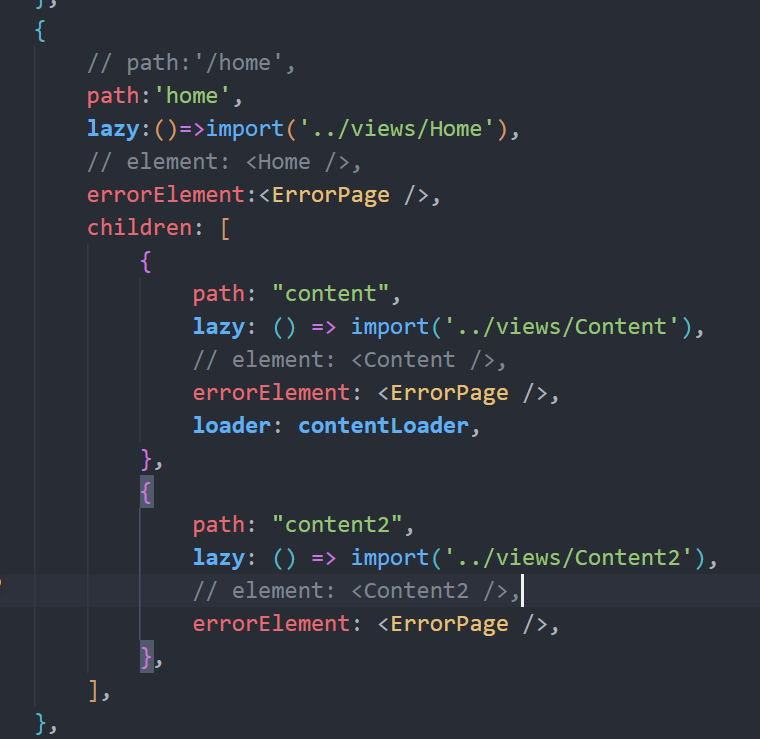
网络结构
1. Backbone

2. Head

3. 说明
- 网络结构按 YOLOv10m 绘制,不同 scale 的模型在结构上略有不同,而不是像 YOLOv8 一样仅调整 depth 和 width。
- Head 有部分后续计算与 YOLOv8 完全相同,上图省略,具体请看此文。
- YOLOv10 整体的网络结构与 YOLOv8 相同,在一些细节模块上有所改进,查看具体的模块计算方式、优化策略跳转模型优化部分。
4. Predict Postprocess
首先需要说明的是,网络实际包含两个 Head(结构相同、参数不同),分别对应了 One-to-many Head 和 One-to-one Head,在训练时两个 Head 同时参与,而推理预测时只需要 One-to-one Head。
class v10Detect(Detect):
def __init__(self, nc=80, ch=()):
super().__init__(nc, ch)
c3 = max(ch[0], min(self.nc, 100)) # channels
self.cv3 = ...
self.one2one_cv2 = copy.deepcopy(self.cv2)
self.one2one_cv3 = copy.deepcopy(self.cv3)
后处理具体流程:
one2one [1, 84, 6300]→ \to →boxes [1, 6300, 4]+scores [1, 6300, 80]- 根据每个 Anchor 最高的分类得分
max_scores [1,6300]排序,取前max_det=300个 Anchor - 将这 300 个 Anchor 的 80 类分类得分再做一次排序,取前
max_det=300个
此过程可以看作直接将所有 scores 中得分较高的 300 个结果作为检测结果,代码中使用两次 topk 可能是效率更高。 由于 scores 计算使用的是 Sigmoid 而非 Softmax,这个后处理过程就可能会得到两个 Anchor 相同的框(即框的位置大小也都相同),但类别不同的结果。
由于后处理的不同,作者建议在预测中可以自由调节置信度阈值,或者设较小的阈值来提升对小目标、远处目标的检测效果,并且可以看出调节阈值对于后处理速度并无影响,只是从这 300 个结果中用不同的阈值筛选出最终结果而已。
# step 1
preds = preds["one2one"][0] # [1,84,6300]
preds.transpose(-1, -2) # [1,6300,84]
boxes, scores = preds.split([4, nc], dim=-1) # [1,6300,4], [1,6300,80]
# step 2
max_scores = scores.amax(dim=-1) # [1,6300]
max_scores, index = torch.topk(max_scores, max_det, axis=-1) # [1,300], [1,300]
index = index.unsqueeze(-1)
boxes = torch.gather(boxes, dim=1, index=index.repeat(1, 1, boxes.shape[-1])) # [1,300,4]
scores = torch.gather(scores, dim=1, index=index.repeat(1, 1, scores.shape[-1])) # [1,300,80]
# step 3
scores, index = torch.topk(scores.flatten(1), max_det, axis=-1)
labels = index % nc
index = index // nc
boxes = boxes.gather(dim=1, index=index.unsqueeze(-1).repeat(1, 1, boxes.shape[-1]))
return boxes, scores, labels
Train
YOLOv10 最大的特点就是在预测阶段不需要 NMS,而这个功能正是通过训练来实现的。
YOLOv10 在训练中会对 One-to-many Head 和 One-to-one Head 两个头的输出都计算损失,而损失函数与 YOLOv8 相同。具体看下面代码,仅仅是 tal_topk 参数设置不同,也就是在参与损失计算的正样本的选择上有所不同。
class v10DetectLoss:
