目录
- 1.Maven 依赖
- 2.创建表结构
- 3.yml 配置
- 4.TimeShardingAlgorithm.java 分片算法类
- 5.ShardingAlgorithmTool.java 分片工具类
- 6.ShardingTablesLoadRunner.java 初始化缓存类
- 7.SpringUtil.java Spring工具类
- 8.源码测试
- 9.测试结果
- 10.代码地址
背景: 项目用户数据库表量太大,对数据按月分表,需要满足如下需求:
- 将数据库按月分表;
- 自动建表;
- 数据自动跨表查询。
ShardingJDBC 4 升到 5 过后还是解决了许多问题,4版本的分页、跨库和子查询问题都解决来了,性能也提高了。
1.Maven 依赖
<!-- Sharding-JDBC -->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>
<version>5.1.0</version>
</dependency>
<!-- ShardingJDBC 5.1.0使用druid连接池需要加dbcp依赖 -->
<dependency>
<groupId>org.apache.tomcat</groupId>
<artifactId>tomcat-dbcp</artifactId>
<version>10.0.16</version>
</dependency>
<!-- Mybatis的分页插件 -->
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper-spring-boot-starter</artifactId>
<version>1.3.0</version>
</dependency>
2.创建表结构
-- ------------------------------
-- 用户表
-- ------------------------------
CREATE TABLE `t_user` (
`id` bigint(16) NOT NULL COMMENT '主键',
`username` varchar(64) NOT NULL COMMENT '用户名',
`password` varchar(64) NOT NULL COMMENT '密码',
`age` int(8) NOT NULL COMMENT '年龄',
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='用户表';
-- ------------------------------
-- 用户表202201
-- ------------------------------
CREATE TABLE `t_user_202201` (
`id` bigint(16) NOT NULL COMMENT '主键',
`username` varchar(64) NOT NULL COMMENT '用户名',
`password` varchar(64) NOT NULL COMMENT '密码',
`age` int(8) NOT NULL COMMENT '年龄',
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='用户表202201';
3.yml 配置
server:
port: 8081
spring:
### 处理连接池冲突 #####
main:
allow-bean-definition-overriding: true
shardingsphere:
# 是否启用 Sharding
enabled: true
# 打印sql
# props:
# sql-show: true
datasource:
names: mydb
mydb:
type: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://localhost:3306/mydb?useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: root
# 数据源其他配置
initialSize: 5
minIdle: 5
maxActive: 20
maxWait: 60000
timeBetweenEvictionRunsMillis: 60000
minEvictableIdleTimeMillis: 300000
validationQuery: SELECT 1 FROM DUAL
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
poolPreparedStatements: true
# 配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙
#filters: stat,wall,log4j
maxPoolPreparedStatementPerConnectionSize: 20
useGlobalDataSourceStat: true
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=500
rules:
sharding:
# 表策略配置
tables:
# t_user 是逻辑表
t_user:
# 配置数据节点,这里是按月分表
# 示例1:时间范围设置在202201 ~ 210012
# actualDataNodes: mydb.t_user_$->{2022..2100}0$->{1..9},mydb.t_user_$->{2022..2100}1$->{0..2}
# 示例2:时间范围设置在202201 ~ 202203
actualDataNodes: mydb.t_user
tableStrategy:
# 使用标准分片策略
standard:
# 配置分片字段
shardingColumn: create_time
# 分片算法名称,不支持大写字母和下划线,否则启动就会报错
shardingAlgorithmName: time-sharding-altorithm
# t_log 是逻辑表
t_log:
