = argv.flag?('deployment', false)
@clean_install = argv.flag?('clean-install', false)
end
def run
verify_podfile_exists! # 校验 工程目录Podfile 文件是否存在
installer = installer_for_config # 根据config 生成 installer
installer.repo_update = repo_update?(:default => false) # 配置是否需要更新索引库
installer.update = false # 由于是install 因此 update 是false
installer.deployment = @deployment
installer.clean_install = @clean_install
installer.install! # 进入真正的install 流程
end那installer.install里面做了什么呢?我们继续往下看:
5.下面是installer.install的源码,我们可以简单将install分为以下步骤:
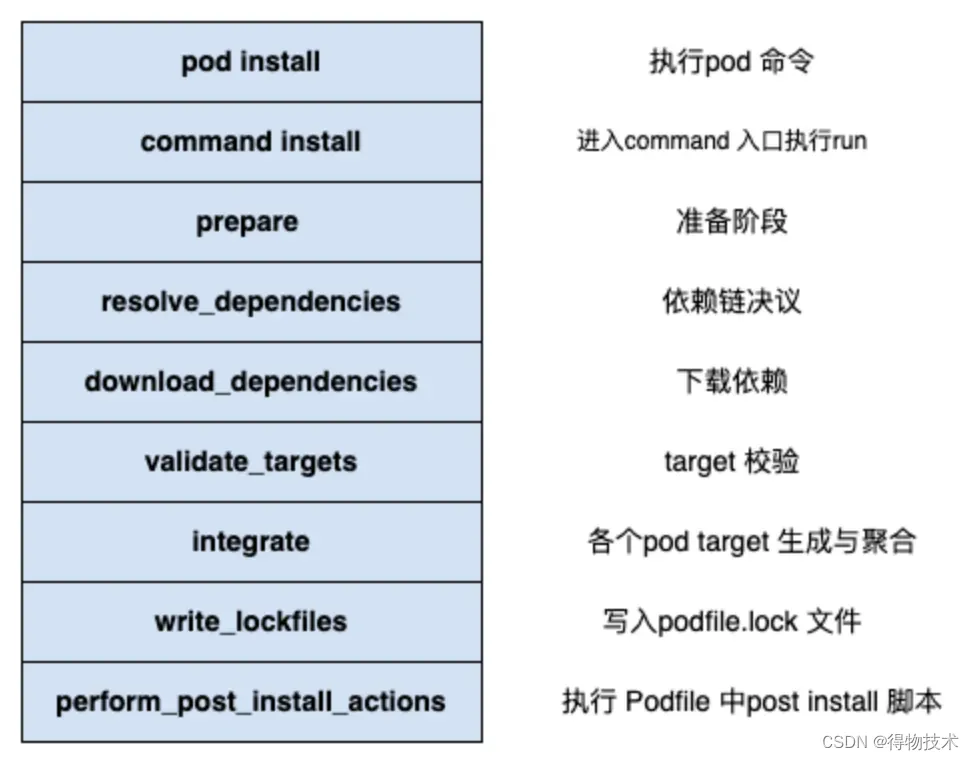
# install 源代码
def install!
prepare
resolve_dependencies # 依赖链分析
download_dependencies #
validate_targets
clean_sandbox
if installation_options.skip_pods_project_generation?