def __init__(self, model):
self.one2many = v8DetectionLoss(model, tal_topk=10)
self.one2one = v8DetectionLoss(model, tal_topk=1)
def __call__(self, preds, batch):
one2many = preds["one2many"]
loss_one2many = self.one2many(one2many, batch)
one2one = preds["one2one"]
loss_one2one = self.one2one(one2one, batch)
return loss_one2many[0] + loss_one2one[0], torch.cat((loss_one2many[1], loss_one2one[1]))
YOLOv8 的损失计算代码较多,关于代码逐句解析请看此文。本文将以尽可能简洁明了的方式说明损失的计算流程。
1. 前期准备
在训练阶段使用的网络输出为 Head 的输出
x
1
,
x
2
,
x
3
x_1,x_2,x_3
x1,x2,x3,并将其分离为分类得分 pred_scores [b, a, 80]、原始检测框 pred_dist [b, a, 16] 以及解码后的检测框 pred_bboxes [b, a, 4]。对于标签也会做简单处理,得到分类标签 gt_labels [b, n, 1] 和目标框标签 gt_bboxes [b, n, 4]。
b:BatchSize
a:Anchors
80:分类数量
4:xyxy
n:该 Batch 中的最大实例数,实例数不足的图像会填充0,方便后续矩阵运算
2. 正样本选择与指标计算
选择 Anchor 坐标在 gt_bboxes 内部的输出来计算指标:
overlaps = CIoU(gt_boxes, pd_boxes)
align_metric = bbox_scores.pow(self.alpha) * overlaps.pow(self.beta)
此处 bbox_scores 仅保留 Anchor 所在 gt_bboxes 对应类别的得分,alpha=0.5, beta=6。对应 YOLOv10 论文中的公式(
s
s
s 代表 Anchor 是否在实例内部):
m
(
α
,
β
)
=
s
⋅
p
α
⋅
I
o
U
(
b
^
,
b
)
β
m(\alpha,\beta) = s·p^{\alpha} · \mathrm{IoU}(\hat{b}, b)^\beta
m(α,β)=s⋅pα⋅IoU(b^,b)β
选出每个 gt 目标中 align_metric 前 10 / 1 的输出,如果同一个 Anchor 的输出入选多个 gt 目标的 Top10 / 1,选择 overlaps 即 IoU 较高的。
通俗来说对于每个实例,都会选择一些与其匹配得分较高的输出作为正样本,但对于一个 Anchor 的输出同时只能作为一个目标的正样本。而 One-to-many Head 和 One-to-one Head 的不同之处就在于一个会选择多个(Top 10)得分较高的作为正样本,一个只选择得分最高的作为正样本。
3. target scores
t
j
=
u
∗
⋅
m
j
m
∗
t_j = u^*·\frac{m_j}{m^*}
tj=u∗⋅m∗mj
其中
t
j
t_j
tj 代表某个实例的
j
j
j 号正样本的 target_score,
u
∗
u^*
u∗ 代表所有正样本中 IoU 的最大值,
m
j
m_j
mj 代表该正样本的 align_metric,
m
∗
m^*
m∗ 同理为最大值。
4. 计算损失
4.1 Class
self.bce = nn.BCEWithLogitsLoss(reduction="none")
target_scores_sum = max(target_scores.sum(), 1)
loss[1] = self.bce(pred_scores, target_scores.to(dtype)).sum() / target_scores_sum
l n = − w n [ y n ⋅ log σ ( x n ) + ( 1 − y n ) ⋅ log ( 1 − σ ( x n ) ) ] l_{n}=-w_{n}\left[y_{n} \cdot \log \sigma\left(x_{n}\right)+\left(1-y_{n}\right) \cdot \log \left(1-\sigma\left(x_{n}\right)\right)\right] ln=−wn[yn⋅logσ(xn)+(1−yn)⋅log(1−σ(xn))]