# 配置数据节点,这里是按月分表
# 示例1:时间范围设置在202201 ~ 210012
# actualDataNodes: mydb.t_user_$->{2022..2100}0$->{1..9},mydb.t_user_$->{2022..2100}1$->{0..2}
# 示例2:时间范围设置在202201 ~ 202203
actualDataNodes: mydb.t_log
tableStrategy:
# 使用标准分片策略
standard:
# 配置分片字段
shardingColumn: create_time
# 分片算法名称,不支持大写字母和下划线,否则启动就会报错
shardingAlgorithmName: time-sharding-altorithm
# 分片算法配置
shardingAlgorithms:
# 分片算法名称,不支持大写字母和下划线,否则启动就会报错
time-sharding-altorithm:
# 类型:自定义策略
type: CLASS_BASED
props:
# 分片策略
strategy: standard
# 分片算法类
algorithmClassName: com.demo.module.config.sharding.TimeShardingAlgorithm
# mybatis-plus
mybatis-plus:
mapper-locations: classpath*:/mapper/*Mapper.xml
# 实体扫描,多个package用逗号或者分号分隔
typeAliasesPackage: cn.agile.stats.*.entity
# 测试环境打印sql
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
pagehelper:
helperDialect: postgresql
4.TimeShardingAlgorithm.java 分片算法类
import com.demo.module.config.sharding.enums.ShardingTableCacheEnum;
import com.google.common.collect.Range;
import lombok.extern.slf4j.Slf4j;
import org.apache.shardingsphere.sharding.api.sharding.standard.PreciseShardingValue;
import org.apache.shardingsphere.sharding.api.sharding.standard.RangeShardingValue;
import org.apache.shardingsphere.sharding.api.sharding.standard.StandardShardingAlgorithm;
import java.sql.Timestamp;
import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter;
import java.util.*;
import java.util.function.Function;
/**
* <p> @Title TimeShardingAlgorithm
* <p> @Description 分片算法,按月分片
*
* @author ACGkaka
* @date 2022/12/20 11:33
*/
@Slf4j
public class TimeShardingAlgorithm implements StandardShardingAlgorithm<Timestamp> {
/**
* 分片时间格式
*/
private static final DateTimeFormatter TABLE_SHARD_TIME_FORMATTER = DateTimeFormatter.ofPattern("yyyyMM");
/**
* 完整时间格式
*/
private static final DateTimeFormatter DATE_TIME_FORMATTER = DateTimeFormatter.ofPattern("yyyyMMdd HH:mm:ss");
/**
* 表分片符号,例:t_contract_202201 中,分片符号为 "_"
*/
private final String TABLE_SPLIT_SYMBOL = "_";
/**
* 精准分片
* @param tableNames 对应分片库中所有分片表的集合
* @param preciseShardingValue 分片键值,其中 logicTableName 为逻辑表,columnName 分片键,value 为从 SQL 中解析出来的分片键的值
* @return 表名
*/
@Override
public String doSharding(Collection<String> tableNames, PreciseShardingValue<Timestamp> preciseShardingValue) {
String logicTableName = preciseShardingValue.getLogicTableName();
ShardingTableCacheEnum logicTable = ShardingTableCacheEnum.of(logicTableName);
if (logicTable == null) {
log.error(">>>>>>>>>> 【ERROR】数据表类型错误,请稍后重试,logicTableNames:{},logicTableName:{}",
ShardingTableCacheEnum.logicTableNames(), logicTableName);
throw new IllegalArgumentException("数据表类型错误,请稍后重试");
}
log.info(">>>>>>>>>> 【INFO】精确分片,节点配置表名:{},数据库缓存表名:{}", tableNames, logicTable.resultTableNamesCache());
LocalDateTime dateTime = preciseShardingValue.getValue().toLocalDateTime();
