一 实例操作目标检测
下面通过一个具体的例子来说明锚框标签。我们已经为加载图像中的狗和猫定义了真实边界框,其中第一个 元素是类别(0代表狗,1代表猫),其余四个元素是左上角和右下角的(x, y)轴坐标(范围介于0和1之间)。我 们还构建了五个锚框,用左上角和右下角的坐标进行标记:A0, . . . , A4(索引从0开始)。然后我们在图像中 绘制这些真实边界框和锚框。
ground_truth = torch.tensor([[0, 0.1, 0.08, 0.52, 0.92],
[1, 0.55, 0.2, 0.9, 0.88]])
anchors = torch.tensor([[0, 0.1, 0.2, 0.3], [0.15, 0.2, 0.4, 0.4],
[0.63, 0.05, 0.88, 0.98], [0.66, 0.45, 0.8, 0.8],
[0.57, 0.3, 0.92, 0.9]])
fig = d2l.plt.imshow(img)
show_bboxes(fig.axes, ground_truth[:, 1:] * bbox_scale, ['dog', 'cat'], 'k')
show_bboxes(fig.axes, anchors * bbox_scale, ['0', '1', '2', '3', '4'])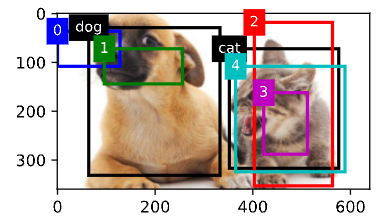
使用上面定义的multibox_target函数,我们可以根据狗和猫的真实边界框,标注这些锚框的分类和偏移量。 在这个例子中,背景、狗和猫的类索引分别为0、1和2。下面我们为锚框和真实边界框样本添加一个维度。
labels = multibox_target(anchors.unsqueeze(dim=0),
ground_truth.unsqueeze(dim=0))返回的结果中有三个元素,都是张量格式。第三个元素包含标记的输入锚框的类别。
1.1 使用非极大值抑制预测边界框
在预测时,我们先为图像生成多个锚框,再为这些锚框一一预测类别和偏移量。一个预测好的边界框则根据 其中某个带有预测偏移量的锚框而生成。下面我们实现了offset_inverse函数,该函数将锚框和偏移量预测 作为输入,并应用逆偏移变换来返回预测的边界框坐标。
def offset_inverse(anchors, offset_preds):
anc = d2l.box_corner_to_center(anchors)
pred_bbox_xy = (offset_preds[:, :2] * anc[:, 2:] / 10) + anc[:, :2]
pred_bbox_wh = torch.exp(offset_preds[:, 2:] / 5) * anc[:, 2:]
pred_bbox = torch.cat((pred_bbox_xy, pred_bbox_wh), axis=1)
predicted_bbox = d2l.box_center_to_corner(pred_bbox)
return predicted_bbox当有许多锚框时,可能会输出许多相似的具有明显重叠的预测边界框,都围绕着同一目标。为了简化输出,我 们可以使用非极大值抑制(non‐maximum suppression,NMS)合并属于同一目标的类似的预测边界框。
以下是非极大值抑制的工作原理。对于一个预测边界框B,目标检测模型会计算每个类别的预测概率。假设最大的预测概率为p,则该概率所对应的类别B即为预测的类别。具体来说,我们将p称为预测边界框B的置信度(confidence)。在同一张图像中,所有预测的非背景边界框都按置信度降序排序,以生成列表L。然后 我们通过以下步骤操作排序列表L。
- 从L中 选取置信度最高的预测边界框B1作为基准,然后将所有与B1的IoU超过预定阈值ϵ的非基准预测 边界框从L中移除。这时,L保留了置信度最高的预测边界框,去除了与其太过相似的其他预测边界框。 简而言之,那些具有非极大值置信度的边界框被抑制了。
- 从L中选取置信度第二高的预测边界框B2作为又一个基准,然后将所有与B2的IoU大于ϵ的非基准预测 边界框从L中移除。
- 重复上述过程,直到L中的所有预测边界框都曾被用作基准。此时,L中任意一对预测边界框的IoU都小于阈值ϵ;因此,没有一对边界框过于相似。
- 输出列表L中的所有预测边界框。
以下nms函数按降序对置信度进行排序并返回其索引。
#@save
def nms(boxes, scores, iou_threshold):
B = torch.argsort(scores, dim=-1, descending=True)
keep = []
while B.numel() > 0:
i = B[0]
keep.append(i)
if B.numel() == 1:
break
iou = box_iou(boxes[i, :].reshape(-1, 4),
boxes[B[1:], :].reshape(-1, 4)).reshape(-1)
inds = torch.nonzero(iou <= iou_threshold).reshape(-1)
B = B[inds + 1]
return torch.tensor(keep, device=boxes.device)我们定义以下multibox_detection函数来 将非极大值抑制应用于预测边界框。这里的实现有点复杂,请不要 担心。我们将在实现之后,马上用一个具体的例子来展示它是如何工作的。