l
n
l_n
ln 表示某个 Anchor 在某个类别上的分类损失,一共有
b
∗
a
∗
80
b*a*80
b∗a∗80 个
l
l
l;
w
n
w_n
wn 统一取 1;
y
n
y_n
yn 在正样本处的值为对应的 target_score,其余负样本处的值为 0;
L c l s = ∑ l ∑ t L_{cls}=\frac{\sum{l}}{\sum{t}} Lcls=∑t∑l
4.2 Box
weight = target_scores.sum(-1)[fg_mask].unsqueeze(-1)
iou = bbox_iou(pred_bboxes[fg_mask], target_bboxes[fg_mask], xywh=False, CIoU=True)
loss_iou = ((1.0 - iou) * weight).sum() / target_scores_sum
L b o x = ∑ t j ( 1 − C I o U j ) ∑ t L_{box}=\frac{\sum{t_j(1 - \mathrm{CIoU}_j)}} {\sum{t}} Lbox=∑t∑tj(1−CIoUj)
I
o
U
\mathrm{IoU}
IoU 仅计算正样本,并且会以 target_score 作为权重 weight
注:一个 Anchor 输出仅作为一个实例的正样本,仅在实例的类别上存在 target_score,可用以下代码作为验证
(target_scores.sum(-1) == target_scores.max(-1)[0]).all()
> True
4.3 DFL
target_ltrb = bbox2dist(anchor_points, target_bboxes, self.reg_max)
loss_dfl = self._df_loss(pred_dist[fg_mask].view(-1, self.reg_max + 1), target_ltrb[fg_mask]) * weight
loss_dfl = loss_dfl.sum() / target_scores_sum
def _df_loss(pred_dist, target):
tl = target.long() # target left
tr = tl + 1 # target right
wl = tr - target # weight left
wr = 1 - wl # weight right
return (
F.cross_entropy(pred_dist, tl.view(-1), reduction="none").view(tl.shape) * wl
+ F.cross_entropy(pred_dist, tr.view(-1), reduction="none").view(tl.shape) * wr
).mean(-1, keepdim=True)
注:这里计算损失时使用的 pred_dist 是网络对于 Box 的原始输出,未经过 DFL 解码成常规的 Box,而标签则是将常规的 target_bboxes 转化成了距离对应 Anchor 坐标的距离,与 pred_dist 的形式相匹配。
l n = − w y n log exp ( x n , y n ) ∑ c = 1 C exp ( x n , c ) ⋅ 1 { y n ≠ i g n o r e _ i n d e x } l_{n}=-w_{y_{n}} \log \frac{\exp \left(x_{n, y_{n}}\right)}{\sum_{c=1}^{C} \exp \left(x_{n, c}\right)} \cdot 1\left\{y_{n} \neq \mathrm { ignore\_index }\right\} ln=−wynlog∑c=1Cexp(xn,c)exp(xn,yn)⋅1{yn=ignore_index}
上式为 F.cross_entropy 计算公式,等价于用 Softmax 计算分类概率
p
p
p,
l
n
=
−
log
p
n
l_n = -\log p_n
ln=−logpn 作为损失,其中
p
n
p_n
pn 为标签类别对应的概率。
l
d
f
l
=
(
y
i
+
1
−
y
)
l
i
+
(
y
−
y
i
)
l
i
+
1
l_{dfl} = (y_{i+1} - y)l_i + (y-y_i)l_{i+1}
ldfl=(yi+1−y)li+(y−yi)li+1
其中
y
y