String resultTableName = logicTableName + "_" + dateTime.format(TABLE_SHARD_TIME_FORMATTER);
// 检查分表获取的表名是否存在,不存在则自动建表
return ShardingAlgorithmTool.getShardingTableAndCreate(logicTable, resultTableName);
}
/**
* 范围分片
* @param tableNames 对应分片库中所有分片表的集合
* @param rangeShardingValue 分片范围
* @return 表名集合
*/
@Override
public Collection<String> doSharding(Collection<String> tableNames, RangeShardingValue<Timestamp> rangeShardingValue) {
String logicTableName = rangeShardingValue.getLogicTableName();
ShardingTableCacheEnum logicTable = ShardingTableCacheEnum.of(logicTableName);
if (logicTable == null) {
log.error(">>>>>>>>>> 【ERROR】逻辑表范围异常,请稍后重试,logicTableNames:{},logicTableName:{}",
ShardingTableCacheEnum.logicTableNames(), logicTableName);
throw new IllegalArgumentException("逻辑表范围异常,请稍后重试");
}
log.info(">>>>>>>>>> 【INFO】范围分片,节点配置表名:{},数据库缓存表名:{}", tableNames, logicTable.resultTableNamesCache());
// between and 的起始值
Range<Timestamp> valueRange = rangeShardingValue.getValueRange();
boolean hasLowerBound = valueRange.hasLowerBound();
boolean hasUpperBound = valueRange.hasUpperBound();
// 获取最大值和最小值
Set<String> tableNameCache = logicTable.resultTableNamesCache();
LocalDateTime min = hasLowerBound ? valueRange.lowerEndpoint().toLocalDateTime() :getLowerEndpoint(tableNameCache);
LocalDateTime max = hasUpperBound ? valueRange.upperEndpoint().toLocalDateTime() :getUpperEndpoint(tableNameCache);
// 循环计算分表范围
Set<String> resultTableNames = new LinkedHashSet<>();
while (min.isBefore(max) || min.equals(max)) {
String tableName = logicTableName + TABLE_SPLIT_SYMBOL + min.format(TABLE_SHARD_TIME_FORMATTER);
resultTableNames.add(tableName);
min = min.plusMinutes(1);
}
return ShardingAlgorithmTool.getShardingTablesAndCreate(logicTable, resultTableNames);
}
@Override
public void init() {
}
@Override
public String getType() {
return null;
}
// --------------------------------------------------------------------------------------------------------------
// 私有方法
// --------------------------------------------------------------------------------------------------------------
/**
* 获取 最小分片值
* @param tableNames 表名集合
* @return 最小分片值
*/
private LocalDateTime getLowerEndpoint(Collection<String> tableNames) {
Optional<LocalDateTime> optional = tableNames.stream()
.map(o -> LocalDateTime.parse(o.replace(TABLE_SPLIT_SYMBOL, "") + "01 00:00:00", DATE_TIME_FORMATTER))
.min(Comparator.comparing(Function.identity()));
if (optional.isPresent()) {
return optional.get();
} else {
log.error(">>>>>>>>>> 【ERROR】获取数据最小分表失败,请稍后重试,tableName:{}", tableNames);
throw new IllegalArgumentException("获取数据最小分表失败,请稍后重试");
}
}
/**
* 获取 最大分片值
* @param tableNames 表名集合
* @return 最大分片值
*/
private LocalDateTime getUpperEndpoint(Collection<String> tableNames) {