show_skip_pods_project_generation_message
run_podfile_post_install_hooks
else
integrate
end
write_lockfiles
perform_post_install_actions
end- resolve_sependencies会更新索引库,得到pods target对应的数据,得到aggregate target对应的数组,并提前加载git依赖与本地依赖的组件。为下载pod依赖做环境准备。
1. 为了能将:git、:branch、:commit依赖与本地:path依赖做代码编码并整合,我们需要再resolve_dependencies中加载git依赖与本地依赖阶段时做hook,满足本地依赖与git依赖组件集成时做代码编码整合。
2. 为了能对正常pod"Example"组件做整合,我们需要再download_dependencies中对组件做整合。具体实现整合与定制参数传入,我们继续往下看。
Pod命令改造:引入pod update --transform-local --transform-file。
1. 上文我们了解了,每个command都有一个命令类,为了不污染cocoapods的源码,使得能正常随着cocoapods更新进行升级,我们模仿cocoapods设计的想法,在cocoapods/cocoapods.rb核心类引入hook/hook_option.rb,cocoapods.rb加入的内容如下:
# hook_file用于统一管理du_hook文件
# 判断有没有hook_file
if File.exist?(File.join(__dir__, 'cocoapods/du_hook/hook_file.rb'))
require 'cocoapods/hook/hook_file'
end2. 在hook_file中,Cat同学为cocoapods做了热更新机制,同时引入了main_hook.rb、main_hook.rb中引入了得物为cocoapods做的魔改部分。代码如下:
热更机制简单理解就是每次执行pod命令时会执行git操作,将魔改部分的仓库代码保持到最新,Cat这一巧妙的设计让得物iOSer都能实时享受到cocoapods改造带来的新功能。
require 'cocoapods/hook/cocoapods-hook/cocoapods_concurrent_hook' # 魔改的高并发下载
require 'cocoapods/hook/cocoapods-hook/cocoapods_option' # 为cocoapod 加入 命令参数的入口3. 我们继续往下看,在cocoapods_option.rb文件中。咱们模仿cocoapods的设计逻辑,对命令解析。如果有传入--transform-file --transform-local 参数,那么就引入 cocoapods_transform_file.rb 文件,进入文件编码整合的入口。
module Pod
class Command
module Options
module Demo
module Options
def initialize(argv)
# 每个电脑都有一个全局的环境变量,在执行命令的生命周期内是一直存在的,给环境变量传入配置,不改动cocoapods的config源配置文件,不入侵cocoapods的源代码。
ENV['transform_FILE'] = '1' if @transform_file
ENV['ransform_LOCAL'] = '1' if @transform_local
super
end
end
end
end
endRuby是一个运行时的动态语言,在required cocoapods_transform_file文件中,将指定的cocoapods函数进行重写,就能实现HOOK的功能。
- 因此在cocoapods_transform_file.rb文件中覆盖cocoapods/external_sources/path_source.rb 下class PathSource的fetch方法就能定制为本地依赖的组件、git依赖的组件的组件执行定制的整合能力
- 覆盖cocoapods/downlod.rb下的Module Downloader self.download module类方法就能定制为pod"Example"的组件执行定制的整合。
具体的整合思路我们继续往下看。
Pod组件编码整合介绍
- 我们为每个组件配置了整合的版本号,每次需要进行整合时会传入版本号,默认是不整合,当一个组件进入download流程。会优先判断组件配置的版本号是否满足。
- 如果不满足那么不进行整合,正常执行常规的下载流程。
- 如果满足:
- 会继续判断是否在存在已经缓存好的文件夹,如果存在,直接将整合好的缓存文件Copy到Pods文件夹
- Cococoapods的组件缓存目录在~/Library/Caches/Cocoapods/Pods/Release/<版本号>-hash
- 我们为了能提高整合的效率为每个整合好的组件也进行缓存,这样能明显提高cocoapods的下载效率。命令规则会在原目录下多一份~/Library/Caches/Cocoapods/Pods/Release/<版本号>-hash-setuped。
- 会继续判断是否在存在已经缓存好的文件夹,如果存在,直接将整合好的缓存文件Copy到Pods文件夹
- 如果不存在缓存文件,那么解析podspec,拿到待整合文件数组,执行整合,保存整合后的缓存,并将整合后的缓存Copy到Pods文件夹。

本地依赖组件整合介绍
- 当本地依赖组件进入fetch方法,判断组件配置的版本号是否满足,不满足不执行整合。
- 满足则执行整合,并将整合的内容保存到新文件中,保存到pod target数组中以备后续cocoapods生成本地组件的pod targets。

Native代码整改
为什么要改造?
- 针对所有文件做编码并整合,会使得分散在不同文件中的同名方法名称冲突,使得工程无法编译成功,因此需要扫描出工程中所有的同名方法,并扫描出同名方法的上层调用。
如何改造?