#@save
def multibox_detection(cls_probs, offset_preds, anchors, nms_threshold=0.5,
pos_threshold=0.009999999):
device, batch_size = cls_probs.device, cls_probs.shape[0]
anchors = anchors.squeeze(0)
num_classes, num_anchors = cls_probs.shape[1], cls_probs.shape[2]
out = []
for i in range(batch_size):
cls_prob, offset_pred = cls_probs[i], offset_preds[i].reshape(-1, 4)
conf, class_id = torch.max(cls_prob[1:], 0)
predicted_bb = offset_inverse(anchors, offset_pred)
keep = nms(predicted_bb, conf, nms_threshold)
all_idx = torch.arange(num_anchors, dtype=torch.long, device=device)
combined = torch.cat((keep, all_idx))
uniques, counts = combined.unique(return_counts=True)
non_keep = uniques[counts == 1]
all_id_sorted = torch.cat((keep, non_keep))
class_id[non_keep] = -1
class_id = class_id[all_id_sorted]
conf, predicted_bb = conf[all_id_sorted], predicted_bb[all_id_sorted]
below_min_idx = (conf < pos_threshold)
class_id[below_min_idx] = -1
conf[below_min_idx] = 1 - conf[below_min_idx]
pred_info = torch.cat((class_id.unsqueeze(1),
conf.unsqueeze(1), predicted_bb), dim=1)
out.append(pred_info)
return torch.stack(out)现在让我们将上述算法应用到一个带有四个锚框的具体示例中。为简单起见,我们假设预测的偏移量都是零, 这意味着预测的边界框即是锚框。对于背景、狗和猫其中的每个类,我们还定义了它的预测概率。
anchors = torch.tensor([[0.1, 0.08, 0.52, 0.92], [0.08, 0.2, 0.56, 0.95],
[0.15, 0.3, 0.62, 0.91], [0.55, 0.2, 0.9, 0.88]])
offset_preds = torch.tensor([0] * anchors.numel())
cls_probs = torch.tensor([[0] * 4, # 背景的预测概率
[0.9, 0.8, 0.7, 0.1], # 狗的预测概率
[0.1, 0.2, 0.3, 0.9]]) # 猫的预测概率我们可以在图像上绘制这些预测边界框和置信度。
fig = d2l.plt.imshow(img)
show_bboxes(fig.axes, anchors * bbox_scale,
['dog=0.9', 'dog=0.8', 'dog=0.7', 'cat=0.9'])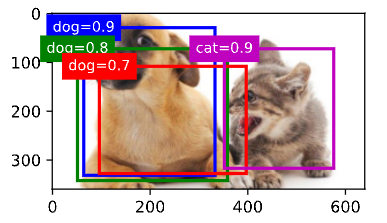
现在我们可以调用multibox_detection函数来 执行非极大值抑制,其中阈值设置为0.5。请注意,我们在示例 的张量输入中添加了维度。
我们可以看到返回结果的形状是(批量大小,锚框的数量,6)。最内层维度中的六个元素提供了同一预测 边界框的输出信息。第一个元素是预测的类索引,从0开始(0代表狗,1代表猫),值‐1表示背景或在非极大 值抑制中被移除了。第二个元素是预测的边界框的置信度。其余四个元素分别是预测边界框左上角和右下角 的(x, y)轴坐标(范围介于0和1之间)。
output = multibox_detection(cls_probs.unsqueeze(dim=0),
offset_preds.unsqueeze(dim=0),
anchors.unsqueeze(dim=0),
nms_threshold=0.5)
output
删除‐1类别(背景)的预测边界框后,我们可以 输出由非极大值抑制保存的最终预测边界框。
fig = d2l.plt.imshow(img)
for i in output[0].detach().numpy():
if i[0] == -1:
continue
label = ('dog=', 'cat=')[int(i[0])] + str(i[1])