Optional<LocalDateTime> optional = tableNames.stream()
.map(o -> LocalDateTime.parse(o.replace(TABLE_SPLIT_SYMBOL, "") + "01 00:00:00", DATE_TIME_FORMATTER))
.max(Comparator.comparing(Function.identity()));
if (optional.isPresent()) {
return optional.get();
} else {
log.error(">>>>>>>>>> 【ERROR】获取数据最大分表失败,请稍后重试,tableName:{}", tableNames);
throw new IllegalArgumentException("获取数据最大分表失败,请稍后重试");
}
}
}
5.ShardingAlgorithmTool.java 分片工具类
import com.alibaba.druid.util.StringUtils;
import com.demo.module.config.sharding.enums.ShardingTableCacheEnum;
import com.demo.module.utils.SpringUtil;
import lombok.extern.slf4j.Slf4j;
import org.apache.shardingsphere.driver.jdbc.core.datasource.ShardingSphereDataSource;
import org.apache.shardingsphere.infra.config.RuleConfiguration;
import org.apache.shardingsphere.mode.manager.ContextManager;
import org.apache.shardingsphere.sharding.algorithm.config.AlgorithmProvidedShardingRuleConfiguration;
import org.apache.shardingsphere.sharding.api.config.rule.ShardingTableRuleConfiguration;
import org.apache.shardingsphere.sharding.rule.TableRule;
import org.springframework.core.env.Environment;
import javax.sql.DataSource;
import java.lang.reflect.Field;
import java.lang.reflect.Modifier;
import java.sql.*;
import java.time.YearMonth;
import java.time.format.DateTimeFormatter;
import java.util.*;
import java.util.stream.Collectors;
/**
* <p> @Title ShardingAlgorithmTool
* <p> @Description 按月分片算法工具
*
* @author ACGkaka
* @date 2022/12/20 14:03
*/
@Slf4j
public class ShardingAlgorithmTool {
/** 表分片符号,例:t_contract_202201 中,分片符号为 "_" */
private static final String TABLE_SPLIT_SYMBOL = "_";
/** 数据库配置 */
private static final Environment ENV = SpringUtil.getApplicationContext().getEnvironment();
private static final String DATASOURCE_URL = ENV.getProperty("spring.shardingsphere.datasource.mydb.url");
private static final String DATASOURCE_USERNAME = ENV.getProperty("spring.shardingsphere.datasource.mydb.username");
private static final String DATASOURCE_PASSWORD = ENV.getProperty("spring.shardingsphere.datasource.mydb.password");
/**
* 检查分表获取的表名是否存在,不存在则自动建表
* @param logicTable 逻辑表
* @param resultTableNames 真实表名,例:t_contract_202201
* @return 存在于数据库中的真实表名集合
*/
public static Set<String> getShardingTablesAndCreate(ShardingTableCacheEnum logicTable, Collection<String> resultTableNames) {
return resultTableNames.stream().map(o -> getShardingTableAndCreate(logicTable, o)).collect(Collectors.toSet());
}
/**
* 检查分表获取的表名是否存在,不存在则自动建表
* @param logicTable 逻辑表
* @param resultTableName 真实表名,例:t_contract_202201
* @return 确认存在于数据库中的真实表名
*/
public static String getShardingTableAndCreate(ShardingTableCacheEnum logicTable, String resultTableName) {
// 缓存中有此表则返回,没有则判断创建