y 为真实的标签,即某个坐标到 Anchor 坐标的距离,
y
i
+
1
y_{i+1}
yi+1 代表对
y
y
y 向上取整,
y
i
y_i
yi 代表对
y
y
y 向下取整。
举例进行说明,假设 y = 3.7 y = 3.7 y=3.7, l d f l = ( 4 − 3.7 ) l 3 + ( 3.7 − 3 ) l 4 l_{dfl} = (4-3.7)l_3 + (3.7-3)l_4 ldfl=(4−3.7)l3+(3.7−3)l4,由于实际的 y y y 通常不会是个整数,单纯的将输出往单一类别收敛是不行的,理想情况就是让 3 和 4 两个类别的概率都比较高,那么通过 DFL 层的计算坐标就会落在 3~4 之间,同时以 y y y 到两边的距离作为权重来平衡两个类别的概率,往理想的 0.3 × 3 + 0.7 × 4 = 3.7 0.3 \times 3 + 0.7 \times 4=3.7 0.3×3+0.7×4=3.7 收敛。
注:每个正样本的损失为 4 个坐标的 DFL 损失的均值,最终当前 Batch 的 DFL 损失为所有正样本损失的和除以 target_scores_sum。
模型优化
1. Lightweight Classification Head
在 YOLOv8 的检测头中,分类头比回归头的参数量和计算量都要大。论文中表示在分析了分类误差和回归误差的影响后,发现回归头意义更大,因此减少分类头的开销不会对性能有较大损害。
论文的分析实验为分别用真实的回归值和分类值代替输出,使回归或分类的损失置零,最终在验证集上的精度无回归的要比无分类的高很多。个人理解就是类似单独训练两个头,已知检测框位置训练分类,和已知分类训练检测框位置,得出的结论就是针对检测框的回归任务更难,分类任务简单很多,那么分类头就可以简化一些,至少参数量没必要比回归头还多。
分类头从两个 3 × 3 3\times 3 3×3 卷积轻量化为两个的深度可分离卷积,深度可分离卷积由一个 3 × 3 3\times 3 3×3 的深度卷积和一个 1 × 1 1\times 1 1×1 的逐点卷积构成。
在结构图中,卷积上方参数对应 [size, stride, padding, groups]。下面结合代码,感受 groups 对于卷积计算的影响(在深度可分离卷积中通常输入通道数和输出通道数相同,为了更直观,示例中使用不同的通道数)
import torch.nn as nn
from ptflops import get_model_complexity_info
conv1 = nn.Conv2d(64, 128, 3, 1, 1, bias=False)
conv2 = nn.Conv2d(64, 128, 3, 1, 1, groups=64, bias=False)
conv3 = nn.Conv2d(64, 128, 3, 1, 1, groups=2, bias=False)
flops, params = get_model_complexity_info(conv1, (64, 320, 320), as_strings=False, print_per_layer_stat=True)
print(f"FLOPs: {flops}, {64*3*3*128*320*320}")
print(f"Parameters: {params}, {128*64*3*3}")
flops, params = get_model_complexity_info(conv2, (64, 320, 320), as_strings=False, print_per_layer_stat=True)
print(f"FLOPs: {flops}, {1*3*3*128*320*320}")
print(f"Parameters: {params}, {128*1*3*3}")
flops, params = get_model_complexity_info(conv3, (64, 320, 320), as_strings=False, print_per_layer_stat=True)
print(f"FLOPs: {flops}, {32*3*3*128*320*320}")
print(f"Parameters: {params}, {128*32*3*3}")
in_channels 和 out_channels 都需要可被 groups 整除,标准卷积 groups=1。可以看作把输入按通道维度划分为 groups 组,并将卷积核按输出通道即卷积核个数也划分为 groups 组,然后进行 groups 个并行的标准卷积。
2. SCDown