- 扫描工程中所有的方法可以借助swift-syntax或者SwiftLint自定义规则具体扫描代码可参考如下。
SwiftLint中依赖了Swiftsytax,本质都是借助Swiftsyntax进行词法分析,扫描出工程的所有extension同名函数,并进行改造。
override func visitPost(_ node: ExtensionDeclSyntax) {
let functionList = _isFunctionDecl(node)
guard !functionList.isEmpty else { return }
for funcItem in functionList {
// 如果是private function 那么不纳入考虑范围
guard !_isPrivateFunction(funcItem) else { continue }
// 如果不是public的extension,并且函数也不是public 那么这个函数就不是公开函数,也可以忽略
if !isPublicExtension && !_isPublicFunction(node: funcItem) {
continue
}
violations.insert(ReasonedRuleViolation(position: funcItem.position, reason: funcItem.resolvedName(), severity: .warning), at: violations.count)
}
}- 扫描出同名方法后,使用indexstore-db将方法签名传入,通过扫描产物,可得出方法的上层调用,并进行统一改造,indexstore-db使用可参考如下
Indexstore-db是一个用于存储和管理源代码索引数据的开源工具。indexstore-db工具可以收集和存储源代码的元数据信息,包括符号、模块依赖关系、引用关系等,以便在开发工具(如Xcode)中进行快速的代码导航和搜索。它在构建大型代码库时尤其有用,可以提高代码编辑、查找引用、代码重构等操作的效率。
func testExtensionSymbol() throws {
// indexstore-db 的动态加载库
let libIndexStore = try! IndexStoreLibrary(dylibPath: "/Applications/Xcode.app/xxx/libIndexStore.dylib")
// 生成indexstore 实例
let indexWait = try IndexStoreDB(storePath: "/Users/xxx/Library/Developer/Xcode/DerivedData/.../DataStore", databasePath: "/Users/xxx/Downloads/aaa", library: libIndexStore, waitUntilDoneInitializing: true)
indexWait.pollForUnitChangesAndWait()
// 假设我们需要扫描如下的文件
let symbols = indexWait.symbols(inFilePath: "/Users/xxx/Project/String+Demo.swift")
for symbol in symbols {
// 假设我们需要扫描searchAtRange函数。
guard symbol.name == "searchAtRange()" else { continue}