if (logicTable.resultTableNamesCache().contains(resultTableName)) {
return resultTableName;
} else {
// 未创建的表返回逻辑空表
boolean isSuccess = createShardingTable(logicTable, resultTableName);
return isSuccess ? resultTableName : logicTable.logicTableName();
}
}
/**
* 重载全部缓存
*/
public static void tableNameCacheReloadAll() {
Arrays.stream(ShardingTableCacheEnum.values()).forEach(ShardingAlgorithmTool::tableNameCacheReload);
}
/**
* 重载指定分表缓存
* @param logicTable 逻辑表,例:t_contract
*/
public static void tableNameCacheReload(ShardingTableCacheEnum logicTable) {
// 读取数据库中|所有表名
List<String> tableNameList = getAllTableNameBySchema(logicTable);
// 删除旧的缓存(如果存在)
logicTable.resultTableNamesCache().clear();
// 写入新的缓存
logicTable.resultTableNamesCache().addAll(tableNameList);
// 动态更新配置 actualDataNodes
actualDataNodesRefresh(logicTable);
}
/**
* 获取所有表名
* @return 表名集合
* @param logicTable 逻辑表
*/
public static List<String> getAllTableNameBySchema(ShardingTableCacheEnum logicTable) {
List<String> tableNames = new ArrayList<>();
if (StringUtils.isEmpty(DATASOURCE_URL) || StringUtils.isEmpty(DATASOURCE_USERNAME) || StringUtils.isEmpty(DATASOURCE_PASSWORD)) {
log.error(">>>>>>>>>> 【ERROR】数据库连接配置有误,请稍后重试,URL:{}, username:{}, password:{}", DATASOURCE_URL, DATASOURCE_USERNAME, DATASOURCE_PASSWORD);
throw new IllegalArgumentException("数据库连接配置有误,请稍后重试");
}
try (Connection conn = DriverManager.getConnection(DATASOURCE_URL, DATASOURCE_USERNAME, DATASOURCE_PASSWORD);
Statement st = conn.createStatement()) {
String logicTableName = logicTable.logicTableName();
try (ResultSet rs = st.executeQuery("show TABLES like '" + logicTableName + TABLE_SPLIT_SYMBOL + "%'")) {
while (rs.next()) {
String tableName = rs.getString(1);
// 匹配分表格式 例:^(t\_contract_\d{6})$
if (tableName != null && tableName.matches(String.format("^(%s\\d{6})$", logicTableName + TABLE_SPLIT_SYMBOL))) {
tableNames.add(rs.getString(1));
}
}
}
} catch (SQLException e) {
log.error(">>>>>>>>>> 【ERROR】数据库连接失败,请稍后重试,原因:{}", e.getMessage(), e);
throw new IllegalArgumentException("数据库连接失败,请稍后重试");
}
return tableNames;
}
/**
* 动态更新配置 actualDataNodes
* @param logicTable
*/
public static void actualDataNodesRefresh(ShardingTableCacheEnum logicTable) {
try {
// 获取数据分片节点
String dbName = "mydb";
String logicTableName = logicTable.logicTableName();
Set<String> tableNamesCache = logicTable.resultTableNamesCache();
log.info(">>>>>>>>>> 【INFO】更新分表配置,logicTableName:{},tableNamesCache:{}", logicTableName, tableNamesCache);
// generate actualDataNodes
String newActualDataNodes = tableNamesCache.stream().map(o -> String.format("%s.%s", dbName, o)).collect(Collectors.joining(","));
ShardingSphereDataSource shardingSphereDataSource = SpringUtil.getBean(ShardingSphereDataSource.class);
updateShardRuleActualDataNodes(shardingSphereDataSource, logicTableName, newActualDataNodes);