show_bboxes(fig.axes, [torch.tensor(i[2:]) * bbox_scale], label)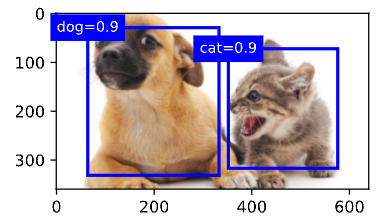
实践中,在执行非极大值抑制前,我们甚至 可以将置信度较低的预测边界框移除,从而减少此算法中的计算量。我们也可以对非极大值抑制的输出结果进行后处理。例如,只保留置信度更高的结果作为最终输出。
小结:
- 我们 以图像的每个像素为中心生成不同形状的锚框。
- 交并比(IoU)也被称为杰卡德系数,用于衡量两个边界框的相似性。它是相交面积与相并面积的比率。
- 在训练集中,我们需要给每个锚框两种类型的标签。一个是与锚框中目标检测的类别,另一个是锚框真实相对于边界框的偏移量。
- 预测期间可以使用非极大值抑制(NMS)来移除类似的预测边界框,从而简化输出。
二 多尺度目标检测
我们以输入图像的每个像素为中心,生成了多个锚框。基本而言,这些锚框代表了图像不同区域 的样本。然而,如果为每个像素都生成的锚框,我们最终可能会得到太多需要计算的锚框。想象一个 561×728的 输入图像,如果以每个像素为中心生成五个形状不同的锚框,就需要在图像上标记和预测超过200万个锚框 (561 × 728 × 5)。
减少图像上的锚框数量并不困难。比如,我们可以在输入图像中均匀采样一小部分像素,并以它们为中心生 成锚框。此外,在不同尺度下,我们可以生成不同数量和不同大小的锚框。直观地说,比起较大的目标,较小的目标在图像上出现的可能性更多样。例如,1 × 1、1 × 2和2 × 2的目标可以分别以4、2和1种可能的方式 出现在2 × 2图像上。因此,当使用较小的锚框检测较小的物体时,我们可以采样更多的区域,而对于较大的 物体,我们可以采样较少的区域。
为了演示如何在多个尺度下生成锚框,让我们先读取一张图像。
%matplotlib inline
import torch
from d2l import torch as d2l
img = d2l.plt.imread('../img/catdog.jpg')
img.shape # (360, 640, 3)display_anchors函数定义如下。我们 在特征图(fmap)上生成锚框(anchors),每个单位(像素)作为锚框的中心。由于锚框中的(x, y)轴坐标值(anchors)已经被除以特征图(fmap)的宽度和高度,因此这些值介 于0和1之间,表示特征图中锚框的相对位置。
由于锚框(anchors)的中心分布于特征图(fmap)上的所有单位,因此这些中心必须根据其相对空间位置在任何输入图像上均匀分布。更具体地说,给定特征图的宽度和高度fmap_w和fmap_h,以下函数将均匀地对任 何输入图像中fmap_h行和fmap_w列中的像素进行采样。以这些均匀采样的像素为中心,将会生成大小为s(假 设列表s的长度为1)且宽高比(ratios)不同的锚框。
def display_anchors(fmap_w, fmap_h, s):
d2l.set_figsize()
fmap = torch.zeros((1, 10, fmap_h, fmap_w))
anchors = d2l.multibox_prior(fmap, sizes=s, ratios=[1, 2, 0.5])
bbox_scale = torch.tensor((w, h, w, h))
d2l.show_bboxes(d2l.plt.imshow(img).axes, anchors[0] * bbox_scale)首先,让我们考虑探测小目标。为了在显示时更容易分辨,在这里具有不同中心的锚框不会重叠:锚框的尺 度设置为0.15,特征图的高度和宽度设置为4。我们可以看到,图像上4行和4列的锚框的中心是均匀分布的。
display_anchors(fmap_w=4, fmap_h=4, s=[0.15])
然后,我们将特征图的高度和宽度减小一半,然后使用较大的锚框来检测较大的目标。当尺度设置为0.4时, 一些锚框将彼此重叠。
display_anchors(fmap_w=2, fmap_h=2, s=[0.4])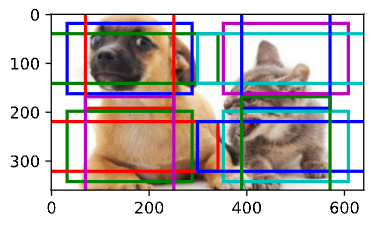
最后,我们进一步将特征图的高度和宽度减小一半,然后将锚框的尺度增加到0.8。此时,锚框的中心即是图 像的中心。
display_anchors(fmap_w=1, fmap_h=1, s=[0.8])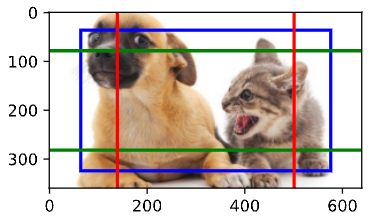
小结:
- 在多个尺度下,我们 可以生成不同尺寸的锚框来检测不同尺寸的目标。
- 通过定义特征图的形状,我们 可以决定任何图像上均匀采样的锚框的中心。
- 我们 使用输入图像在某个感受野区域内的信息,来预测输入图像上与该区域位置相近的锚框类别和偏 移量。
- 我们可以通过深入学习,在 多个层次上的图像分层表示进行多尺度目标检测。


![[Cloud Networking] Layer 2 Protocol](https://img-blog.csdnimg.cn/direct/70300f65f3f8422498f323c38858672f.png)




![Java面向对象-[封装、继承、多态、权限修饰符]](https://img-blog.csdnimg.cn/direct/ee0b16d8512b4735b994de318f1b1783.gif#pic_center)