YOLOv8 使用一个标准卷积同时实现空间下采样
h
,
w
→
h
/
2
,
w
/
2
h,w\to h/2,w/2
h,w→h/2,w/2 和通道变化
c
→
2
c
c \to 2c
c→2c,计算成本高。
SCDown(Spatial-channel decoupled downsampling)将上面两个操作——空间和通道解耦。先通过
1
×
1
1\times 1
1×1 的逐点卷积调节通道数,再通过
3
×
3
3\times 3
3×3 的深度卷积做空间下采样,在降低计算成本的同时最大限度保留信息。
3. CIB

在结构上 C2fCIB 就是用 CIB (compact inverted block)替换了原本 C2f 中的 Bottleneck,CIB 则是将 Bottleneck 中的标准卷积用深度卷积加逐点卷积进行替换。
论文中,计算每个 stage 最后一个 basic block 中最后一个卷积的数值秩(numerical rank),数值秩越低表示冗余越多,即可进行简化。数值秩是先计算矩阵的奇异值,奇异值大于阈值的数量为数值秩,奇异值大代表重要的信息,奇异值小代表冗余或噪声。
最终得到的结论如下图,stage 越大,模型越大,冗余越多。这里的 stage 看起来是对应了网络中的 8 个 C2f。

在模块替换时,大致方法为对数值秩进行排序,逐步替换,直到出现性能下降。因此不同 scale 的模型在模块选择上也有所不同。(具体原理和细节暂不深究)
4. Large-kernel Conv
用 size 较大的深度卷积可以扩大感受野,增强模型能力,但简单使用会影响针对小目标的浅层特征,也会在高分辨率阶段引入 I/O 开销和延迟。建议在小模型的深层阶段(例如 YOLOv10n 的 22 层),将 CIB 中的第二个深层卷积替换为
7
×
7
7\times 7
7×7 和
3
×
3
3\times3
3×3 的深度卷积,具体还是看代码比较直观。
class CIB(nn.Module):
def __init__(self, c1, c2, shortcut=True, e=0.5, lk=False):
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = nn.Sequential(
Conv(c1, c1, 3, g=c1),
Conv(c1, 2 * c_, 1),
Conv(2 * c_, 2 * c_, 3, g=2 * c_) if not lk else RepVGGDW(2 * c_),
Conv(2 * c_, c2, 1),
Conv(c2, c2, 3, g=c2),
)
class RepVGGDW(torch.nn.Module):
def __init__(self, ed) -> None:
super().__init__()
self.conv = Conv(ed, ed, 7, 1, 3, g=ed, act=False)
self.conv1 = Conv(ed, ed, 3, 1, 1, g=ed, act=False)
self.dim = ed
self.act = nn.SiLU()
def forward(self, x):
return self.act(self.conv(x) + self.conv1(x))
5. PSA

论文中对这个模块并没有原理上的说明,主要是自注意力的开销比较大,所以设计了 PSA(Partial self-attention)对分辨率最低的特征的一半进行计算,将对于全局的学习能力以较小的计算成本融入 YOLO 中。
Attention 部分的具体计算方式结合下图和代码查看:

class Attention(nn.Module):
def __init__(self, dim, num_heads=8, attn_ratio=0.5):
super().__init__()
self.num_heads = num_heads
self.head_dim = dim // num_heads
self.key_dim = int(self.head_dim * attn_ratio)
self.scale = self.key_dim ** -0.5
nh_kd = self.key_dim * num_heads
h = dim + nh_kd * 2
self.qkv = Conv(dim, h, 1, act=False)
self.proj = Conv(dim, dim, 1, act=False)
self.pe = Conv(dim, dim, 3, 1, g=dim, act=False)
def forward(self, x):
B, C, H, W = x.shape
N = H * W
qkv = self.qkv(x)
q, k, v = qkv.view(B, self.num_heads, self.key_dim*2 + self.head_dim, N).split([self.key_dim, self.key_dim, self.head_dim], dim=2)
attn = ((q.transpose(-2, -1) @ k) * self.scale)
attn = attn.softmax(dim=-1)
x = (v @ attn.transpose(-2, -1)).view(B, C, H, W) + self.pe(v.reshape(B, C, H, W))
x = self.proj(x)
return x






![[Cloud Networking] Layer 2 Protocol](https://img-blog.csdnimg.cn/direct/70300f65f3f8422498f323c38858672f.png)




![Java面向对象-[封装、继承、多态、权限修饰符]](https://img-blog.csdnimg.cn/direct/ee0b16d8512b4735b994de318f1b1783.gif#pic_center)