}catch (Exception e){
log.error("初始化 动态表单失败,原因:{}", e.getMessage(), e);
}
}
// --------------------------------------------------------------------------------------------------------------
// 私有方法
// --------------------------------------------------------------------------------------------------------------
/**
* 刷新ActualDataNodes
*/
private static void updateShardRuleActualDataNodes(ShardingSphereDataSource dataSource, String logicTableName, String newActualDataNodes) {
// Context manager.
ContextManager contextManager = dataSource.getContextManager();
// Rule configuration.
String schemaName = "logic_db";
Collection<RuleConfiguration> newRuleConfigList = new LinkedList<>();
Collection<RuleConfiguration> oldRuleConfigList = dataSource.getContextManager()
.getMetaDataContexts()
.getMetaData(schemaName)
.getRuleMetaData()
.getConfigurations();
for (RuleConfiguration oldRuleConfig : oldRuleConfigList) {
if (oldRuleConfig instanceof AlgorithmProvidedShardingRuleConfiguration) {
// Algorithm provided sharding rule configuration
AlgorithmProvidedShardingRuleConfiguration oldAlgorithmConfig = (AlgorithmProvidedShardingRuleConfiguration) oldRuleConfig;
AlgorithmProvidedShardingRuleConfiguration newAlgorithmConfig = new AlgorithmProvidedShardingRuleConfiguration();
// Sharding table rule configuration Collection
Collection<ShardingTableRuleConfiguration> newTableRuleConfigList = new LinkedList<>();
Collection<ShardingTableRuleConfiguration> oldTableRuleConfigList = oldAlgorithmConfig.getTables();
oldTableRuleConfigList.forEach(oldTableRuleConfig -> {
if (logicTableName.equals(oldTableRuleConfig.getLogicTable())) {
ShardingTableRuleConfiguration newTableRuleConfig = new ShardingTableRuleConfiguration(oldTableRuleConfig.getLogicTable(), newActualDataNodes);
newTableRuleConfig.setTableShardingStrategy(oldTableRuleConfig.getTableShardingStrategy());
newTableRuleConfig.setDatabaseShardingStrategy(oldTableRuleConfig.getDatabaseShardingStrategy());
newTableRuleConfig.setKeyGenerateStrategy(oldTableRuleConfig.getKeyGenerateStrategy());
newTableRuleConfigList.add(newTableRuleConfig);
} else {
newTableRuleConfigList.add(oldTableRuleConfig);
}
});
newAlgorithmConfig.setTables(newTableRuleConfigList);
newAlgorithmConfig.setAutoTables(oldAlgorithmConfig.getAutoTables());
newAlgorithmConfig.setBindingTableGroups(oldAlgorithmConfig.getBindingTableGroups());
newAlgorithmConfig.setBroadcastTables(oldAlgorithmConfig.getBroadcastTables());
newAlgorithmConfig.setDefaultDatabaseShardingStrategy(oldAlgorithmConfig.getDefaultDatabaseShardingStrategy());
newAlgorithmConfig.setDefaultTableShardingStrategy(oldAlgorithmConfig.getDefaultTableShardingStrategy());