let res = indexWait.occurrences(ofUSR: symbol.usr, roles: .reference)
for x in res {
debugPrint(x.relations.compactMap({ symbol in
return symbol.symbol.usr
}))
}
}
}组件发版流程重构
为什么要改造?
- 将cocoapods与同名方法改造完后,我们进行全工程源码编译是可以通过的,而且由于做了编码整合,编译时长也降低了5~8分钟,但是当发布组件发布CI时发现,未整合的组件二进制与整合的源码会出现link时符号不对齐的问题。
未整合的组件二进制符号是确定的,调用下游的符号签名也是确定的,Swift有 fileprivate的函数定义,当函数由A文件经过编码迁移到整合后的文件时,函数的签名也会变化。因此会出现函数签名符号不对齐。
如何改造?
- 得物工程每个版本都有一个源码索引库和二进制索引库,因此在组件发版时,我们需要再创建一个索引库,编码整合后的二进制索引库,并重新建立一套编码整合的二进制的CICD打包流程。具体流程可参考如下。
开发者开发时使用正常的二进制制作任务。发版与出包的打包机会使用整合二进制索引库。这样设计使得对日常开发无感知,而且能保证对外提测的任务都是整合后的包。
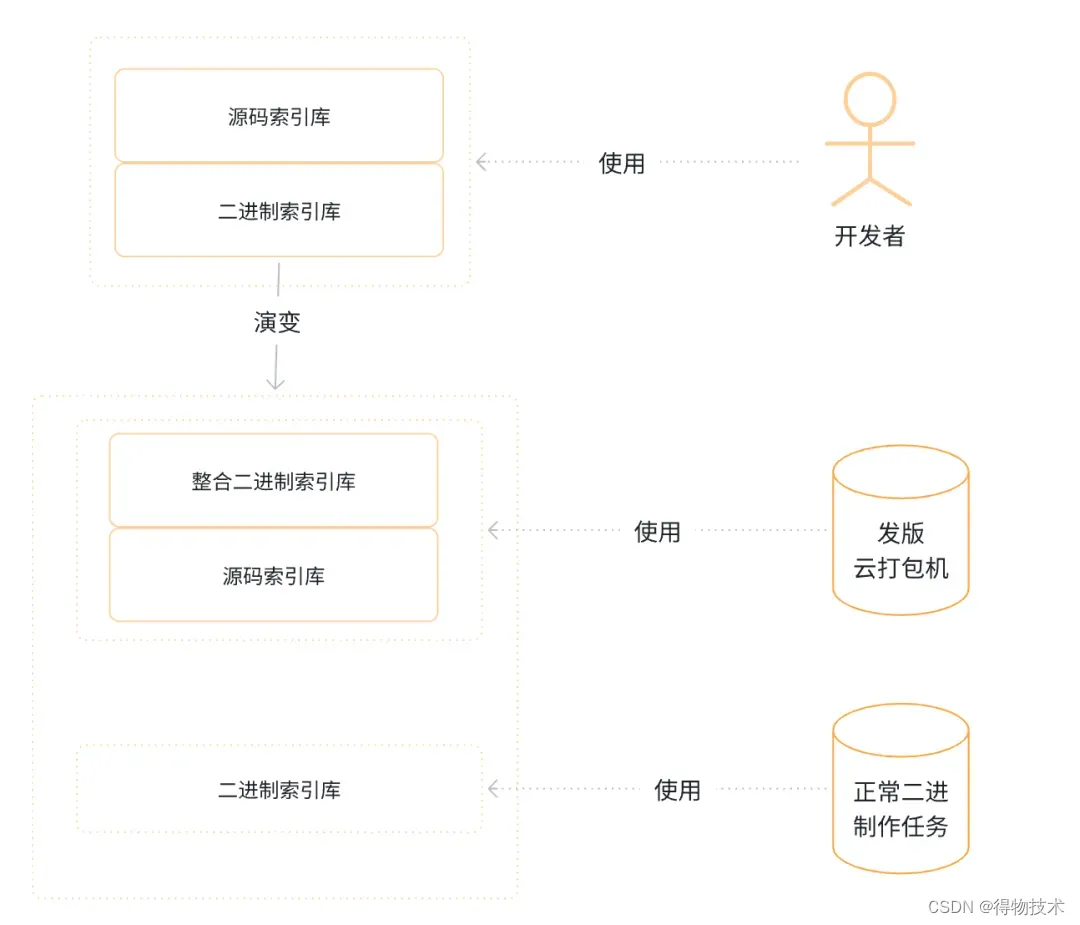
整合符号表
- 上述的改造解决了编译和出包的问题,但编译后的报错工程师阅读会比较困难,为了解决这个问题,引入了整合符号表,能根据符号表,反推出源工程的文件名以及行号,这就解决了编译报错阅读难的问题。

四、总结与收益
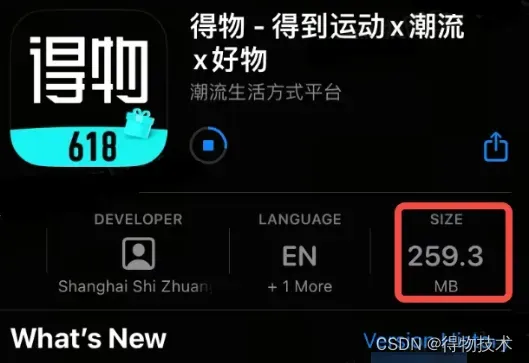
经过了深度的治理以及组件编码整合,期间cocoapods的改造与ruby原理的学习得益与Cat的请教,并得到各个iOS开发伙伴的无条件支持,同时将整个构建打包流程做了重构,以满足组件编码,经过多个版本的治理,得物的包大小在业务代码迭代有增量的前提下,从289.3M降低至259.3M。
下面列出每个阶段治理做个小结。

五、展望
后续包体的主要方向,是结合产物的扫描,与函数命名域治理以及全工程分析无用功能与可下线功能的持续跟进,并在防裂化上做好每次不合理增量的把控。把包体积的任务指标share至各个业务域。让包体积能在深度优化与防裂化两条路并行。
引用:
https://github.com/apple/indexstore-db
https://github.com/realm/SwiftLint
https://refspecs.linuxfoundation.org/LSB_3.0.0/LSB-Core-generic/LSB-Core-generic/ehframechpt.html
https://juejin.cn/post/6844904168096792583
*文/明颉
本文属得物技术原创,更多精彩文章请看:得物技术
未经得物技术许可严禁转载,否则依法追究法律责任!

![AI论文速读 | 2024[ICML]FlashST:简单通用的流量预测提示微调框架](https://img-blog.csdnimg.cn/direct/298821f3e9e84d95bc42cb4a680b52e7.jpeg#pic_center)





![【代码随想录】【算法训练营】【第32天】 [122]买卖股票的最佳时机II [376]摆动序列 [53]最大子序和](https://img-blog.csdnimg.cn/direct/ec2d0c118b174a7195f69976deac86eb.png)