newAlgorithmConfig.setDefaultKeyGenerateStrategy(oldAlgorithmConfig.getDefaultKeyGenerateStrategy());
newAlgorithmConfig.setDefaultShardingColumn(oldAlgorithmConfig.getDefaultShardingColumn());
newAlgorithmConfig.setShardingAlgorithms(oldAlgorithmConfig.getShardingAlgorithms());
newAlgorithmConfig.setKeyGenerators(oldAlgorithmConfig.getKeyGenerators());
newRuleConfigList.add(newAlgorithmConfig);
}
}
// update context
contextManager.alterRuleConfiguration(schemaName, newRuleConfigList);
}
/**
* 创建分表
* @param logicTable 逻辑表
* @param resultTableName 真实表名,例:t_contract_202201
* @return 创建结果(true创建成功,false未创建)
*/
private static boolean createShardingTable(ShardingTableCacheEnum logicTable, String resultTableName) {
// 根据日期判断,当前月份之后分表不提前创建
String month = resultTableName.replace(logicTable.logicTableName() + TABLE_SPLIT_SYMBOL,"");
YearMonth shardingMonth = YearMonth.parse(month, DateTimeFormatter.ofPattern("yyyyMM"));
if (shardingMonth.isAfter(YearMonth.now())) {
return false;
}
synchronized (logicTable.logicTableName().intern()) {
// 缓存中有此表 返回
if (logicTable.resultTableNamesCache().contains(resultTableName)) {
return false;
}
// 缓存中无此表,则建表并添加缓存
executeSql(Collections.singletonList("CREATE TABLE IF NOT EXISTS `" + resultTableName + "` LIKE `" + logicTable.logicTableName() + "`;"));
// 缓存重载
tableNameCacheReload(logicTable);
}
return true;
}
/**
* 执行SQL
* @param sqlList SQL集合
*/
private static void executeSql(List<String> sqlList) {
if (StringUtils.isEmpty(DATASOURCE_URL) || StringUtils.isEmpty(DATASOURCE_USERNAME) || StringUtils.isEmpty(DATASOURCE_PASSWORD)) {
log.error(">>>>>>>>>> 【ERROR】数据库连接配置有误,请稍后重试,URL:{}, username:{}, password:{}", DATASOURCE_URL, DATASOURCE_USERNAME, DATASOURCE_PASSWORD);
throw new IllegalArgumentException("数据库连接配置有误,请稍后重试");
}
try (Connection conn = DriverManager.getConnection(DATASOURCE_URL, DATASOURCE_USERNAME, DATASOURCE_PASSWORD)) {
try (Statement st = conn.createStatement()) {
conn.setAutoCommit(false);
for (String sql : sqlList) {
st.execute(sql);
}
} catch (Exception e) {
conn.rollback();
log.error(">>>>>>>>>> 【ERROR】数据表创建执行失败,请稍后重试,原因:{}", e.getMessage(), e);
throw new IllegalArgumentException("数据表创建执行失败,请稍后重试");
}
} catch (SQLException e) {
log.error(">>>>>>>>>> 【ERROR】数据库连接失败,请稍后重试,原因:{}", e.getMessage(), e);
throw new IllegalArgumentException("数据库连接失败,请稍后重试");
}
}
}
6.ShardingTablesLoadRunner.java 初始化缓存类
import org.springframework.boot.CommandLineRunner;
import org.springframework.core.annotation.Order;
import org.springframework.stereotype.Component;
/**
* <p> @Title ShardingTablesLoadRunner
* <p> @Description 项目启动后,读取已有分表,进行缓存
*
* @author ACGkaka
* @date 2022/12/20 15:41
*/
@Order(value = 1) // 数字越小,越先执行
@Component
public class ShardingTablesLoadRunner implements CommandLineRunner {
@Override
public void run(String... args) {
// 读取已有分表,进行缓存
ShardingAlgorithmTool.tableNameCacheReloadAll();
}
}
7.SpringUtil.java Spring工具类
import org.springframework.beans.BeansException;
import org.springframework.context.ApplicationContext;
import org.springframework.context.ApplicationContextAware;
import org.springframework.core.env.Environment;
import org.springframework.stereotype.Component;
/**
* <p> @Title SpringUtil
* <p> @Description Spring工具类
*
* @author ACGkaka
* @date 2022/12/20 14:39
*/
@Component
public class SpringUtil implements ApplicationContextAware {
private static ApplicationContext applicationContext = null;
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
SpringUtil.applicationContext = applicationContext;
}
public static ApplicationContext getApplicationContext() {
return SpringUtil.applicationContext;
}
public static <T> T getBean(Class<T> cla) {
return applicationContext.getBean(cla);
}
public static <T> T getBean(String name, Class<T> cal) {
return applicationContext.getBean(name, cal);
}
public static String getProperty(String key) {
return applicationContext.getBean(Environment.class).getProperty(key);
}
}
8.源码测试
import com.demo.module.entity.User;
import com.demo.module.service.UserService;
import com.github.pagehelper.PageHelper;
import com.github.pagehelper.PageInfo;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter;
import java.util.ArrayList;
import java.util.List;
@SpringBootTest
class SpringbootDemoApplicationTests {
private final DateTimeFormatter DATE_TIME_FORMATTER = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
@Autowired
private UserService userService;
@Test
void saveTest() {
List<User> users = new ArrayList<>(3);
LocalDateTime time1 = LocalDateTime.parse("2022-01-01 00:00:00", DATE_TIME_FORMATTER);
LocalDateTime time2 = LocalDateTime.parse("2022-02-01 00:00:00", DATE_TIME_FORMATTER);
users.add(new User("ACGkaka_1", "123456", 10, time1, time1));
users.add(new User("ACGkaka_2", "123456", 11, time2, time2));
userService.saveBatch(users);
}
@Test
void listTest() {
PageHelper.startPage(1, 1);
List<User> users = userService.list();
PageInfo<User> pageInfo = new PageInfo<>(users);
System.out.println(">>>>>>>>>> 【Result】<<<<<<<<<< ");
System.out.println(pageInfo);
}
}
9.测试结果
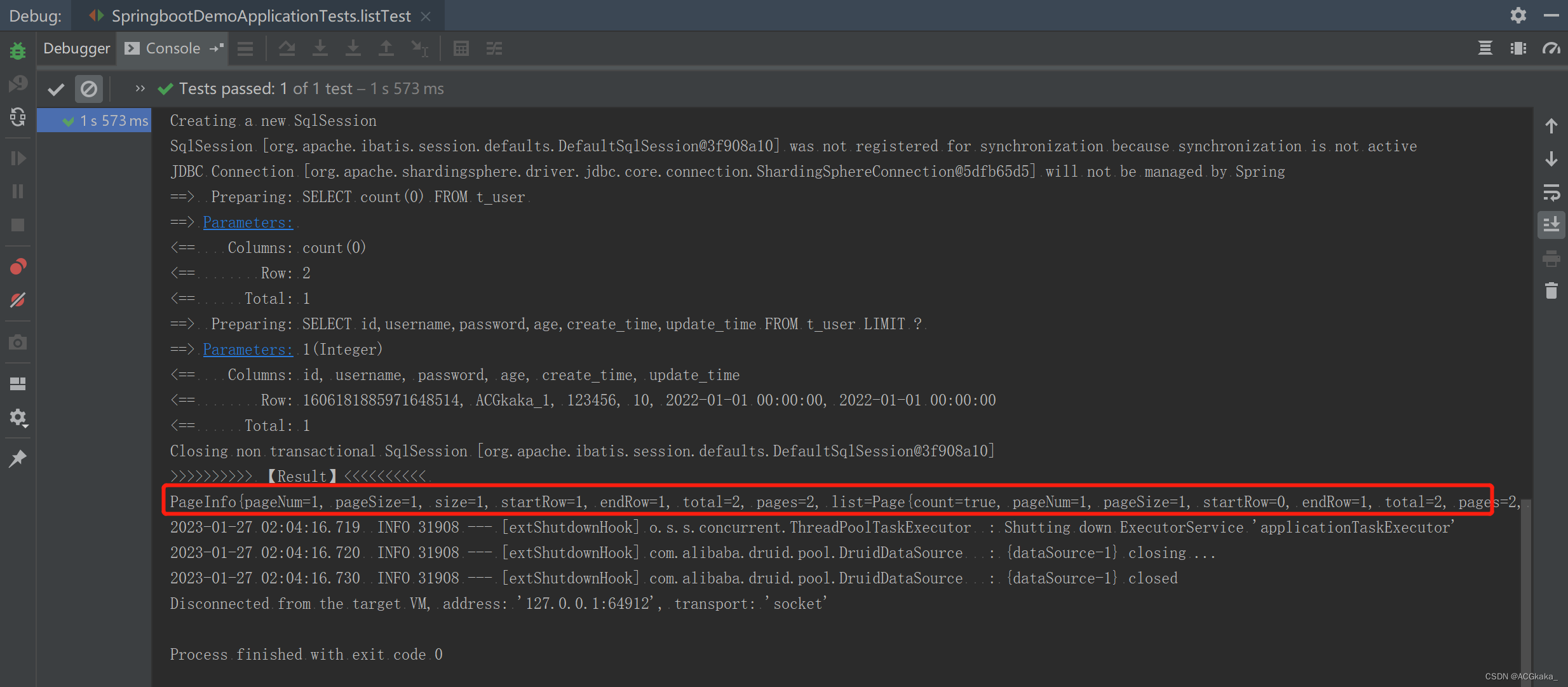
新增和查询可以正常分页查询,测试成功。
10.代码地址
地址: https://gitee.com/acgkaka/SpringBootExamples/tree/master/springboot-sharding-jdbc-month-5.1.0
参考地址:
1.SharDingJDBC-5.1.0按月水平分表+读写分离,自动创表、自动刷新节点表,https://blog.csdn.net/weixin_51216079/article/details/123873967
2.shardingjdbc 5.1 是否支持java 动态加载 数据节点,而不是在配置文件中用表达式定义好,https://community.sphere-ex.com/t/topic/1025







![UE Operation File [ Read / Write ] DTOperateFile 插件说明](https://img-blog.csdnimg.cn/9dc7660405c24ec2a7be702065fae2a9.png)
